- Коллективные операции передачи данных

Содержание
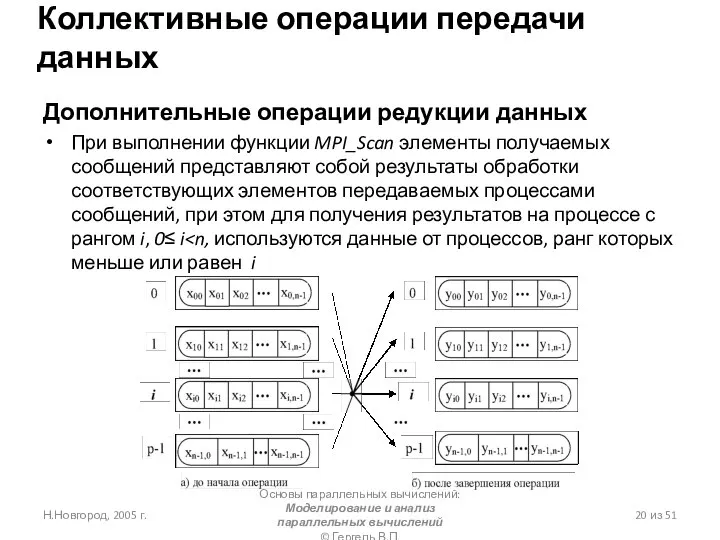
- 2. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 3. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 4. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 5. Графическая интерпретация операции Scatter
- 6. int MPI_Scatterv(void *sbuf, int *scounts, int *displs, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, int
- 7. Графическая интерпретация операции Scatterv
- 8. Определение частей массива в rank’s . . . count=m / size; ost=m % size; /* Calculating
- 9. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 10. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
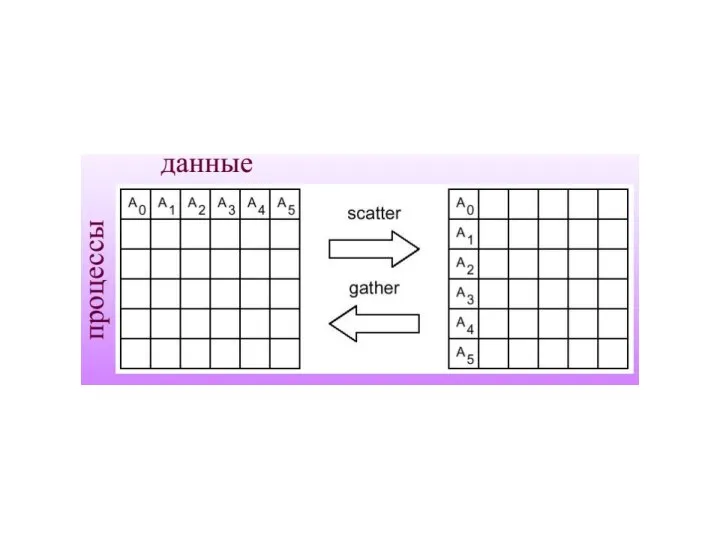
- 11. Графическая интерпретация операции Gather
