- Алгоритмы сортировки массивов.

Содержание
- 2. Сортировка является одной из фундаментальных алгоритмических задач программирования. Решению проблем, связанных с сортировкой, посвящено множество научных
- 3. Практически каждый алгоритм сортировки можно разбить на 3 части: сравнение, определяющее упорядоченность пары элементов; перестановку, меняющую
- 4. Оценка алгоритмов сортировки Ни одна другая проблема не породила такого количества разнообразнейших решений, как задача сортировки.
- 5. Классификация алгоритмов сортировок Все разнообразие и многообразие алгоритмов сортировок можно классифицировать по различным признакам, например, по
- 6. Внутренняя сортировка – это алгоритм сортировки, который в процессе упорядочивания данных использует только оперативную память (ОЗУ)
- 7. Внешняя сортировка – это алгоритм сортировки, который при проведении упорядочивания данных использует внешнюю память, например, жесткие
- 8. Внутренняя сортировка является базовой для любого алгоритма внешней сортировки – отдельные части массива данных сортируются в
- 9. Основные алгоритмы внутренних сортировок
- 10. Сортировка выбором. Sortimine valiku abil. Tom Debby Mike Ron Ron Tom Debby Mike Ron Ron Tom
- 11. 50 20 40 75 35 A[0] A[1] A[2] A[3] A[4] Valime 20 ja vahetame A[0]-ga 20
- 12. void SelectionSort ( A[ ], int n) { int v_Index; //kõige väiksema elemendi index int i,
- 13. Сортировка методом пузырька. Mulli meetodi sortimine. 50 20 40 75 35 A[0] A[1] A[2] A[3] A[4]
- 14. 20 40 50 35 75 20 ja 40 oma kohtadel 20 40 50 35 75 40
- 15. Läbimine 2 Проход 2 20 40 35 50 75 20 ja 40 oma kohtadel 20 35
- 16. void BubbleSort ( A[ ], int n) { int i, j; //viimase vahetamise elemendi index int
- 17. 50 20 40 75 35 A[0] A[1] A[2] A[3] A[4] Сортировка вставкой. 50 Alustame 50-st Andmetöötlus:
- 18. void InsertionSort ( A[ ], int n) { int i, j; T temp; for (i=1; i
- 19. "Поразрядная сортировка" Поразрядная сортировка была изобретена в 1920-х годах как побочный результат использования сортирующих машин. Такая
- 20. Значения в разрядах номеров заданы цифрами, поэтому поразрядную сортировку еще называют цифровой. Заметим, что цифры от
- 21. Далее сложим получившиеся стопки в одну в порядке возрастания последней цифры. 231 721 733 323 123
- 22. #include "stdafx.h" #include using namespace std; const int D = 3; const int B = 10;
- 23. for ( k = 0 ; k PQNext[k] = k + 1; for ( int r
- 24. // описание функции поразрядной сортировки void SortD(int k){ for ( tempL = 0 ; tempL PFirst[tempL]
- 25. while ( tempL newL = tempL + 1; while ( newL newL++; if ( newL PQNext[PLast[tempL]]
- 26. /*описание функции вывода элементов из массива Data, индекс которого задан ее аргументом*/ void outDigs(int i){ int
- 27. Данный метод сортировки был предложен Дж.Уильямсом и Р.У. Флойдом в 1964 году. Пирамидальная сортировка в некотором
- 28. Просеивание – это построение новой пирамиды по следующему алгоритму: новый элемент помещается в вершину дерева, далее
- 29. Алгоритм пирамидальной сортировки. Шаг 1. Преобразовать массив в пирамиду (перебираем в цикле элементы массива справа налево
- 30. Алгоритм преобразования массива в пирамиду (построение пирамиды). Пусть дан массив x[1],x[2],...,x[n]. Шаг 1. Устанавливаем k=n/2. Шаг
- 31. Алгоритм сортировки пирамиды. Рассмотрим массив размерности n, который представляет пирамиду x[1],x[2],...,x[n](см.рис.А). Шаг 1. Переставляем элементы x[1]
- 32. Шаг 3. Рассматриваем массив x[1],x[2],...,x[n-1], который получается из исходного за счет исключения последнего элемента. Данный массив
- 33. Построение пирамиды, ее сортировка и "просеивание" элементов реализуются с помощью рекурсии. Базой рекурсии при этом выступает
- 34. //Построение пирамиды void Build_Pyramid (int k, int r, int *x){ Sifting(k,r,x); if (k > 0) Build_Pyramid(k-1,r,x);
- 35. for(j=0;j cout cout Binary_Pyramidal_Sort (n,x); cout for(j=0;j {if ( (j+1) % 10 ==0) cout cout }
- 36. Теоретическое время работы этого алгоритма можно оценить, учитывая, что пирамидальная сортировка аналогична построению пирамиды методом просеивания
- 37. Сортировка методом Шелла Сортировка Шелла была названа в честь ее изобретателя – Дональда Шелла, который опубликовал
- 38. Общая схема метода: Шаг 1. Происходит упорядочивание элементов n/2 пар (xi,xn/2+i) для 1 Шаг 2. Упорядочиваются
- 39. #include #include #include #define k 10 using namespace std; //процедура обмена двух элементов void Exchange (int
- 40. Быстрая сортировка Хоара Метод быстрой сортировки был впервые описан Ч.А.Р. Хоаром в 1962 году. Быстрая сортировка
- 41. Алгоритм быстрой сортировки Хоара Пусть дан массив x[n] размерности n. Шаг 1. Выбирается опорный элемент массива.
