- Базы данных и SQL. Лекция 18 часть 1

Содержание
- 2. Что изучим сегодня Первичным и ссылочный ключ СУБД Реляционные базы данных Операторы для запросов Логика написания
- 3. История баз данных История активного развития баз данных начинается с одного из самых значительных и неоднозначных
- 4. Иерархическая модель Поле Name в такой модели содержало название отдельно взятого элемента, поле ID было введено
- 5. Таким образом, благодаря иерархической модели, было выведено несколько фундаментальных понятий: Первичный ключ (Primary Key [PK]) –
- 6. Следующий большой шаг в истории развития баз данных сделал доктор Эдгар Кодд (Edgar Codd) - научный
- 7. Реляционная модель данных В реляционной модели, придуманной Коддом, данные можно было свободно описывать в их естественном
- 8. Основные понятия База данных — набор логически связанных данных, предназначенный для удовлетворения информационных потребностей. Реляционная база
- 9. Распространённые СУБД Oracle (~60% рынка СУБД); MS SQL Server (~15%); IBM DB (~13%); MySQL, PostgreSQL, SQLite,
- 11. Подмножества запросов Structured Query Language – структурированный язык запросов, предназначенный для работы с данными в рамках
- 12. SQL. Выборка данных Программный код на языке SQL пишется в виде запросов к данным. Сам по
- 13. Для выборки всех данных из таблицы, напишем запрос: SELECT * FROM table_Section ‘SELECT’ – это команда
- 14. Попробуем немного усложнить задачу, добавив условие. Допустим, теперь нам нужно вычленить записи с id больше, либо
- 15. Продолжаем изучение языка SQL и его логических операторов. Допустим, у нас есть таблица с названием Employee
- 16. Обратите внимание на этот запрос, который мы только что написали: SELECT name FROM Employee WHERE org
- 17. Таблица остаётся той же. Теперь нас интересуют все бухгалтеры или снабженцы с зарплатой менее 8000. В
- 18. SQL. Логика. BETWEEN и DISTINCT Когда мы работаем с числовым или табельным диапазоном значений, часто приходится
- 19. SQL. LIKE Очень часто возникает ситуация, когда мы хотим сделать выборку, но точных условий задать не
- 20. Символ ‘%’ означает, что после букв ‘Ва’ могут быть какие угодно символы. Их количество от 0
- 21. SQL. Логика. IN/NOT IN Когда условий становится много и они накладываются на одно поле, можно совместить
- 22. Как не сложно догадаться, оператор IN работает похожим на OR способом, т.е., в блоке WHERE можно
- 23. SQL. Логика. Подзапросы Очень часто мы сталкиваемся с ситуацией, когда в явном виде не знаем условий,
- 24. SQL. NULL NULL в СУБД — специальное значение (псевдозначение), которое может быть записано в поле таблицы
- 25. Что изучили сегодня Первичный и ссылочный ключ СУБД Реляционные базы данных Логика написания запросов Where/ Like/
- 27. Скачать презентацию
Слайд 2Что изучим сегодня
Первичным и ссылочный ключ
СУБД
Реляционные базы данных
Операторы для запросов
Логика написания запросов
Что изучим сегодня
Первичным и ссылочный ключ
СУБД
Реляционные базы данных
Операторы для запросов
Логика написания запросов

Слайд 3История баз данных
История активного развития баз данных начинается с одного из самых
История баз данных
История активного развития баз данных начинается с одного из самых

Слайд 4Иерархическая модель
Поле Name в такой модели содержало название отдельно взятого элемента, поле
Поле Name в такой модели содержало название отдельно взятого элемента, поле

Слайд 5Таким образом, благодаря иерархической модели, было выведено несколько фундаментальных понятий:
Первичный
Таким образом, благодаря иерархической модели, было выведено несколько фундаментальных понятий:
Первичный

Слайд 6Следующий большой шаг в истории развития баз данных сделал доктор Эдгар Кодд
Следующий большой шаг в истории развития баз данных сделал доктор Эдгар Кодд

