- Понятие информация

Содержание
- 2. Под информацией в быту понимают любые сведения об окружающем мире и протекающих в нем процессах, воспринимаемые
- 3. Под информацией в технике понимают любые сообщения, которые зафиксированы в виде знаков и могут передаваться в
- 4. Под информацией в теории управления (менеджменте) понимают сообщения, уменьшающие существующую до этого неопределенность в той предметной
- 5. ключевые атрибуты информации. 1. Достоверность. информация свободна от ошибок, чьей-либо пристрастности и отражает истинное положение дел.
- 6. в узком смысле информацией можно назвать сведения о предметах, фактах, понятиях некоторой предметной области. С середины
- 7. информацию можно подразделить на: 1) структурную (или связанную) присущую объектам неживой и живой природы естественного или
- 8. Данные, знания Сведения, полученные путем измерения, наблюдения, логических или арифметических операций, и представленные в форме, пригодной
- 9. Свойства знаний 1. Внутренняя интерпретируемость знаний (понятность знания его носителю). 2. Структурированность знаний. Информационные единицы должны
- 10. Введение информации в научно-технический и хозяйственный оборот привело к необходимости ее количественной оценки, т.е. к введению
- 11. Пример 1. Как определить, какая из двух монет фальшивая, если на вид они одинаковы, но известно,
- 12. Понятие бита бит – это и двоичный знак, и единица измерения количества информации, определяемая как количество
- 13. Пример 2. А если монет 8? Тогда делим их на две равные части и взвешиваем их.
- 14. Пример 3. Перейдем от монет к картам. Пусть в колоде из 32 карт необходимо угадать определенную
- 15. В этих примерах процесс получения информации рассматривается как выбор одного сообщения из конечного наперёд заданного множества
- 16. Справедливо утверждение Хартли: если во множестве X={x1,x2,…,xn} выделить произвольный элемент xi ∈ X , то, чтобы
- 17. Вероятности отдельных букв в русском языке (с учетом пробела)
- 18. Частоты букв (в процентах) ряда европейских языков
- 19. Для неравновероятных процессов американский учёный Клод Шеннон предложил (1948 г.) другую формулу определения количества информации, которая
- 20. Можно представить что для того, чтобы получить какой то символ от источника сообщения нужно перебрать по
- 21. Из формулы непосредственно вытекают свойства энтропии: энтропия заранее известного сообщения равна 0; во всех других случаях
- 22. Кодирование источника сообщений Как уже отмечалось, результат одного отдельного альтернативного выбора может быть представлен как 0
- 23. Если количество символов представляет собой степень двойки (n = 2N) и все знаки равновероятны Pi =
- 24. Кодирование словами постоянной длины ld(7)≈2,807 и L=3. . Проведем кодирование, разбивая исходное множество знаков на равновероятные
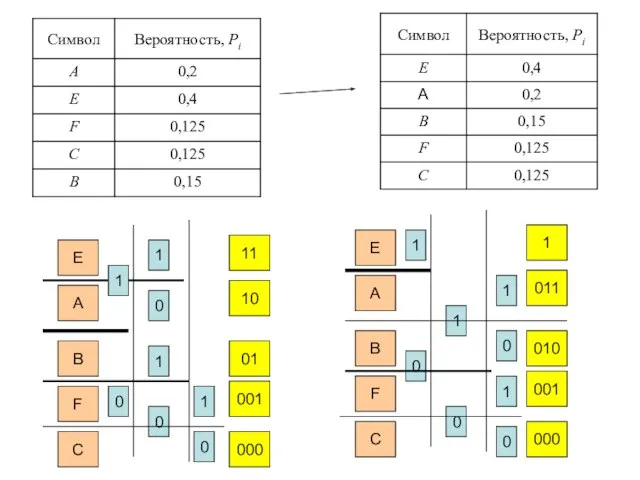
- 25. В общем случае алгоритм построения оптимального кода Шеннона-Фано выглядит следующим образом: 1. сообщения, входящие в ансамбль,
- 26. E A B F C 1 0 1 0 1 0 1 0 11 10 01
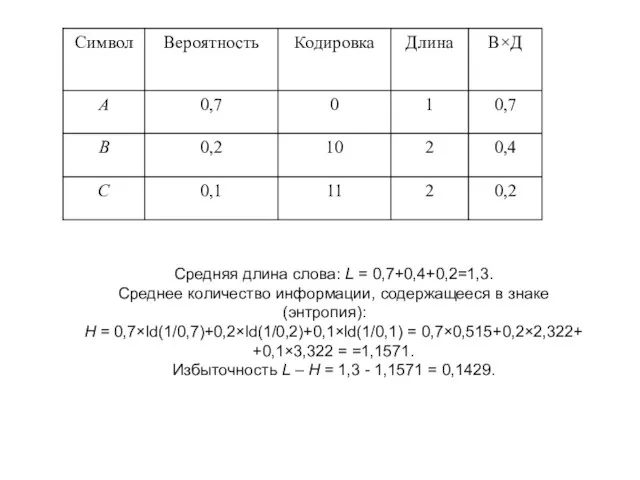
- 27. При неравномерном кодировании вводят среднюю длину кодировки, которая определяется по формуле В общем же случае связь
- 28. Средняя длина слова: L = 0,7+0,4+0,2=1,3. Среднее количество информации, содержащееся в знаке (энтропия): H = 0,7×ld(1/0,7)+0,2×ld(1/0,2)+0,1×ld(1/0,1)
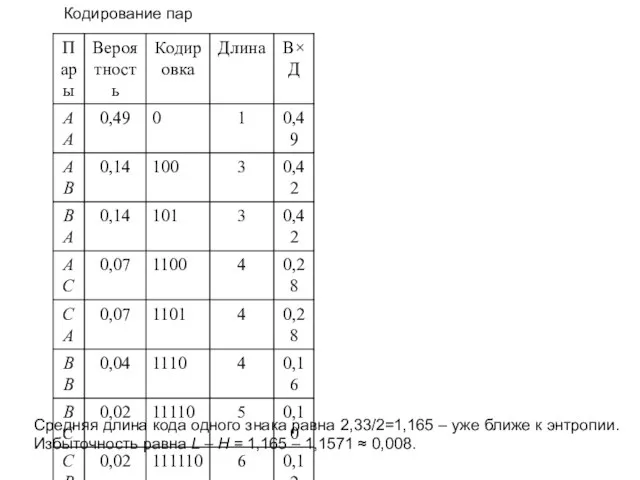
- 29. Кодирование пар Средняя длина кода одного знака равна 2,33/2=1,165 – уже ближе к энтропии. Избыточность равна
- 31. Скачать презентацию