- 42. //Описание функции сортировки Хоара void Hoar_Sort (int k, int *x){ Quick_Sort (0, k-1, x); } void
- 43. Эффективность быстрой сортировки в значительной степени определяется правильностью выбора опорных (ведущих) элементов при формировании блоков. В
- 44. Сортировка слиянием Алгоритм сортировки слиянием был изобретен Джоном фон Нейманом в 1945 году. Он является одним
- 45. Данный алгоритм применяется тогда, когда есть возможность использовать для хранения промежуточных результатов память, сравнимую с размером
- 46. Алгоритм сортировки слиянием Шаг 1. Разбить имеющиеся элементы массива на пары и осуществить слияние элементов каждой
- 47. //Описание функции сортировки слиянием void Merging_Sort (int n, int *x){ int i, j, k, t, s,
- 48. Недостаток алгоритма заключается в том, что он требует дополнительную память размером порядка n (для хранения вспомогательного
- 49. Теоретические временные и пространственные сложности рассмотренных методов сортировки
- 50. Таблица позволяет сделать ряд выводов. 1. На небольших наборах данных целесообразнее использовать сортировку включением, т.к. из
- 51. 5. Если же добавляется требование гарантировать приемлемое время работы метода (быстрая сортировка в худшем случае имеет
- 52. Задание Дан целочисленный массив. Выполнить проверку уникальности элементов. Удалить из массива повторные вхождения чисел, предварительно отсортировав
- 53. Внешняя сортировка – это сортировка данных, которые расположены на внешних устройствах и не вмещаются в оперативную
- 54. Внешние сортировки применяются к данным, которые хранятся во внешней памяти. При выполнении таких сортировок требуется работать
- 55. Данные, хранящиеся на внешних устройствах, имеют большой объем, что не позволяет их целиком переместить в оперативную
- 56. Серия (упорядоченный отрезок) – это последовательность элементов, которая упорядочена (отсортирована) по ключу. Длина серии - количество
- 57. Фаза – это действия по однократной обработке всей последовательности элементов. Двухфазная сортировка – это сортировка, в
- 58. Общий алгоритм сортировки слиянием Сначала серии распределяются на два или более вспомогательных файлов. Данное распределение идет
- 59. Сортировка простым слиянием Алгоритм сортировки простым слияния является простейшим алгоритмом внешней сортировки, основанный на процедуре слияния
- 60. После выполнения i проходов получаем два файла, состоящих из серий длины 2i. Окончание процесса происходит при
- 61. //Описание функции сортировки простым слиянием void Simple_Merging_Sort (char *name) { int a1, a2, k, i, j,
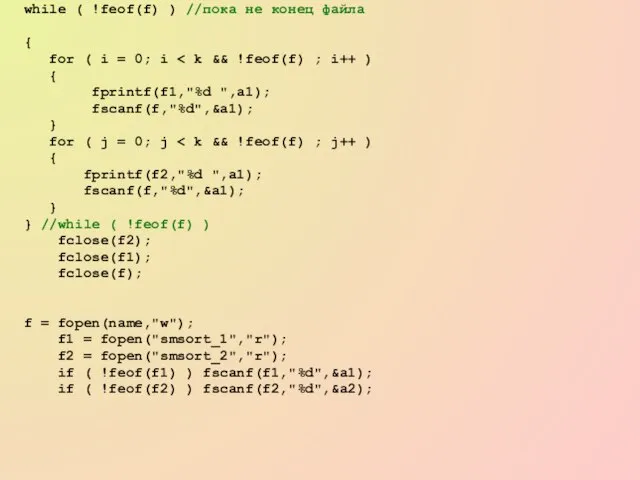
- 62. while ( !feof(f) ) //пока не конец файла { for ( i = 0; i {
- 63. while( !feof(f1) && !feof(f2) ) { i = 0; j = 0; while(i { if (
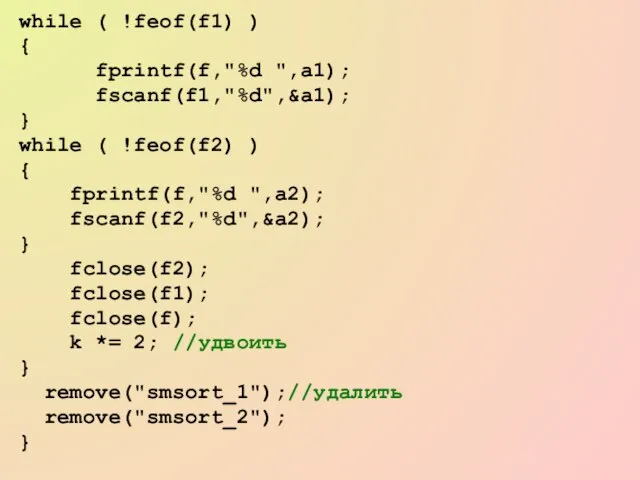
- 64. while ( !feof(f1) ) { fprintf(f,"%d ",a1); fscanf(f1,"%d",&a1); } while ( !feof(f2) ) { fprintf(f,"%d ",a2);
- 65. Сортировка естественным слиянием В случае простого слияния частичная упорядоченность сортируемых данных не дает никакого преимущества. Это
- 66. Алгоритм сортировки естественным слиянием Шаг 1. Исходный файл f разбивается на два вспомогательных файла f1 и
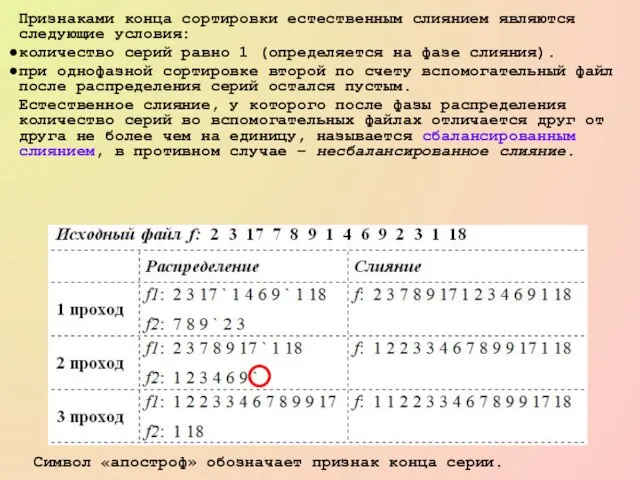
- 67. Признаками конца сортировки естественным слиянием являются следующие условия: количество серий равно 1 (определяется на фазе слияния).
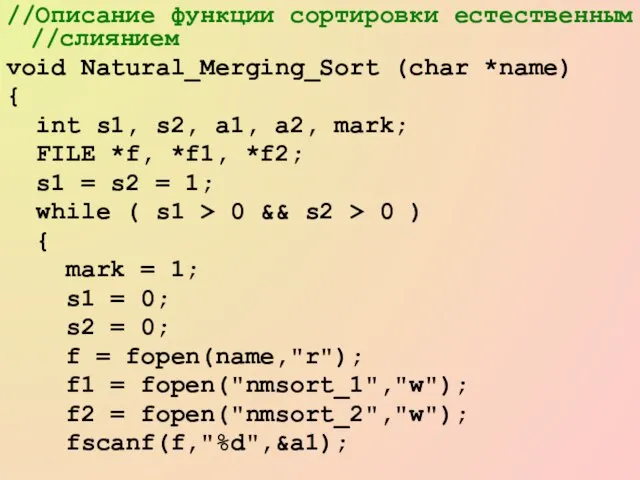
- 68. //Описание функции сортировки естественным //слиянием void Natural_Merging_Sort (char *name) { int s1, s2, a1, a2, mark;
- 69. if ( !feof(f) ) { fprintf(f1,"%d ",a1); } if ( !feof(f) ) fscanf(f,"%d",&a2); while ( !feof(f)
- 70. if ( s2 > 0 && mark == 2 ) { fprintf(f2,"'");} if ( s1 >
- 71. bool file1, file2; while ( !feof(f1) && !feof(f2) ) { file1 = file2 = false; while
- 72. while ( !file1 ) { fprintf(f,"%d ",a1); file1 = End_Range(f1); fscanf(f1,"%d",&a1); } while ( !file2 )
- 73. while ( !file2 && !feof(f2) ) { fprintf(f,"%d ",a2); file2 = End_Range(f2); fscanf(f2,"%d",&a2); } fclose(f2); fclose(f1);
- 74. Выводы. Число чтений или перезаписей файлов при использовании метода естественного слияния будет не хуже, чем при
- 75. Краткие итоги Внешние сортировки применяются к данным, которые хранятся во внешней памяти. Внешние сортировки применяются, если
- 76. Алгоритмы внешних сортировок отличаются по реализации числом фаз и путей. Простое слияние является одной из сортировок
- 78. Скачать презентацию
Слайд 2Сортировка является одной из фундаментальных алгоритмических задач программирования. Решению проблем, связанных с
Сортировка является одной из фундаментальных алгоритмических задач программирования. Решению проблем, связанных с

