- Системы распознавания речи: базовые принципы и алгоритмы

Содержание
- 2. Задача распознавания речи Система распознавания речи — устройство, которое осуществляет автоматическую трансляцию речи в текст. Оно
- 3. Зашумленный канал
- 4. Sequence-labeling и обработка естественного языка Secretariat/NNP is/BEZ expected/VBN to/TO race/?? tomorrow/ Рассмотрим предложение: Определим часть речи
- 5. Простейшая модель вывода Выберем набор релевантных признаков Припишем им числовые значения — «веса». Веса могут быть
- 6. Обработка естественного языка и декодирование Большое количество задач NLP может быть так или иначе сведено к
- 7. Модель зашумленного канала в распознавании речи
- 8. Sequence-labelling и распознавание речи Скрытые состояния — фонемы/аллофоны Наблюдаемые состояния — векторы акустических признаков В основе
- 9. Представление речевого сигнала в виде дискретной последовательности
- 10. Общая схема системы распознавания речи
- 11. Основные разделы курса Выделение акустических признаков Дискретное преобразование Фурье и его разновидности MFCC (mel-frequency cepstral coefficients)
- 12. Коротко о MATLAB MATLAB — популярный программный пакет для инженерных вычислений и моделирования Поддерживает встроенный язык
- 14. Скачать презентацию
Слайд 2Задача распознавания речи
Система распознавания речи — устройство, которое осуществляет автоматическую трансляцию речи
Задача распознавания речи
Система распознавания речи — устройство, которое осуществляет автоматическую трансляцию речи

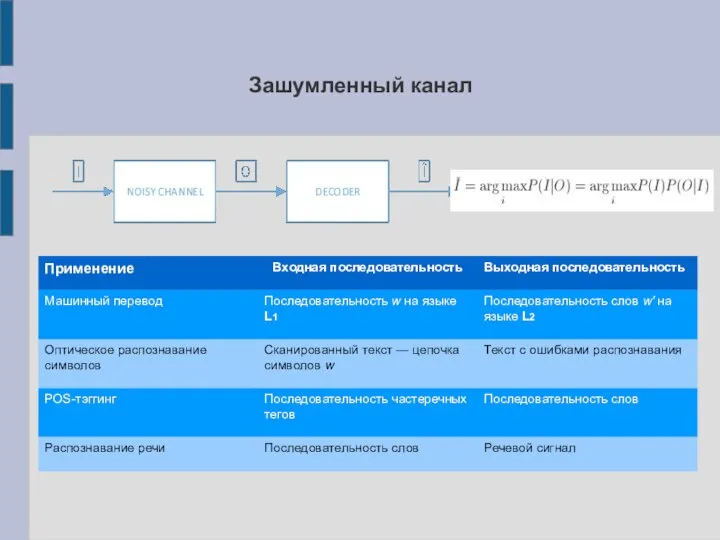
Слайд 3Зашумленный канал
Зашумленный канал
Слайд 4Sequence-labeling и обработка естественного языка
Secretariat/NNP is/BEZ expected/VBN to/TO race/?? tomorrow/
Рассмотрим предложение:
Определим часть
Sequence-labeling и обработка естественного языка
Secretariat/NNP is/BEZ expected/VBN to/TO race/?? tomorrow/
Рассмотрим предложение:
Определим часть

Слайд 5Простейшая модель вывода
Выберем набор релевантных признаков
Припишем им числовые значения — «веса».
Простейшая модель вывода
Выберем набор релевантных признаков
Припишем им числовые значения — «веса».

Слайд 6Обработка естественного языка и декодирование
Большое количество задач NLP может быть так или
Обработка естественного языка и декодирование
Большое количество задач NLP может быть так или

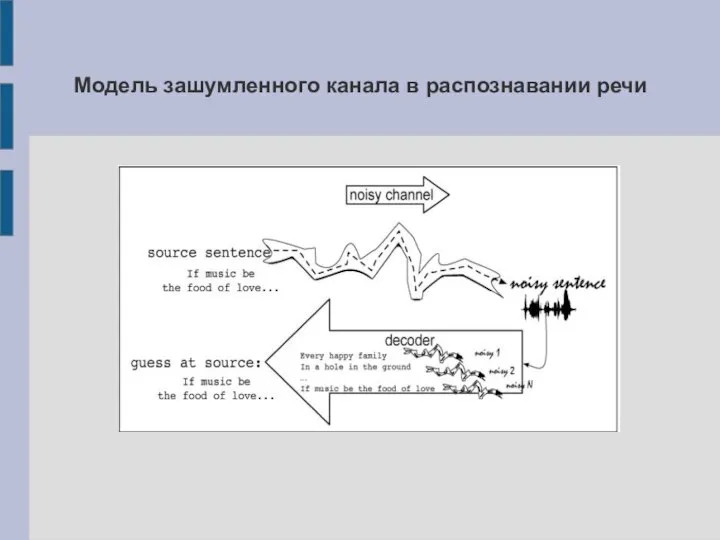
Слайд 7Модель зашумленного канала в распознавании речи
Модель зашумленного канала в распознавании речи
Слайд 8Sequence-labelling и распознавание речи
Скрытые состояния — фонемы/аллофоны
Наблюдаемые состояния — векторы акустических признаков
В
Sequence-labelling и распознавание речи
Скрытые состояния — фонемы/аллофоны
Наблюдаемые состояния — векторы акустических признаков
В

