- Презентация1

Содержание
- 2. Информационное обеспечение и информационный фонд САПР Информационное обеспечение САПР состоит из информационного фонда и средств управления
- 3. Информационный фонд Информационный фонд включает в себя информацию для выполнения автоматизированного проектирования, и представляется в виде
- 4. Банки данных Основу информационного обеспечения САПР составляют банки данных, состоящие из баз данных и систем управления
- 5. Определения БД База данных — структурированная совокупность взаимосвязанных данных, относящихся к конкретной предметной области. База данных
- 6. Электронные таблицы и реляционные СУБД (РСУБД): Все РСУБД предназначены для обработки очень больших объемов данных —
- 7. Любая база данных должна обладать следующими свойствами: интегрированностью, направленной на решение широкого круга задач; структурированностью; взаимосвязанностью;
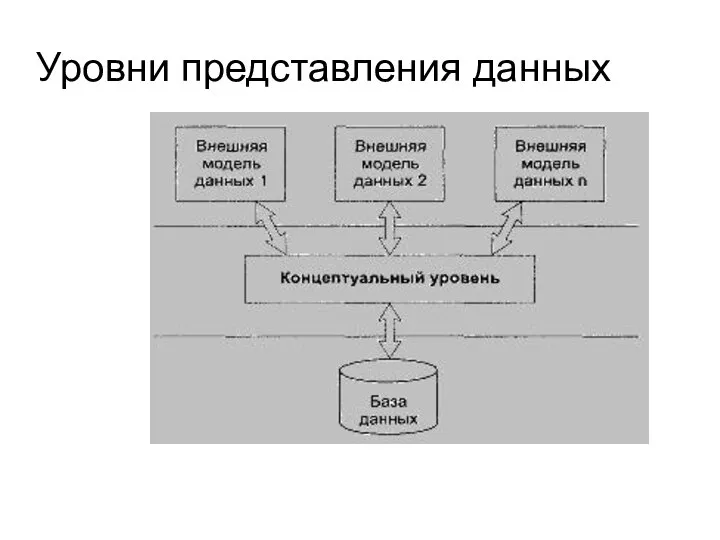
- 8. Независимость описания данных достигается за счет построения двух уровней представления данных: логического и физического. На логическом
- 9. Уровни представления данных
- 10. Независимость данных Физический уровень( первый) – внешние модели и концептуальная модель не подвержены изменениям физической памяти
- 11. В современной технологии БД предполагается, что создание БД, ее поддержка и обеспечение доступа пользователей к ней
- 12. СУБД реализует два внутренних интерфейса: между логическими структурами данных в программных модулях и различными программными модулями
- 13. Преимущества централизованного подхода в управлении данными. Возможность сокращения избыточности хранимых данных возможность устранения (до некоторой степени)
- 14. Основные функции СУБД Создание БД, включая формирование описаний объектов, их свойств и отношений. Первоначальная загрузка реализаций.
- 15. Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной
- 16. Лекция 2 Жизненный цикл базы данных Этапы проектирования БД Методология IDEF1X
- 18. Этапы проектирования БД Инфологическое проектирование Датологическое проектирование Логическое проектирование Физическое проектирование
