- Data science. Кластеризация

Содержание
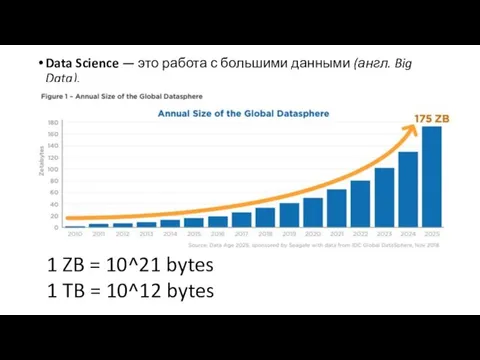
- 2. Data Science — это работа с большими данными (англ. Big Data). 1 ZB = 10^21 bytes
- 3. Эволюция в области хранения и Обработки данных
- 4. Кто такой Data Scientist?
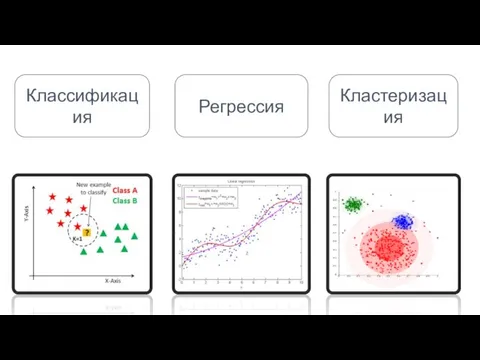
- 5. Классификация Регрессия Кластеризация
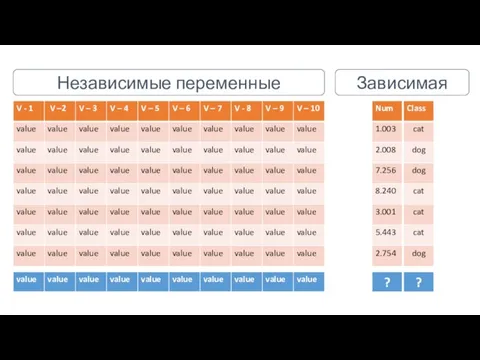
- 6. Независимые переменные Зависимая
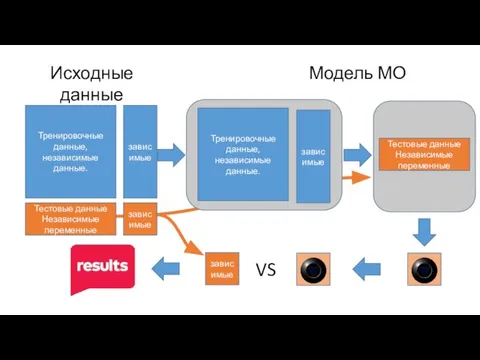
- 7. Тренировочные данные, независимые данные. Тестовые данные Независимые переменные зависимые зависимые Исходные данные Модель МО Тестовые данные
- 9. Кластеризация молекул
- 11. Задача на Python c1ccc(c(c1)C(=O)O)O Salicylic acid C1=CC(=C(C=C1N)O)C(=O)O PASA
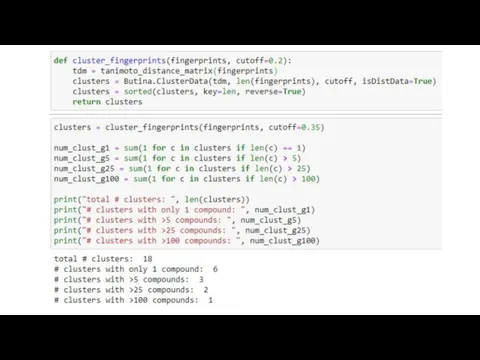
- 14. Сложности.. У нас есть список из 5 молекул (1 – 5). Нужно рассчитать коэфф. Танимото для
- 15. Трудности…
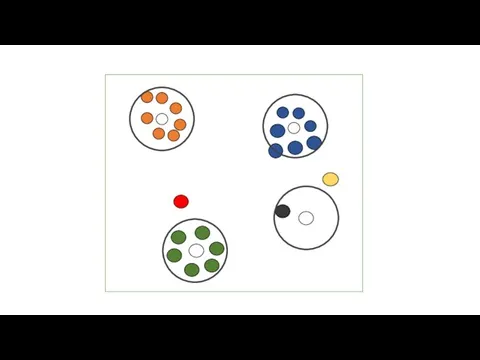
- 16. Принцип кластеризации
- 17. D B С А
- 18. Расстояние Для кластеризации необходимы: Расстояние Центроиды Цель – найти оптимальные центройды при данном расстоянии
- 19. Не оптимальный центроид Оптимальный центроид
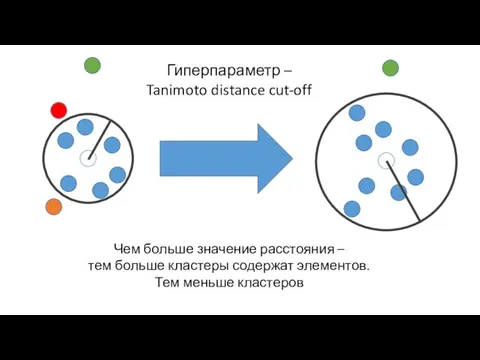
- 20. Гиперпараметр – Tanimoto distance cut-off Чем больше значение расстояния – тем больше кластеры содержат элементов. Тем
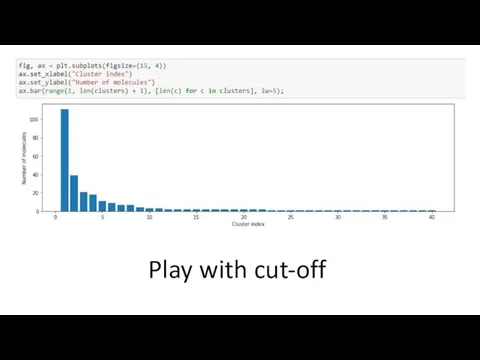
- 23. Play with cut-off
- 26. Скачать презентацию
Слайд 3Эволюция в
области
хранения и
Обработки
данных
Эволюция в
области
хранения и
Обработки
данных