Слайд 3Практически каждый алгоритм сортировки можно разбить на 3 части:
сравнение, определяющее упорядоченность пары
Практически каждый алгоритм сортировки можно разбить на 3 части:
сравнение, определяющее упорядоченность пары

Слайд 4Оценка алгоритмов сортировки
Ни одна другая проблема не породила такого количества разнообразнейших решений,
Оценка алгоритмов сортировки
Ни одна другая проблема не породила такого количества разнообразнейших решений,

Слайд 5Классификация алгоритмов сортировок
Все разнообразие и многообразие алгоритмов сортировок можно классифицировать по различным
Классификация алгоритмов сортировок
Все разнообразие и многообразие алгоритмов сортировок можно классифицировать по различным

Слайд 6Внутренняя сортировка – это алгоритм сортировки, который в процессе упорядочивания данных использует
Внутренняя сортировка – это алгоритм сортировки, который в процессе упорядочивания данных использует

Слайд 7Внешняя сортировка – это алгоритм сортировки, который при проведении упорядочивания данных использует
Внешняя сортировка – это алгоритм сортировки, который при проведении упорядочивания данных использует

Слайд 8Внутренняя сортировка является базовой для любого алгоритма внешней сортировки – отдельные части
Внутренняя сортировка является базовой для любого алгоритма внешней сортировки – отдельные части

Слайд 9Основные алгоритмы внутренних сортировок
Основные алгоритмы внутренних сортировок

Слайд 10Сортировка выбором.
Sortimine valiku abil.
Tom
Debby
Mike
Ron
Ron
Tom
Debby
Mike
Ron
Ron
Tom
Tom
Debby
Mike
Ron
Ron
Tom
Mike
Сортировка выбором.
Sortimine valiku abil.
Tom
Debby
Mike
Ron
Ron
Tom
Debby
Mike
Ron
Ron
Tom
Tom
Debby
Mike
Ron
Ron
Tom
Mike