- 19. Инфологическое проектирование Задача инфологического проектирования - получение семантических или смысловых моделей, отражающих информационное содержание конкретной предметной
- 20. Предметная область - часть реального мира, которая описывается или моделируется с помощью баз данных и использующих
- 21. Логическое проектирование Задача логического проектирования - организация данных, выделенных на предыдущем этапе проектирования в форму принятую
- 22. Физическое проектирование Задача физического проектирования - выбор рациональной структуры хранения данных и методов доступа к ним,
- 23. Основные этапы проектирования реляционной СУБД Выделение ПО, анализ требований пользователей. Разработка представлений пользователей , то есть
- 24. Методология IDEF1X Методология IDEF1X определяет стандарты терминологии, используемой при информационном моделировании, и графического изображения типовых элементов
- 25. Процесс построения информационной модели определение сущностей; определение связей между сущностями; задание первичных и альтернативных ключей; определение
- 26. Определение сущностей Каждая сущность должна иметь уникальное имя, обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно
- 27. Определение сущностей
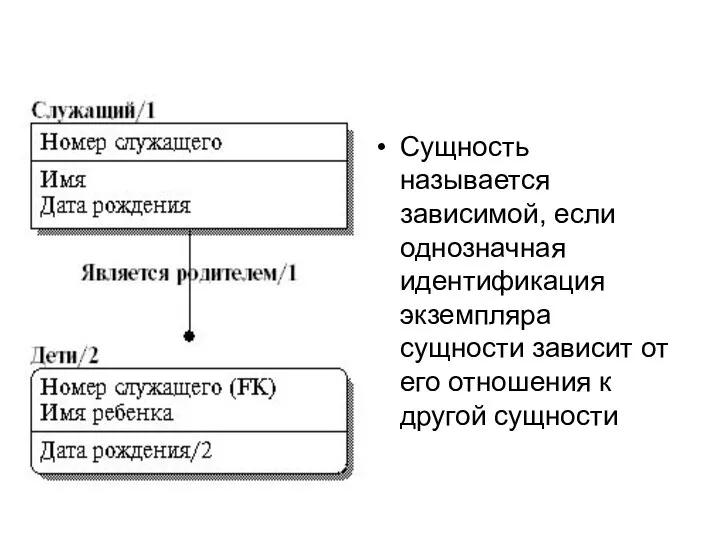
- 28. Сущность называется независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с
- 29. Сущность называется зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности
- 30. Определение связей На диаграмме связи представляются пятью основными элементами информации: тип связи (идентифицирующая, неидентифицирующая, полная/неполная категория,
- 31. Определение связей Наиболее часто в модели используется связь "родитель-потомок" или функциональная зависимость между двумя сущностями, при
- 32. Связь называется идентифицирующей, если экземпляр дочерней сущности идентифицируется через ее связь с родительской сущностью. Атрибуты, составляющие
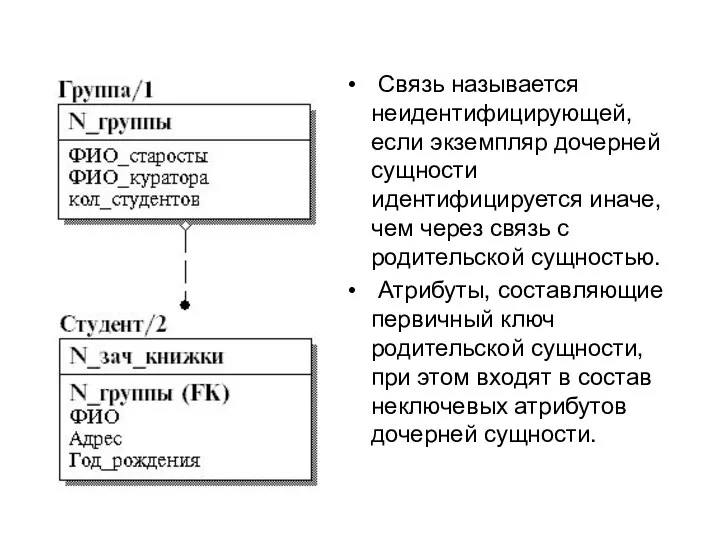
- 33. Связь называется неидентифицирующей, если экземпляр дочерней сущности идентифицируется иначе, чем через связь с родительской сущностью. Атрибуты,
- 34. Миграция атрибутов При определении связи происходит миграция атрибутов первичного ключа родительской сущности в соответствующую область атрибутов
