- Методы кластеризации

Содержание
- 2. Задачи интеллектуального анализа данных Задачи ИАД Описательные Ассоциативные правила Кластеризация Классификация Прогнозирование Предсказательные
- 3. Введение Задача кластеризации состоит в разделении исследуемого множества объектов на группы «похожих» объектов, называемых кластерами Решение
- 4. Кластеризация отличается от классификации тем, что этап обучения на примерах отсутствует В задачах классификации множество классов
- 5. Задача кластеризации часто решается на начальных этапах исследования, когда о данных мало что известно Ее решение
- 6. ПРИМЕР –кластеризация результатов поиска
- 8. Формальная постановка задачи Дано множество данных, состоящее из N объектов (векторов): S1, S2, …, SN Каждый
- 9. Формальная постановка задачи Таким образом, i-й объект можно записать в виде: Si = (xi1, xi2, …,
- 10. Формальная постановка задачи Требуется: найти способ сравнения d(Sp, Sq) объектов между собой (меру сходства, функцию расстояния)
- 11. евклидово расстояние Манхэттенское расстояние расстояние Чебышева Метрики расстояния между объектами
- 12. Методы кластерного анализа можно разделить на две группы: неиерархические иерархические
- 13. Виды кластеров Внутрикластерные расстояния, как правило, меньше межкластерных Но бывают ленточные кластеры, в которых внутрикластерные расстояния
- 14. Разные виды кластеров ведут к проблеме выбора оптимального алгоритма кластеризации
- 15. Алгоритмы кластеризации
- 16. Как сделать признаки равноправными в образовании кластеров? ИТОГ: мы получим значения признаков, 95% которых находится в
- 17. Метод k-средних Неиерархическим методом кластеризации является метод k-средних (k-means) Предварительно необходимо выбрать вероятное число кластеров k
- 18. Метод k-средних 1. Выбирается k произвольных исходных центров кластеров – обычно выбираются k объектов 2. Все
- 19. Метод k-средних Пример. Примем k = 3 Начальные центры – объекты 1, 3, 4 Разобьем все
- 20. Метод k-средних Найдем новые центры кластеров
- 21. Метод k-средних Найдем новые центры кластеров
- 22. Метод k-средних Разобьем все объекты по новым кластерам, относя каждый объект к кластеру с ближайшим центром
- 23. Метод k-средних Пересчитаем центры кластеров. Дальнейшая разбивка объектов по новым кластерам не меняет расположение центров
- 24. Метод k-средних: определение k с помощью метода каменистой осыпи J (Ck) - сумма квадратов расстояний от
- 25. До стандартизации После График средних значений Признаков в кластерах
- 26. Иерархические методы К иерархическим методам кластеризации относятся: агломеративный алгоритмы дивизимный алгоритмы
- 27. Агломеративный метод В начале работы алгоритма все объекты являются отдельными кластерами На первом шаге наиболее похожие
- 28. Метод ближайшего соседа (одиночная связь, Single linkage). Расстояние между двумя кластерами определяется расстоянием между двумя наиболее
- 29. 4. Невзвешенный центроидный метод (Unweighted pair-group centroid). В этом методе расстояние между двумя кластерами определяется как
- 30. Агломеративный метод Пример. Каждый объект формирует свой кластер
- 31. Агломеративный метод Выбираем и объединяем два наиболее близких кластера
- 32. Агломеративный метод Выбираем и объединяем два наиболее близких кластера
- 33. Агломеративный метод Выбираем и объединяем два наиболее близких кластера
- 34. Дивизимный метод На первом шаге все объекты помещаются в один кластер С1 Выбирается объект, у которого
- 35. Дивизимный метод Выбранный объект удаляется из кластера С1 и формирует первый элемент второго кластера С2 На
- 36. Дивизимный метод В результате один кластер делится на два дочерних, один из которых расщепляется на следующем
- 37. Иерархические методы
- 38. ДЕНДРОГРАММА
- 39. Метрики качества кластеризации Коэффициент силуэта: Здесь a — среднее внутрикластерное расстояние (то есть среднее расстояние между
- 40. Пример программы на Python from sklearn import datasets dataset = datasets.load_iris() X = dataset.data y =
- 41. DBSCAN На вход алгоритму подаётся набор точек, параметры ϵ (радиус окрестности) и m (минимальное число точек
- 42. DBSCAN
- 43. DBSCAN: результаты работы
- 45. Скачать презентацию
Слайд 2Задачи интеллектуального анализа данных
Задачи ИАД
Описательные
Ассоциативные правила
Кластеризация
Классификация
Прогнозирование
Предсказательные
Задачи интеллектуального анализа данных
Задачи ИАД
Описательные
Ассоциативные правила
Кластеризация
Классификация
Прогнозирование
Предсказательные
Слайд 3Введение
Задача кластеризации состоит
в разделении исследуемого множества объектов на группы «похожих» объектов, называемых
Введение
Задача кластеризации состоит в разделении исследуемого множества объектов на группы «похожих» объектов, называемых

