- Анатомия составных частей компилятора

Содержание
- 2. ТЕРМИНОЛОГИЯ Транслятор - это программа, которая переводит исходную программу в эквивалентную ей объектную программу. Если объектный
- 3. Препроцессор Препроцессор — это компьютерная программа — это компьютерная программа, принимающая данные на входе и выдающая
- 4. «Границы моего языка есть границы моего мира» Л.Витгенштейн
- 5. Компилятор компиляторов Компилятор компиляторов (КК) – система, позволяющая генерировать компиляторы; на входе системы - множество грамматик,
- 6. Классическая структура компилятора
- 7. На всех этих этапах происходит работа с различного рода таблицами
- 9. Синтаксис. Семантика. Синтаксический анализатор. Синтаксис - совокупность правил некоторого языка, определяющих формирование его элементов. Иначе говоря,
- 10. Лексический анализ (сканер) На входе сканера - цепочка символов некоторого алфавита (именно так выглядит для сканера
- 11. Как будет интерпретироваться такая входная последовательность "567АВ" ?
- 12. Прямой ЛА и непрямой ЛА Прямой ЛА определяет лексему, расположенную непосредственно справа от текущего указателя, и
- 13. DO5I=1,10 Фортран – это классический пример языка, использующего непрямой лексический анализатор. Все дело в том, что
- 14. Итак, на выходе сканера - внутреннее представление имен, разделителей и т.п.
- 15. Работа с таблицами Таблица имен представляет собой структуру, подобную следующей: Механизм работы с таблицами должен обеспечивать:
- 16. Синтаксический и семантический анализ Синтаксический анализ - это процесс, в котором исследуется цепочка лексем и устанавливается,
- 17. Синтаксический анализатор расчленяет исходную программу на составные части, формирует ее внутреннее представление, заносит информацию в таблицу
- 18. Синтаксический анализатор можно разбить на следующие составляющие : ∙ распознаватель; блок семантического анализа; объектную модель, или
- 20. Предложения исходной программы обычно записываются в инфиксной форме
- 21. Три вида записи выражений Существуют три вида записи выражений: 1. инфиксная форма, в которой оператор расположен
- 22. Обычно под польской формой понимают именно постфиксную форму записи. Кроме того, используются и такие внутренние формы
- 23. Дерево. Допустим, имеется входная цепочка i=(a+b)*c. Тогда дерево будет выглядеть так: У каждого элемента дерева может
- 24. Тетрада- это четверка, состоящая из кода операции, приемника и двух операндов. Если требуется не два, а
- 25. Пусть на вход синтаксического анализатора подаются выражения " =( + )* " и "A = B+C*D"
- 26. Тетрады для " = ( + )* " +, , , T1 *, T1, , T2
- 27. 3 Польская форма для " = ( + )* ": + * = И еще один
- 28. Алгоритм вычисления польской формы записи очень прост: Просматриваем последовательно символы входной цепочки. Если очередной символ является
- 29. ТЕОРИЯ ФОРМАЛЬНЫХ ЯЗЫКОВ ГРАММАТИКИ ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЕ Общение на каком-либо языке – искусственном или естественном- заключается в
- 30. Определение: Язык L - это множество цепочек конечной длины в алфавите Σ . Одним из наиболее
- 31. Если ∑ - множество (алфавит или словарь), то ∑ * - замыкание множества ∑ , или,
- 32. Определение. Грамматика - это четверка G = (N, Σ ,P,S), где N - конечное множество нетерминальных
- 33. Нормальная форма Бэкуса-Наура := A|B|C|…|Z := 0|1| … |9 := { | } Грамматика целых чисел
- 34. Формула с плюсами и минусами без скобок := | := +|-
- 35. Диаграммы Вирта
- 37. ИЕРАРХИЯ ХОМСКОГО Иерархия Хомского — классификация формальных языков — классификация формальных языков и формальных грамматик —
- 38. Конечные автоматы
- 39. В основе всех процессов обработки языков лежит теория автоматов и формальных языков.
