- Оптимизация обновления информационной базы

Содержание
- 2. Информация для технических специалистов Проблемы существовавшего механизма обновления Долго проходит монопольный этап обновления на больших базах
- 3. Информация для технических специалистов Решение проблем Радикальное сокращение количества монопольных обработчиков обновления если раньше монопольно обновлялась
- 4. Информация для технических специалистов Параллельный режим выполнения отложенных обработчиков обновления Раньше все обработчики выполнялись последовательно Порция
- 5. Информация для технических специалистов Параллельный режим выполнения отложенных обработчиков обновления Теперь обработчики выполняются параллельно Порция 1
- 6. Информация для технических специалистов Параллельный режим выполнения отложенных обработчиков обновления Параллельный режим выполнения вкупе с правилом
- 7. Информация для технических специалистов Очереди отложенной обработки данных По разным причинам написать обработчики полностью независимыми не
- 8. Информация для технических специалистов Очереди отложенной обработки данных Особенности использования очередей отложенной обработки данных очереди присваиваются
- 9. Информация для технических специалистов Блокировка необновленных данных от изменения На время отложенного обновления блокируются формы объектов
- 10. Информация для технических специалистов Управление процессом обработки данных Повышение приоритета обновления по умолчанию перед обработкой очередной
- 11. Информация для технических специалистов Управление процессом обработки данных Появилась возможность повышать приоритет отдельных обработчиков данных при
- 12. Информация для технических специалистов Особенности обновления РИБ (только в УТ 11) Полный РИБ обновляется конфигурация главного
- 13. Информация для технических специалистов Особенности обновления РИБ (только в УТ 11) РИБ с фильтрами – отличия
- 14. Информация для технических специалистов Заключение По данным наших замеров (в т.ч. на базах предоставленных пользователями), монопольная
- 15. Информация для технических специалистов Планы по развитию механизма Большая часть доработок механизмов обновления сейчас реализована по
- 17. Скачать презентацию
Слайд 2Информация для технических специалистов
Проблемы существовавшего механизма обновления
Долго проходит монопольный этап обновления
на больших
Информация для технических специалистов
Проблемы существовавшего механизма обновления
Долго проходит монопольный этап обновления
на больших

Слайд 3Информация для технических специалистов
Решение проблем
Радикальное сокращение количества монопольных обработчиков обновления
если раньше монопольно
Информация для технических специалистов
Решение проблем
Радикальное сокращение количества монопольных обработчиков обновления
если раньше монопольно

Слайд 4Информация для технических специалистов
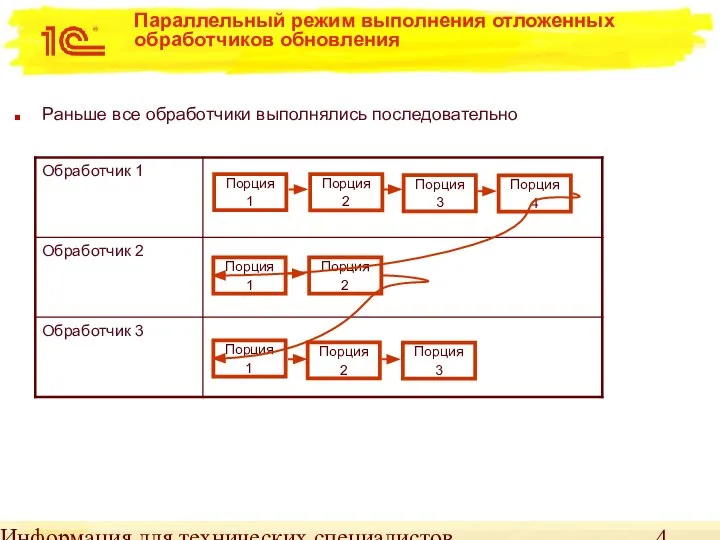
Параллельный режим выполнения отложенных обработчиков обновления
Раньше все обработчики выполнялись
Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Раньше все обработчики выполнялись
Слайд 5Информация для технических специалистов
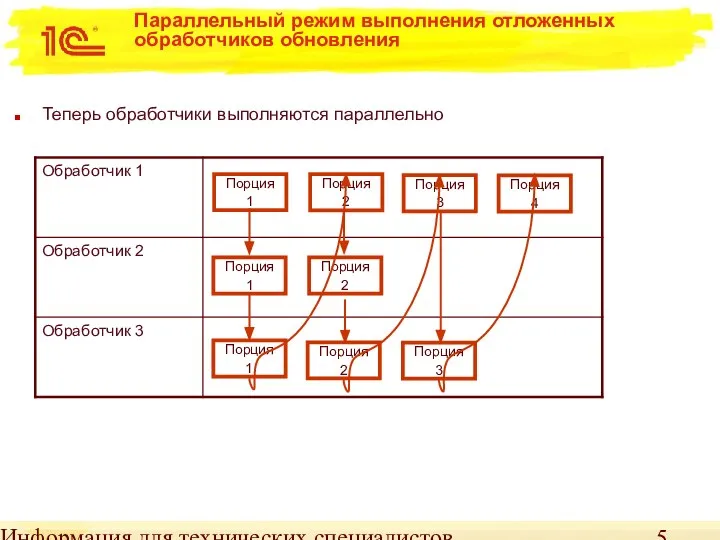
Параллельный режим выполнения отложенных обработчиков обновления
Теперь обработчики выполняются параллельно
Порция
Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Теперь обработчики выполняются параллельно
Порция
Слайд 6Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Параллельный режим выполнения вкупе
Информация для технических специалистов
Параллельный режим выполнения отложенных обработчиков обновления
Параллельный режим выполнения вкупе

