- Информационные системы обработки данных

Содержание
- 2. Системы управления базами данных Система управления базами данных (СУБД) — это комплекс программных средств, предназначенный для
- 3. В основе любой БД лежит модель данных , включающая в себя: множество формальных объектов, с помощью
- 4. По типу используемой модели можно выделить базы данных : Иерархическая Сетевая Реляционная В последние годы активно
- 5. Иерархическая модель данных Если в модели каждый порожденный элемент имеет не более одного исходного, то такая
- 6. Иерархическая модель данных Тип данных «дерево»(составной из подтипов, каждый из которых является, в свою очередь, типом
- 7. Иерархическая БД представляет собой иерархически организованный набор типов «запись»
- 8. Для организации данных могут использоваться следующие группы методов: представление линейным списком с последовательным распределением памяти (адресная
- 9. Достоинства иерархической модели : эффективное использование памяти ЭВМ ; неплохие показатели времени выполнения основных операций над
- 10. Сетевая модель Если в модели каждый порожденный элемент может иметь более одного исходного, то такая модель
- 11. Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для
- 12. Операции манипулирования данными : поиск записи в БД; переход от предка к первому потомку; переход от
- 13. Достоинством сетевой модели данных является: возможность эффективной реализации по показателям затрат памяти и оперативности сетевая модель
- 14. Реляционная модель данных
- 15. Операции работы с данными: объединение, пересечение, разность, произведение, ограничение и соединение. Таблица (отношение) имеет строки (записи)
- 16. Пример реляционной базы (начальная таблица )
- 17. I нормальная форма II нормальная форма
- 18. III нормальная форма базы данных
- 19. IV нормальная форма базы данных
- 20. Достоинства реляционной модели Развитая теория реляционной модели данных. Возможность сведения иерархической и сетевой модели данных к
- 21. Недостатки реляционной модели Разработка программного обеспечения приходится проектировать свою задачу не в терминах ПрО (самой по
- 22. Объектно-ориентированная модель ODMG-93 (Object Database Management Group) Структура графически представима в виде дерева, узлами которого являются
- 23. Объектно-ориентированная БД
- 24. Методы манипулирования данными: применяются логические операции, усиленные механизмами инкапсуляции, наследования и полиморфизма создание и модификация БД
- 25. Достоинство объектно-ориентированной модели в сравнении с реляционной : возможность отображения информации о сложных взаимосвязях объектов; позволяет
- 26. Объектно-реляционный подход (ORM – Object Relation Mapping Отличие между объектно-ориентированными и объектно-реляционными БД заключается в том,
- 27. Структура хранилища данных Свойства хранилищ данных Область применения хранилищ данных Data Mining – технология аналитической обработки
- 28. Хранилище данных (ХД) — это предметно-ориентированное, интегрированное, привязанное ко времени и неизменяемое собрание данных для поддержки
- 29. Структура гиперкуба Измерение — это множество, образующее одну из граней гиперкуба. Значение — данные, которые подвергаются
- 30. Сечение – формируется подмножество гиперкуба, в котором значение одного или более измерений фиксиро-вано. Вращение – изменение
- 31. ХД в зависимости от размера делятся : Малые (до 106 ячеек данных) Средние (до 108) Крупные
- 32. MOLAP Используют при небольшой базе данных и стабильном наборе измерений. Преимущество: быстрое чтение и поиск данных
- 33. Основные свойства хранилищ данных: Ориентация на ПрО: данные в хранилище организованы вокруг существенных аспектов прикладной деятельности;
- 34. Поддержка хронологии: хранилище можно рассматривать как набор моментальных снимков состояния данных так, что атрибут времени всегда
- 35. Область применения хранилищ данных для своевременного обеспечения аналитиков всей информацией, необходимой для выработки решений; для создания
- 36. Схема взаимодействия хранилища данных с клиентскими приложениями
- 37. Data Mining – это технология выявления скрытых (ранее неизвестных) взаимосвязей внутри больших объемов данных. Data Mining
- 38. Системы поддержки принятия решений(СППР) СППР – являются человеко-машинными объектами, которые позволяют лицам, принимающим решения (ЛПР), использовать
- 39. Функции СППР : помощь ЛПР при анализе обстановки (ситуации) и ограничений, накладываемых внешней средой; выявление предпочтений
- 40. Выработка решений в этих системах происходит в результате итерационного процесса, в котором участвуют: система ППР в
- 41. Основные компоненты информационной технологии поддержки принятия решений
- 43. Скачать презентацию
Слайд 2Системы управления базами данных
Система управления базами данных (СУБД) — это комплекс программных
Системы управления базами данных
Система управления базами данных (СУБД) — это комплекс программных