Слайд 1150
20
40
75
35
A[0] A[1] A[2] A[3] A[4]
Valime 20 ja vahetame A[0]-ga
20
50
40
75
35
Valime 35 ja vahetame
50
20
40
75
35
A[0] A[1] A[2] A[3] A[4]
Valime 20 ja vahetame A[0]-ga
20
50
40
75
35
Valime 35 ja vahetame
![50 20 40 75 35 A[0] A[1] A[2] A[3] A[4] Valime 20](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-10.jpg)
Слайд 12void SelectionSort ( A[ ], int n)
{ int v_Index; //kõige väiksema elemendi index
void SelectionSort (
{ int v_Index; //kõige väiksema elemendi index
![void SelectionSort ( A[ ], int n) { int v_Index; //kõige väiksema](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-11.jpg)
Слайд 13 Сортировка методом пузырька.
Mulli meetodi sortimine.
50
20
40
75
35
A[0] A[1] A[2] A[3] A[4]
Vahetame
Сортировка методом пузырька.
Mulli meetodi sortimine.
50
20
40
75
35
A[0] A[1] A[2] A[3] A[4]
Vahetame
![Сортировка методом пузырька. Mulli meetodi sortimine. 50 20 40 75 35 A[0]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-12.jpg)
Слайд 1420
40
50
35
75
20 ja 40 oma kohtadel
20
40
50
35
75
40 ja 50 oma kohtadel
20
40
50
35
75
Vahetame 50 ja 35
20
40
35
50
75
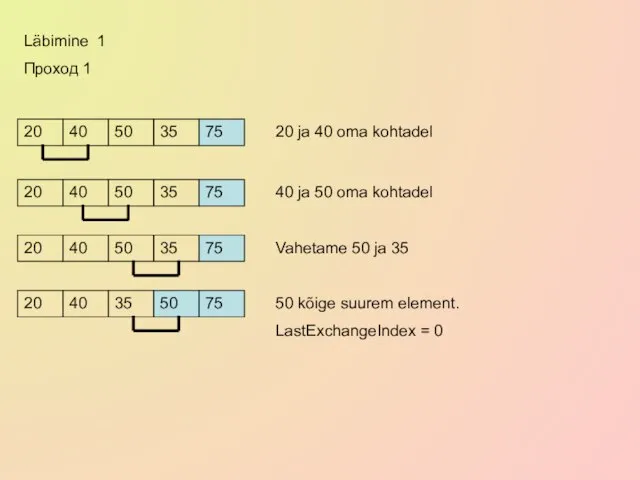
50
20
40
50
35
75
20 ja 40 oma kohtadel
20
40
50
35
75
40 ja 50 oma kohtadel
20
40
50
35
75
Vahetame 50 ja 35
20
40
35
50
75
50
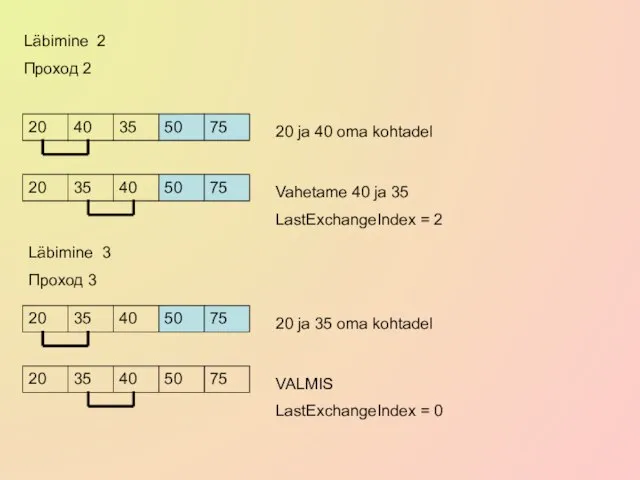
Слайд 15Läbimine 2
Проход 2
20
40
35
50
75
20 ja 40 oma kohtadel
20
35
40
50
75
Vahetame 40 ja 35
LastExchangeIndex = 2
Läbimine
Läbimine 2
Проход 2
20
40
35
50
75
20 ja 40 oma kohtadel
20
35
40
50
75
Vahetame 40 ja 35
LastExchangeIndex = 2
Läbimine
Слайд 16void BubbleSort ( A[ ], int n)
{
int i, j;
//viimase vahetamise elemendi index
void BubbleSort (
{
int i, j;
//viimase vahetamise elemendi index
![void BubbleSort ( A[ ], int n) { int i, j; //viimase](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-15.jpg)
Слайд 1750
20
40
75
35
A[0] A[1] A[2] A[3] A[4]
Сортировка вставкой.
50
Alustame 50-st
Andmetöötlus: 20
50
A[0]=20 ja A[1]=50
20
Andmetöötlus: 40
40
A[1]=40
50
20
40
75
35
A[0] A[1] A[2] A[3] A[4]
Сортировка вставкой.
50
Alustame 50-st
Andmetöötlus: 20
50
A[0]=20 ja A[1]=50
20
Andmetöötlus: 40
40
A[1]=40
![50 20 40 75 35 A[0] A[1] A[2] A[3] A[4] Сортировка вставкой.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-16.jpg)
Слайд 18void InsertionSort ( A[ ], int n)
{
int i, j;
T temp;
for
void InsertionSort (
{
int i, j;
T temp;
for
![void InsertionSort ( A[ ], int n) { int i, j; T](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-17.jpg)
Слайд 19"Поразрядная сортировка"
Поразрядная сортировка была изобретена в 1920-х годах как побочный результат использования
"Поразрядная сортировка"
Поразрядная сортировка была изобретена в 1920-х годах как побочный результат использования

Слайд 20Значения в разрядах номеров заданы цифрами, поэтому поразрядную сортировку еще называют цифровой.
Значения в разрядах номеров заданы цифрами, поэтому поразрядную сортировку еще называют цифровой.

Слайд 21Далее сложим получившиеся стопки в одну в порядке возрастания последней цифры.
231 721
Далее сложим получившиеся стопки в одну в порядке возрастания последней цифры.
231 721

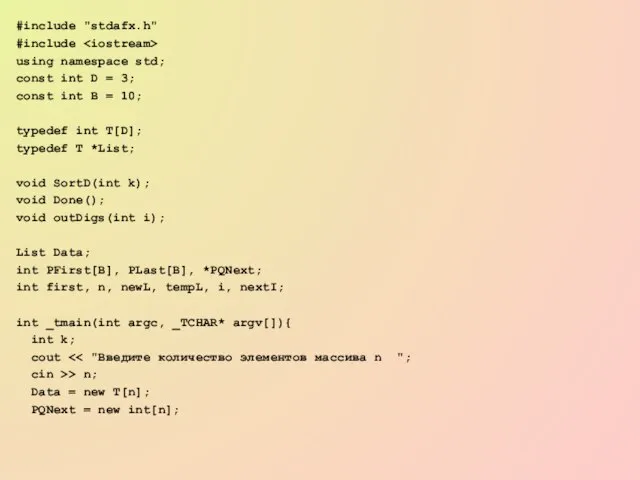
Слайд 22#include "stdafx.h"
#include
using namespace std;
const int D = 3;
const int B =
#include "stdafx.h"
#include
using namespace std;
const int D = 3;
const int B =
Слайд 23for ( k = 0 ; k < n ; k++ ){
for ( k = 0 ; k < n ; k++ ){
![for ( k = 0 ; k PQNext[k] = k + 1;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-22.jpg)
Слайд 24// описание функции поразрядной сортировки
void SortD(int k){
for ( tempL = 0
// описание функции поразрядной сортировки
void SortD(int k){
for ( tempL = 0

Слайд 25while ( tempL < B - 1 ){
newL = tempL +
while ( tempL < B - 1 ){
newL = tempL +

Слайд 26/*описание функции вывода элементов из массива Data, индекс которого задан ее аргументом*/
void
/*описание функции вывода элементов из массива Data, индекс которого задан ее аргументом*/
void

Слайд 27Данный метод сортировки был предложен Дж.Уильямсом и Р.У. Флойдом в 1964 году.
Данный метод сортировки был предложен Дж.Уильямсом и Р.У. Флойдом в 1964 году.