Слайд 7Информация для технических специалистов
Очереди отложенной обработки данных
По разным причинам написать обработчики полностью
Информация для технических специалистов
Очереди отложенной обработки данных
По разным причинам написать обработчики полностью

Слайд 8Информация для технических специалистов
Очереди отложенной обработки данных
Особенности использования очередей отложенной обработки данных
очереди
Информация для технических специалистов
Очереди отложенной обработки данных
Особенности использования очередей отложенной обработки данных
очереди

Слайд 9Информация для технических специалистов
Блокировка необновленных данных от изменения
На время отложенного обновления блокируются
формы
Информация для технических специалистов
Блокировка необновленных данных от изменения
На время отложенного обновления блокируются
формы

Слайд 10Информация для технических специалистов
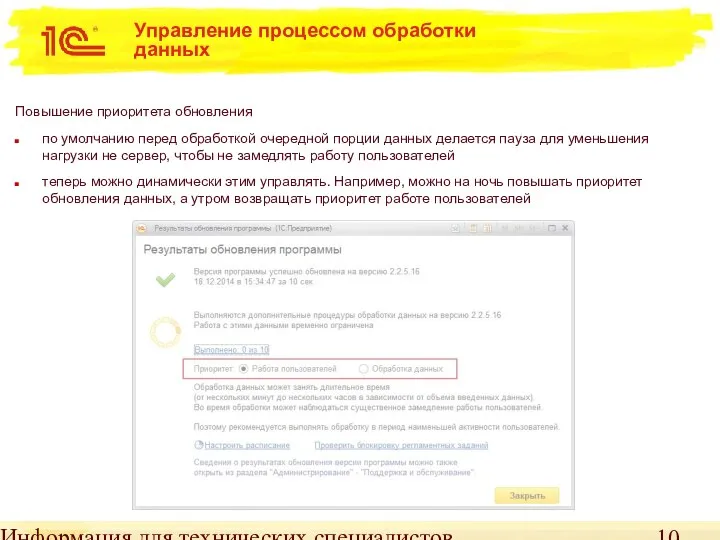
Управление процессом обработки данных
Повышение приоритета обновления
по умолчанию перед обработкой
Информация для технических специалистов
Управление процессом обработки данных
Повышение приоритета обновления
по умолчанию перед обработкой
Слайд 11Информация для технических специалистов
Управление процессом обработки данных
Появилась возможность повышать приоритет отдельных обработчиков
Информация для технических специалистов
Управление процессом обработки данных
Появилась возможность повышать приоритет отдельных обработчиков

Слайд 12Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
Полный РИБ
обновляется конфигурация
Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
Полный РИБ
обновляется конфигурация

Слайд 13Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
РИБ с фильтрами
Информация для технических специалистов
Особенности обновления РИБ (только в УТ 11)
РИБ с фильтрами

Слайд 14Информация для технических специалистов
Заключение
По данным наших замеров (в т.ч. на базах предоставленных
Информация для технических специалистов
Заключение
По данным наших замеров (в т.ч. на базах предоставленных

Слайд 15Информация для технических специалистов
Планы по развитию механизма
Большая часть доработок механизмов обновления сейчас
Информация для технических специалистов
Планы по развитию механизма
Большая часть доработок механизмов обновления сейчас

 Креатив и оптимизация: друзья или враги?
Креатив и оптимизация: друзья или враги? Экономика и финансы. Творческая школа Хорошие презентации
Экономика и финансы. Творческая школа Хорошие презентации Методы обработки информации
Методы обработки информации Устройство ПК
Устройство ПК 5 Типы данных
5 Типы данных Носители информации. Кодирование информации. Способы кодирования информации
Носители информации. Кодирование информации. Способы кодирования информации Operators and Expression / 1 of 25
Operators and Expression / 1 of 25 Компьютерное зрение
Компьютерное зрение Комплексный интернет-маркетинг. Аналитика. Академия Digital-профессий
Комплексный интернет-маркетинг. Аналитика. Академия Digital-профессий Редактирование текста
Редактирование текста Вход в личный кабинет
Вход в личный кабинет Дополнительные устройства компьютера
Дополнительные устройства компьютера Планерка. Семейство IG
Планерка. Семейство IG Шаблон паспорта проектной идеи
Шаблон паспорта проектной идеи Измерение текстовой информации
Измерение текстовой информации Комплектующие компьютера
Комплектующие компьютера Разработка архитектурного прототипа системы для репетиторства
Разработка архитектурного прототипа системы для репетиторства Делаем первый проект
Делаем первый проект Свинограм
Свинограм Базы данных
Базы данных Використання інформаційних технологій у вирішенні галузевих завдань
Використання інформаційних технологій у вирішенні галузевих завдань Эллиптическое шифрование
Эллиптическое шифрование Диаграммы и графики
Диаграммы и графики Базы данных
Базы данных Информационные технологии на уроках
Информационные технологии на уроках Медиация в моей жизни
Медиация в моей жизни Растровая и векторная графика
Растровая и векторная графика Признаки предметов
Признаки предметов