- 35. Мощность связи Мощность связи представляет собой отношение количества экземпляров родительской сущности к соответствующему количеству экземпляров дочерней
- 36. Мощность связи В соответствии с методологией IDEF1X, предоставляется 4 варианта для n, которые изображаются дополнительным символом
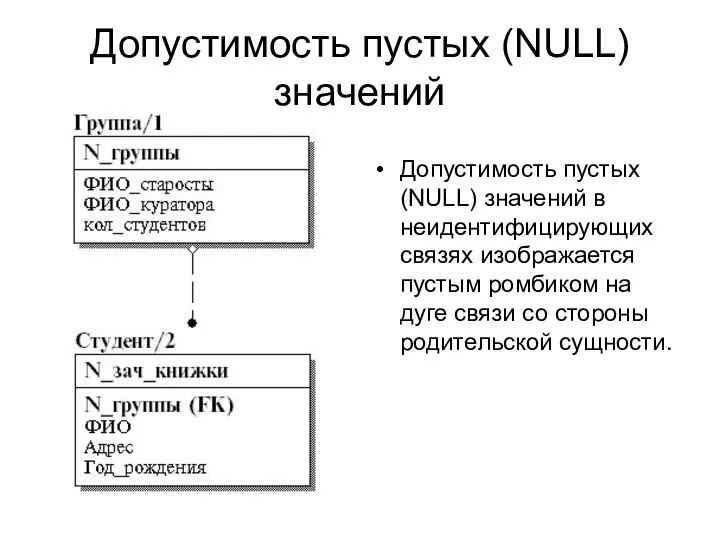
- 37. Допустимость пустых (NULL) значений Допустимость пустых (NULL) значений в неидентифицирующих связях изображается пустым ромбиком на дуге
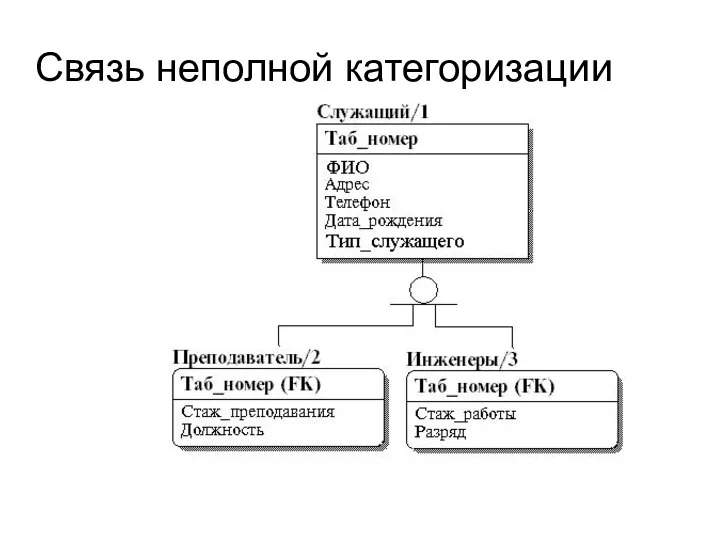
- 38. Связи категоризации Некоторые сущности определяют целую категорию объектов одного типа. Для выражения такой связи вводится тип
- 39. Связь неполной категоризации
- 40. Связь полной категоризации
- 41. Первичный ключ - это атрибут или минимальный набор атрибутов, уникально идентифицирующий экземпляр сущности. Если несколько наборов
- 42. Приведение модели к требуемому уровню нормальной формы В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или
- 43. Приведение модели к требуемому уровню нормальной формы Во второй нормальной форме устраняются атрибуты, зависящие только от
- 44. Приведение модели к требуемому уровню нормальной формы В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов,
- 45. Case - средство ERwin ERwin - средство концептуального моделирования БД, использующее методологию IDEF1X. ERwin реализует проектирование
- 46. Процесс проектирования с помощью ERwin описание модели на логическом уровне (построение инфологической модели определение: сущностей, связей,
- 47. Уровни представления ERwin Логический уровень представления соответствует этапу инфологическому проектирования или концептуальной схеме. Целевая СУБД, имена
- 48. преимущества применения ERwin существенное повышение скорости разработки за счет мощного редактора диаграмм, автоматической генерации базы данных,
- 50. Скачать презентацию
Слайд 2
Информационное обеспечение и информационный фонд САПР
Информационное обеспечение САПР состоит из информационного фонда
Информационное обеспечение и информационный фонд САПР
Информационное обеспечение САПР состоит из информационного фонда