Слайд 28Просеивание – это построение новой пирамиды по следующему алгоритму:
новый элемент помещается
Просеивание – это построение новой пирамиды по следующему алгоритму:
новый элемент помещается

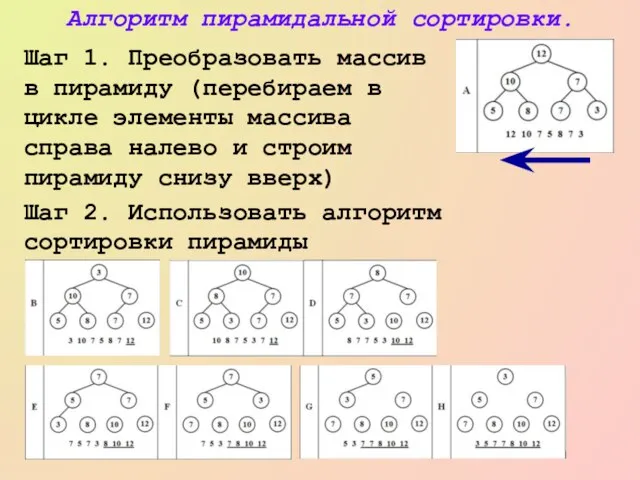
Слайд 29Алгоритм пирамидальной сортировки.
Шаг 1. Преобразовать массив в пирамиду (перебираем в цикле элементы
Алгоритм пирамидальной сортировки.
Шаг 1. Преобразовать массив в пирамиду (перебираем в цикле элементы
Слайд 30Алгоритм преобразования массива в пирамиду (построение пирамиды).
Пусть дан массив x[1],x[2],...,x[n].
Шаг 1. Устанавливаем
Алгоритм преобразования массива в пирамиду (построение пирамиды).
Пусть дан массив x[1],x[2],...,x[n].
Шаг 1. Устанавливаем
![Алгоритм преобразования массива в пирамиду (построение пирамиды). Пусть дан массив x[1],x[2],...,x[n]. Шаг](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-29.jpg)
Слайд 31Алгоритм сортировки пирамиды.
Рассмотрим массив размерности n, который представляет пирамиду x[1],x[2],...,x[n](см.рис.А).
Шаг 1. Переставляем
Алгоритм сортировки пирамиды.
Рассмотрим массив размерности n, который представляет пирамиду x[1],x[2],...,x[n](см.рис.А).
Шаг 1. Переставляем
![Алгоритм сортировки пирамиды. Рассмотрим массив размерности n, который представляет пирамиду x[1],x[2],...,x[n](см.рис.А). Шаг](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-30.jpg)
Слайд 32Шаг 3. Рассматриваем массив x[1],x[2],...,x[n-1], который получается из исходного за счет исключения
Шаг 3. Рассматриваем массив x[1],x[2],...,x[n-1], который получается из исходного за счет исключения
![Шаг 3. Рассматриваем массив x[1],x[2],...,x[n-1], который получается из исходного за счет исключения](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-31.jpg)
Слайд 33Построение пирамиды, ее сортировка и "просеивание" элементов реализуются с помощью рекурсии. Базой
Построение пирамиды, ее сортировка и "просеивание" элементов реализуются с помощью рекурсии. Базой

Слайд 34//Построение пирамиды
void Build_Pyramid (int k, int r, int *x){
Sifting(k,r,x);
if (k
//Построение пирамиды
void Build_Pyramid (int k, int r, int *x){
Sifting(k,r,x);
if (k

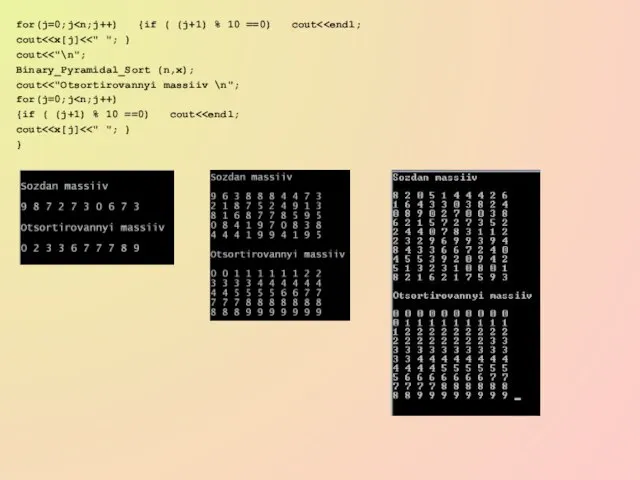
Слайд 35for(j=0;jcout<cout<<"\n";
Binary_Pyramidal_Sort (n,x);
cout<<"Otsortirovannyi massiiv
for(j=0;j
Binary_Pyramidal_Sort (n,x);
cout<<"Otsortirovannyi massiiv
Слайд 36Теоретическое время работы этого алгоритма можно оценить, учитывая, что пирамидальная сортировка аналогична
Теоретическое время работы этого алгоритма можно оценить, учитывая, что пирамидальная сортировка аналогична

Слайд 37Сортировка методом Шелла
Сортировка Шелла была названа в честь ее изобретателя – Дональда
Сортировка методом Шелла
Сортировка Шелла была названа в честь ее изобретателя – Дональда

