- Представление числовых данных

Содержание
- 2. Статистическая обработка данных. Ребята, мы переходим к изучению нового раздела, связанного с вопросами обработки данных различных
- 3. Статистическая обработка данных. Давайте рассмотрим какой-нибудь пример, где нам может пригодиться обработка информации. Пусть у нас
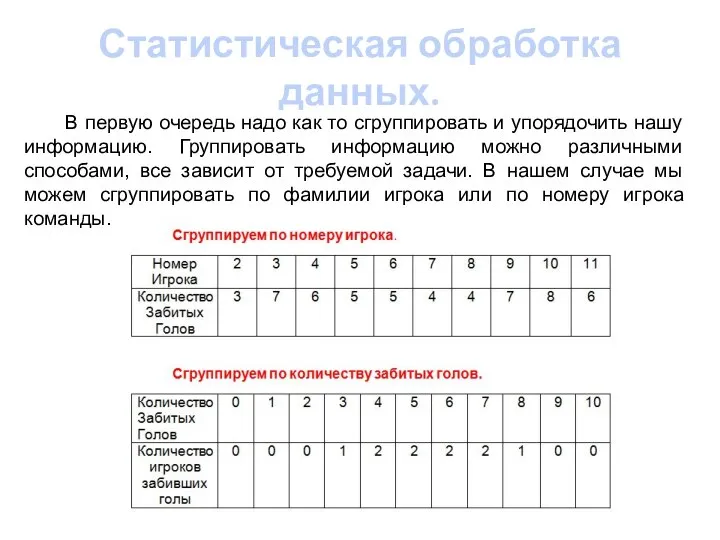
- 4. Статистическая обработка данных. В первую очередь надо как то сгруппировать и упорядочить нашу информацию. Группировать информацию
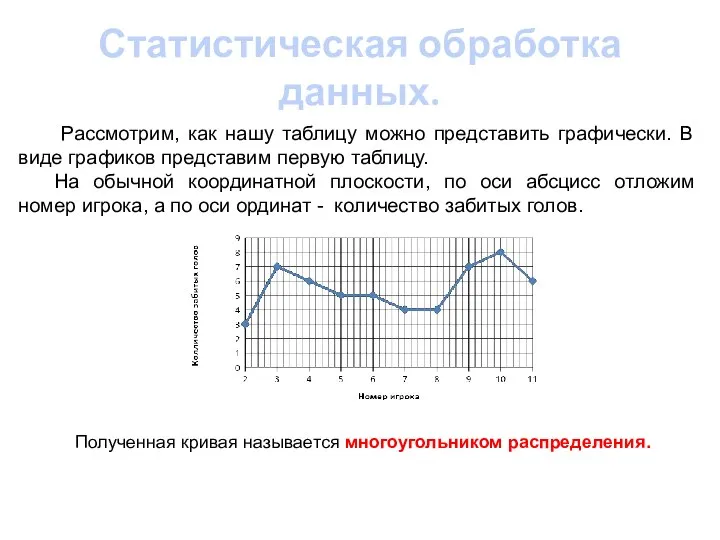
- 5. Статистическая обработка данных. Рассмотрим, как нашу таблицу можно представить графически. В виде графиков представим первую таблицу.
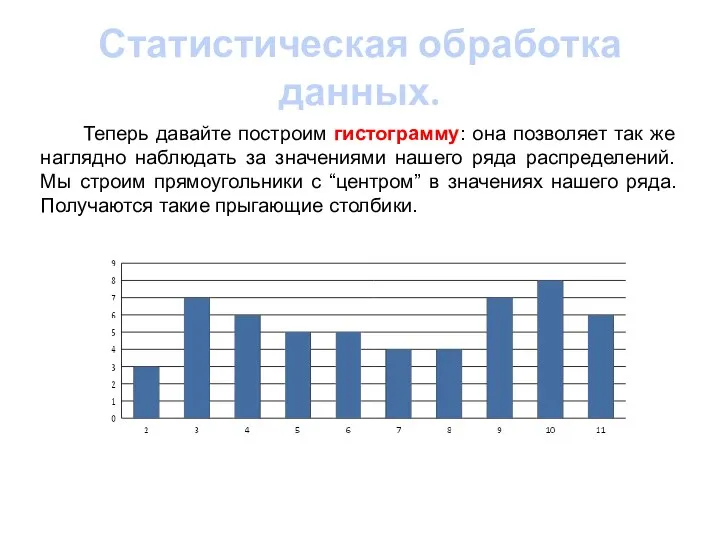
- 6. Статистическая обработка данных. Теперь давайте построим гистограмму: она позволяет так же наглядно наблюдать за значениями нашего
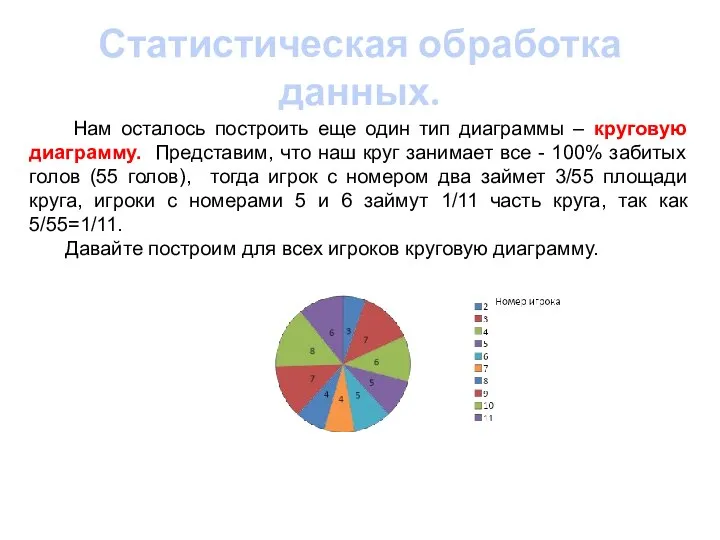
- 7. Статистическая обработка данных. Нам осталось построить еще один тип диаграммы – круговую диаграмму. Представим, что наш