Слайд 4Кто такой Data Scientist?
Кто такой Data Scientist?

Слайд 5Классификация
Регрессия
Кластеризация
Классификация
Регрессия
Кластеризация
Слайд 6Независимые переменные
Зависимая
Независимые переменные
Зависимая
Слайд 7Тренировочные данные, независимые данные.
Тестовые данные
Независимые переменные
зависимые
зависимые
Исходные данные
Модель МО
Тестовые данные
Независимые переменные
Тренировочные данные,
Тренировочные данные, независимые данные.
Тестовые данные
Независимые переменные
зависимые
зависимые
Исходные данные
Модель МО
Тестовые данные
Независимые переменные
Тренировочные данные,
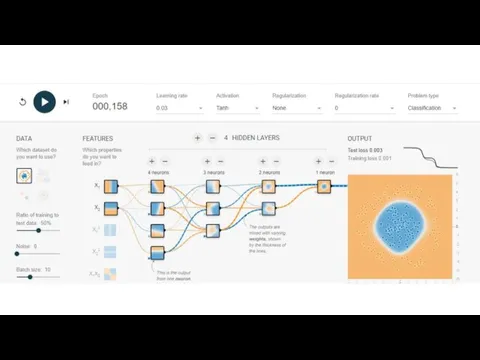
Слайд 9Кластеризация молекул
Кластеризация молекул


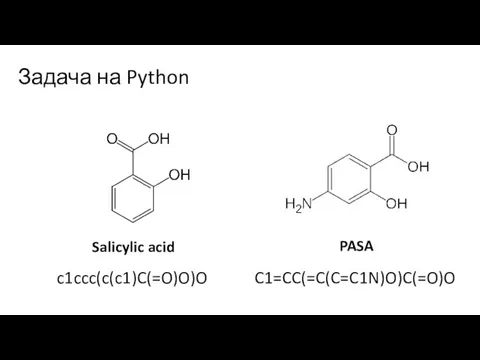
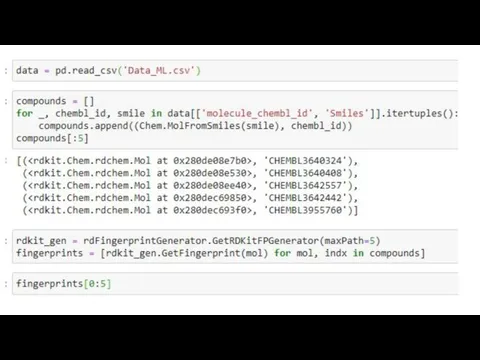
Слайд 11Задача на Python
c1ccc(c(c1)C(=O)O)O
Salicylic acid
C1=CC(=C(C=C1N)O)C(=O)O
PASA
Задача на Python
c1ccc(c(c1)C(=O)O)O
Salicylic acid
C1=CC(=C(C=C1N)O)C(=O)O
PASA

Слайд 14Сложности..
У нас есть список из 5 молекул (1 – 5). Нужно рассчитать
Сложности..
У нас есть список из 5 молекул (1 – 5). Нужно рассчитать

