- Машинное обучение

Содержание
- 2. Типы машинного обучения Индуктивное (по прецедентам) и дедуктивное. Некоторые методы индуктивного обучения были разработаны в качестве
- 3. Статистическая теория обучения Статистическая теория обучения — это модель для обучения машин на основе статистики и
- 4. Статистическая теория обучения
- 5. E
- 6. E Разброс - характеризует разнообразие алгоритмов (из-за случайности обучающей выборки, в том числе шума, и стохастической
- 7. Смещение, разброс, переобучение и недообучение.
- 8. Смещение, разброс, переобучение и недообучение.
- 9. Смещение, разброс, переобучение и недообучение.
- 10. Статистический вывод
- 11. Параметрические и непараметрические методы
- 12. Параметрические и непараметрические методы
- 13. Параметрические и непараметрические методы
- 14. Параметрические и непараметрические методы
- 15. Компромисс между смещением и дисперсией
- 16. Компромисс между смещением и дисперсией
- 17. Компромисс между смещением и дисперсией
- 18. Истинная функция существенно отличается от линейной
- 19. Истинная функция существенно отличается от линейной
- 20. Степени обученности модели
- 21. Примеры недообученных и переобученных моделей
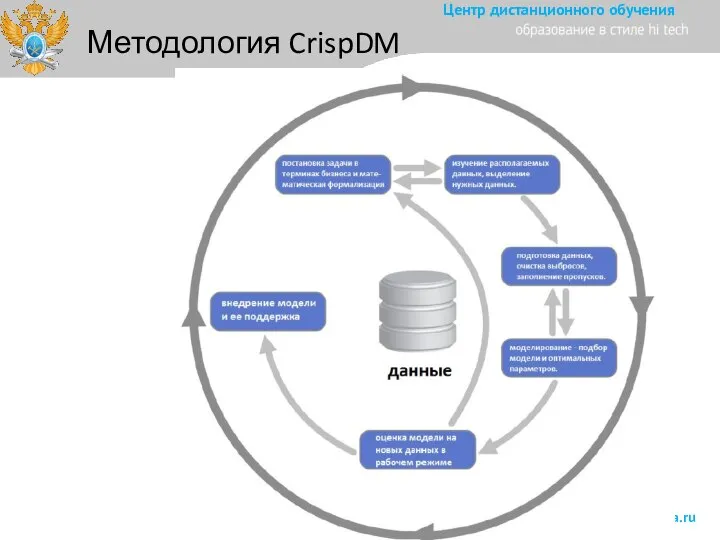
- 28. Методология CrispDM
- 31. Смещение, разброс, переобучение и недообучение. Переобучение (overfitting) – явление, когда ошибка на тестовой выборке заметно больше
- 32. Смещение, разброс, переобучение и недообучение. Сложность (complexity) модели алгоритмов (допускает множество формализаций) – оценивает, насколько разнообразно
- 33. Смещение, разброс, переобучение и недообучение. Пример переобучения. зашумлённой пороговой зависимости Видно, что с увеличением степени ошибка
- 34. Измерение качества модели через среднеквадратическое отклонение.
- 35. Список литературы 1. Джеймс Г., Уиттон Д., Хасти Т., Тибширани Р . Введение в статистическое обучение
- 37. Скачать презентацию
Слайд 2Типы машинного обучения
Индуктивное (по прецедентам) и дедуктивное. Некоторые методы индуктивного обучения были
Типы машинного обучения
Индуктивное (по прецедентам) и дедуктивное. Некоторые методы индуктивного обучения были

Слайд 3Статистическая теория обучения
Статистическая теория обучения — это модель для обучения машин
Статистическая теория обучения
Статистическая теория обучения — это модель для обучения машин

Слайд 4Статистическая теория обучения
Статистическая теория обучения


Слайд 6E
Разброс - характеризует разнообразие алгоритмов (из-за случайности обучающей выборки, в том числе
E
Разброс - характеризует разнообразие алгоритмов (из-за случайности обучающей выборки, в том числе

Слайд 7Смещение, разброс, переобучение и недообучение.
Смещение, разброс, переобучение и недообучение.