Слайд 4Кластеризация отличается
от классификации тем, что этап обучения на примерах отсутствует
В задачах классификации
Кластеризация отличается
от классификации тем, что этап обучения на примерах отсутствует
В задачах классификации

Слайд 5Задача кластеризации часто решается на начальных этапах исследования, когда о данных мало
Задача кластеризации часто решается на начальных этапах исследования, когда о данных мало

Слайд 6ПРИМЕР –кластеризация результатов поиска


Слайд 8Формальная постановка задачи
Дано множество данных, состоящее из N объектов (векторов):
S1, S2, …,
Формальная постановка задачи
Дано множество данных, состоящее из N объектов (векторов):
S1, S2, …,

Слайд 9Формальная постановка задачи
Таким образом, i-й объект можно записать в виде:
Si = (xi1,
Формальная постановка задачи
Таким образом, i-й объект можно записать в виде:
Si = (xi1,

Слайд 10Формальная постановка задачи
Требуется:
найти способ сравнения d(Sp, Sq)
объектов между собой (меру сходства, функцию
Формальная постановка задачи
Требуется:
найти способ сравнения d(Sp, Sq)
объектов между собой (меру сходства, функцию

Слайд 11евклидово расстояние
Манхэттенское расстояние
расстояние Чебышева
Метрики расстояния между объектами
евклидово расстояние
Манхэттенское расстояние
расстояние Чебышева
Метрики расстояния между объектами

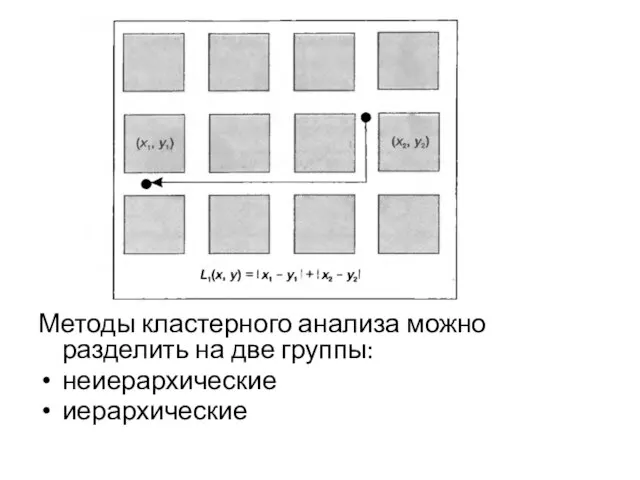
Слайд 12Методы кластерного анализа можно разделить на две группы:
неиерархические
иерархические
Методы кластерного анализа можно разделить на две группы:
неиерархические
иерархические
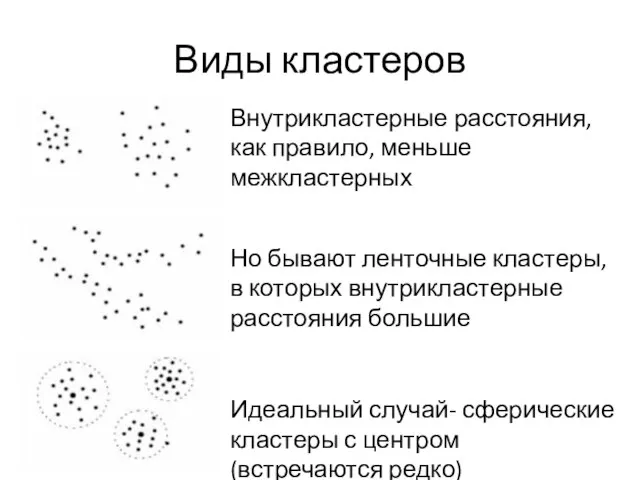
Слайд 13Виды кластеров
Внутрикластерные расстояния, как правило, меньше межкластерных
Но бывают ленточные кластеры, в которых
Виды кластеров
Внутрикластерные расстояния, как правило, меньше межкластерных
Но бывают ленточные кластеры, в которых
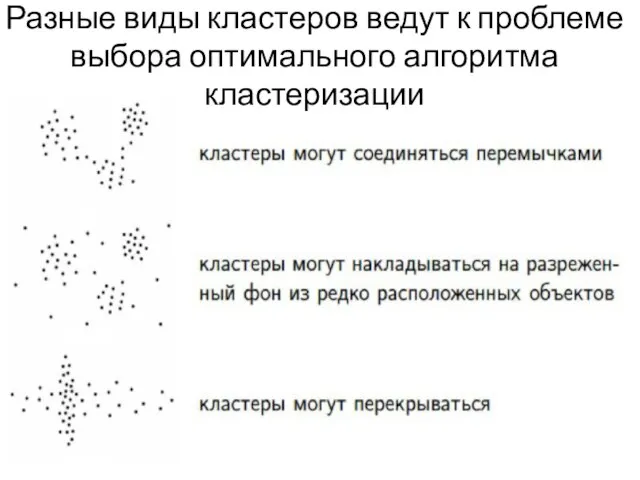
Слайд 14Разные виды кластеров ведут к проблеме выбора оптимального алгоритма кластеризации
Разные виды кластеров ведут к проблеме выбора оптимального алгоритма кластеризации
Слайд 15Алгоритмы кластеризации
Алгоритмы кластеризации