Слайд 3Информационный фонд
Информационный фонд включает в себя информацию для выполнения автоматизированного проектирования, и
Информационный фонд
Информационный фонд включает в себя информацию для выполнения автоматизированного проектирования, и

Слайд 4Банки данных
Основу информационного обеспечения САПР составляют банки данных, состоящие из баз данных и систем управления
Банки данных
Основу информационного обеспечения САПР составляют банки данных, состоящие из баз данных и систем управления

Слайд 5Определения БД
База данных — структурированная совокупность взаимосвязанных данных, относящихся к конкретной предметной
Определения БД
База данных — структурированная совокупность взаимосвязанных данных, относящихся к конкретной предметной

Слайд 6Электронные таблицы и реляционные СУБД (РСУБД):
Все РСУБД предназначены для обработки очень больших
Электронные таблицы и реляционные СУБД (РСУБД):
Все РСУБД предназначены для обработки очень больших

Слайд 7Любая база данных должна обладать следующими свойствами:
интегрированностью, направленной на решение широкого круга
Любая база данных должна обладать следующими свойствами:
интегрированностью, направленной на решение широкого круга

Слайд 8Независимость описания данных достигается за счет построения двух уровней представления данных: логического
Независимость описания данных достигается за счет построения двух уровней представления данных: логического

Слайд 9Уровни представления данных
Уровни представления данных
Слайд 10Независимость данных
Физический уровень( первый) – внешние модели и концептуальная модель не подвержены
Независимость данных
Физический уровень( первый) – внешние модели и концептуальная модель не подвержены

Слайд 11В современной технологии БД предполагается, что создание БД, ее поддержка и обеспечение
В современной технологии БД предполагается, что создание БД, ее поддержка и обеспечение

Слайд 12СУБД реализует два внутренних интерфейса:
между логическими структурами данных в программных модулях и
СУБД реализует два внутренних интерфейса:
между логическими структурами данных в программных модулях и

Слайд 13Преимущества централизованного подхода в управлении данными.
Возможность сокращения избыточности хранимых данных
возможность устранения
Преимущества централизованного подхода в управлении данными.
Возможность сокращения избыточности хранимых данных
возможность устранения

Слайд 14Основные функции СУБД
Создание БД, включая формирование описаний объектов, их свойств и отношений.
Основные функции СУБД
Создание БД, включая формирование описаний объектов, их свойств и отношений.

Слайд 15Программы, с помощью которых пользователи работают с базой данных, называются приложениями.
В
Программы, с помощью которых пользователи работают с базой данных, называются приложениями.
В

Слайд 16Лекция 2
Жизненный цикл базы данных
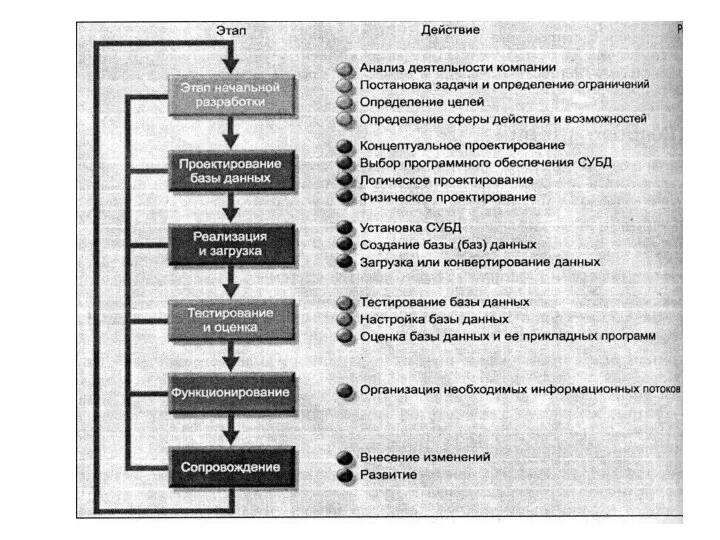
Этапы проектирования БД
Методология IDEF1X
Лекция 2
Жизненный цикл базы данных
Этапы проектирования БД
Методология IDEF1X

Слайд 18Этапы проектирования БД
Инфологическое проектирование
Датологическое проектирование
Логическое проектирование
Физическое проектирование
Этапы проектирования БД
Инфологическое проектирование
Датологическое проектирование
Логическое проектирование
Физическое проектирование

