- Оптимизация обновления информационной базы. Информация для технических специалистов

Содержание
- 2. Информация для технических специалистов Проблемы существовавшего механизма обновления Долго проходит монопольный этап обновления на больших базах
- 3. Информация для технических специалистов Решение проблем Радикальное сокращение количества монопольных обработчиков обновления если раньше монопольно обновлялась
- 4. Информация для технических специалистов Параллельный режим выполнения отложенных обработчиков обновления Раньше все обработчики выполнялись последовательно Порция
- 5. Информация для технических специалистов Параллельный режим выполнения отложенных обработчиков обновления Теперь обработчики выполняются параллельно Порция 1
- 6. Информация для технических специалистов Параллельный режим выполнения отложенных обработчиков обновления Параллельный режим выполнения вкупе с правилом
- 7. Информация для технических специалистов Очереди отложенной обработки данных По разным причинам написать обработчики полностью независимыми не
- 8. Информация для технических специалистов Очереди отложенной обработки данных Особенности использования очередей отложенной обработки данных очереди присваиваются
- 9. Информация для технических специалистов Блокировка необновленных данных от изменения На время отложенного обновления блокируются формы объектов
- 10. Информация для технических специалистов Управление процессом обработки данных Повышение приоритета обновления по умолчанию перед обработкой очередной
- 11. Информация для технических специалистов Управление процессом обработки данных Появилась возможность повышать приоритет отдельных обработчиков данных при
- 12. Информация для технических специалистов Особенности обновления РИБ (только в УТ 11) Полный РИБ обновляется конфигурация главного
- 13. Информация для технических специалистов Особенности обновления РИБ (только в УТ 11) РИБ с фильтрами – отличия
- 14. Информация для технических специалистов Заключение По данным наших замеров (в т.ч. на базах предоставленных пользователями), монопольная
- 15. Информация для технических специалистов Планы по развитию механизма Большая часть доработок механизмов обновавления сейчас реализована по
- 17. Скачать презентацию
Слайд 2Информация для технических специалистов
Проблемы существовавшего механизма обновления
Долго проходит монопольный этап обновления
на больших
Информация для технических специалистов
Проблемы существовавшего механизма обновления
Долго проходит монопольный этап обновления
на больших

Слайд 3Информация для технических специалистов
Решение проблем
Радикальное сокращение количества монопольных обработчиков обновления
если раньше монопольно
Информация для технических специалистов
Решение проблем
Радикальное сокращение количества монопольных обработчиков обновления
если раньше монопольно

Слайд 4Информация для технических специалистов
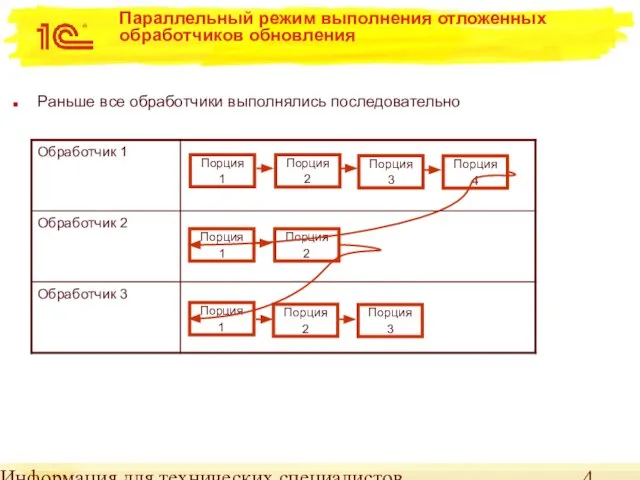
Параллельный режим выполнения отложенных обработчиков обновления
Раньше все обработчики выполнялись
Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Раньше все обработчики выполнялись
Слайд 5Информация для технических специалистов
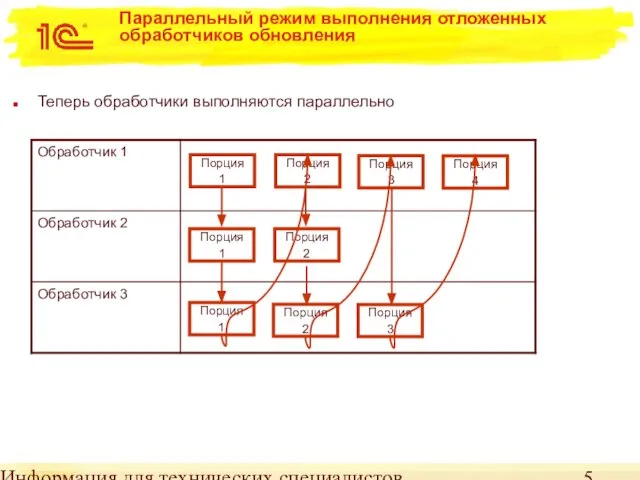
Параллельный режим выполнения отложенных обработчиков обновления
Теперь обработчики выполняются параллельно
Порция
Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Теперь обработчики выполняются параллельно
Порция
Слайд 6Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Параллельный режим выполнения вкупе
Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Параллельный режим выполнения вкупе

Слайд 7Информация для технических специалистов
Очереди отложенной обработки данных
По разным причинам написать обработчики полностью
Информация для технических специалистов
Очереди отложенной обработки данных
По разным причинам написать обработчики полностью

Слайд 8Информация для технических специалистов
Очереди отложенной обработки данных
Особенности использования очередей отложенной обработки данных
очереди
Информация для технических специалистов
Очереди отложенной обработки данных
Особенности использования очередей отложенной обработки данных
очереди

Слайд 9Информация для технических специалистов
Блокировка необновленных данных от изменения
На время отложенного обновления блокируются
формы
Информация для технических специалистов
Блокировка необновленных данных от изменения
На время отложенного обновления блокируются
формы