Слайд 16
Как сделать признаки
равноправными в образовании кластеров?
ИТОГ: мы получим значения признаков,
Как сделать признаки
равноправными в образовании кластеров?
ИТОГ: мы получим значения признаков,
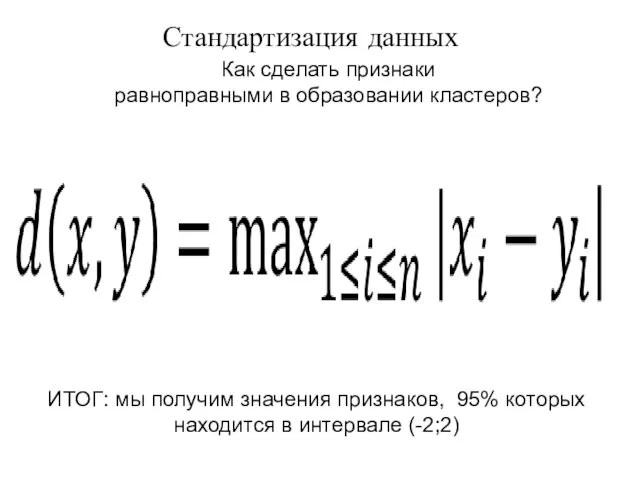
Слайд 17Метод k-средних
Неиерархическим методом кластеризации является метод k-средних (k-means)
Предварительно необходимо выбрать вероятное число
Метод k-средних
Неиерархическим методом кластеризации является метод k-средних (k-means)
Предварительно необходимо выбрать вероятное число

Слайд 18Метод k-средних
1. Выбирается k произвольных исходных центров кластеров – обычно выбираются k
Метод k-средних
1. Выбирается k произвольных исходных центров кластеров – обычно выбираются k