Слайд 3В основе любой БД лежит модель данных , включающая в себя:
множество формальных
В основе любой БД лежит модель данных , включающая в себя:
множество формальных

Слайд 4По типу используемой модели можно выделить базы данных :
Иерархическая
Сетевая
Реляционная
В последние годы активно
По типу используемой модели можно выделить базы данных :
Иерархическая
Сетевая
Реляционная
В последние годы активно

Слайд 5Иерархическая модель данных
Если в модели каждый порожденный элемент имеет не более одного
Иерархическая модель данных
Если в модели каждый порожденный элемент имеет не более одного
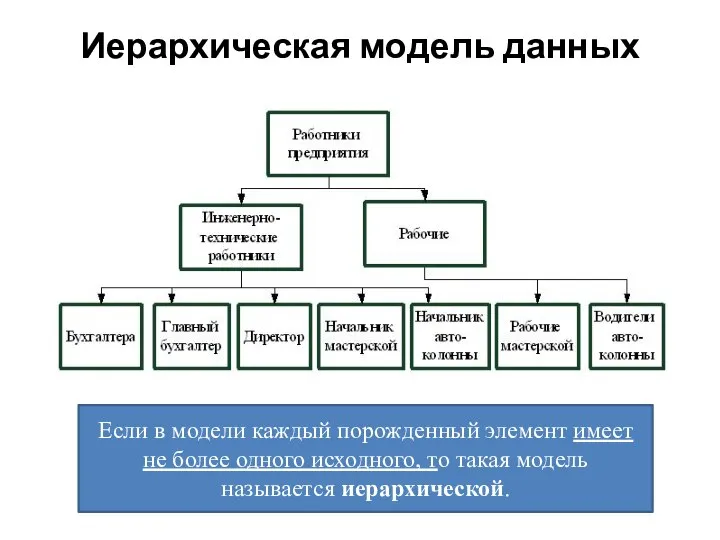
Слайд 6Иерархическая модель данных
Тип данных «дерево»(составной из подтипов, каждый из которых является, в
Иерархическая модель данных
Тип данных «дерево»(составной из подтипов, каждый из которых является, в

Слайд 7Иерархическая БД представляет собой иерархически организованный набор типов «запись»
Иерархическая БД представляет собой иерархически организованный набор типов «запись»
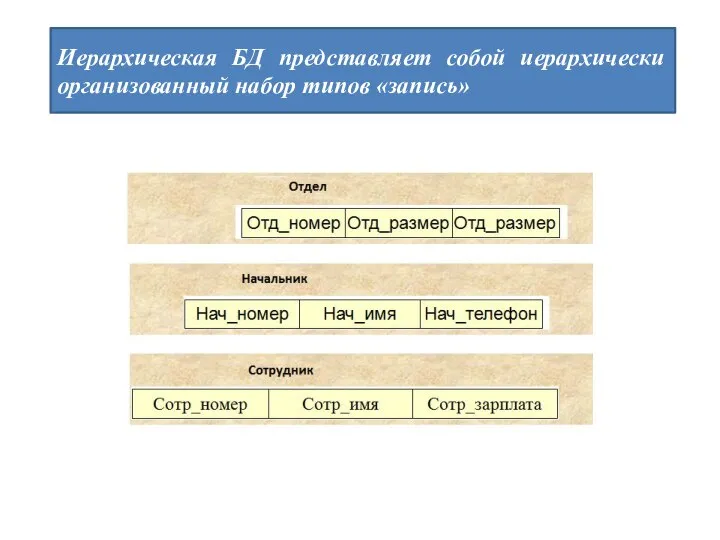
Слайд 8Для организации данных могут использоваться следующие группы методов:
представление линейным списком с последовательным
представление линейным списком с последовательным

Слайд 9Достоинства иерархической модели :
эффективное использование памяти ЭВМ ;
неплохие показатели времени выполнения
Достоинства иерархической модели :
эффективное использование памяти ЭВМ ;
неплохие показатели времени выполнения