Слайд 8Смещение, разброс, переобучение и недообучение.
Смещение, разброс, переобучение и недообучение.
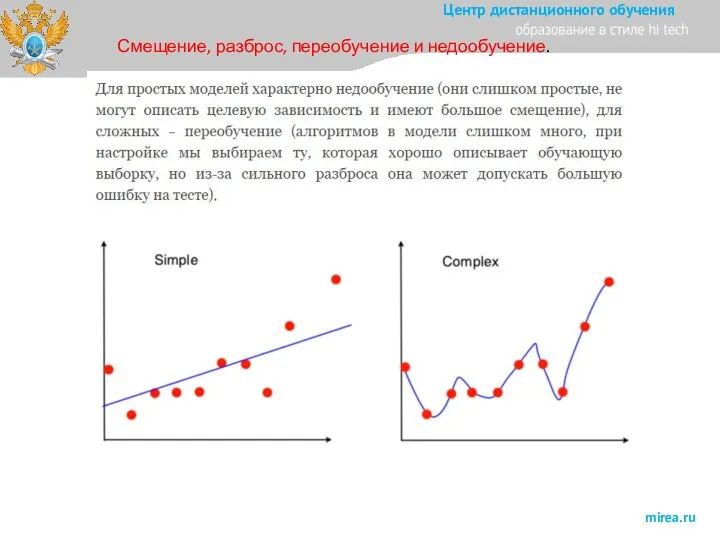
Слайд 9Смещение, разброс, переобучение и недообучение.
Смещение, разброс, переобучение и недообучение.
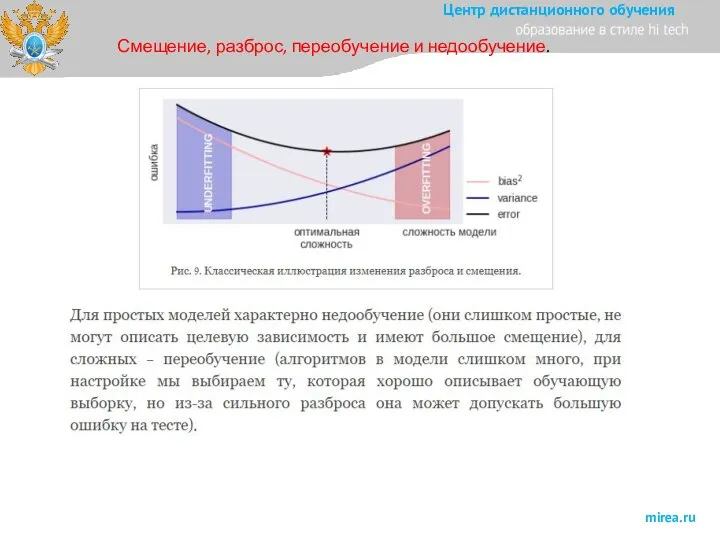
Слайд 10Статистический вывод
Статистический вывод

Слайд 11Параметрические и непараметрические методы
Параметрические и непараметрические методы

Слайд 12Параметрические и непараметрические методы
Параметрические и непараметрические методы

Слайд 13Параметрические и непараметрические методы
Параметрические и непараметрические методы

Слайд 14Параметрические и непараметрические методы
Параметрические и непараметрические методы

Слайд 15Компромисс между смещением и дисперсией
Компромисс между смещением и дисперсией