Слайд 19Метод k-средних
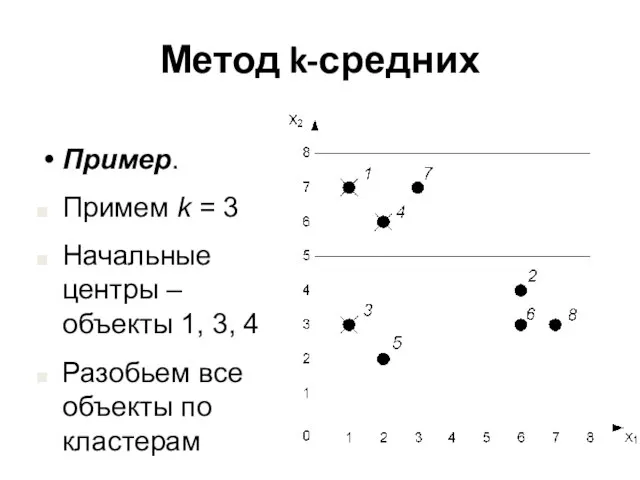
Пример.
Примем k = 3
Начальные центры – объекты 1, 3, 4
Разобьем
Метод k-средних
Пример.
Примем k = 3
Начальные центры – объекты 1, 3, 4
Разобьем
Слайд 20Метод k-средних
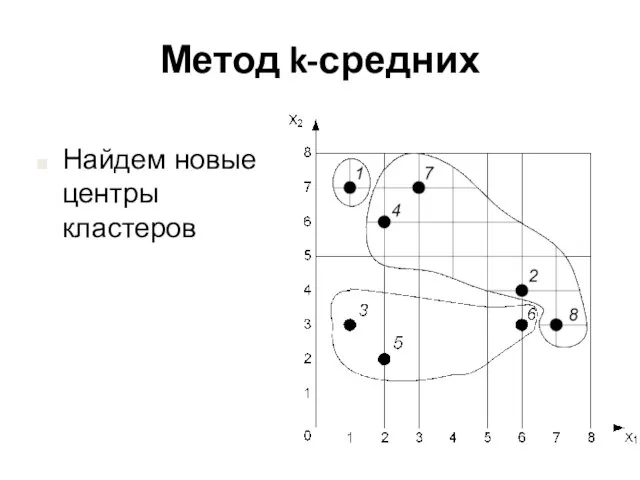
Найдем новые центры кластеров
Метод k-средних
Найдем новые центры кластеров
Слайд 21Метод k-средних
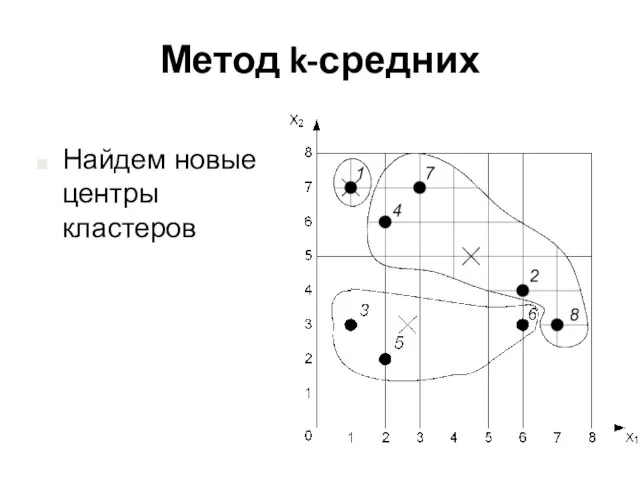
Найдем новые центры кластеров
Метод k-средних
Найдем новые центры кластеров
Слайд 22Метод k-средних
Разобьем все объекты по новым кластерам, относя каждый объект к кластеру
Метод k-средних
Разобьем все объекты по новым кластерам, относя каждый объект к кластеру
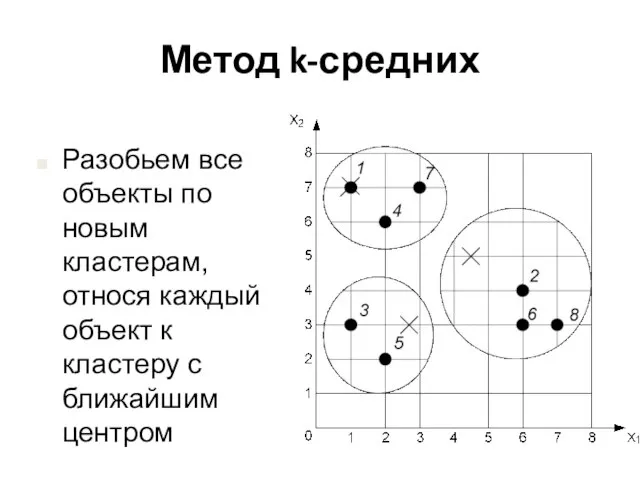
Слайд 23Метод k-средних
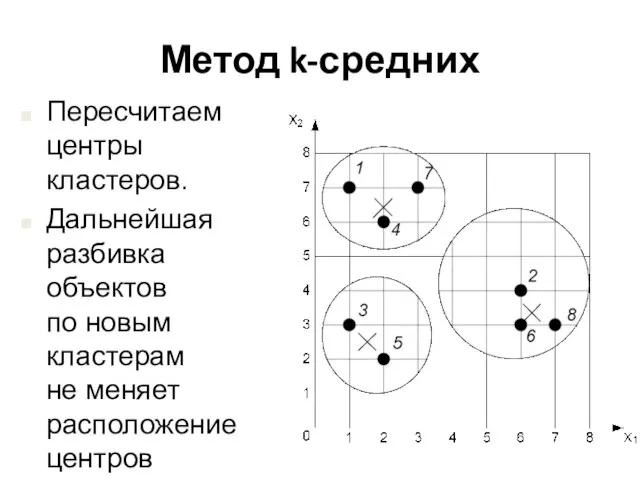
Пересчитаем центры кластеров.