Слайд 38Общая схема метода:
Шаг 1. Происходит упорядочивание элементов n/2 пар (xi,xn/2+i) для 1Шаг
Общая схема метода:
Шаг 1. Происходит упорядочивание элементов n/2 пар (xi,xn/2+i) для 1

Слайд 39#include
#include
#include
#define k 10
using namespace std;
//процедура обмена двух элементов
void Exchange
#include
#include
#include
#define k 10
using namespace std;
//процедура обмена двух элементов
void Exchange

Слайд 40Быстрая сортировка Хоара
Метод быстрой сортировки был впервые описан Ч.А.Р. Хоаром в 1962
Быстрая сортировка Хоара
Метод быстрой сортировки был впервые описан Ч.А.Р. Хоаром в 1962

Слайд 41Алгоритм быстрой сортировки Хоара
Пусть дан массив x[n] размерности n.
Шаг 1. Выбирается опорный
Алгоритм быстрой сортировки Хоара
Пусть дан массив x[n] размерности n.
Шаг 1. Выбирается опорный
![Алгоритм быстрой сортировки Хоара Пусть дан массив x[n] размерности n. Шаг 1.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409498/slide-40.jpg)
Слайд 42//Описание функции сортировки Хоара
void Hoar_Sort (int k, int *x){
Quick_Sort (0, k-1,
//Описание функции сортировки Хоара
void Hoar_Sort (int k, int *x){
Quick_Sort (0, k-1,

Слайд 43Эффективность быстрой сортировки в значительной степени определяется правильностью выбора опорных (ведущих) элементов
Эффективность быстрой сортировки в значительной степени определяется правильностью выбора опорных (ведущих) элементов

Слайд 44Сортировка слиянием
Алгоритм сортировки слиянием был изобретен Джоном фон Нейманом в 1945 году.
Сортировка слиянием
Алгоритм сортировки слиянием был изобретен Джоном фон Нейманом в 1945 году.

Слайд 45Данный алгоритм применяется тогда, когда есть возможность использовать для хранения промежуточных результатов
Данный алгоритм применяется тогда, когда есть возможность использовать для хранения промежуточных результатов

Слайд 46Алгоритм сортировки слиянием
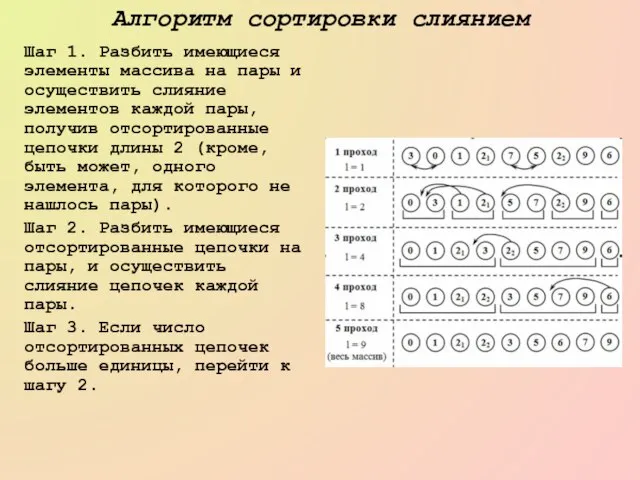
Шаг 1. Разбить имеющиеся элементы массива на пары и осуществить
Алгоритм сортировки слиянием
Шаг 1. Разбить имеющиеся элементы массива на пары и осуществить
Слайд 47//Описание функции сортировки слиянием
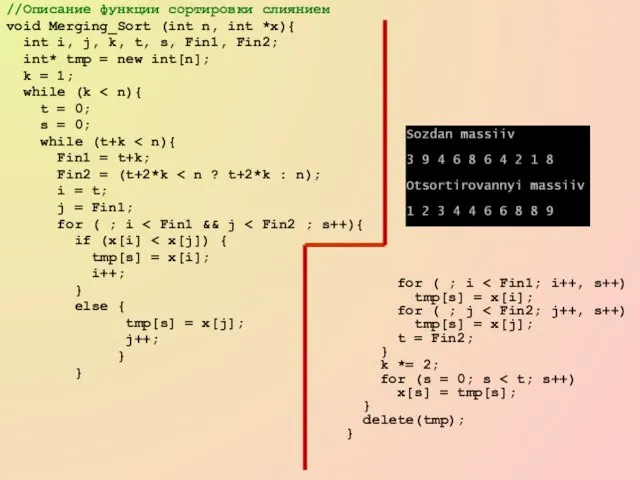
void Merging_Sort (int n, int *x){
int i, j,
//Описание функции сортировки слиянием
void Merging_Sort (int n, int *x){
int i, j,
Слайд 48Недостаток алгоритма заключается в том, что он требует дополнительную память размером порядка
Недостаток алгоритма заключается в том, что он требует дополнительную память размером порядка

Слайд 49Теоретические временные и пространственные сложности рассмотренных методов сортировки
Теоретические временные и пространственные сложности рассмотренных методов сортировки

Слайд 50Таблица позволяет сделать ряд выводов.
1. На небольших наборах данных целесообразнее использовать сортировку
Таблица позволяет сделать ряд выводов.
1. На небольших наборах данных целесообразнее использовать сортировку

Слайд 515. Если же добавляется требование гарантировать приемлемое время работы метода (быстрая сортировка
5. Если же добавляется требование гарантировать приемлемое время работы метода (быстрая сортировка

Слайд 52 Задание
Дан целочисленный массив. Выполнить проверку уникальности элементов. Удалить из массива повторные вхождения
Задание
Дан целочисленный массив. Выполнить проверку уникальности элементов. Удалить из массива повторные вхождения

Слайд 53Внешняя сортировка – это сортировка данных, которые расположены на внешних устройствах и
Внешняя сортировка – это сортировка данных, которые расположены на внешних устройствах и

Слайд 54Внешние сортировки применяются к данным, которые хранятся во внешней памяти.
При выполнении
Внешние сортировки применяются к данным, которые хранятся во внешней памяти.
При выполнении

Слайд 55Данные, хранящиеся на внешних устройствах, имеют большой объем, что не позволяет их
Данные, хранящиеся на внешних устройствах, имеют большой объем, что не позволяет их

Слайд 56Серия (упорядоченный отрезок) – это последовательность элементов, которая упорядочена (отсортирована) по ключу.
Длина
Серия (упорядоченный отрезок) – это последовательность элементов, которая упорядочена (отсортирована) по ключу.
Длина

Слайд 57Фаза – это действия по однократной обработке всей последовательности элементов.
Двухфазная сортировка
Фаза – это действия по однократной обработке всей последовательности элементов.
Двухфазная сортировка

Слайд 58Общий алгоритм сортировки слиянием
Сначала серии распределяются на два или более вспомогательных файлов.
Общий алгоритм сортировки слиянием
Сначала серии распределяются на два или более вспомогательных файлов.