Слайд 19Инфологическое проектирование
Задача инфологического проектирования - получение семантических или смысловых моделей, отражающих информационное
Инфологическое проектирование
Задача инфологического проектирования - получение семантических или смысловых моделей, отражающих информационное

Слайд 20Предметная область - часть реального мира, которая описывается или моделируется с помощью
Предметная область - часть реального мира, которая описывается или моделируется с помощью

Слайд 21Логическое проектирование
Задача логического проектирования - организация данных, выделенных на предыдущем этапе проектирования
Логическое проектирование
Задача логического проектирования - организация данных, выделенных на предыдущем этапе проектирования

Слайд 22Физическое проектирование
Задача физического проектирования - выбор рациональной структуры хранения данных и методов
Физическое проектирование
Задача физического проектирования - выбор рациональной структуры хранения данных и методов

Слайд 23Основные этапы проектирования реляционной СУБД
Выделение ПО, анализ требований пользователей. Разработка представлений
Основные этапы проектирования реляционной СУБД
Выделение ПО, анализ требований пользователей. Разработка представлений

Слайд 24Методология IDEF1X
Методология IDEF1X определяет стандарты терминологии, используемой при информационном моделировании, и
Методология IDEF1X
Методология IDEF1X определяет стандарты терминологии, используемой при информационном моделировании, и

Слайд 25Процесс построения информационной модели
определение сущностей;
определение связей между сущностями;
задание первичных
Процесс построения информационной модели
определение сущностей;
определение связей между сущностями;
задание первичных

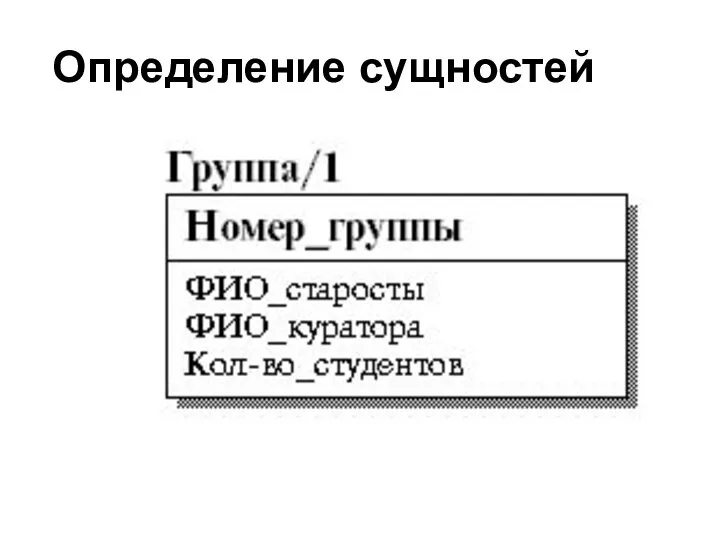
Слайд 26Определение сущностей
Каждая сущность должна иметь уникальное имя, обладать уникальным идентификатором. Каждый
Определение сущностей
Каждая сущность должна иметь уникальное имя, обладать уникальным идентификатором. Каждый

Слайд 27Определение сущностей
Определение сущностей
Слайд 28Сущность называется независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без
Сущность называется независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без
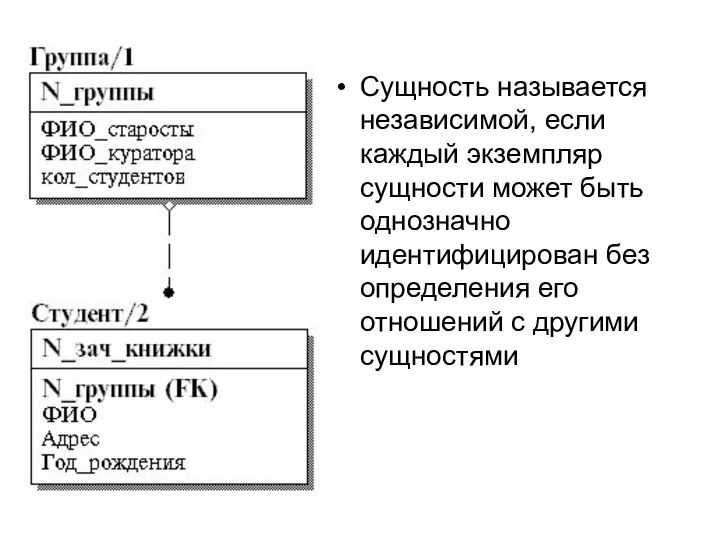
Слайд 29Сущность называется зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения
Сущность называется зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения
Слайд 30Определение связей
На диаграмме связи представляются пятью основными элементами информации:
тип связи
Определение связей
На диаграмме связи представляются пятью основными элементами информации:
тип связи

