Интеллектуальные методы обнаружения аномалий функционирования автоматизированных систем управления техническими процессами
- Интеллектуальные методы обнаружения аномалий функционирования автоматизированных систем управления техническими процессами

Содержание
- 2. Что такое аномалии? Перед началом, важно определиться с типами аномалий: 1. Точечные аномалии. Единичный случай аномального
- 3. Простые статистические методы Простейшим способом обнаружения аномалий является выделение отклонений от обычных статистических параметров распределения, таких
- 4. Минусы статистических подходов Статистические методы плохо работают в следующих случаях: Данные содержат шум близкий к аномальному,
- 5. Поиск аномалий, основанный на плотности Аномалии обнаруживаются из предположения, что схожие данные должны находится рядом. Метрики
- 6. Кластеризация Ещё одной популярной техникой является кластеризация, основанная на обучении без учителя. Полагается, что схожие точки
- 7. Local Outlier Factor Фактор локального выброса основан на понятии локальной плотности, которая определяется k ближайшими соседями,
- 8. Метод опорных векторов(SVM) Основная идея метода — перевод исходных векторов в пространство более высокой размерности и
- 9. Изолирующий лес Ещё одним эффективным способом поиска аномалий является модифицированные алгоритм случайного леса. Такой лес случайно
- 11. Скачать презентацию
Слайд 2Что такое аномалии?
Перед началом, важно определиться с типами аномалий:
1. Точечные аномалии. Единичный
Что такое аномалии?
Перед началом, важно определиться с типами аномалий:
1. Точечные аномалии. Единичный

Слайд 3Простые статистические методы
Простейшим способом обнаружения аномалий является выделение отклонений от обычных статистических
Простые статистические методы
Простейшим способом обнаружения аномалий является выделение отклонений от обычных статистических
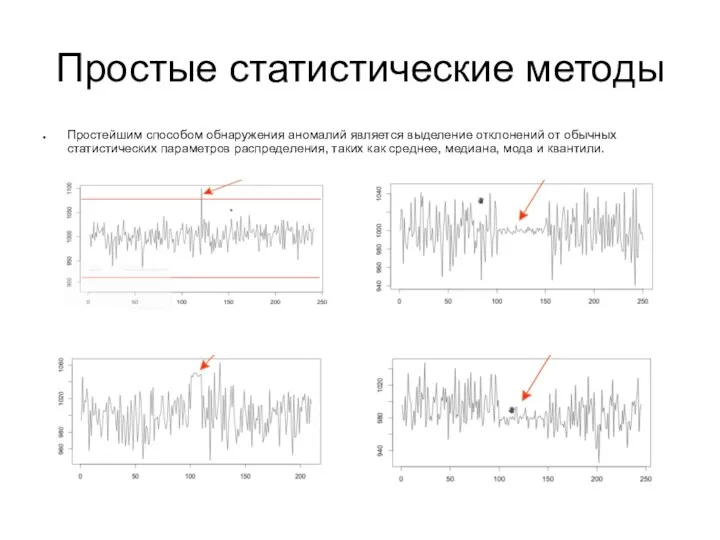
Слайд 4Минусы статистических подходов
Статистические методы плохо работают в следующих случаях:
Данные содержат шум близкий
Минусы статистических подходов
Статистические методы плохо работают в следующих случаях:
Данные содержат шум близкий

Слайд 5Поиск аномалий, основанный на плотности
Аномалии обнаруживаются из предположения, что схожие данные должны
Поиск аномалий, основанный на плотности
Аномалии обнаруживаются из предположения, что схожие данные должны
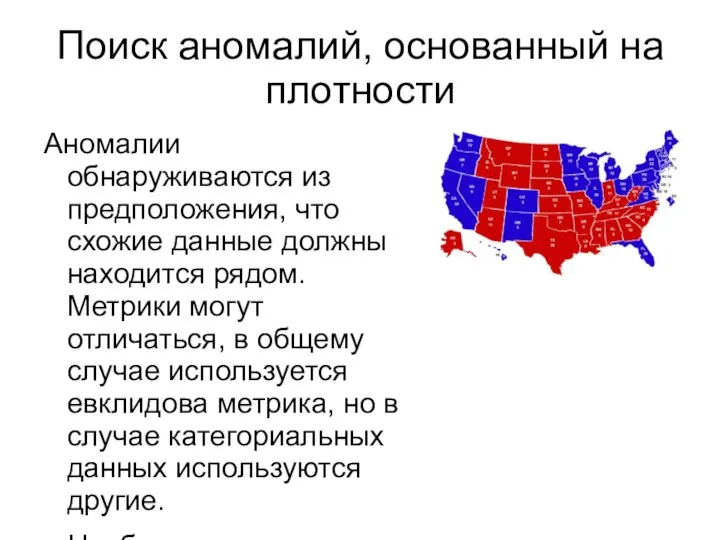
Слайд 6Кластеризация
Ещё одной популярной техникой является кластеризация, основанная на обучении без учителя. Полагается,
Кластеризация
Ещё одной популярной техникой является кластеризация, основанная на обучении без учителя. Полагается,