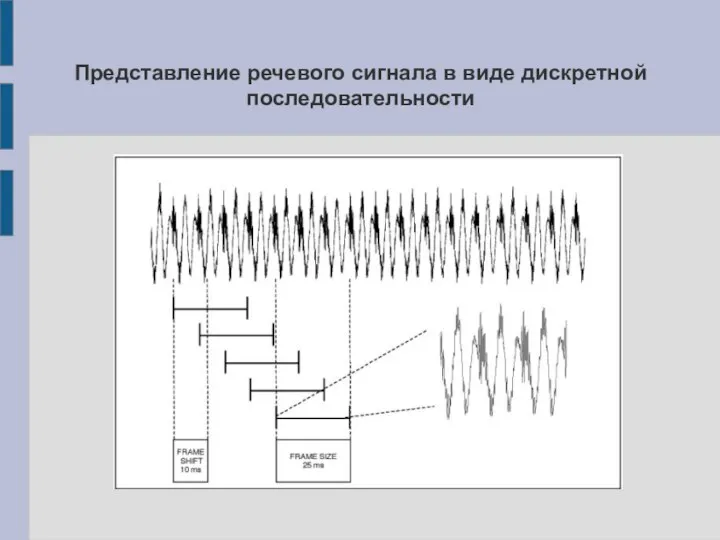
Слайд 9Представление речевого сигнала в виде дискретной последовательности
Представление речевого сигнала в виде дискретной последовательности
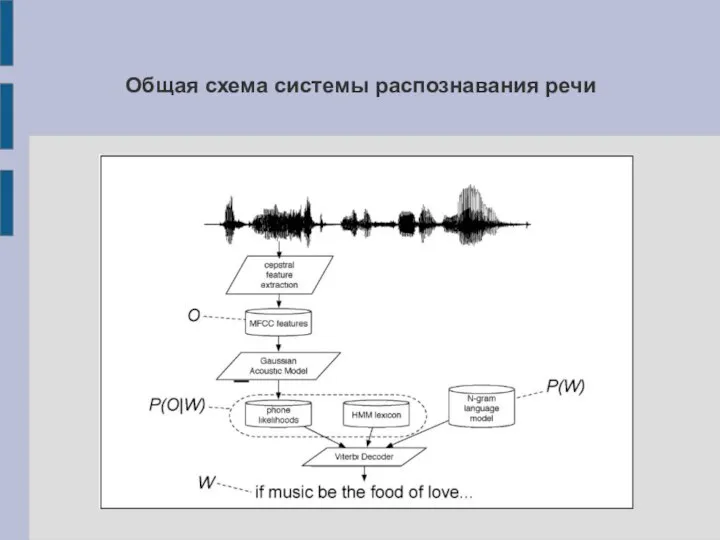
Слайд 10Общая схема системы распознавания речи
Общая схема системы распознавания речи
Слайд 11Основные разделы курса
Выделение акустических признаков
Дискретное преобразование Фурье и его разновидности
MFCC (mel-frequency cepstral
Основные разделы курса
Выделение акустических признаков
Дискретное преобразование Фурье и его разновидности
MFCC (mel-frequency cepstral

Слайд 12Коротко о MATLAB
MATLAB — популярный программный пакет для инженерных вычислений и моделирования
Поддерживает
Коротко о MATLAB
MATLAB — популярный программный пакет для инженерных вычислений и моделирования
Поддерживает