Дальнейшая разбивка объектов
по новым кластерам
не меняет расположение центров
Метод k-средних
Пересчитаем центры кластеров.
Дальнейшая разбивка объектов
по новым кластерам
не меняет расположение центров
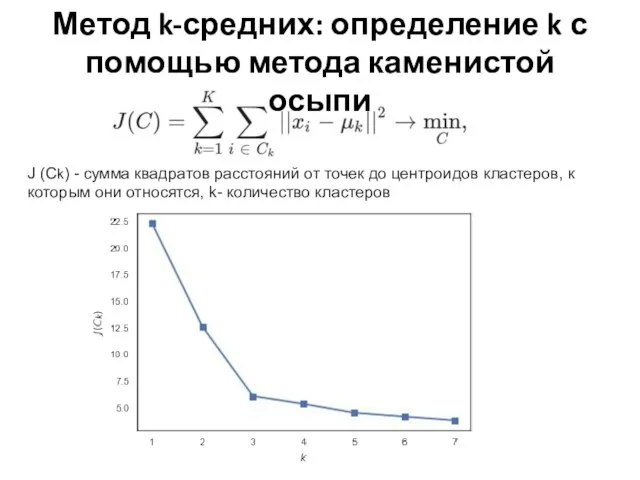
Слайд 24Метод k-средних: определение k с помощью метода каменистой осыпи
J (Ck) - сумма
Метод k-средних: определение k с помощью метода каменистой осыпи
J (Ck) - сумма
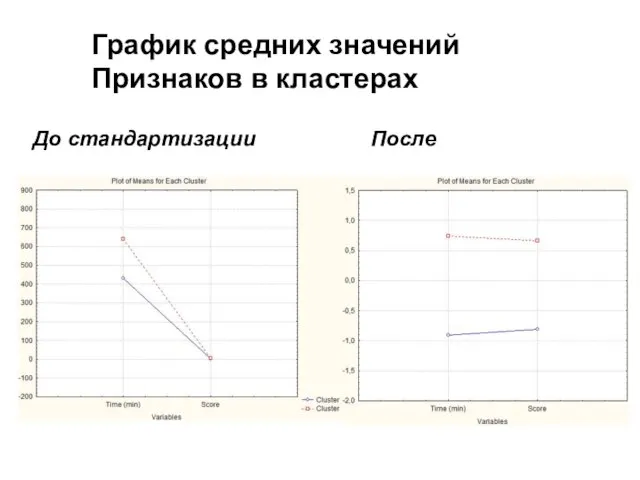
Слайд 25До стандартизации
После
График средних значений
Признаков в кластерах
До стандартизации
После
График средних значений
Признаков в кластерах
Слайд 26Иерархические методы
К иерархическим методам кластеризации относятся:
агломеративный алгоритмы
дивизимный алгоритмы
Иерархические методы
К иерархическим методам кластеризации относятся:
агломеративный алгоритмы
дивизимный алгоритмы