Слайд 16Компромисс между смещением и дисперсией
Компромисс между смещением и дисперсией
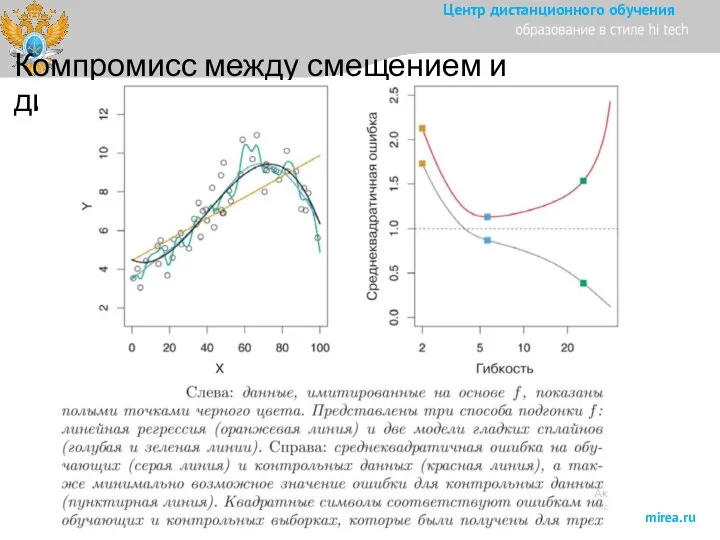
Слайд 17Компромисс между смещением и дисперсией
Компромисс между смещением и дисперсией
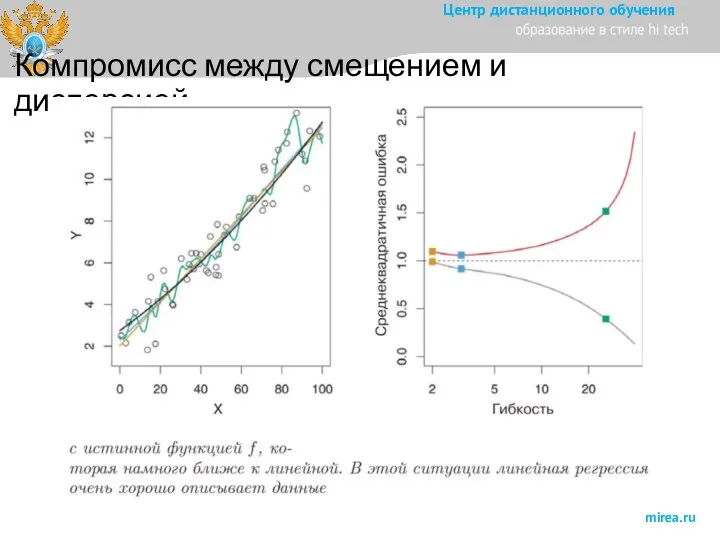
Слайд 18Истинная функция существенно отличается от линейной
Истинная функция существенно отличается от линейной
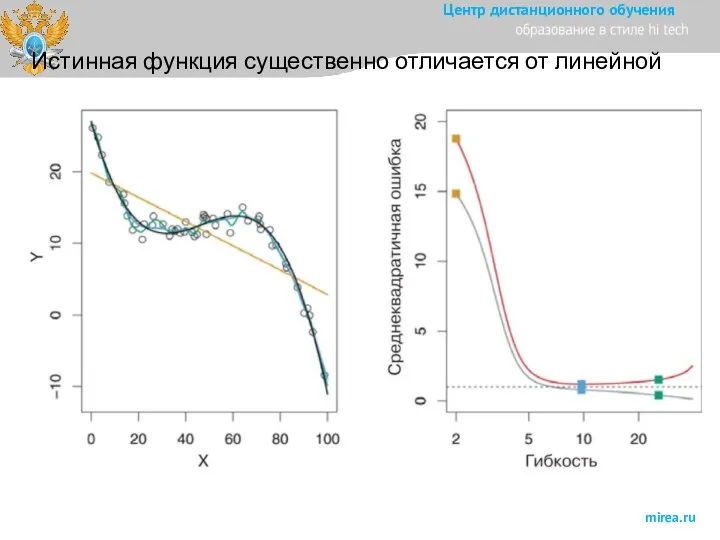
Слайд 19Истинная функция существенно отличается от линейной
Истинная функция существенно отличается от линейной
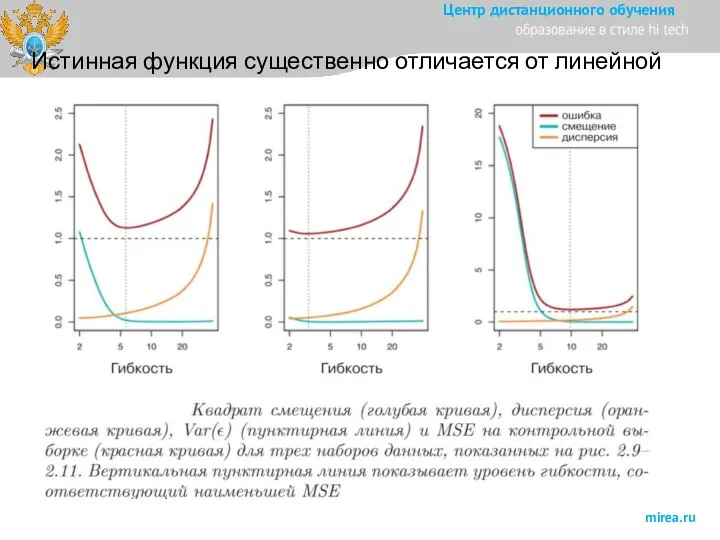
Слайд 20Степени обученности модели
Степени обученности модели