 V значит Vilki
V значит Vilki Платформа Freescale Semiconductor для реализации беспроводных решений ZigBee / 802.15.4 / SMAC
Платформа Freescale Semiconductor для реализации беспроводных решений ZigBee / 802.15.4 / SMAC Геймификация, микрообучение, виртуальная реальность
Геймификация, микрообучение, виртуальная реальность Алгоритмы с результатом
Алгоритмы с результатом Работу выполнил Пестов Григорий Работу выполнил Пестов Григорий ученик 9г класса МОУ СОШ с УИОП пгт. Ленинское Учитель Е.И.
Работу выполнил Пестов Григорий Работу выполнил Пестов Григорий ученик 9г класса МОУ СОШ с УИОП пгт. Ленинское Учитель Е.И. 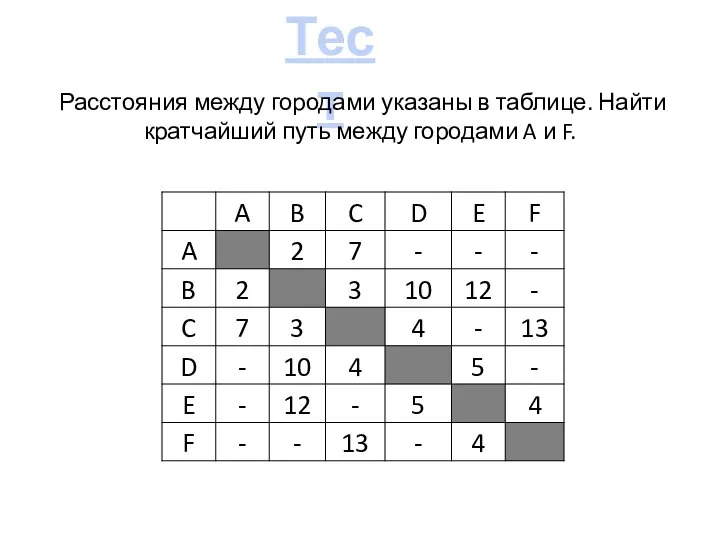 Кодирование информации
Кодирование информации Компьютерные сети
Компьютерные сети Цифровая трансформация живописи
Цифровая трансформация живописи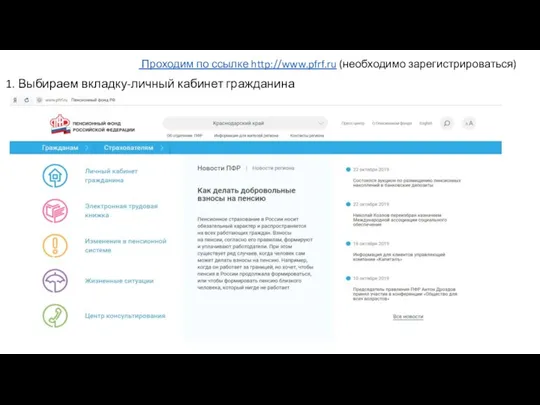 Выбираем вкладку - личный кабинет гражданина
Выбираем вкладку - личный кабинет гражданина Диаграммы классов и состояний
Диаграммы классов и состояний 5 наиболее популярных Instagram блогеров
5 наиболее популярных Instagram блогеров Front-end. Back-end
Front-end. Back-end История развития Интернета
История развития Интернета Стикеры в Paint Tool Sai. Мастер-класс Новогоднее настроение
Стикеры в Paint Tool Sai. Мастер-класс Новогоднее настроение Логические операции. Логические формулы
Логические операции. Логические формулы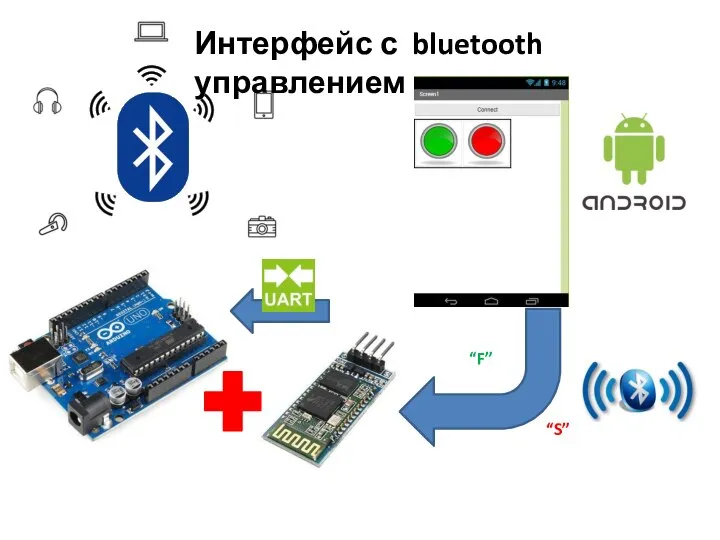 Интерфейс с bluetooth управлением
Интерфейс с bluetooth управлением Новые технологии в Русском музее Санкт-Петербурга
Новые технологии в Русском музее Санкт-Петербурга Система документирования радиолокационной информации
Система документирования радиолокационной информации Технология создания и обработки графической информации
Технология создания и обработки графической информации AMN – максимальный охват с минимальной конкуренцией. Контроль качества трафика
AMN – максимальный охват с минимальной конкуренцией. Контроль качества трафика Автоматизация тестирования пользовательского интерфейса
Автоматизация тестирования пользовательского интерфейса Кейс технологии. методология и содержание
Кейс технологии. методология и содержание Безопасный интрнет детям
Безопасный интрнет детям Поиск информации с помощью браузера Internet Explorer
Поиск информации с помощью браузера Internet Explorer Видеоролики и буктрейлеры. Теория
Видеоролики и буктрейлеры. Теория Архитектура компьютера. Виды программного обеспечения компьютеров
Архитектура компьютера. Виды программного обеспечения компьютеров Алгоритм струны в моделировании травления и осаждения слоев
Алгоритм струны в моделировании травления и осаждения слоев Своя игра 1
Своя игра 1