Слайд 27Агломеративный метод
В начале работы алгоритма все объекты являются отдельными кластерами
На первом шаге
Агломеративный метод
В начале работы алгоритма все объекты являются отдельными кластерами
На первом шаге

Слайд 28Метод ближайшего соседа (одиночная связь, Single linkage). Расстояние между двумя кластерами определяется
Метод ближайшего соседа (одиночная связь, Single linkage). Расстояние между двумя кластерами определяется

Слайд 294. Невзвешенный центроидный метод (Unweighted pair-group centroid). В этом методе расстояние между двумя
4. Невзвешенный центроидный метод (Unweighted pair-group centroid). В этом методе расстояние между двумя

Слайд 30Агломеративный метод
Пример.
Каждый объект формирует свой кластер
Агломеративный метод
Пример.
Каждый объект формирует свой кластер
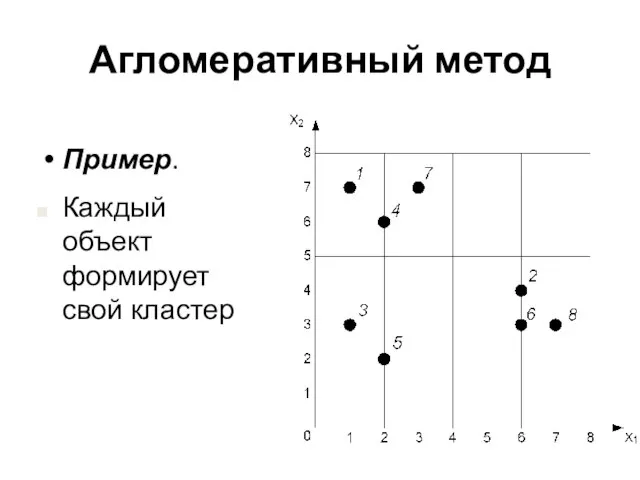
Слайд 31Агломеративный метод
Выбираем и объединяем
два наиболее близких кластера
Агломеративный метод
Выбираем и объединяем
два наиболее близких кластера
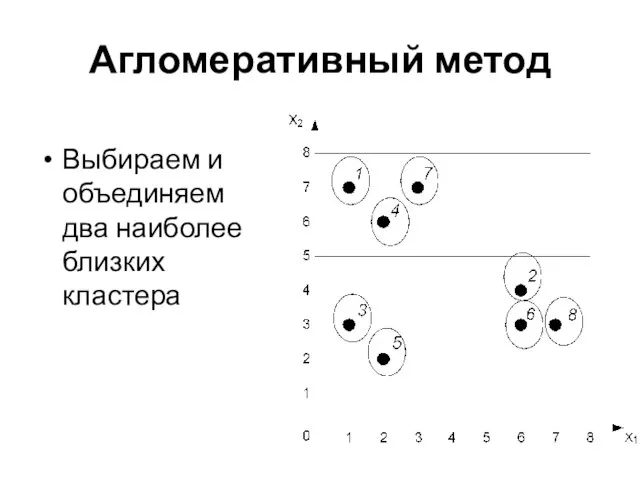
Слайд 32Агломеративный метод
Выбираем и объединяем
два наиболее близких кластера
Агломеративный метод
Выбираем и объединяем
два наиболее близких кластера
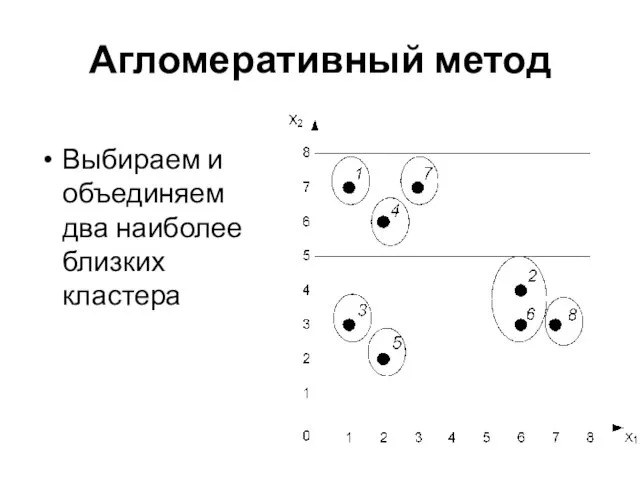
Слайд 33Агломеративный метод
Выбираем и объединяем
два наиболее близких кластера
Агломеративный метод
Выбираем и объединяем
два наиболее близких кластера
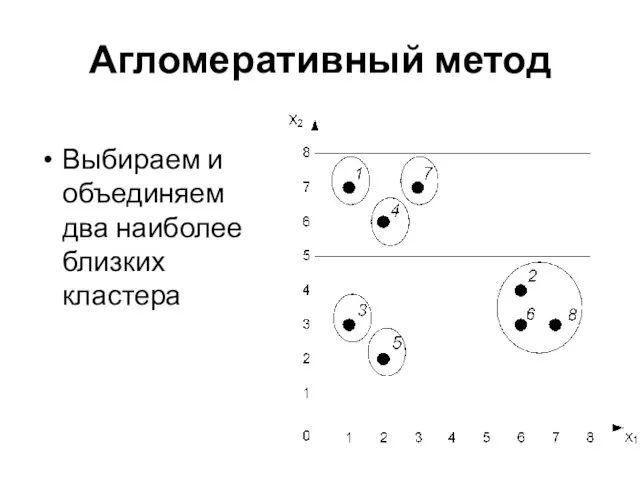
Слайд 34Дивизимный метод
На первом шаге все объекты помещаются в один кластер С1
Выбирается объект,
Дивизимный метод
На первом шаге все объекты помещаются в один кластер С1
Выбирается объект,