Слайд 7Реляционная модель данных
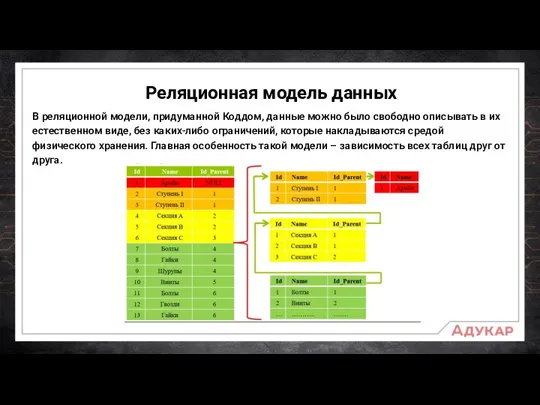
В реляционной модели, придуманной Коддом, данные можно было свободно описывать
Реляционная модель данных
В реляционной модели, придуманной Коддом, данные можно было свободно описывать
Слайд 8Основные понятия
База данных — набор логически связанных данных, предназначенный для удовлетворения информационных
Основные понятия
База данных — набор логически связанных данных, предназначенный для удовлетворения информационных

Слайд 9Распространённые СУБД
Oracle (~60% рынка СУБД);
MS SQL Server (~15%);
Распространённые СУБД
Oracle (~60% рынка СУБД);
MS SQL Server (~15%);

Слайд 11Подмножества запросов
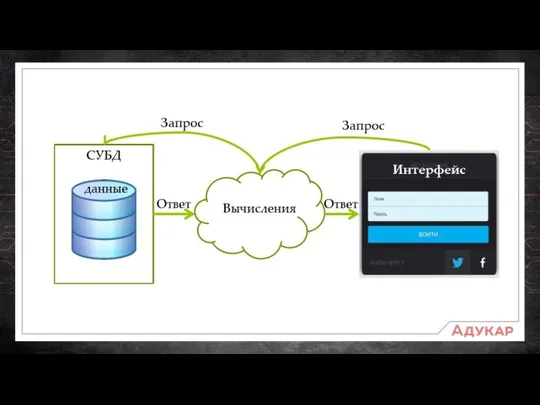
Structured Query Language – структурированный язык запросов, предназначенный для работы с
Подмножества запросов
Structured Query Language – структурированный язык запросов, предназначенный для работы с

Слайд 12SQL. Выборка данных
Программный код на языке SQL пишется в виде запросов к
SQL. Выборка данных
Программный код на языке SQL пишется в виде запросов к

Слайд 13Для выборки всех данных из таблицы, напишем запрос:
SELECT *
FROM table_Section
‘SELECT’
Для выборки всех данных из таблицы, напишем запрос:
SELECT *
FROM table_Section
‘SELECT’

Слайд 14Попробуем немного усложнить задачу, добавив условие. Допустим, теперь нам нужно вычленить записи
Попробуем немного усложнить задачу, добавив условие. Допустим, теперь нам нужно вычленить записи

Слайд 15Продолжаем изучение языка SQL и его логических операторов. Допустим, у нас есть
Продолжаем изучение языка SQL и его логических операторов. Допустим, у нас есть

Слайд 16Обратите внимание на этот запрос, который мы только что написали:
SELECT name
Обратите внимание на этот запрос, который мы только что написали:
SELECT name

Слайд 17Таблица остаётся той же. Теперь нас интересуют все бухгалтеры или снабженцы с
Таблица остаётся той же. Теперь нас интересуют все бухгалтеры или снабженцы с

Слайд 18SQL. Логика. BETWEEN и DISTINCT
Когда мы работаем с числовым или табельным диапазоном
SQL. Логика. BETWEEN и DISTINCT
Когда мы работаем с числовым или табельным диапазоном

Слайд 19SQL. LIKE
Очень часто возникает ситуация, когда мы хотим сделать выборку, но точных
SQL. LIKE
Очень часто возникает ситуация, когда мы хотим сделать выборку, но точных

Слайд 20Символ ‘%’ означает, что после букв ‘Ва’ могут быть какие угодно символы.
Символ ‘%’ означает, что после букв ‘Ва’ могут быть какие угодно символы.