- 12. int MPI_Gatherv(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int *rcounts, int *displs, MPI_Datatype rtype, int
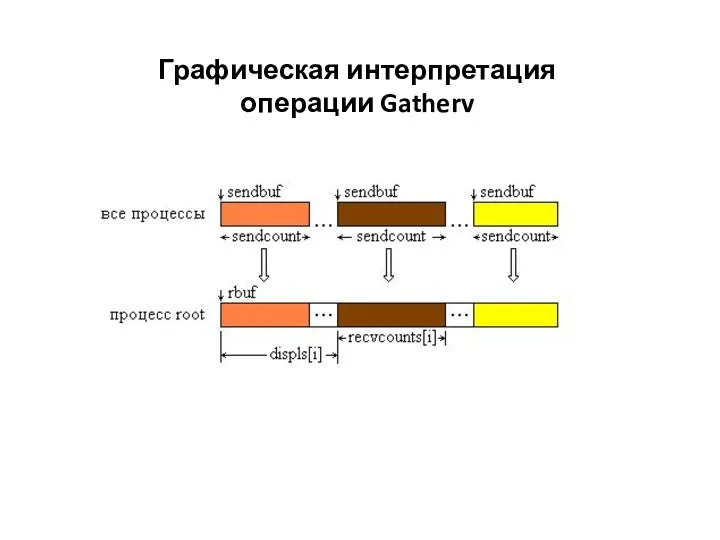
- 13. Графическая интерпретация операции Gatherv
- 15. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 16. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
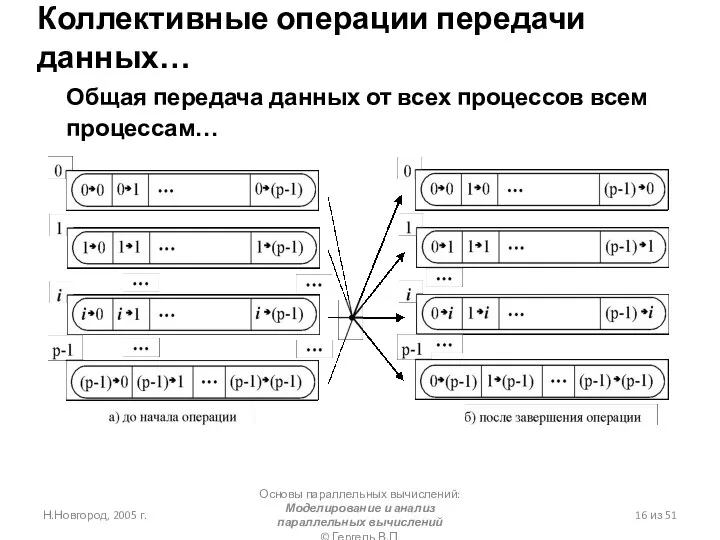
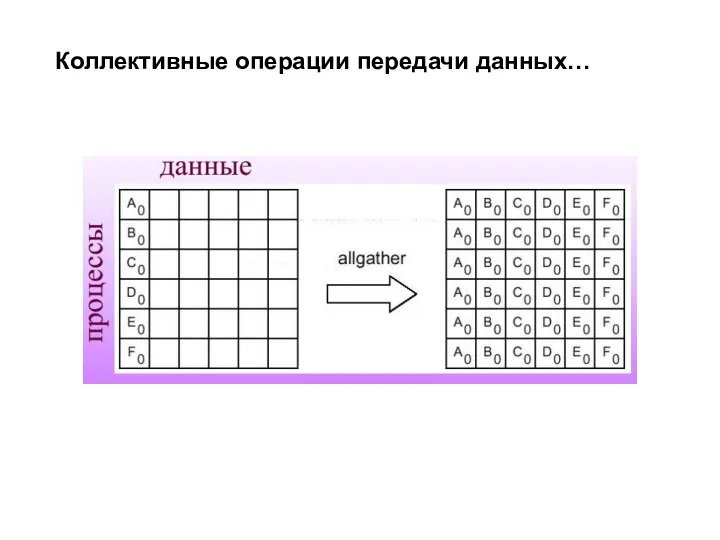
- 17. Коллективные операции передачи данных…
- 18. int MPI_Alltoall(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm) Рассылка
- 19. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 20. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 22. Скачать презентацию
Слайд 2Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель

Слайд 3Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель

Слайд 4Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель
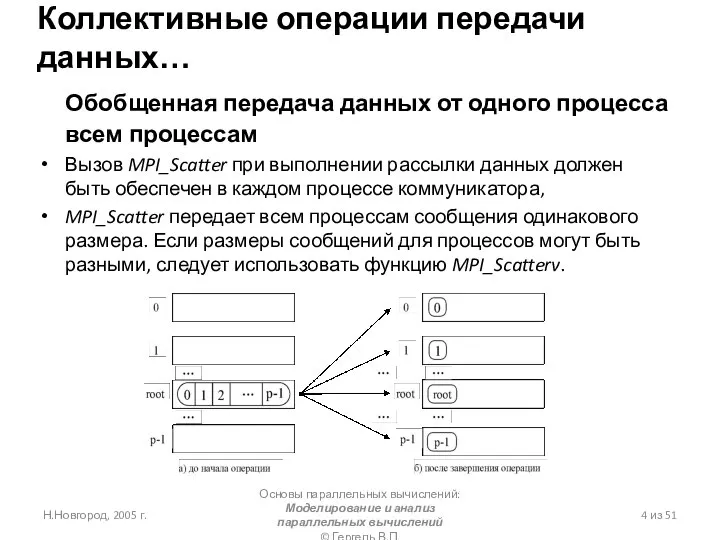
Слайд 5Графическая интерпретация операции Scatter
Графическая интерпретация операции Scatter
Слайд 6int MPI_Scatterv(void *sbuf, int *scounts, int *displs, MPI_Datatype stype,
void *rbuf,
int MPI_Scatterv(void *sbuf, int *scounts, int *displs, MPI_Datatype stype,
void *rbuf,

Слайд 7Графическая интерпретация операции Scatterv
Графическая интерпретация операции Scatterv

Слайд 8Определение частей массива в rank’s
. . .
count=m / size; ost=m % size;
/*
Определение частей массива в rank’s
. . .
count=m / size; ost=m % size;
/*

Слайд 9Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель

Слайд 10Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель
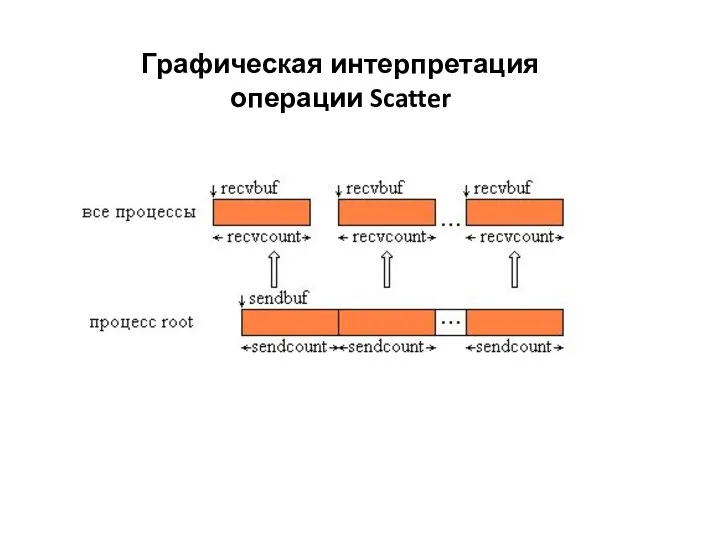
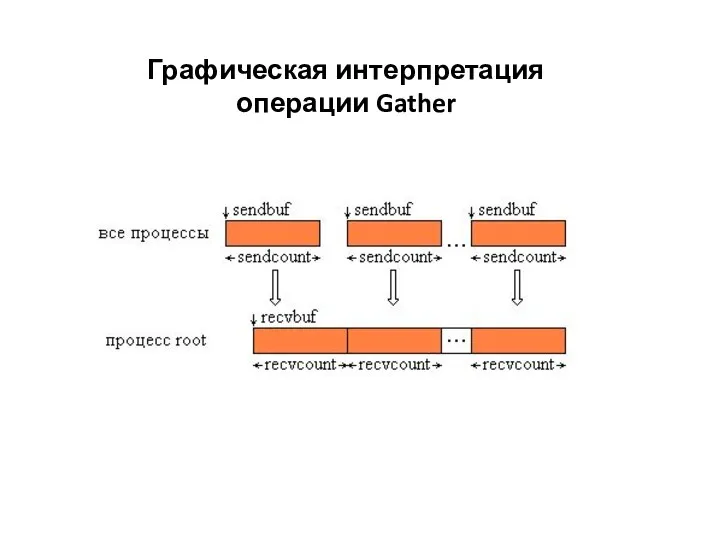
Слайд 11Графическая интерпретация операции Gather
Графическая интерпретация операции Gather
Слайд 12int MPI_Gatherv(void *sbuf, int scount, MPI_Datatype stype,
void *rbuf, int *rcounts, int
int MPI_Gatherv(void *sbuf, int scount, MPI_Datatype stype,
void *rbuf, int *rcounts, int