Слайд 3Под информацией в технике понимают любые сообщения, которые зафиксированы в виде знаков
Под информацией в технике понимают любые сообщения, которые зафиксированы в виде знаков

Слайд 4Под информацией в теории управления (менеджменте) понимают сообщения, уменьшающие существующую до этого
Под информацией в теории управления (менеджменте) понимают сообщения, уменьшающие существующую до этого

Слайд 5ключевые атрибуты информации.
1. Достоверность. информация свободна от ошибок, чьей-либо пристрастности и
ключевые атрибуты информации.
1. Достоверность. информация свободна от ошибок, чьей-либо пристрастности и

Слайд 6в узком смысле информацией можно назвать сведения о предметах, фактах, понятиях некоторой
в узком смысле информацией можно назвать сведения о предметах, фактах, понятиях некоторой

Слайд 7информацию можно подразделить на:
1) структурную (или связанную) присущую объектам неживой и живой
информацию можно подразделить на:
1) структурную (или связанную) присущую объектам неживой и живой

Слайд 8Данные, знания
Сведения, полученные путем измерения, наблюдения, логических или арифметических операций, и представленные
Данные, знания
Сведения, полученные путем измерения, наблюдения, логических или арифметических операций, и представленные

Слайд 9Свойства знаний
1. Внутренняя интерпретируемость знаний (понятность знания его носителю).
2. Структурированность знаний. Информационные
Свойства знаний
1. Внутренняя интерпретируемость знаний (понятность знания его носителю).
2. Структурированность знаний. Информационные

Слайд 10Введение информации в научно-технический и хозяйственный оборот привело к необходимости ее количественной
Введение информации в научно-технический и хозяйственный оборот привело к необходимости ее количественной

Слайд 11Пример 1. Как определить, какая из двух монет фальшивая, если на вид
Пример 1. Как определить, какая из двух монет фальшивая, если на вид

Слайд 12Понятие бита
бит – это и двоичный знак, и единица измерения количества информации,
Понятие бита
бит – это и двоичный знак, и единица измерения количества информации,

Слайд 13Пример 2. А если монет 8? Тогда делим их на две равные
Пример 2. А если монет 8? Тогда делим их на две равные

Слайд 14Пример 3. Перейдем от монет к картам. Пусть в колоде из 32
Пример 3. Перейдем от монет к картам. Пусть в колоде из 32
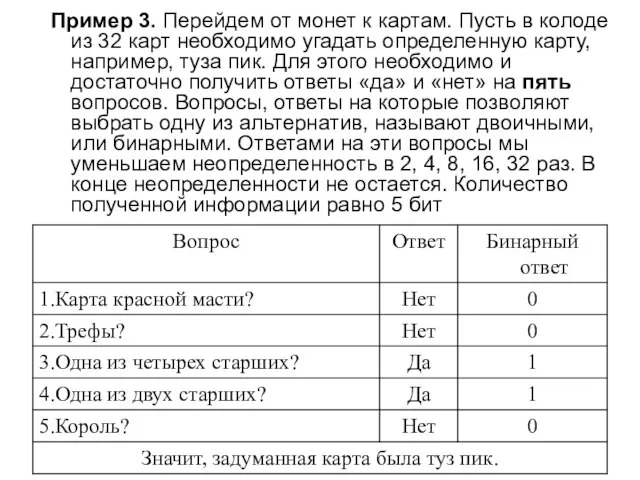
Слайд 15В этих примерах процесс получения информации рассматривается как выбор одного сообщения из
В этих примерах процесс получения информации рассматривается как выбор одного сообщения из