Слайд 10Сетевая модель
Если в модели каждый порожденный элемент может иметь более одного
Сетевая модель
Если в модели каждый порожденный элемент может иметь более одного
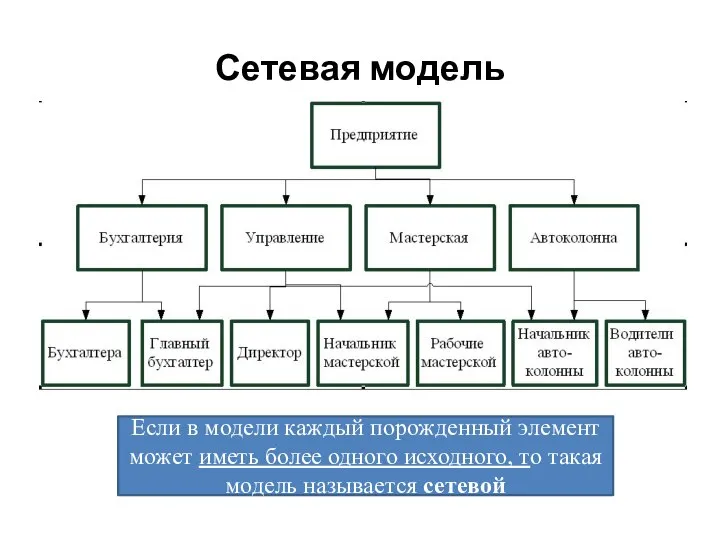
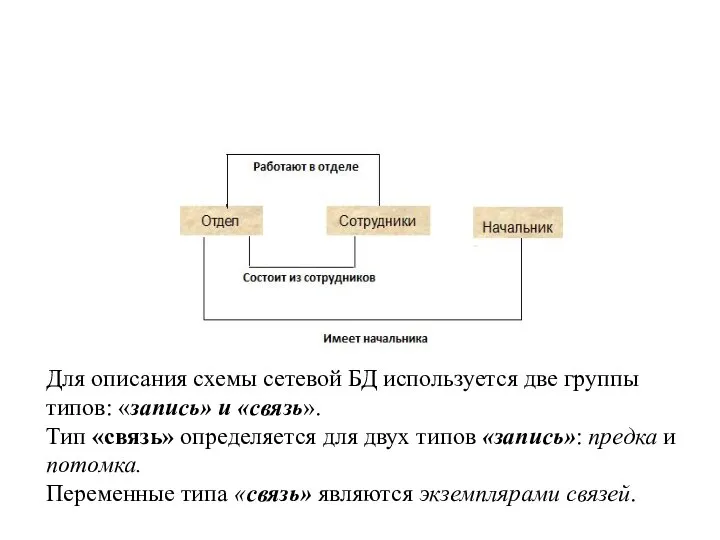
Слайд 11Для описания схемы сетевой БД используется две группы типов: «запись» и «связь».
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь».
Слайд 12Операции манипулирования данными :
поиск записи в БД;
переход от предка к первому потомку;
переход
Операции манипулирования данными :
поиск записи в БД;
переход от предка к первому потомку;
переход

Слайд 13Достоинством сетевой модели данных является:
возможность эффективной реализации по показателям затрат памяти
Достоинством сетевой модели данных является:
возможность эффективной реализации по показателям затрат памяти

Слайд 14Реляционная модель данных
Реляционная модель данных
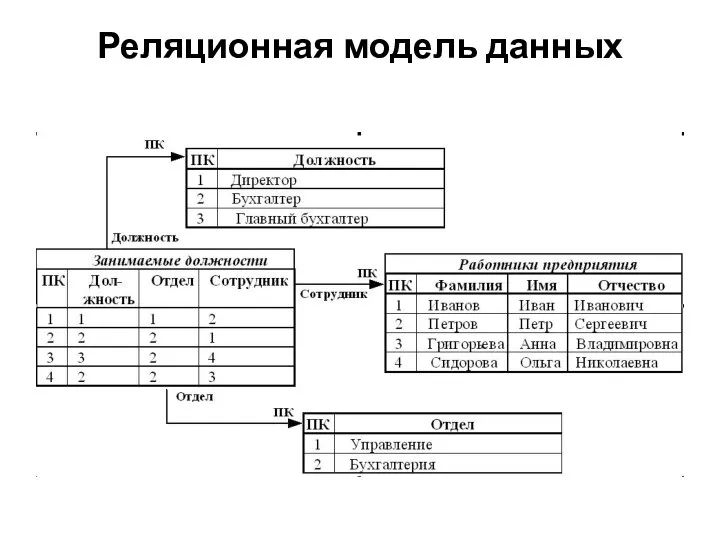
Слайд 15Операции работы с данными: объединение, пересечение, разность, произведение, ограничение и соединение.
Таблица (отношение)
Операции работы с данными: объединение, пересечение, разность, произведение, ограничение и соединение.
Таблица (отношение)