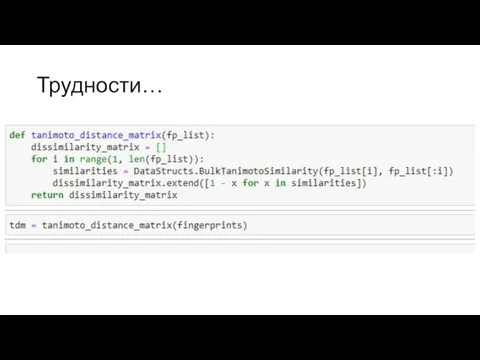
Слайд 15Трудности…
Трудности…
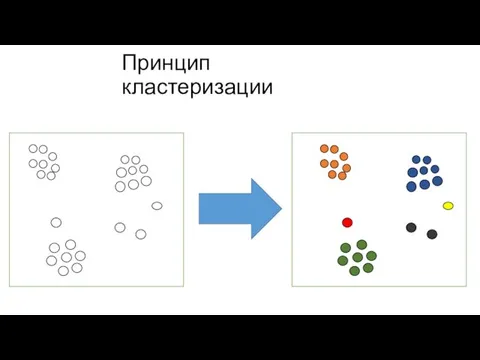
Слайд 16Принцип кластеризации
Принцип кластеризации
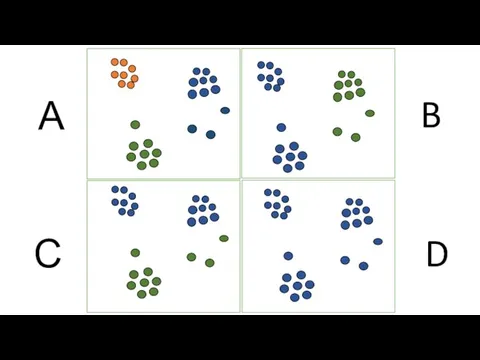
Слайд 17D
B
С
А
D
B
С
А
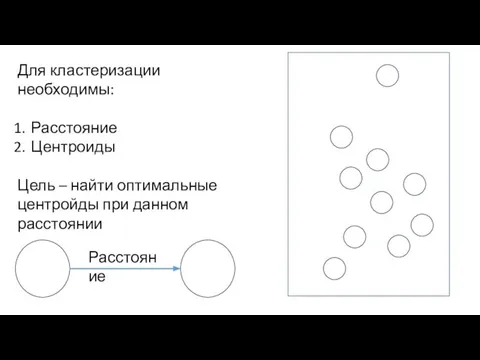
Слайд 18Расстояние
Для кластеризации необходимы:
Расстояние
Центроиды
Цель – найти оптимальные
центройды при данном
расстоянии
Расстояние
Для кластеризации необходимы:
Расстояние
Центроиды
Цель – найти оптимальные
центройды при данном
расстоянии
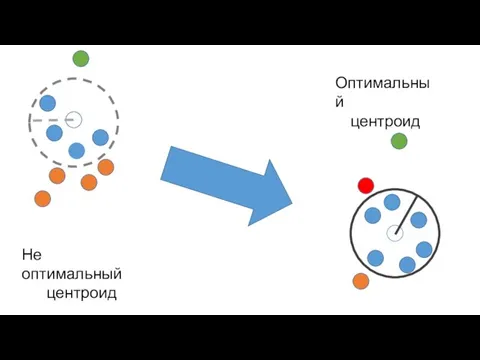
Слайд 19Не оптимальный
центроид
Оптимальный
центроид
Не оптимальный
центроид
Оптимальный
центроид
Слайд 20Гиперпараметр –
Tanimoto distance cut-off
Чем больше значение расстояния –
тем больше
Гиперпараметр –
Tanimoto distance cut-off
Чем больше значение расстояния –
тем больше
Слайд 23Play with cut-off
Play with cut-off
 День спортивного журналиста
День спортивного журналиста Этапы разработки базы данных
Этапы разработки базы данных Таблицы в HTML. Web-программирование
Таблицы в HTML. Web-программирование Сложные условия
Сложные условия ВНУТРЕННЯЯ ПАМЯТЬ
ВНУТРЕННЯЯ ПАМЯТЬ Дизайн для соцсетей. Техническое задание
Дизайн для соцсетей. Техническое задание Актуальное прошлое: веб-ресурсы как инструмент сохранения исторической памяти о Великой Отечественной войне
Актуальное прошлое: веб-ресурсы как инструмент сохранения исторической памяти о Великой Отечественной войне Культура интеллектуального труда
Культура интеллектуального труда Роль интернета в жизни современного курсанта
Роль интернета в жизни современного курсанта Понятие растровой графики
Понятие растровой графики Понятие БД, информационной системы
Понятие БД, информационной системы Как устроен компьютер
Как устроен компьютер Как настраивать рекламу в Facebook
Как настраивать рекламу в Facebook Информационно-коммуникационные технологии
Информационно-коммуникационные технологии Растровые графические редакторы
Растровые графические редакторы Advent Empire. Карьерная лестница
Advent Empire. Карьерная лестница Организация подпрограмм. Программирование на яву. Лекция 5
Организация подпрограмм. Программирование на яву. Лекция 5 Передача информации. Схема передачи информации
Передача информации. Схема передачи информации Популяризация внутреннего туризма в РФ через внедрение современных медийных и репортажных технологий
Популяризация внутреннего туризма в РФ через внедрение современных медийных и репортажных технологий Изучение и применение графов, а так же их визуализация. Практическая работа
Изучение и применение графов, а так же их визуализация. Практическая работа Определение машины Тьюринга
Определение машины Тьюринга Текстовая информация
Текстовая информация Покори английский с Lingualeo
Покори английский с Lingualeo Информация и ее свойства
Информация и ее свойства Проект Quna
Проект Quna vis01
vis01 Логические операции
Логические операции Все основные версии GTA. C чего начиналась GTA
Все основные версии GTA. C чего начиналась GTA