Слайд 16Справедливо утверждение Хартли: если во множестве X={x1,x2,…,xn} выделить произвольный элемент xi ∈
Справедливо утверждение Хартли: если во множестве X={x1,x2,…,xn} выделить произвольный элемент xi ∈

Слайд 17Вероятности отдельных букв в русском языке (с учетом пробела)
Вероятности отдельных букв в русском языке (с учетом пробела)
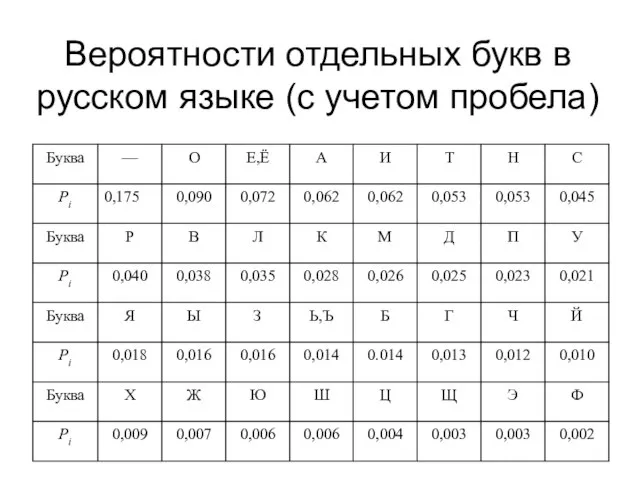
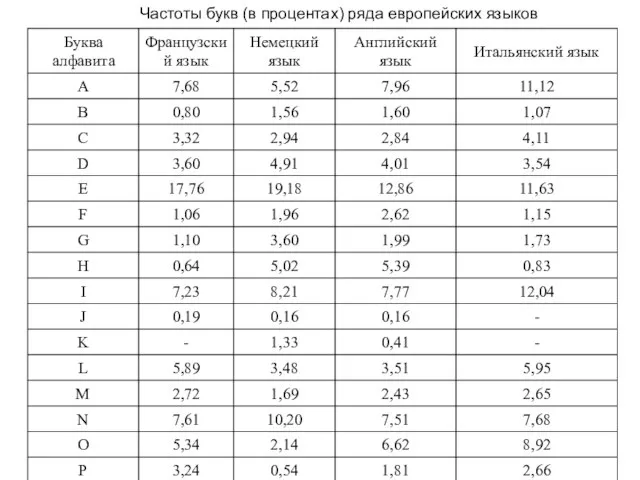
Слайд 18Частоты букв (в процентах) ряда европейских языков
Частоты букв (в процентах) ряда европейских языков
Слайд 19Для неравновероятных процессов американский учёный Клод Шеннон предложил (1948 г.) другую формулу
Для неравновероятных процессов американский учёный Клод Шеннон предложил (1948 г.) другую формулу

Слайд 20Можно представить что для того, чтобы получить какой то символ от источника
Можно представить что для того, чтобы получить какой то символ от источника

Слайд 21Из формулы непосредственно вытекают свойства энтропии:
энтропия заранее известного сообщения равна 0;
во всех
Из формулы непосредственно вытекают свойства энтропии:
энтропия заранее известного сообщения равна 0;
во всех

Слайд 22Кодирование источника сообщений
Как уже отмечалось, результат одного отдельного альтернативного выбора может быть
Кодирование источника сообщений
Как уже отмечалось, результат одного отдельного альтернативного выбора может быть

Слайд 23Если количество символов представляет собой степень двойки (n = 2N) и все
Если количество символов представляет собой степень двойки (n = 2N) и все