Слайд 59Сортировка простым слиянием
Алгоритм сортировки простым слияния является простейшим алгоритмом внешней сортировки, основанный
Сортировка простым слиянием
Алгоритм сортировки простым слияния является простейшим алгоритмом внешней сортировки, основанный

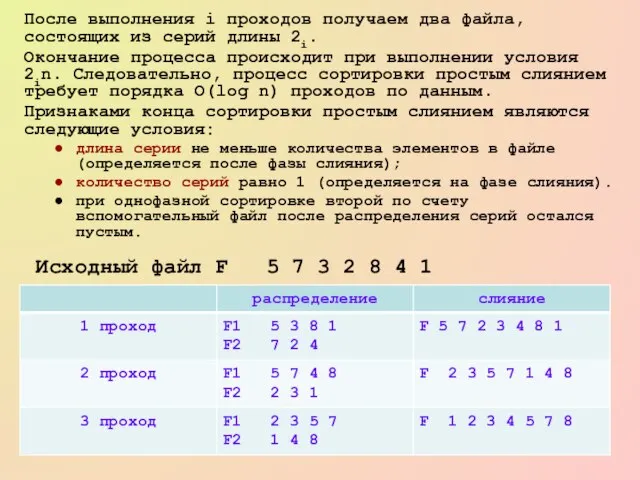
Слайд 60После выполнения i проходов получаем два файла, состоящих из серий длины 2i.
После выполнения i проходов получаем два файла, состоящих из серий длины 2i.
Слайд 61//Описание функции сортировки простым слиянием
void Simple_Merging_Sort (char *name)
{
int a1, a2, k,
//Описание функции сортировки простым слиянием
void Simple_Merging_Sort (char *name)
{
int a1, a2, k,

Слайд 62while ( !feof(f) ) //пока не конец файла
{
for ( i =
while ( !feof(f) ) //пока не конец файла
{
for ( i =
Слайд 63while( !feof(f1) && !feof(f2) )
{
i = 0;
j = 0;
while(i
while( !feof(f1) && !feof(f2) )
{
i = 0;
j = 0;
while(i
Слайд 64while ( !feof(f1) )
{
fprintf(f,"%d ",a1);
fscanf(f1,"%d",&a1);
}
while ( !feof(f2) )
{
while ( !feof(f1) )
{
fprintf(f,"%d ",a1);
fscanf(f1,"%d",&a1);
}
while ( !feof(f2) )
{
Слайд 65Сортировка естественным слиянием
В случае простого слияния частичная упорядоченность сортируемых данных не дает
Сортировка естественным слиянием
В случае простого слияния частичная упорядоченность сортируемых данных не дает

Слайд 66Алгоритм сортировки естественным слиянием
Шаг 1. Исходный файл f разбивается на два вспомогательных
Алгоритм сортировки естественным слиянием
Шаг 1. Исходный файл f разбивается на два вспомогательных

Слайд 67Признаками конца сортировки естественным слиянием являются следующие условия:
количество серий равно 1 (определяется
Признаками конца сортировки естественным слиянием являются следующие условия:
количество серий равно 1 (определяется
Слайд 68//Описание функции сортировки естественным //слиянием
void Natural_Merging_Sort (char *name)
{
int s1, s2, a1,
//Описание функции сортировки естественным //слиянием
void Natural_Merging_Sort (char *name)
{
int s1, s2, a1,
Слайд 69if ( !feof(f) ) { fprintf(f1,"%d ",a1); }
if ( !feof(f) ) fscanf(f,"%d",&a2);
while
if ( !feof(f) ) { fprintf(f1,"%d ",a1); }
if ( !feof(f) ) fscanf(f,"%d",&a2);
while

Слайд 70if ( s2 > 0 && mark == 2 )
{ fprintf(f2,"'");}
if ( s2 > 0 && mark == 2 )
{ fprintf(f2,"'");}

