- Документальные системы

Содержание
- 2. ОБЩЕЕ На практике информация чаше всего представляется в виде текстовых документов, а не в виде структурированных
- 3. Понятие пертинентность отражает смысловое соответствие документа информационным потребностям пользователя. Релевантность — соответствие содержания документа информационному запросу
- 4. Структура ДИПС В ДИПС входят 4 подсистемы: Ввод и регистрация; Обработка; Хранение; Поиск.
- 5. Подсистема ввода решает следующие вопросы: создание электронных копий (сканирование, распознавание, ввод с клавиатуры); подключение к каналам
- 6. Естественный язык не может быть использован в качестве представления информации из-за следующих недостатков: Многообразие передачи смысла,
- 7. Так как документы поступают в систему в текстовом виде, то они должны быть преобразованы в ИПЯ.
- 8. Модель поиска характеризуется следующими параметрами: Представление документов и запросов; Критерий смыслового соответствия; Методы ранжирования результатов запросов;
- 9. В любой ДИПС присутствуют два типа ошибок: Пропуск цели, т.е. невыдача релевантных документов; Шум — выдача
- 11. Скачать презентацию

Слайд 3Понятие пертинентность отражает смысловое соответствие документа информационным потребностям пользователя.
Релевантность — соответствие содержания документа информационному запросу
Понятие пертинентность отражает смысловое соответствие документа информационным потребностям пользователя.
Релевантность — соответствие содержания документа информационному запросу

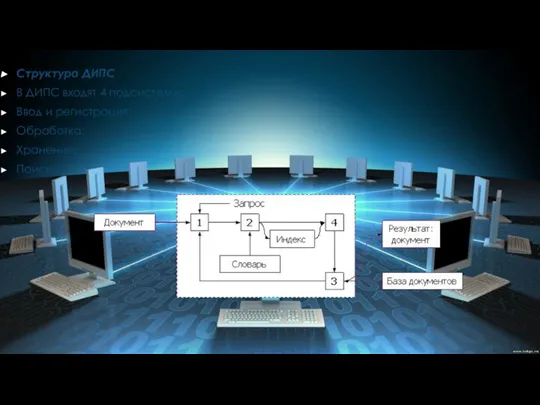
Слайд 4Структура ДИПС
В ДИПС входят 4 подсистемы:
Ввод и регистрация;
Обработка;
Хранение;
Поиск.
Структура ДИПС
В ДИПС входят 4 подсистемы:
Ввод и регистрация;
Обработка;
Хранение;
Поиск.
Слайд 5Подсистема ввода решает следующие вопросы:
создание электронных копий (сканирование, распознавание, ввод с клавиатуры);
подключение к
Подсистема ввода решает следующие вопросы:
создание электронных копий (сканирование, распознавание, ввод с клавиатуры);
подключение к
создание электронных копий (сканирование, распознавание, ввод с клавиатуры);
подключение к

Слайд 6Естественный язык не может быть использован в качестве представления информации из-за следующих
Естественный язык не может быть использован в качестве представления информации из-за следующих

Слайд 7Так как документы поступают в систему в текстовом виде, то они должны
Так как документы поступают в систему в текстовом виде, то они должны

Слайд 8Модель поиска характеризуется следующими параметрами:
Представление документов и запросов;
Критерий смыслового соответствия;
Методы ранжирования результатов
Модель поиска характеризуется следующими параметрами:
Представление документов и запросов;
Критерий смыслового соответствия;
Методы ранжирования результатов

Слайд 9В любой ДИПС присутствуют два типа ошибок:
Пропуск цели, т.е. невыдача релевантных документов;
Шум —
В любой ДИПС присутствуют два типа ошибок:
Пропуск цели, т.е. невыдача релевантных документов;
Шум —

 Данные. Модели данных
Данные. Модели данных GRandapp. Смартфон - это просто
GRandapp. Смартфон - это просто Странствие. Игра платформер-лабиринт с элементами квеста
Странствие. Игра платформер-лабиринт с элементами квеста База данных с характеристиками электросетевых объектов
База данных с характеристиками электросетевых объектов Компьютер и его устройство
Компьютер и его устройство Компьютерные презентации. Настройка гиперссылки
Компьютерные презентации. Настройка гиперссылки Измерение информации
Измерение информации Организация ввода-вывода информации в БД. Лекция 7
Организация ввода-вывода информации в БД. Лекция 7 Требования к интернет-системам
Требования к интернет-системам Безопасность детей в Интернете
Безопасность детей в Интернете Центральный процессор
Центральный процессор Оптимизация Photoshop
Оптимизация Photoshop Одномерные массивы целых чисел. Алгоритмизация и программирование
Одномерные массивы целых чисел. Алгоритмизация и программирование Информационная система федерального института промышленной собственности РФ
Информационная система федерального института промышленной собственности РФ Обработка ошибок
Обработка ошибок Магия и боль ML. Машинное обучение
Магия и боль ML. Машинное обучение 7-1-5
7-1-5 Математические основы информатики. Единицы представления информации. (Тема 3)
Математические основы информатики. Единицы представления информации. (Тема 3) Электронный чек-лист. Способ оценивания
Электронный чек-лист. Способ оценивания Переменные. Сложение чисел: простое решение. 10 класс
Переменные. Сложение чисел: простое решение. 10 класс Scratch. Практическая работа Правильные многоугольники
Scratch. Практическая работа Правильные многоугольники Виды информации
Виды информации Введение в информатику Вещественно-энергетическая картина мира
Введение в информатику Вещественно-энергетическая картина мира Система типов C#
Система типов C# Lecture_02_Python
Lecture_02_Python Программирование. Введение (
Программирование. Введение ( Презентация на тему Разветвляющийся алгоритм
Презентация на тему Разветвляющийся алгоритм  Dota 2
Dota 2