Слайд 10Информация для технических специалистов
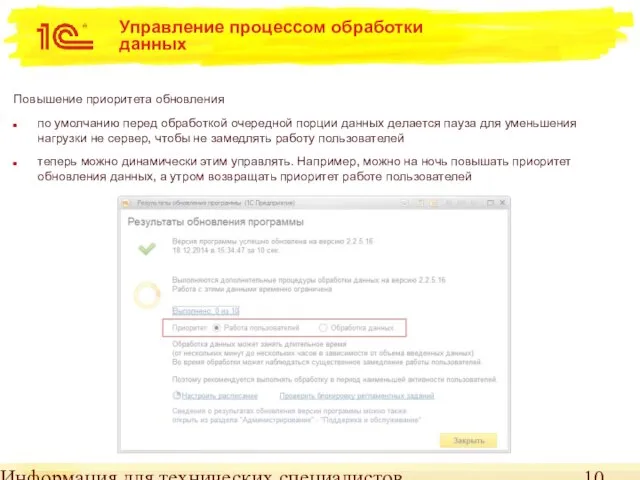
Управление процессом обработки данных
Повышение приоритета обновления
по умолчанию перед обработкой
Информация для технических специалистов
Управление процессом обработки данных
Повышение приоритета обновления
по умолчанию перед обработкой
Слайд 11Информация для технических специалистов
Управление процессом обработки данных
Появилась возможность повышать приоритет отдельных обработчиков
Информация для технических специалистов
Управление процессом обработки данных
Появилась возможность повышать приоритет отдельных обработчиков

Слайд 12Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
Полный РИБ
обновляется конфигурация
Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
Полный РИБ
обновляется конфигурация

Слайд 13Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
РИБ с фильтрами
Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
РИБ с фильтрами

Слайд 14Информация для технических специалистов
Заключение
По данным наших замеров (в т.ч. на базах предоставленных
Информация для технических специалистов
Заключение
По данным наших замеров (в т.ч. на базах предоставленных

Слайд 15Информация для технических специалистов
Планы по развитию механизма
Большая часть доработок механизмов обновавления сейчас
Информация для технических специалистов
Планы по развитию механизма
Большая часть доработок механизмов обновавления сейчас

 Системы счисления
Системы счисления Как работать с 1с не в локальной сети
Как работать с 1с не в локальной сети Комплексное продвижение групп ВКонтакте
Комплексное продвижение групп ВКонтакте Средства массовой информации, которыми я интересуюсь
Средства массовой информации, которыми я интересуюсь Оформление библиографического описания
Оформление библиографического описания Основы передачи дискретных сообщений. Лекция 3
Основы передачи дискретных сообщений. Лекция 3 Место и роль ПКП
Место и роль ПКП Общая постановка и алгоритм решения задач динамического программирования. Тема 1.5
Общая постановка и алгоритм решения задач динамического программирования. Тема 1.5 ShotOut 3D
ShotOut 3D Человек и информация
Человек и информация Моделирование в среде графического редактора (урок информатики)
Моделирование в среде графического редактора (урок информатики) Циклы по переменной. Программирование на языке Python
Циклы по переменной. Программирование на языке Python Видеоблогинг. Мастер-класс
Видеоблогинг. Мастер-класс Пэкмен. Обзор. Скайрим – моя жизнь
Пэкмен. Обзор. Скайрим – моя жизнь Процесс разработки программного обеспечения
Процесс разработки программного обеспечения Операционная система
Операционная система Вещественные числа
Вещественные числа Adobe Photoshop
Adobe Photoshop Региональная геоинформационная система Новосибирской области
Региональная геоинформационная система Новосибирской области Разработка программного модуля для визуализации и аналитики данных
Разработка программного модуля для визуализации и аналитики данных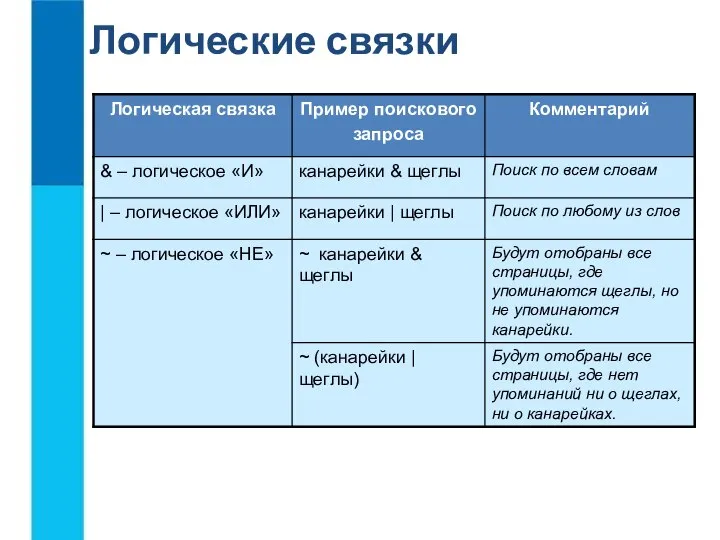 Круги Эйлера
Круги Эйлера Instrukcja instalacji programu Maestro System operacyjny Windows
Instrukcja instalacji programu Maestro System operacyjny Windows Градиент, фон, фильтр
Градиент, фон, фильтр Текстовый процессор Writer
Текстовый процессор Writer Буккроссинг - новое увлечение современных людей
Буккроссинг - новое увлечение современных людей Операторы цикла
Операторы цикла Интерактивный тест по информатике
Интерактивный тест по информатике Импорт документов. Платежное поручение с автоопределением формата
Импорт документов. Платежное поручение с автоопределением формата