Слайд 16Пример реляционной базы
(начальная таблица )
Пример реляционной базы
(начальная таблица )
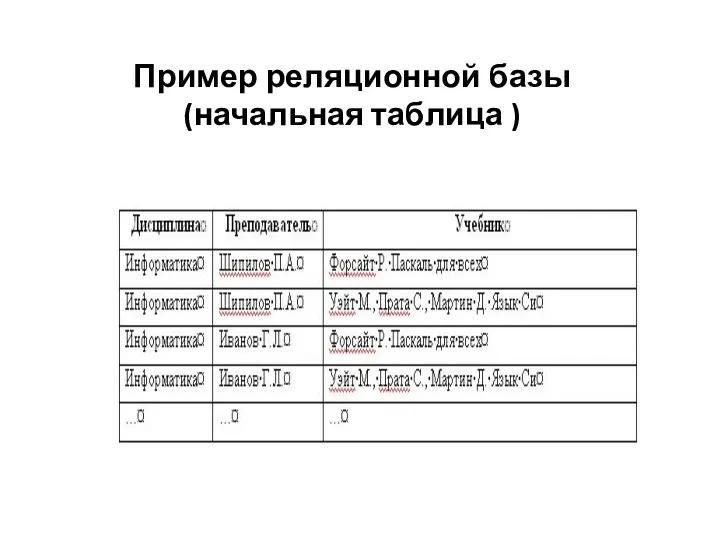
Слайд 17
I нормальная форма
II нормальная форма
I нормальная форма
II нормальная форма
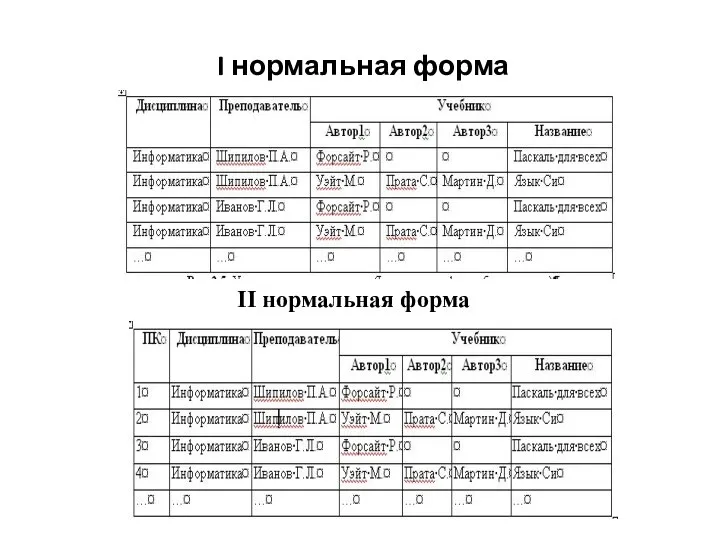
Слайд 18III нормальная форма базы данных
III нормальная форма базы данных
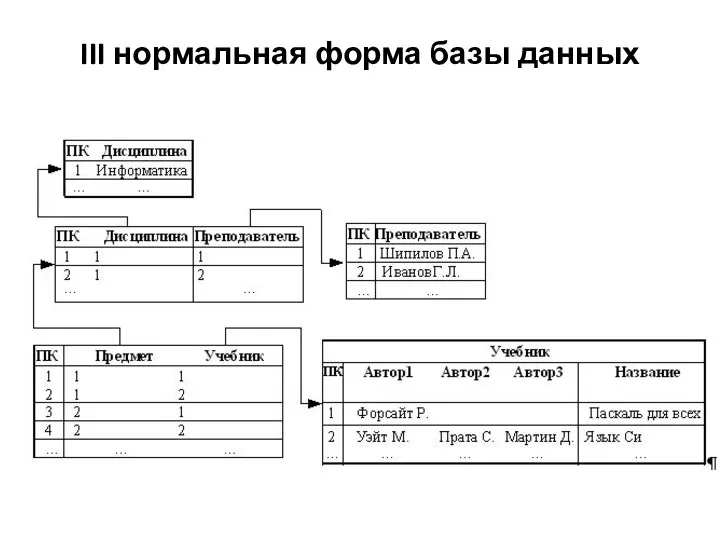
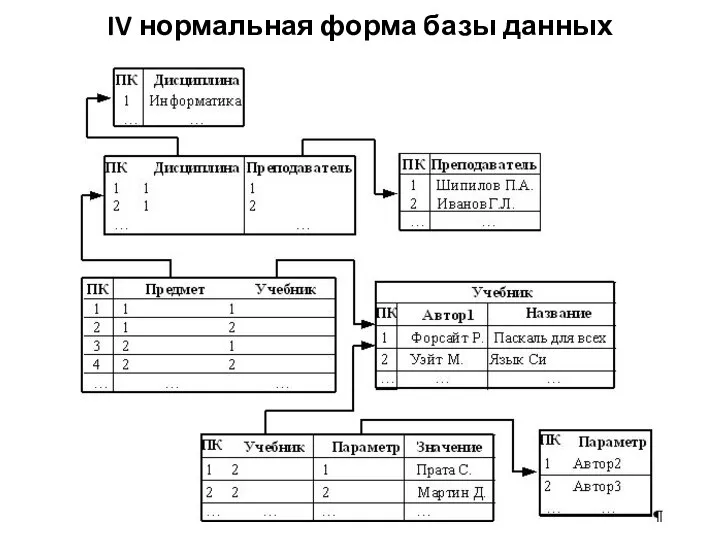
Слайд 19IV нормальная форма базы данных
IV нормальная форма базы данных
Слайд 20Достоинства реляционной модели
Развитая теория реляционной модели данных.
Возможность сведения иерархической и сетевой модели
Достоинства реляционной модели
Развитая теория реляционной модели данных.
Возможность сведения иерархической и сетевой модели