Слайд 21Примеры недообученных и переобученных моделей
Примеры недообученных и переобученных моделей
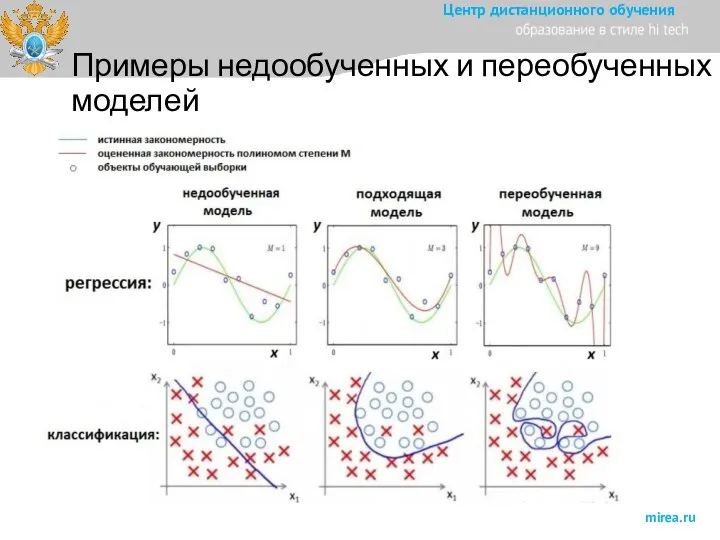


Слайд 28Методология CrispDM
Методология CrispDM


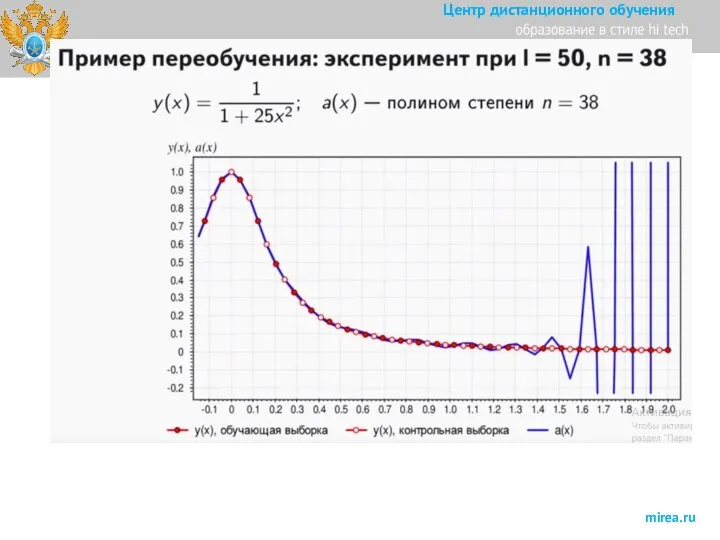
Слайд 31Смещение, разброс, переобучение и недообучение.
Переобучение (overfitting) – явление, когда ошибка на
Смещение, разброс, переобучение и недообучение.
Переобучение (overfitting) – явление, когда ошибка на