- 8. Статистическая обработка данных. Ну вот, мы с вами научились немного обрабатывать данные. Давайте напишем небольшой алгоритм
- 9. Статистическая обработка данных. Но на этом обработка информации не заканчивается, для нашего ряда распределения можно найти
- 10. Статистическая обработка данных. Среднее значение выборки. Суммируя все результаты и поделив на оббьем выборки можно получить
- 11. Статистическая обработка данных. Варианта измерения – каждое число встретившиеся в результате измерения. В нашем случае для
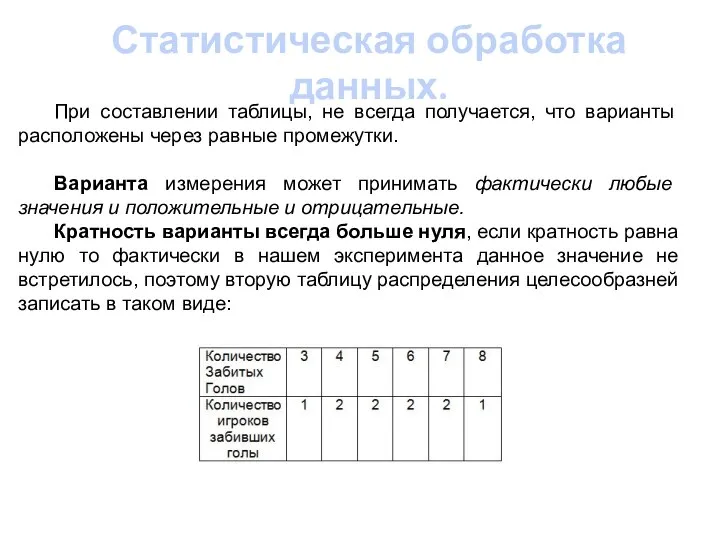
- 12. Статистическая обработка данных. При составлении таблицы, не всегда получается, что варианты расположены через равные промежутки. Варианта
- 13. Статистическая обработка данных. Варианта измерения – каждое число встретившиеся в результате измерения. В нашем случае для
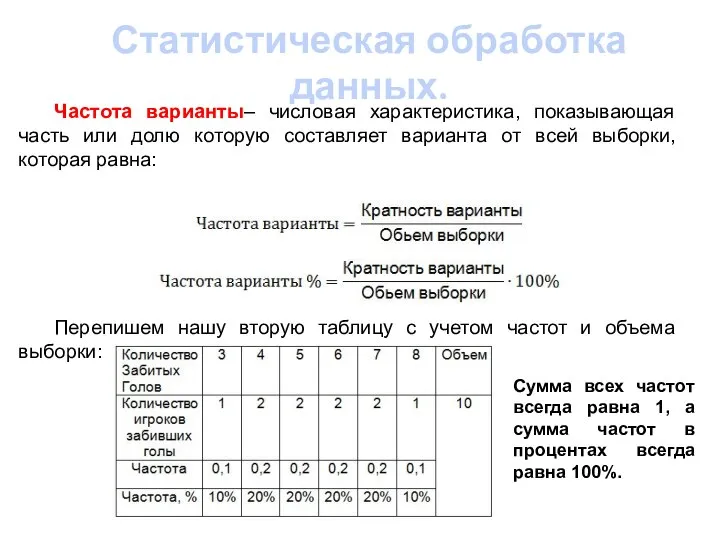