Слайд 21Недостатки реляционной модели
Разработка программного обеспечения приходится проектировать свою задачу не в
Недостатки реляционной модели
Разработка программного обеспечения приходится проектировать свою задачу не в

Слайд 22Объектно-ориентированная модель
ODMG-93 (Object Database Management Group)
Структура графически представима в виде дерева, узлами
Объектно-ориентированная модель
ODMG-93 (Object Database Management Group)
Структура графически представима в виде дерева, узлами

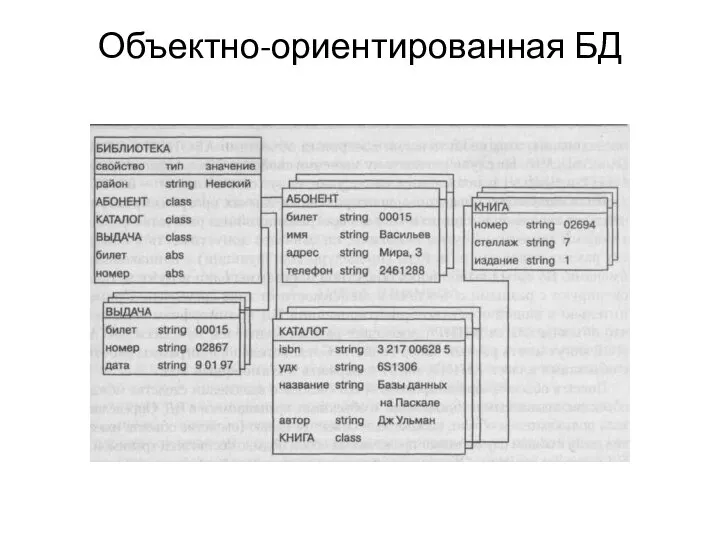
Слайд 23Объектно-ориентированная БД
Объектно-ориентированная БД
Слайд 24Методы манипулирования данными:
применяются логические операции, усиленные механизмами инкапсуляции, наследования и полиморфизма
создание и
Методы манипулирования данными:
применяются логические операции, усиленные механизмами инкапсуляции, наследования и полиморфизма
создание и

Слайд 25Достоинство объектно-ориентированной
модели в сравнении с реляционной :
возможность отображения информации о
модели в сравнении с реляционной :
возможность отображения информации о