Слайд 35Дивизимный метод
Выбранный объект удаляется из кластера С1 и формирует первый элемент второго
Дивизимный метод
Выбранный объект удаляется из кластера С1 и формирует первый элемент второго

Слайд 36Дивизимный метод
В результате один кластер делится на два дочерних, один из которых
Дивизимный метод
В результате один кластер делится на два дочерних, один из которых

Слайд 37Иерархические методы
Иерархические методы
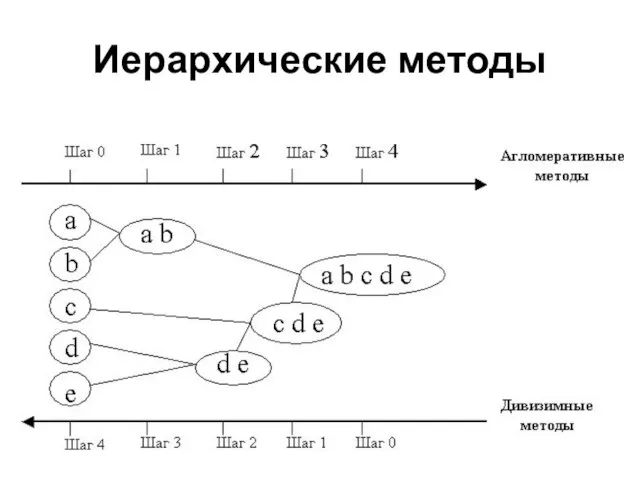
Слайд 38ДЕНДРОГРАММА
ДЕНДРОГРАММА
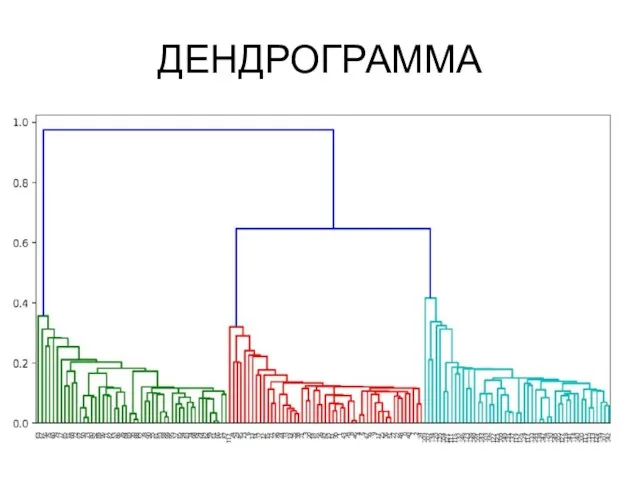
Слайд 39Метрики качества кластеризации
Коэффициент силуэта:
Здесь a — среднее внутрикластерное расстояние (то есть
Метрики качества кластеризации
Коэффициент силуэта:
Здесь a — среднее внутрикластерное расстояние (то есть

Слайд 40Пример программы на Python
from sklearn import datasets
dataset = datasets.load_iris()
X =
Пример программы на Python
from sklearn import datasets
dataset = datasets.load_iris()
X =