Слайд 21SQL. Логика. IN/NOT IN
Когда условий становится много и они накладываются на одно
SQL. Логика. IN/NOT IN
Когда условий становится много и они накладываются на одно

Слайд 22Как не сложно догадаться, оператор IN работает похожим на OR способом, т.е.,
Как не сложно догадаться, оператор IN работает похожим на OR способом, т.е.,

Слайд 23SQL. Логика. Подзапросы
Очень часто мы сталкиваемся с ситуацией, когда в явном виде
SQL. Логика. Подзапросы
Очень часто мы сталкиваемся с ситуацией, когда в явном виде

Слайд 24SQL. NULL
NULL в СУБД — специальное значение (псевдозначение), которое может быть
SQL. NULL
NULL в СУБД — специальное значение (псевдозначение), которое может быть

Слайд 25Что изучили сегодня
Первичный и ссылочный ключ
СУБД
Реляционные базы данных
Логика написания запросов
Where/ Like/ In
Что изучили сегодня
Первичный и ссылочный ключ
СУБД
Реляционные базы данных
Логика написания запросов
Where/ Like/ In

 Базы данных. Системы управления базами данных и банками знаний
Базы данных. Системы управления базами данных и банками знаний Средства анализа и визуализации данных
Средства анализа и визуализации данных Занятие 12
Занятие 12 Создание компьютерной игры – визуальная новелла
Создание компьютерной игры – визуальная новелла Методы сортировки
Методы сортировки Профилактика интернет зависимости
Профилактика интернет зависимости Современный образовательный портал
Современный образовательный портал Черепашка. Позиционирование и координаты
Черепашка. Позиционирование и координаты Разгадай ребусы по информатике
Разгадай ребусы по информатике Эволюция информационной технологии
Эволюция информационной технологии MEDIUM. Универсальные, умные, открытые коммуникации суммируем лучшие технологии
MEDIUM. Универсальные, умные, открытые коммуникации суммируем лучшие технологии Разработка бренд айдентики и позиционирования центра социологических исследований
Разработка бренд айдентики и позиционирования центра социологических исследований Photoshop. Знакомство
Photoshop. Знакомство Формы записи алгоритмов. Фигуры (блоки) блок-схемы
Формы записи алгоритмов. Фигуры (блоки) блок-схемы Разработка тематического проекта Web-сайта различными инструментами
Разработка тематического проекта Web-сайта различными инструментами База данных SQLite. Лекция 12
База данных SQLite. Лекция 12 Моделирование движения математического маятника в среде с нелинейным сопротивлением на языке программирования Pascal
Моделирование движения математического маятника в среде с нелинейным сопротивлением на языке программирования Pascal Объектно-ориентированное программирование. Часть 2
Объектно-ориентированное программирование. Часть 2 Instruktaż ogólny dla kontrolerów
Instruktaż ogólny dla kontrolerów Вирусы
Вирусы Кодирование звука
Кодирование звука Антивирус Касперского для Linux File Server. (Лекция 4)
Антивирус Касперского для Linux File Server. (Лекция 4) Информатика. Некоторые понятия математической логики. Лекция 6
Информатика. Некоторые понятия математической логики. Лекция 6 Человек в виртуальной реальности
Человек в виртуальной реальности Циклы, массивы, таблицы
Циклы, массивы, таблицы Никнеймы. Что они могут рассказать о человеке?
Никнеймы. Что они могут рассказать о человеке? Правила стиля. Комбинаторика. Выполнение домашнего задания
Правила стиля. Комбинаторика. Выполнение домашнего задания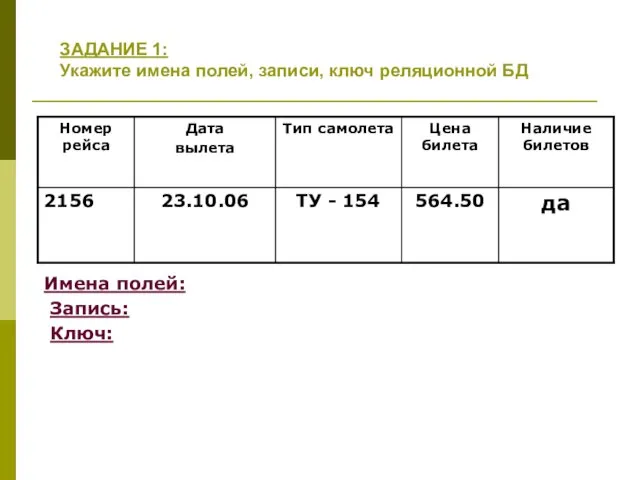 Задания. Базы данных
Задания. Базы данных