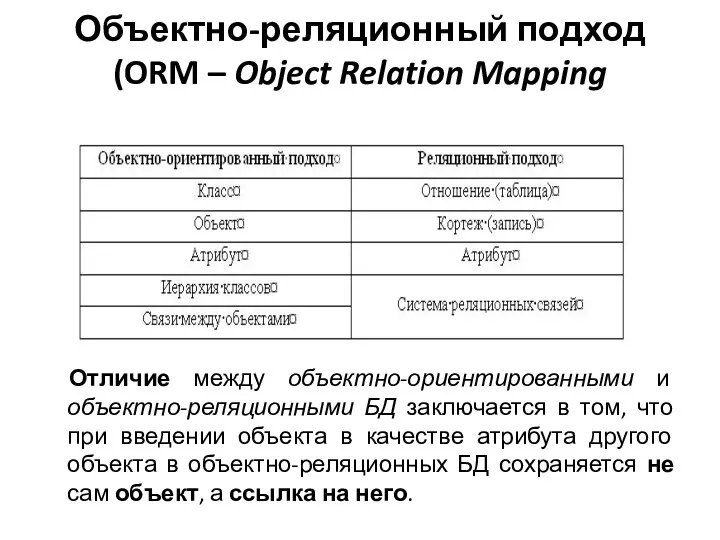
Слайд 26Объектно-реляционный подход (ORM – Object Relation Mapping
Отличие между объектно-ориентированными и объектно-реляционными БД
Объектно-реляционный подход (ORM – Object Relation Mapping
Отличие между объектно-ориентированными и объектно-реляционными БД
Слайд 27Структура хранилища данных
Свойства хранилищ данных
Область применения хранилищ данных
Data Mining – технология аналитической
Структура хранилища данных
Свойства хранилищ данных
Область применения хранилищ данных
Data Mining – технология аналитической

Слайд 28Хранилище данных (ХД) — это предметно-ориентированное, интегрированное, привязанное ко времени и неизменяемое

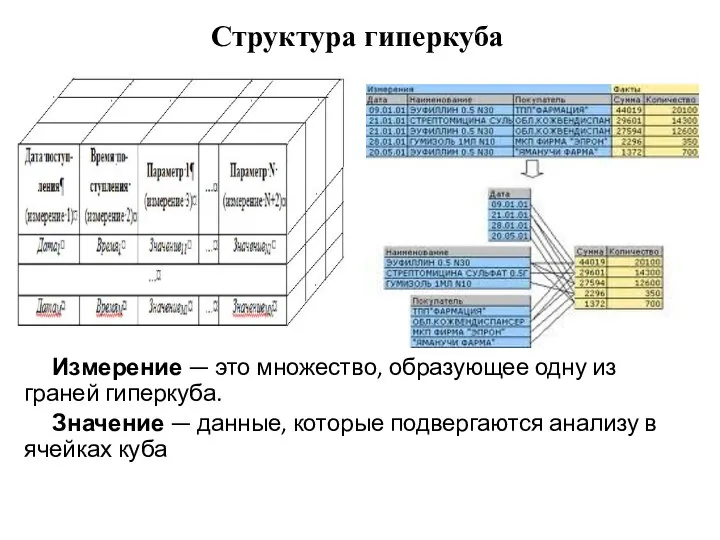
Слайд 29Структура гиперкуба
Измерение — это множество, образующее одну из граней гиперкуба.
Значение — данные,
Структура гиперкуба
Измерение — это множество, образующее одну из граней гиперкуба.
Значение — данные,
Слайд 30Сечение – формируется подмножество гиперкуба, в котором значение одного или более измерений
Сечение – формируется подмножество гиперкуба, в котором значение одного или более измерений
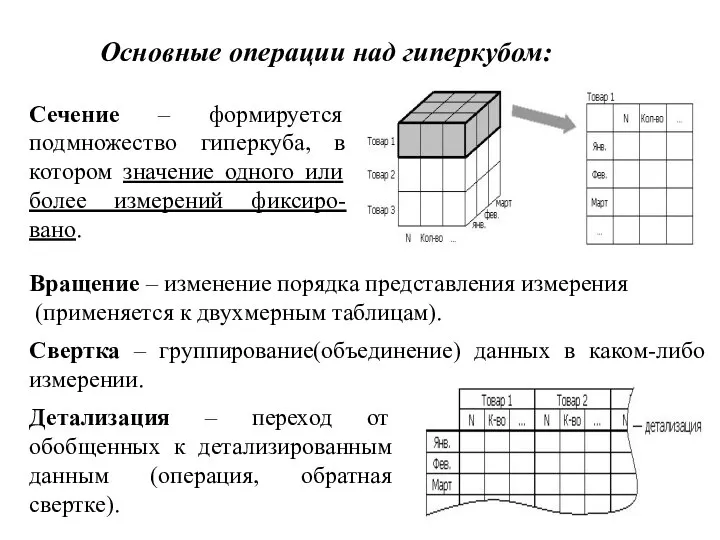
Слайд 31ХД в зависимости от размера делятся :
Малые (до 106 ячеек данных)
Средние
ХД в зависимости от размера делятся :
Малые (до 106 ячеек данных)
Средние

