- Кодирование символов: ASCII, KOI8, UNICODE

Содержание
- 2. Все, что мы видим на экране монитора — это символы. Для вывода каждого символа нужен машинный
- 3. ASCII Для отображения всех этих символов была создана таблитца ASCII (англ. American Standard Code for Information
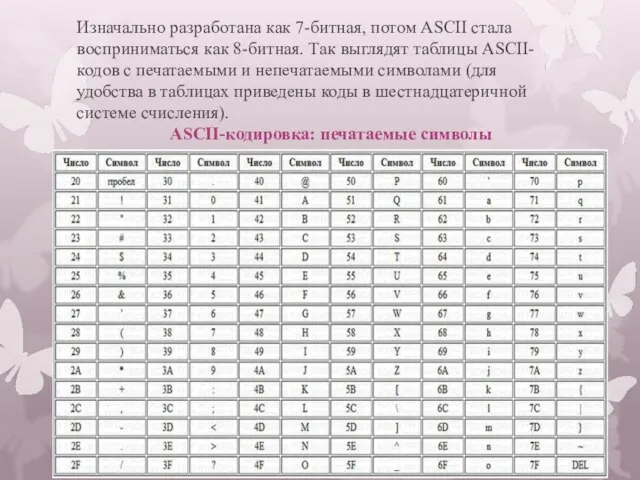
- 4. Изначально разработана как 7-битная, потом ASCII стала восприниматься как 8-битная. Так выглядят таблицы ASCII-кодов с печатаемыми
- 5. Дальнейшее развитие привело к появлению понятия «кодовая страница», т.е. набор из 256 символов для определения группы
- 6. КОИ-8 KOI8 — восьмибитовая ASCII-совместимая кодовая страница, созданная для кодирования букв кириллических алфавитов. В КОИ-8 символы
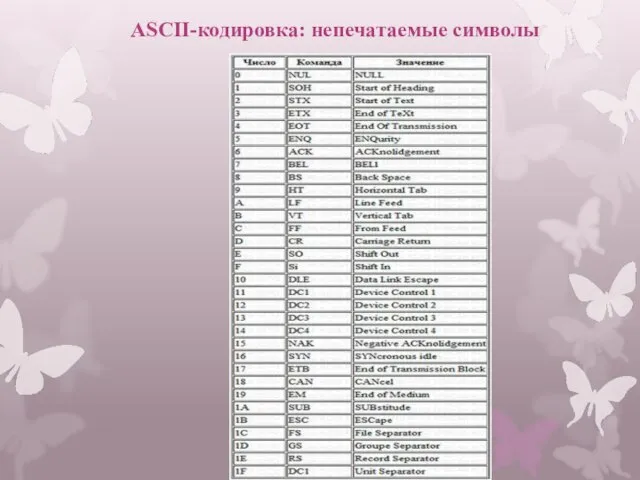
- 7. ASCII-кодировка: непечатаемые символы
- 8. UNICODE Юнико́д — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Это новая система
- 11. Скачать презентацию

Слайд 3 ASCII
Для отображения всех этих символов была создана таблитца ASCII (англ.
ASCII Для отображения всех этих символов была создана таблитца ASCII (англ.

Слайд 4Изначально разработана как 7-битная, потом ASCII стала восприниматься как 8-битная. Так выглядят
Изначально разработана как 7-битная, потом ASCII стала восприниматься как 8-битная. Так выглядят
Слайд 5Дальнейшее развитие привело к появлению понятия «кодовая страница», т.е. набор из 256
Дальнейшее развитие привело к появлению понятия «кодовая страница», т.е. набор из 256

Слайд 6 КОИ-8
KOI8 — восьмибитовая ASCII-совместимая кодовая страница, созданная для кодирования букв
КОИ-8 KOI8 — восьмибитовая ASCII-совместимая кодовая страница, созданная для кодирования букв

Слайд 7ASCII-кодировка: непечатаемые символы
ASCII-кодировка: непечатаемые символы
Слайд 8 UNICODE
Юнико́д — стандарт кодирования символов, позволяющий представить знаки практически всех
UNICODE Юнико́д — стандарт кодирования символов, позволяющий представить знаки практически всех


 Конструирование алгоритмов. Алгоритмизация и программирование
Конструирование алгоритмов. Алгоритмизация и программирование ПО компьютера
ПО компьютера Правила составления библиографического списка
Правила составления библиографического списка Rozproszone systemy komputerowe
Rozproszone systemy komputerowe Дерево систем и его роль при управлении техническими системами
Дерево систем и его роль при управлении техническими системами Самоидентификация в социальных медиа
Самоидентификация в социальных медиа Чтение технической документации
Чтение технической документации Рекурсивные функции
Рекурсивные функции Кодирование тeкстовой информации
Кодирование тeкстовой информации Презентация на тему Устройства ввода-вывода
Презентация на тему Устройства ввода-вывода  Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Amadeus Remote Ticketing Solution (RTS). Новый эффективный инструмент
Amadeus Remote Ticketing Solution (RTS). Новый эффективный инструмент Путешествие в страну Информатика
Путешествие в страну Информатика Презентация
Презентация Вёрстка. Типы вёрстки
Вёрстка. Типы вёрстки Защита информации в интернете. Проведение финансовых операций с использованием Интернета
Защита информации в интернете. Проведение финансовых операций с использованием Интернета Переменные. Сложение чисел: простое решение. 10 класс
Переменные. Сложение чисел: простое решение. 10 класс Изучение и применение графов, а так же их визуализация. Подсчет степени вершин из графа
Изучение и применение графов, а так же их визуализация. Подсчет степени вершин из графа Мир в глобальной сети интернет
Мир в глобальной сети интернет Мессенджер Telegram: портрет пользователей
Мессенджер Telegram: портрет пользователей Мобильное рабочее место Единой корпоративной автоматизированной системы управления инфраструктурой дирекции по ремонту пути
Мобильное рабочее место Единой корпоративной автоматизированной системы управления инфраструктурой дирекции по ремонту пути Сети широкополосного беспроводного доступа семейства стандартов ieee 802.16 (wimax)
Сети широкополосного беспроводного доступа семейства стандартов ieee 802.16 (wimax) Решение задач по поиску наибольшего (max)/наименьшего (min) элементов массива
Решение задач по поиску наибольшего (max)/наименьшего (min) элементов массива Объекты и классы в языке С++. (Лекция 4)
Объекты и классы в языке С++. (Лекция 4) Дизайн методом Value-Link (ER-метод). Реляционная алгебра
Дизайн методом Value-Link (ER-метод). Реляционная алгебра Оператор ввода в Pascal
Оператор ввода в Pascal Журнал ShowKids. Биография группы
Журнал ShowKids. Биография группы Знакомство с системой компьютерной математики
Знакомство с системой компьютерной математики