Слайд 24Кодирование словами постоянной длины
ld(7)≈2,807 и L=3.
. Проведем кодирование, разбивая исходное множество
Кодирование словами постоянной длины
ld(7)≈2,807 и L=3.
. Проведем кодирование, разбивая исходное множество
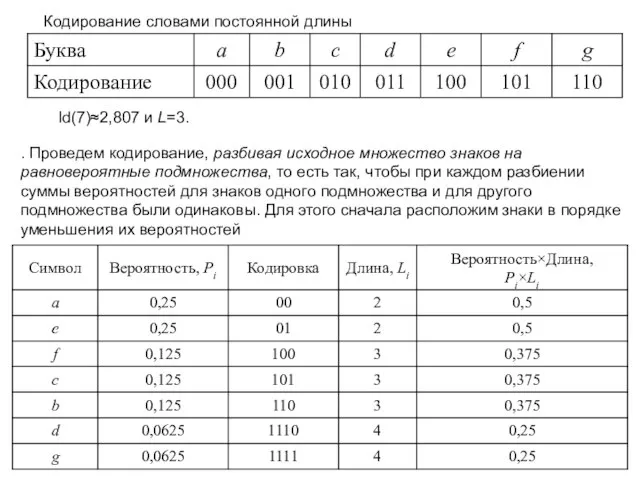
Слайд 25В общем случае алгоритм построения оптимального кода Шеннона-Фано выглядит следующим образом:
1. сообщения,
В общем случае алгоритм построения оптимального кода Шеннона-Фано выглядит следующим образом:
1. сообщения,

Слайд 26E
A
B
F
C
1
0
1
0
1
0
1
0
11
10
01
001
000
E
A
B
F
C
1
0
0
0
1
0
1
011
010
001
000
1
1
E
A
B
F
C
1
0
1
0
1
0
1
0
11
10
01
001
000
E
A
B
F
C
1
0
0
0
1
0
1
011
010
001
000
1
1
Слайд 27При неравномерном кодировании вводят среднюю длину кодировки, которая определяется по формуле
В
При неравномерном кодировании вводят среднюю длину кодировки, которая определяется по формуле
В

Слайд 28Средняя длина слова: L = 0,7+0,4+0,2=1,3.
Среднее количество информации, содержащееся в знаке (энтропия):
H
Средняя длина слова: L = 0,7+0,4+0,2=1,3.
Среднее количество информации, содержащееся в знаке (энтропия):
H
Слайд 29Кодирование пар
Средняя длина кода одного знака равна 2,33/2=1,165 – уже ближе к
Кодирование пар
Средняя длина кода одного знака равна 2,33/2=1,165 – уже ближе к
 Методы работы с источниками информации Неграмотным человеком завтрашнего дня будет не тот, кто не умеет читать, а тот, кто не научи
Методы работы с источниками информации Неграмотным человеком завтрашнего дня будет не тот, кто не умеет читать, а тот, кто не научи WHILE … WEND ЦИКЛ
WHILE … WEND ЦИКЛ NTPP. Общие факты
NTPP. Общие факты Онлайн-конструктора документов Октима
Онлайн-конструктора документов Октима Исследование подходов для аутентификации пользователей беспроводной сети с применением различных LDAP решений
Исследование подходов для аутентификации пользователей беспроводной сети с применением различных LDAP решений Основные свойства и структура системы
Основные свойства и структура системы Презентация на тему Системы счисления
Презентация на тему Системы счисления  Направления развития и итоги работы. Руководитель отдела системного администрирования МРЦ Волга-2
Направления развития и итоги работы. Руководитель отдела системного администрирования МРЦ Волга-2 Что такое программирование
Что такое программирование Теоретические и прикладные аспекты информационного противоборства в сети Интернет
Теоретические и прикладные аспекты информационного противоборства в сети Интернет Представление текстовой информации в ПК
Представление текстовой информации в ПК Устройства образующие типовой компьютер
Устройства образующие типовой компьютер Алгоритмы. Этапы решения задач на ЭВМ
Алгоритмы. Этапы решения задач на ЭВМ Презентация на тему ОС Windows. История её развития и применение
Презентация на тему ОС Windows. История её развития и применение  Образцы технических решений
Образцы технических решений Измерение информации
Измерение информации Работа с файловыми архивами
Работа с файловыми архивами Порядок предоставления в электронной форме услуги Государственная экспертиза проектной документации
Порядок предоставления в электронной форме услуги Государственная экспертиза проектной документации DH Standard AVN Update
DH Standard AVN Update Социальные медиа
Социальные медиа Доработка вёрстки страницы о товаре
Доработка вёрстки страницы о товаре Системное программное обеспечение
Системное программное обеспечение Потенциал инстаграм-проекта по совершенствованию навыков говорения итальяно-язычных студентов (РКИ, уровень А2))
Потенциал инстаграм-проекта по совершенствованию навыков говорения итальяно-язычных студентов (РКИ, уровень А2)) Библиотека и молодёжь
Библиотека и молодёжь Visual storytelling &data visualization best practices
Visual storytelling &data visualization best practices Системы программирования и прикладное программное обеспечение
Системы программирования и прикладное программное обеспечение Вычисление суммы первых n элементов знакочередующегося степенного ряда
Вычисление суммы первых n элементов знакочередующегося степенного ряда Компьютерные сети. Виды, структура, принципы функционирования
Компьютерные сети. Виды, структура, принципы функционирования