Слайд 32MOLAP
Используют при небольшой базе данных и стабильном наборе измерений.
Преимущество: быстрое
Используют при небольшой базе данных и стабильном наборе измерений. Преимущество: быстрое

Слайд 33Основные свойства хранилищ данных:
Ориентация на ПрО:
данные в хранилище организованы вокруг существенных
Основные свойства хранилищ данных:
Ориентация на ПрО:
данные в хранилище организованы вокруг существенных

Слайд 34Поддержка хронологии:
хранилище можно рассматривать как набор моментальных снимков состояния данных так,
Поддержка хронологии:
хранилище можно рассматривать как набор моментальных снимков состояния данных так,

Слайд 35Область применения хранилищ данных
для своевременного обеспечения аналитиков всей информацией, необходимой для выработки
Область применения хранилищ данных
для своевременного обеспечения аналитиков всей информацией, необходимой для выработки

Слайд 36Схема взаимодействия хранилища данных с клиентскими приложениями
Схема взаимодействия хранилища данных с клиентскими приложениями
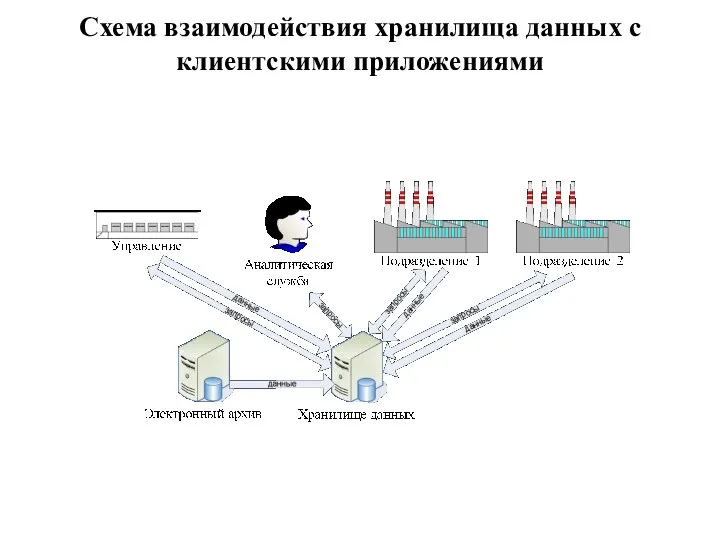
Слайд 37Data Mining – это технология выявления скрытых (ранее неизвестных) взаимосвязей внутри больших
Data Mining – это технология выявления скрытых (ранее неизвестных) взаимосвязей внутри больших

Слайд 38Системы поддержки
принятия решений(СППР)
СППР – являются человеко-машинными объектами, которые позволяют лицам, принимающим
Системы поддержки
принятия решений(СППР)
СППР – являются человеко-машинными объектами, которые позволяют лицам, принимающим

Слайд 39 Функции СППР :
помощь ЛПР при анализе обстановки (ситуации) и ограничений, накладываемых
Функции СППР :
помощь ЛПР при анализе обстановки (ситуации) и ограничений, накладываемых