Слайд 7Local Outlier Factor
Фактор локального выброса основан на понятии локальной плотности, которая определяется
Local Outlier Factor
Фактор локального выброса основан на понятии локальной плотности, которая определяется

Слайд 8Метод опорных векторов(SVM)
Основная идея метода — перевод исходных векторов в пространство более
Метод опорных векторов(SVM)
Основная идея метода — перевод исходных векторов в пространство более

Слайд 9Изолирующий лес
Ещё одним эффективным способом поиска аномалий является модифицированные алгоритм случайного леса.
Изолирующий лес
Ещё одним эффективным способом поиска аномалий является модифицированные алгоритм случайного леса.

 Работа с объектами в векторных графических редакторах
Работа с объектами в векторных графических редакторах День библиотек
День библиотек Трояны. Программы-шпионы
Трояны. Программы-шпионы Наследование
Наследование Oddly Unsatisfying Video
Oddly Unsatisfying Video Типы и структуры данных в .Net
Типы и структуры данных в .Net Форматирование текста (шрифт)
Форматирование текста (шрифт) Взлом компьютерных систем с помощью вирусов
Взлом компьютерных систем с помощью вирусов Изучение и применение графов, а так же их визуализация. Практическая работа
Изучение и применение графов, а так же их визуализация. Практическая работа Памятка менеджеру турнира
Памятка менеджеру турнира Особенности программирования в различных командных интерфейсах
Особенности программирования в различных командных интерфейсах Маски выделения. Photoshop
Маски выделения. Photoshop Проектирование реляционной базы данных. Основные принципы проектирования
Проектирование реляционной базы данных. Основные принципы проектирования Программа виртуализации VirtualBox
Программа виртуализации VirtualBox WB Транзит
WB Транзит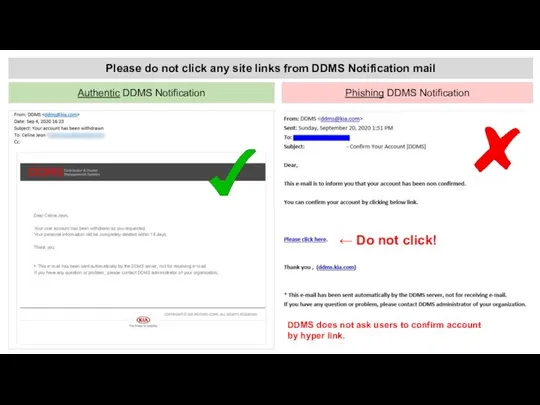 DDMS Phishing Notification update
DDMS Phishing Notification update Пошаговая инструкция по созданию презентации в PowerPoint
Пошаговая инструкция по созданию презентации в PowerPoint Работа с событиями аплета
Работа с событиями аплета Алгоритм и его свойства. Программирование на языке С++
Алгоритм и его свойства. Программирование на языке С++ lesson11
lesson11 Цветовые модели и их виды
Цветовые модели и их виды Я досліджую світ. Інформатика
Я досліджую світ. Інформатика Ребрендинг медиасистемы Республики Татарстан
Ребрендинг медиасистемы Республики Татарстан Методы моделирования и расчета свайных фундаментов в SCAD Office
Методы моделирования и расчета свайных фундаментов в SCAD Office Генератор фракталов
Генератор фракталов Неоднозначные грамматики. Способы устранения неоднозначности
Неоднозначные грамматики. Способы устранения неоднозначности Информация и информационные технологии
Информация и информационные технологии Языки программирования. Единый язык
Языки программирования. Единый язык