Слайд 13Графическая интерпретация операции Gatherv
Графическая интерпретация операции Gatherv
Слайд 15Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель

Слайд 16Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель
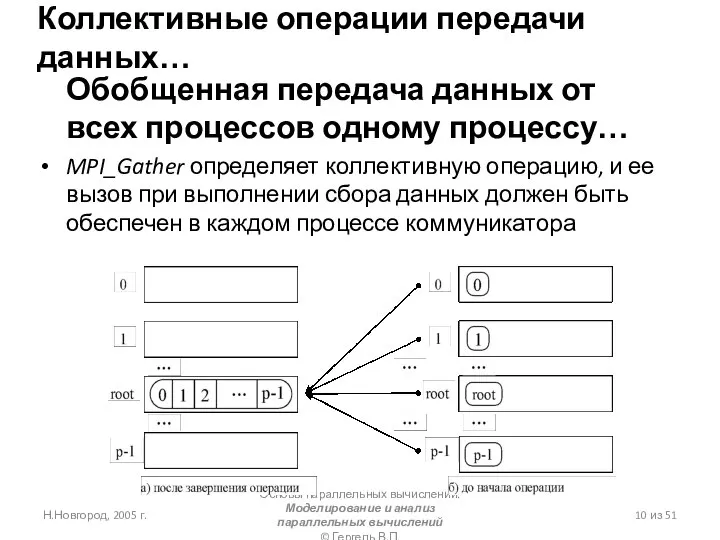
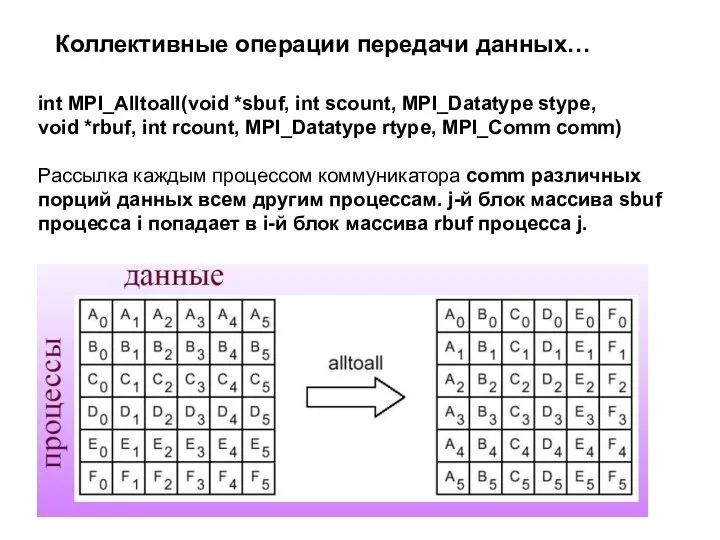
Слайд 17Коллективные операции передачи данных…
Коллективные операции передачи данных…
Слайд 18int MPI_Alltoall(void *sbuf, int scount, MPI_Datatype stype,
void *rbuf, int rcount, MPI_Datatype
void *rbuf, int rcount, MPI_Datatype
Слайд 19Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель

Слайд 20Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
© Гергель
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель
 Данные, информация, документы. Лекция №1
Данные, информация, документы. Лекция №1 Построение таблиц истинности
Построение таблиц истинности Современные веб-технологии. Лекция 2.1
Современные веб-технологии. Лекция 2.1 Jobs Guessing Game
Jobs Guessing Game Презентация "Кодирование изображения" - скачать презентации по Информатике
Презентация "Кодирование изображения" - скачать презентации по Информатике Техника безопасности в компьютерном классе
Техника безопасности в компьютерном классе Программа Tinkercad и сервис Circuits. Практическая работа № 2
Программа Tinkercad и сервис Circuits. Практическая работа № 2 Добавление и редактирование текста
Добавление и редактирование текста Транзакции и параллелизм
Транзакции и параллелизм 1_2_1
1_2_1 Администратор баз данных областное автономное учреждение социального обслуживания
Администратор баз данных областное автономное учреждение социального обслуживания Обработка массива целых чисел из файла
Обработка массива целых чисел из файла Oracle Application Express - что это такое?
Oracle Application Express - что это такое? Введение_в_web_программирование
Введение_в_web_программирование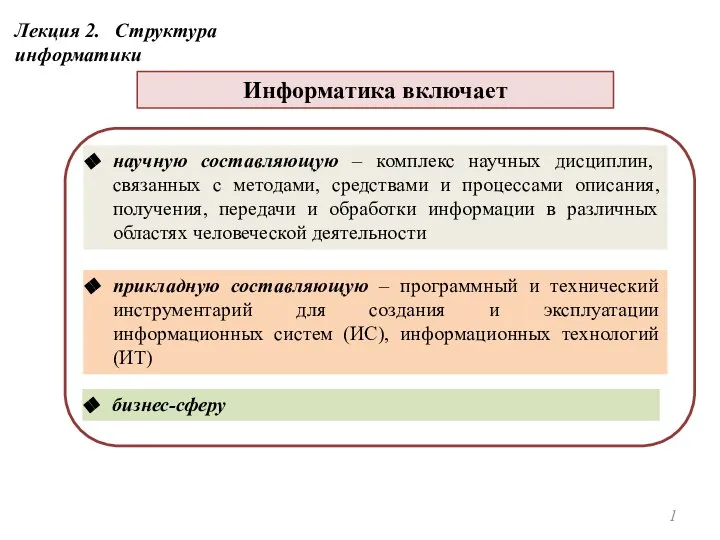 Структура информатики
Структура информатики Лекція1_
Лекція1_ Летние онлайн-смены
Летние онлайн-смены Архивация данных
Архивация данных Отчёт за 23.01.17-07.02.17. По плану транзит
Отчёт за 23.01.17-07.02.17. По плану транзит Использование медиапространства в целях повышения мотивации и эффективности воспитательной деятельности
Использование медиапространства в целях повышения мотивации и эффективности воспитательной деятельности Безопасный интернет. Как избежать опасностей?
Безопасный интернет. Как избежать опасностей?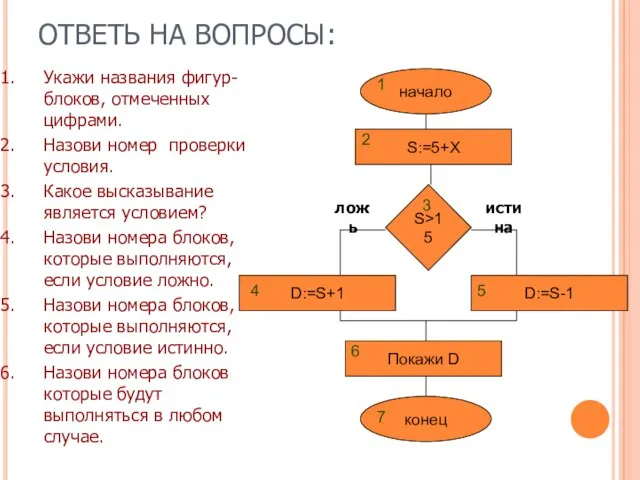 Простые и сложные высказывания
Простые и сложные высказывания Типы данных в VBA
Типы данных в VBA Как заполнить Google форму?
Как заполнить Google форму? Доступ к сервису мои достижения
Доступ к сервису мои достижения 1С:Университет ПРОФ. Общая информация о решении
1С:Университет ПРОФ. Общая информация о решении Введение в алгоритмы DM
Введение в алгоритмы DM Образование на основе онлайновых социальных сетей
Образование на основе онлайновых социальных сетей