Слайд 41DBSCAN
На вход алгоритму подаётся набор точек, параметры ϵ (радиус окрестности)
и m (минимальное число точек в
DBSCAN
На вход алгоритму подаётся набор точек, параметры ϵ (радиус окрестности)
и m (минимальное число точек в
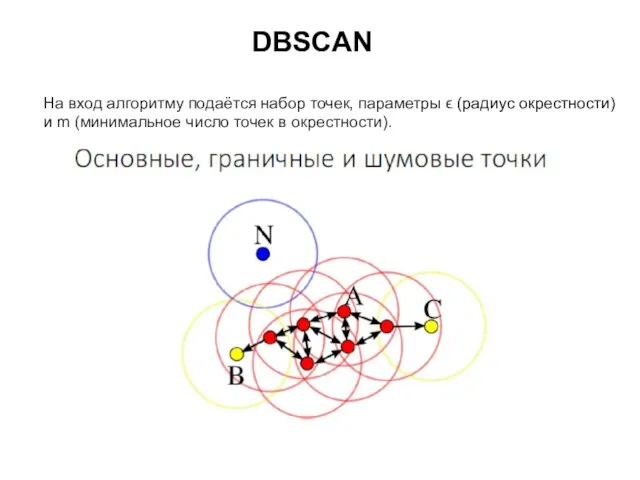
Слайд 42DBSCAN
DBSCAN
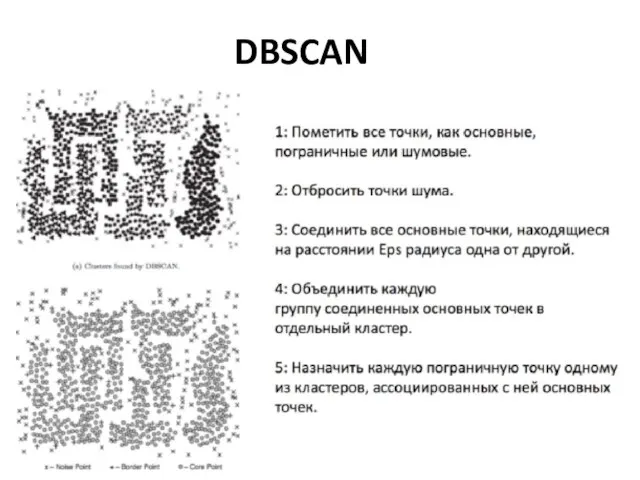
Слайд 43DBSCAN: результаты работы
DBSCAN: результаты работы

 Презентация на тему Лобачевский и его геометрия 10 класс
Презентация на тему Лобачевский и его геометрия 10 класс  Презентация на тему Математический калейдоскоп
Презентация на тему Математический калейдоскоп  Пояснения к определению предела последовательности
Пояснения к определению предела последовательности Модели скоростей при движении по реке. 5 класс
Модели скоростей при движении по реке. 5 класс Оценка сложных систем в условиях неопределенности
Оценка сложных систем в условиях неопределенности Знак деления
Знак деления Устный счёт. Вверху, внизу,слева, справа (1 класс)
Устный счёт. Вверху, внизу,слева, справа (1 класс) Устный счёт. Вычисли наиболее лёгким способом
Устный счёт. Вычисли наиболее лёгким способом Презентация на тему Квадратичная функция
Презентация на тему Квадратичная функция  Многочлен. Основные понятия
Многочлен. Основные понятия Основы логики
Основы логики Основы тригонометрии. Радианная мера угла. Соответствие радианной и градусной мер углов
Основы тригонометрии. Радианная мера угла. Соответствие радианной и градусной мер углов Математические головоломки. Математика вокруг нас
Математические головоломки. Математика вокруг нас Теорема, обратная теореме Пифагора
Теорема, обратная теореме Пифагора Понятие производной
Понятие производной Метрология, основные понятия
Метрология, основные понятия Тригонометрические функции
Тригонометрические функции Проект Математическая вертикаль. Геометрия. 8 класс
Проект Математическая вертикаль. Геометрия. 8 класс Определение корня
Определение корня Сечение поверхности плоскостью
Сечение поверхности плоскостью Решение задач на проценты
Решение задач на проценты Метод научного познания: измерение. Процедура измерения
Метод научного познания: измерение. Процедура измерения Sie hat Geburtstag am fünften August. Er kommt am einunddreißigsten Juli
Sie hat Geburtstag am fünften August. Er kommt am einunddreißigsten Juli Решение систем уравнений с помощью обратной матрицы
Решение систем уравнений с помощью обратной матрицы Статистика. Занятие 5
Статистика. Занятие 5 Сумма углов треугольника. Работа с чертежами
Сумма углов треугольника. Работа с чертежами Подобные слагаемые
Подобные слагаемые Ликвидация пробелов в знаниях по теме Соотношения между сторонами и углами треугольника
Ликвидация пробелов в знаниях по теме Соотношения между сторонами и углами треугольника