Слайд 31Определение связей
Наиболее часто в модели используется связь "родитель-потомок" или функциональная зависимость между
Определение связей
Наиболее часто в модели используется связь "родитель-потомок" или функциональная зависимость между

Слайд 32 Связь называется идентифицирующей, если экземпляр дочерней сущности идентифицируется через ее связь с
Связь называется идентифицирующей, если экземпляр дочерней сущности идентифицируется через ее связь с

Слайд 33 Связь называется неидентифицирующей, если экземпляр дочерней сущности идентифицируется иначе, чем через связь
Связь называется неидентифицирующей, если экземпляр дочерней сущности идентифицируется иначе, чем через связь
Слайд 34Миграция атрибутов
При определении связи происходит миграция атрибутов первичного ключа родительской сущности в
Миграция атрибутов
При определении связи происходит миграция атрибутов первичного ключа родительской сущности в

Слайд 35Мощность связи
Мощность связи представляет собой отношение количества экземпляров родительской сущности к соответствующему
Мощность связи
Мощность связи представляет собой отношение количества экземпляров родительской сущности к соответствующему

Слайд 36Мощность связи
В соответствии с методологией IDEF1X, предоставляется 4 варианта для n, которые
Мощность связи
В соответствии с методологией IDEF1X, предоставляется 4 варианта для n, которые

Слайд 37Допустимость пустых (NULL) значений
Допустимость пустых (NULL) значений в неидентифицирующих связях изображается пустым
Допустимость пустых (NULL) значений
Допустимость пустых (NULL) значений в неидентифицирующих связях изображается пустым
Слайд 38Связи категоризации
Некоторые сущности определяют целую категорию объектов одного типа. Для выражения
Связи категоризации
Некоторые сущности определяют целую категорию объектов одного типа. Для выражения

Слайд 39Связь неполной категоризации
Связь неполной категоризации
Слайд 40Связь полной категоризации
Связь полной категоризации
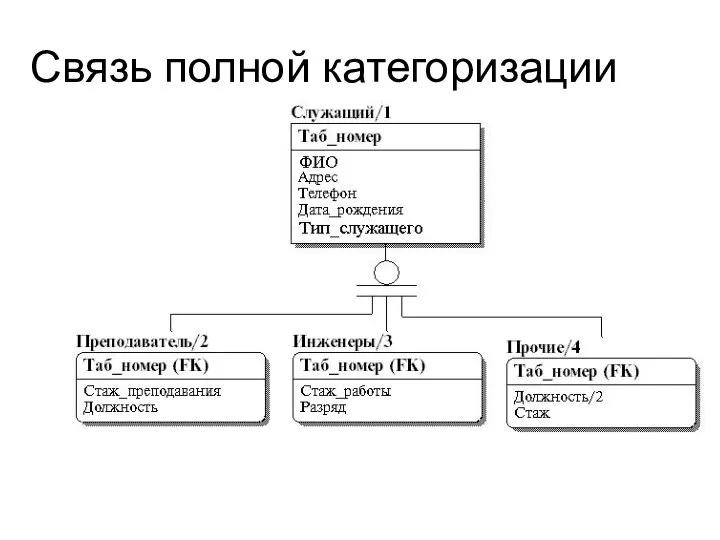
Слайд 41 Первичный ключ - это атрибут или минимальный набор атрибутов, уникально идентифицирующий экземпляр
Первичный ключ - это атрибут или минимальный набор атрибутов, уникально идентифицирующий экземпляр