- 14. Статистическая обработка данных. Частота варианты– числовая характеристика, показывающая часть или долю которую составляет варианта от всей
- 15. Статистическая обработка данных. Вернемся к среднему значению, данная числовая характеристика часто является очень полезной. Но не
- 16. Статистическая обработка данных. Еще одна важная числовая характеристика – Дисперсия, или разброс значений вокруг среднего значения.
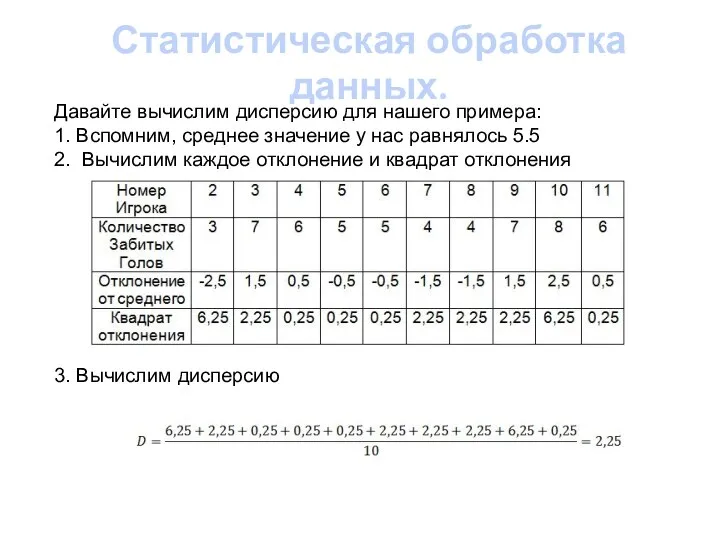
- 17. Статистическая обработка данных. Давайте вычислим дисперсию для нашего примера: 1. Вспомним, среднее значение у нас равнялось
- 18. Статистическая обработка данных. Методы математической статистики позволяют обрабатывать практически любые данные, главное подходить к обработке данных
- 20. Скачать презентацию
Слайд 2Статистическая обработка данных.
Ребята, мы переходим к изучению нового раздела, связанного с вопросами
Статистическая обработка данных.
Ребята, мы переходим к изучению нового раздела, связанного с вопросами