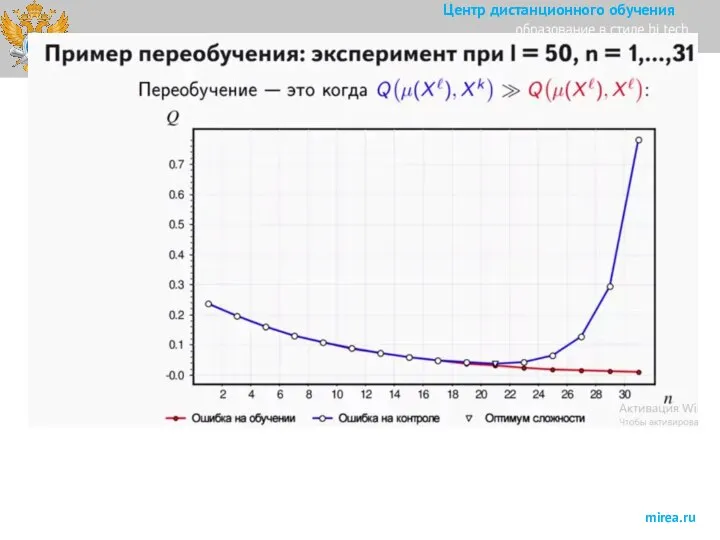
Слайд 32Смещение, разброс, переобучение и недообучение.
Сложность (complexity) модели алгоритмов (допускает множество формализаций) –
Смещение, разброс, переобучение и недообучение.
Сложность (complexity) модели алгоритмов (допускает множество формализаций) –
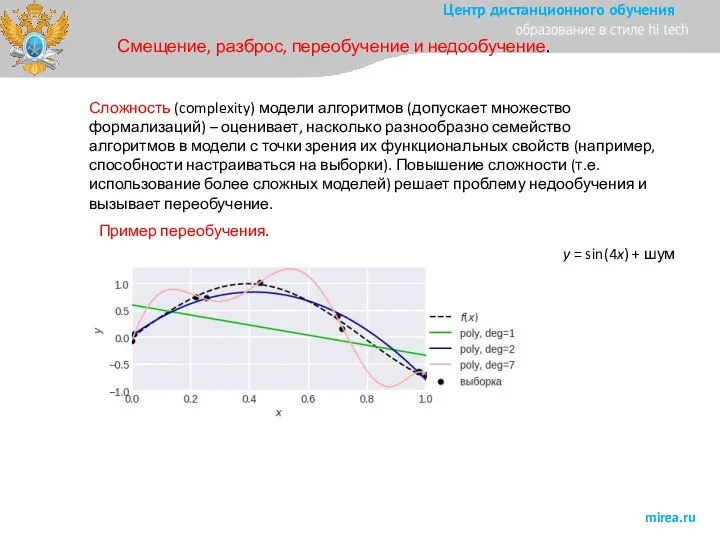
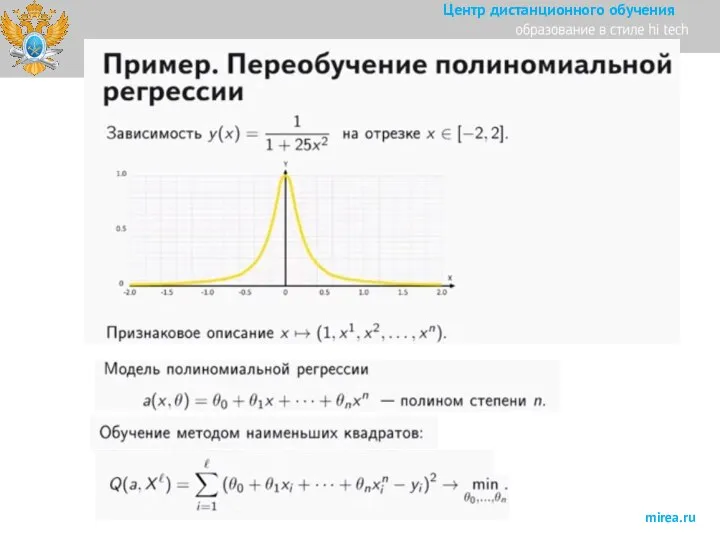
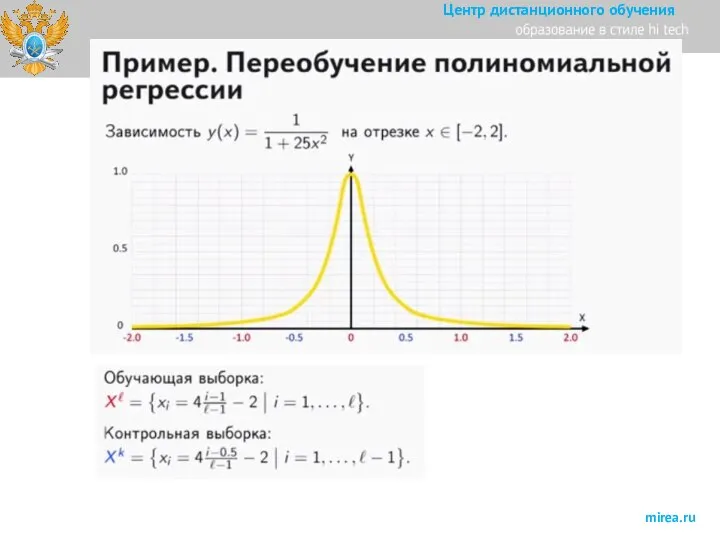
Слайд 33Смещение, разброс, переобучение и недообучение.
Пример переобучения.
зашумлённой пороговой зависимости
Видно, что с увеличением степени
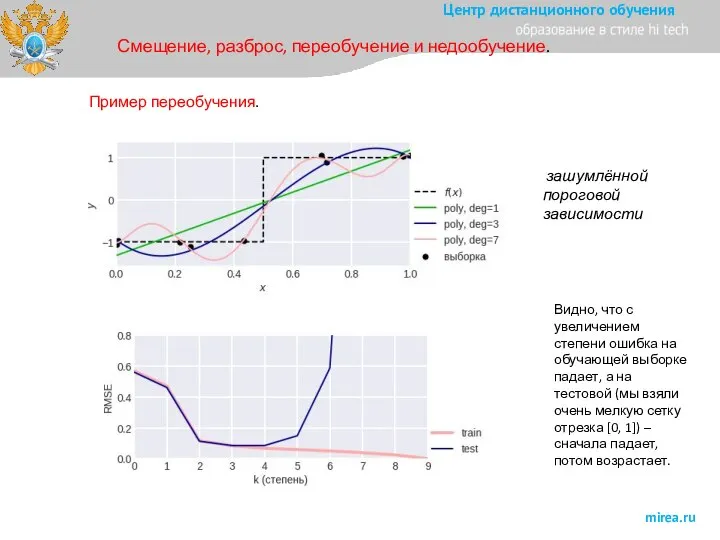
Смещение, разброс, переобучение и недообучение.
Пример переобучения.
зашумлённой пороговой зависимости
Видно, что с увеличением степени
Слайд 34Измерение качества модели через среднеквадратическое отклонение.
Измерение качества модели через среднеквадратическое отклонение.