Слайд 40Выработка решений в этих системах происходит в результате итерационного процесса, в котором
Выработка решений в этих системах происходит в результате итерационного процесса, в котором
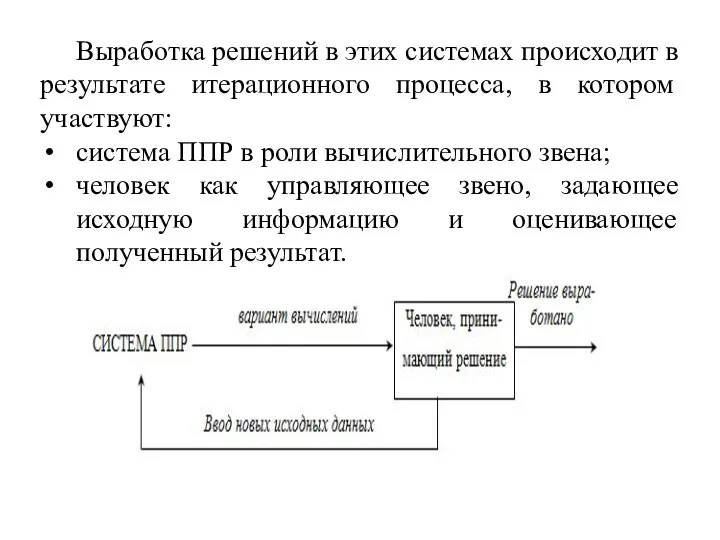
Слайд 41Основные компоненты информационной
технологии поддержки принятия решений
Основные компоненты информационной
технологии поддержки принятия решений
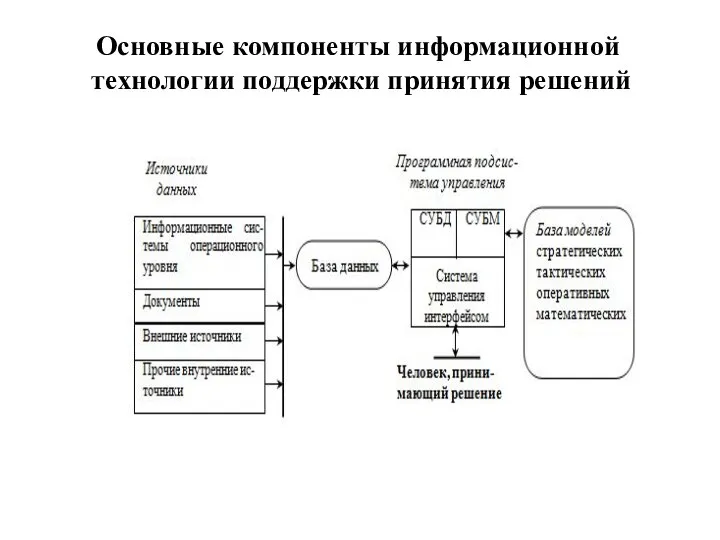
 前期准备
前期准备 Coral DRAW. Линия и объекты
Coral DRAW. Линия и объекты Школа::Кода Основы программирования на языке Python. 7 занятие
Школа::Кода Основы программирования на языке Python. 7 занятие Алгоритм по настройкам интернет
Алгоритм по настройкам интернет Учебник Adobe Photoshop. Первое знакомство
Учебник Adobe Photoshop. Первое знакомство Сказ о доблестном Смайл-царевиче и Интернет-страшилищах Поганых
Сказ о доблестном Смайл-царевиче и Интернет-страшилищах Поганых Разработка методiв та засобiв сервiсу генерацii вiдеконтенту на основi фiльтрiв
Разработка методiв та засобiв сервiсу генерацii вiдеконтенту на основi фiльтрiв Компьютер – универсальная машина для работы с информацией
Компьютер – универсальная машина для работы с информацией Технология производства программных продуктов и услуг. Детальное проектирование программ
Технология производства программных продуктов и услуг. Детальное проектирование программ Математические технологии моделирования вирусной динамики
Математические технологии моделирования вирусной динамики Презентация на тему Основные понятия компьютерной графики
Презентация на тему Основные понятия компьютерной графики  Создание авторской настольной игры
Создание авторской настольной игры Информационная безопасность электронных платежных систем
Информационная безопасность электронных платежных систем Поставка игрушек в детские сады
Поставка игрушек в детские сады Презентация на тему Обучение Word'у
Презентация на тему Обучение Word'у  Предложения отдела научно-методического обеспечения НИР и аспирантуры по внесению изменений на сайт ФБУ ВНИИЛМ
Предложения отдела научно-методического обеспечения НИР и аспирантуры по внесению изменений на сайт ФБУ ВНИИЛМ Файл и файловая система
Файл и файловая система Функциональные типы и описание функций. Примеры
Функциональные типы и описание функций. Примеры Системы счисления. Основные приёмы
Системы счисления. Основные приёмы Двоичное кодирование. Ключевые слова
Двоичное кодирование. Ключевые слова Скины 187-го легиона
Скины 187-го легиона IMEI Write Operational guidance
IMEI Write Operational guidance Знаменитые библиотеки мира
Знаменитые библиотеки мира Кладбище рядом. Взаимный фарм хонора
Кладбище рядом. Взаимный фарм хонора Yandex. Zen as learning instrument
Yandex. Zen as learning instrument Устройства ввода информации в ПК
Устройства ввода информации в ПК Двоичное кодирование текста. ОГЭ
Двоичное кодирование текста. ОГЭ Как найти результаты анализа
Как найти результаты анализа