Слайд 3Статистическая обработка данных.
Давайте рассмотрим какой-нибудь пример, где нам может пригодиться обработка информации.
Статистическая обработка данных.
Давайте рассмотрим какой-нибудь пример, где нам может пригодиться обработка информации.

Слайд 4Статистическая обработка данных.
В первую очередь надо как то сгруппировать и
Статистическая обработка данных.
В первую очередь надо как то сгруппировать и
Слайд 5Статистическая обработка данных.
Рассмотрим, как нашу таблицу можно представить графически. В виде
Статистическая обработка данных.
Рассмотрим, как нашу таблицу можно представить графически. В виде
Слайд 6Статистическая обработка данных.
Теперь давайте построим гистограмму: она позволяет так же наглядно
Статистическая обработка данных.
Теперь давайте построим гистограмму: она позволяет так же наглядно
Слайд 7Статистическая обработка данных.
Нам осталось построить еще один тип диаграммы – круговую
Статистическая обработка данных.
Нам осталось построить еще один тип диаграммы – круговую
Слайд 8Статистическая обработка данных.
Ну вот, мы с вами научились немного обрабатывать данные.
Давайте
Статистическая обработка данных.
Ну вот, мы с вами научились немного обрабатывать данные.
Давайте

Слайд 9Статистическая обработка данных.
Но на этом обработка информации не заканчивается, для нашего ряда
Статистическая обработка данных.
Но на этом обработка информации не заканчивается, для нашего ряда

Слайд 10Статистическая обработка данных.
Среднее значение выборки. Суммируя все результаты и поделив на
Статистическая обработка данных.
Среднее значение выборки. Суммируя все результаты и поделив на

Слайд 11Статистическая обработка данных.
Варианта измерения – каждое число встретившиеся в результате измерения. В
Статистическая обработка данных.
Варианта измерения – каждое число встретившиеся в результате измерения. В

Слайд 12Статистическая обработка данных.
При составлении таблицы, не всегда получается, что варианты расположены через
Статистическая обработка данных.
При составлении таблицы, не всегда получается, что варианты расположены через
Слайд 13Статистическая обработка данных.
Варианта измерения – каждое число встретившиеся в результате измерения. В
Статистическая обработка данных.
Варианта измерения – каждое число встретившиеся в результате измерения. В

Слайд 14Статистическая обработка данных.
Частота варианты– числовая характеристика, показывающая часть или долю которую составляет
Статистическая обработка данных.
Частота варианты– числовая характеристика, показывающая часть или долю которую составляет
Слайд 15Статистическая обработка данных.
Вернемся к среднему значению, данная числовая характеристика часто является очень
Статистическая обработка данных.
Вернемся к среднему значению, данная числовая характеристика часто является очень

Слайд 16Статистическая обработка данных.
Еще одна важная числовая характеристика – Дисперсия, или разброс значений
Статистическая обработка данных.
Еще одна важная числовая характеристика – Дисперсия, или разброс значений

Слайд 17Статистическая обработка данных.
Давайте вычислим дисперсию для нашего примера:
1. Вспомним, среднее значение у
Статистическая обработка данных.
Давайте вычислим дисперсию для нашего примера:
1. Вспомним, среднее значение у
Слайд 18Статистическая обработка данных.
Методы математической статистики позволяют обрабатывать практически любые данные, главное подходить
Статистическая обработка данных.
Методы математической статистики позволяют обрабатывать практически любые данные, главное подходить