Слайд 71bool file1, file2;
while ( !feof(f1) && !feof(f2) )
{
file1 =
bool file1, file2;
while ( !feof(f1) && !feof(f2) )
{
file1 =
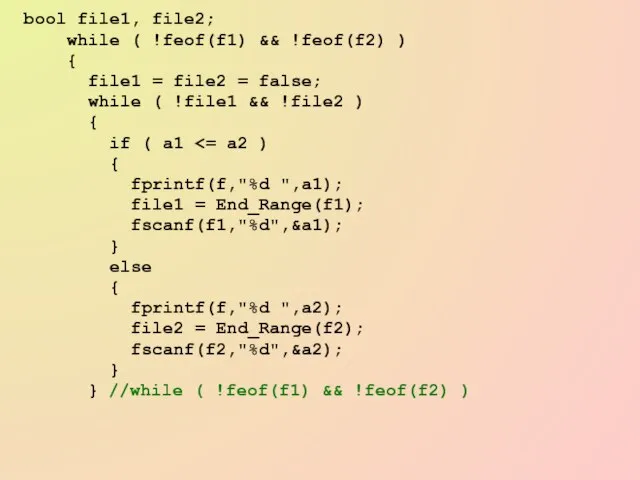
Слайд 72while ( !file1 )
{
fprintf(f,"%d ",a1);
file1 = End_Range(f1);
fscanf(f1,"%d",&a1);
}
while (
while ( !file1 )
{
fprintf(f,"%d ",a1);
file1 = End_Range(f1);
fscanf(f1,"%d",&a1);
}
while (
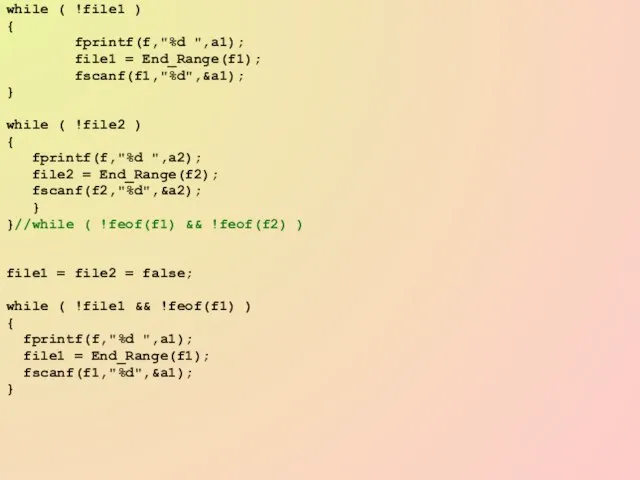
Слайд 73while ( !file2 && !feof(f2) )
{
fprintf(f,"%d ",a2);
file2 = End_Range(f2);
while ( !file2 && !feof(f2) )
{
fprintf(f,"%d ",a2);
file2 = End_Range(f2);
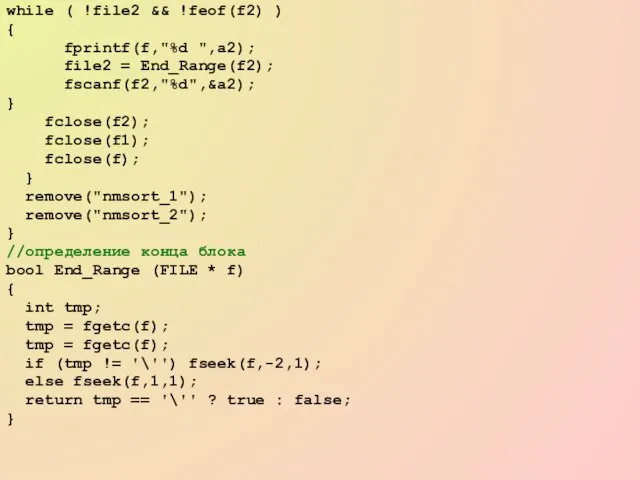
Слайд 74Выводы.
Число чтений или перезаписей файлов при использовании метода естественного слияния будет
Выводы.
Число чтений или перезаписей файлов при использовании метода естественного слияния будет

Слайд 75Краткие итоги
Внешние сортировки применяются к данным, которые хранятся во внешней памяти.
Внешние
Краткие итоги
Внешние сортировки применяются к данным, которые хранятся во внешней памяти.
Внешние

Слайд 76Алгоритмы внешних сортировок отличаются по реализации числом фаз и путей.
Простое слияние является
Алгоритмы внешних сортировок отличаются по реализации числом фаз и путей.
Простое слияние является

 Психолого-педагогическая компетентность педагога как условие достижения современного качества образования
Психолого-педагогическая компетентность педагога как условие достижения современного качества образования Металлогения областей автономной активизации
Металлогения областей автономной активизации  Презентация на тему Колумбия
Презентация на тему Колумбия Режимы течения. Уравнения притока
Режимы течения. Уравнения притока Регистрация
Регистрация Формирование у детей старшего дошкольного возраста чувства гражданской принадлежности
Формирование у детей старшего дошкольного возраста чувства гражданской принадлежности 3_Prezentatsia_BiUU
3_Prezentatsia_BiUU Способы завязывания платков и шарфов
Способы завязывания платков и шарфов Итоги тренировочной работы ГИА 9 класс
Итоги тренировочной работы ГИА 9 класс Первое кругосветное плавание
Первое кругосветное плавание Исследовательское обучение учащихся во внеурочной деятельности по ФГОС - презентация для начальной школы_
Исследовательское обучение учащихся во внеурочной деятельности по ФГОС - презентация для начальной школы_ EXPRESSING ABILITY
EXPRESSING ABILITY ШКОЛЬНЫЕ УЧЕБНИКИ АВТОРОВ МПГУ
ШКОЛЬНЫЕ УЧЕБНИКИ АВТОРОВ МПГУ Material properties
Material properties  16 октября состоялись соревнования среди 4-7 классов. В пионерболе за первое место сражались, команды 4 и 5 классов ,заслуженно победу
16 октября состоялись соревнования среди 4-7 классов. В пионерболе за первое место сражались, команды 4 и 5 классов ,заслуженно победу  СПОРТ ПРОТИВ НАРКОТИКОВ
СПОРТ ПРОТИВ НАРКОТИКОВ Olympische Spiele am Schwarzen Meer
Olympische Spiele am Schwarzen Meer Слова латинского происхождения в европейских языках
Слова латинского происхождения в европейских языках Статус-отчет. Статус проектов ЦЦТ
Статус-отчет. Статус проектов ЦЦТ Игровая модель смены: мотивируй правильно
Игровая модель смены: мотивируй правильно КОНСТИТУЦИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
КОНСТИТУЦИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ Примеры теплопередач в природе, быту и технике
Примеры теплопередач в природе, быту и технике КомпанияGolden Software, Ltd
КомпанияGolden Software, Ltd Как накопить деньги на мечту?
Как накопить деньги на мечту? Обзор систем Human Management Projects Tracking Digital
Обзор систем Human Management Projects Tracking Digital Метеорологическиеопасные явления
Метеорологическиеопасные явления Десоциализация ребенка или неуспех успешной женщины
Десоциализация ребенка или неуспех успешной женщины Презентация на тему Почему нужно есть много овощей и фруктов (1 класс)
Презентация на тему Почему нужно есть много овощей и фруктов (1 класс)