Слайд 35Список литературы
1. Джеймс Г., Уиттон Д., Хасти Т., Тибширани Р . Введение
Список литературы
1. Джеймс Г., Уиттон Д., Хасти Т., Тибширани Р . Введение

 INEX. Главное меню
INEX. Главное меню Human-Computer Interaction
Human-Computer Interaction SportNews
SportNews Помехоустойчивое кодирование
Помехоустойчивое кодирование Интернет-предпринимательство. Идея и стартап проекта
Интернет-предпринимательство. Идея и стартап проекта Цвет в компьютерной графики
Цвет в компьютерной графики Электронные таблицы. Обработка числовой информации в электронных таблицах
Электронные таблицы. Обработка числовой информации в электронных таблицах Преобразование данных csv в xlsx
Преобразование данных csv в xlsx Мультимедийные интерактивные презентации
Мультимедийные интерактивные презентации Отчет о деятельности Пресс-центра ППОС СФУ за 2018 год
Отчет о деятельности Пресс-центра ППОС СФУ за 2018 год Информационные технологии
Информационные технологии Патентный поиск www1.fips.ru. Пример оформления патента в списке использованных источников
Патентный поиск www1.fips.ru. Пример оформления патента в списке использованных источников Data science. Кластеризация
Data science. Кластеризация prez_0
prez_0 Как сделать сердце в Компасе
Как сделать сердце в Компасе UI Performance
UI Performance Практика интервью. Народная журналистика
Практика интервью. Народная журналистика Интернет-мошенничество
Интернет-мошенничество Система управления базами данных (СУБД)
Система управления базами данных (СУБД) Смеситель для умывальника Helic. Правки на сайте
Смеситель для умывальника Helic. Правки на сайте Алгоритмическая конструкция повторение
Алгоритмическая конструкция повторение Проблемы защиты информации в internet
Проблемы защиты информации в internet Создать веб-страницу с HTML
Создать веб-страницу с HTML Здоровым быть здорово
Здоровым быть здорово Презентация на тему Основы HTML
Презентация на тему Основы HTML  Методика решения графических тестов
Методика решения графических тестов Язык интегрированных запросов LINQ
Язык интегрированных запросов LINQ Научный поиск и принципы формирования научных работ
Научный поиск и принципы формирования научных работ