 Информационные системы и программирование
Информационные системы и программирование Ввод информации в память компьютера
Ввод информации в память компьютера Психологическое консультирование онлайн в условиях ЧС, карантина
Психологическое консультирование онлайн в условиях ЧС, карантина Разработка программного обеспечения для управления справочником Самолёты на языке С#
Разработка программного обеспечения для управления справочником Самолёты на языке С# Стилевое оформление текста
Стилевое оформление текста Современный автор, это кто
Современный автор, это кто Основные информационные процессы и их реализация с помощью компьютера. Лекция 4
Основные информационные процессы и их реализация с помощью компьютера. Лекция 4 Периферийные устройства
Периферийные устройства Ақпараттық технологиялардың өмірлік циклі
Ақпараттық технологиялардың өмірлік циклі Виртуальное путешествие по Северной Америке
Виртуальное путешествие по Северной Америке Создание сайта Сервисы Google
Создание сайта Сервисы Google Показ доработок версии 10.2.310pptx
Показ доработок версии 10.2.310pptx Структуры данных. Запись
Структуры данных. Запись Функции и модули 1
Функции и модули 1 CRM система НААБ. Виртуальное рабочее место НААБ
CRM система НААБ. Виртуальное рабочее место НААБ Методы классов в С++. (Лекция 5)
Методы классов в С++. (Лекция 5) Kurilka Gutenberga
Kurilka Gutenberga Построение отказоустойчивых распределенных систем хранения данных на основе модулярной арифметики
Построение отказоустойчивых распределенных систем хранения данных на основе модулярной арифметики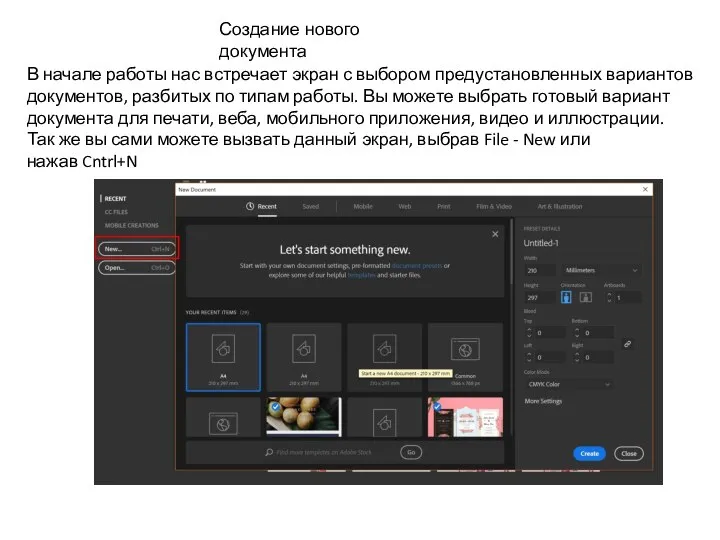 Создание нового документа
Создание нового документа Правила безопасности в интернете
Правила безопасности в интернете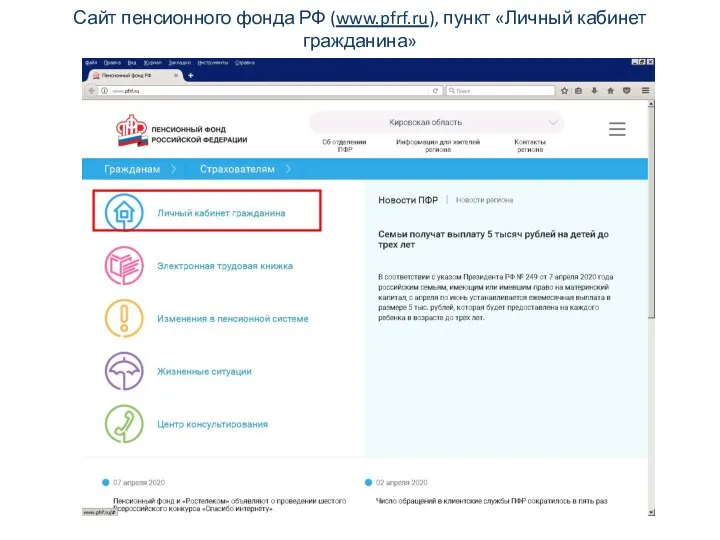 Заполнение интерактивной формы заявления. Сайт пенсионного фонда РФ
Заполнение интерактивной формы заявления. Сайт пенсионного фонда РФ Lektsia_dlya_VK_textovy_protsessor (1)
Lektsia_dlya_VK_textovy_protsessor (1) Информация, информационные процессы и информационное общество
Информация, информационные процессы и информационное общество Интернет как источник информационных ресурсов
Интернет как источник информационных ресурсов МУ к КП
МУ к КП 3D Измерительная компьютерная система Сcar-O-Tronic Сlassic
3D Измерительная компьютерная система Сcar-O-Tronic Сlassic Информационные процессы. Обработка информации. 7 класс
Информационные процессы. Обработка информации. 7 класс Операционные системы, среды и оболочки. Файловая система. Физическая организация
Операционные системы, среды и оболочки. Файловая система. Физическая организация