Слайд 42Приведение модели к требуемому уровню нормальной формы
В первой нормальной форме ER-схемы
Приведение модели к требуемому уровню нормальной формы
В первой нормальной форме ER-схемы

Слайд 43Приведение модели к требуемому уровню нормальной формы
Во второй нормальной форме устраняются атрибуты,
Приведение модели к требуемому уровню нормальной формы
Во второй нормальной форме устраняются атрибуты,

Слайд 44Приведение модели к требуемому уровню нормальной формы
В третьей нормальной форме устраняются атрибуты,
Приведение модели к требуемому уровню нормальной формы
В третьей нормальной форме устраняются атрибуты,

Слайд 45Case - средство ERwin
ERwin - средство концептуального моделирования БД, использующее методологию IDEF1X.
Case - средство ERwin
ERwin - средство концептуального моделирования БД, использующее методологию IDEF1X.

Слайд 46Процесс проектирования с помощью ERwin
описание модели на логическом уровне (построение инфологической модели
Процесс проектирования с помощью ERwin
описание модели на логическом уровне (построение инфологической модели

Слайд 47Уровни представления ERwin
Логический уровень представления соответствует этапу инфологическому проектирования или концептуальной
Уровни представления ERwin
Логический уровень представления соответствует этапу инфологическому проектирования или концептуальной

Слайд 48преимущества применения ERwin
существенное повышение скорости разработки за счет мощного редактора диаграмм,
преимущества применения ERwin
существенное повышение скорости разработки за счет мощного редактора диаграмм,

 Главный вычислительный центр – филиал ОАО РЖД
Главный вычислительный центр – филиал ОАО РЖД Цифровой оператор как инструмент организации образовательной деятельности
Цифровой оператор как инструмент организации образовательной деятельности Предикаты. Функторы. Алгоритмы STL. Лекция 14
Предикаты. Функторы. Алгоритмы STL. Лекция 14 Системы счисления
Системы счисления Приключения Скорпиона
Приключения Скорпиона Презентация на тему Total Commander
Презентация на тему Total Commander  Hometask in VK. Copy the text, choose the correct variant
Hometask in VK. Copy the text, choose the correct variant Приём заявлений в 1 класс
Приём заявлений в 1 класс Программирование и алгоритмизация. Основы программирования. Лекция 4
Программирование и алгоритмизация. Основы программирования. Лекция 4 Применение цифровых ресурсов в технологическом образовании
Применение цифровых ресурсов в технологическом образовании Обзор электронного контента от ведущих мировых издательств: Taylor & Francis и Brill
Обзор электронного контента от ведущих мировых издательств: Taylor & Francis и Brill Безопасный интернет
Безопасный интернет Прием подписки (в плагине)
Прием подписки (в плагине) Общественно-политическая газета Областная
Общественно-политическая газета Областная Оценка эффективности алгоритмов по памяти и времени. Вычисление веса двоичного вектора
Оценка эффективности алгоритмов по памяти и времени. Вычисление веса двоичного вектора Автор – Широкова Л.В. Учитель информатики МОУ лицей № 41 Город Кострома
Автор – Широкова Л.В. Учитель информатики МОУ лицей № 41 Город Кострома Рекомендации по созданию сайта
Рекомендации по созданию сайта Информационная безопасность
Информационная безопасность Прототип автоматизированной системы поиска дубликатов документов для цифровых научных библиотек
Прототип автоматизированной системы поиска дубликатов документов для цифровых научных библиотек Проектирование структуры базы данных
Проектирование структуры базы данных Тест по программированию
Тест по программированию Для представления сервера PlayerWorld
Для представления сервера PlayerWorld Отчёт о прохождении практики в коммуникационном агентстве полного цикла Redline PR
Отчёт о прохождении практики в коммуникационном агентстве полного цикла Redline PR Государственная политика в информационной сфере
Государственная политика в информационной сфере Violence in Video Games
Violence in Video Games Свойства логических операций
Свойства логических операций Тизерная кухня. (День 6)
Тизерная кухня. (День 6) С кого человек списал компьютер? 5 класс
С кого человек списал компьютер? 5 класс