- 40. Лексический блок IFB1=13GOTO4 Здесь 6 лексем Каждая лексема состоит из 2-х частей: класса и значения
- 41. Синтаксический блок Этот блок переводит лексическую последовательность в другую последовательность. 5 лексем 2 лексемы – они
- 42. Генератор кода
- 43. Семантическая обработка
- 44. Оптимизация
- 45. Блоки и проходы компилятора
- 49. Конечные автоматы
- 50. Конечные распознаватели
- 51. Контроль нечетности
- 52. Входной алфавит
- 54. Переходы
- 55. Функция переходов
- 56. Конечный автомат
- 57. 1101
- 58. Регулярные множества
- 59. Таблица переходов
- 60. Таким образом таблица переходов создаёт конечный автомат:
- 61. Ещё один автомат
- 62. Концевые маркеры и выходы из распознавания
- 64. Пусть между управляющими символами задана цепочка Концевой маркер Получение обрабатывающего автомата из распознающего
- 65. Если решили прервать процесс…
- 68. Лексический анализ входного языка транслятора (работа по курсу «Теория вычислительных процессов и структур»)
- 69. Процесс трансляции с алгоритмического языка можно условно разбить на три этапа: лексический анализ, грамматический разбор и
- 70. Лексический анализ Под лексическим анализом понимают процесс предварительной обработки исходной программы, на котором основные лексические единицы
- 71. Дескриптор Дескриптор- это пара вида: ( . ), где - это, как правило, числовой код класса
- 72. После проведения успешной идентификации лексемы формируется её образ - дескриптор, он помещается в выходные данные лексического
- 73. PROGRAM PRIMER; VAR X,Y,Z : REAL; BEGIN X:=5; Y:=6; Z:=X+Y; END; Применим следующие коды для типов
- 74. Лексический анализ можно производить, если нам задан алфавит, список ключевых слов языка и служебных символов. Пусть
- 75. На основании составленных таблиц можно записать входной текст через введённые дескрипторы (дескрипторный текст): ( К1, 1)
- 76. Схемы программ Схема программ— математическая модель программ, в которой такие понятия, как оператор, операнд, переменная, выполнение
- 77. Стандартные схемы Стандартные схемы — схемы алголоподобных программ, исследование которых составляет основное содержание общей теории схем
- 79. Доказательство правильности программ Принцип математической индукции Принцип простой индукции Обычно математическую индукцию вводят как метод доказательства
- 80. Принцип модифицированной простой индукции Иногда необходимо доказать, что высказывание S(n) справедливо для всех целых n≥n0. Для
- 81. ПРИМЕР. Для любого неотрицательного числа n доказать, что 20 + 21 + 22 + … +
- 82. Иногда нужно доказать справедливость высказывания S(n) для целых n, удовлетворяющих условию n0≤n≤m0. Так как между n0
- 83. ДОКАЗАТЕЛЬСТВО ПРАВИЛЬНОСТИ БЛОК-СХЕМ ПРОГРАММ Если мы хотим доказать, что некоторая программа правильна или верна, то прежде
- 84. Высказывание о входных данных Утверждение, относящееся к данным (или высказывание о входных данных), описывающее ограничение на
- 85. Инвариант цикла
- 86. Инвариант цикла Под инвариантом цикла будем понимать утверждение, связывающее переменные, изменяющиеся внутри тела цикла, которое принимает
- 87. Конечность цикла Кроме того, припишем к этой же точке ключевое утверждение о конечности цикла, в котором
- 88. При доказательстве правильности блок-схем являются: 1) доказательство того, что при попадании во входную точку цикла всегда
- 89. ПРИМЕР 2. Предположим, что нужно вычислить произведение двух любых целых чисел M, N, причем M≥0 и
- 90. Доказательства правильности для блок-схемы очень простой программы
- 91. Докажем теперь, что приведенная на рис. блок-схема правильна, т. е. если ее начать выполнять с M
- 94. МЕТОД ИНДУКТИВНЫХ УТВЕРЖДЕНИЙ При доказательстве правильности программ методом индуктивных утверждений доказательство конечности программы проводится отдельно от
- 95. Пусть A – некоторое утверждение, описывающее предполагаемые свойства данных в программе (блок-схеме), а C – утверждение,
- 96. Метод индуктивных утверждений Свяжем утверждение A с началом программы, а утверждение С – с конечной точкой
- 98. Конечность программы Сначала надо удостовериться, что программа закончится. Отметим, что единственными местами в программе, где изменяются
- 99. Для доказательства правильности рассмотрим все пути 1. Путь из точки 1 в точку 2. Предположим, что
- 100. 2. Путь из точки 2 в точку 3. Предположим, что мы находимся в точке 2 и
- 101. 3. Путь из точки 3 через точки 4, 5 к точке 3. Предположим, что мы находимся
- 102. 4. Путь из точки 3 через точки 4, 6 в точку 3. Рассуждения для этого пути
- 103. 5. Путь из точки 3 через точку 7 в точку 2. Предположим, что мы находимся в
- 104. 6. Путь от точки 2 в точку 8. Предположим, что мы находимся в точке 2, справедливо
- 105. Основной метод при доказательстве правильности рекурсивных программ называется методом структурной индукции. F(Х1, ... , ХN) ≡
- 106. Пример 7.1. Рассмотрим рекурсивную программу, определенную для любого положительного целого числа X: F(Х) ≡ IF Х
- 107. Чтобы сделать наш язык программирования точным, нам нужно задать правила вычислений для программ, определяющие последовательность вычислений.
- 108. Структурная индукция Рекурсивные программы обычно строятся по следующей схеме: сначала в них явно определяется способ вычисления
- 109. Докажем правильность рекурсивной программы: F(Х) ≡ IF X = 1 ТНЕN 1 ЕLSЕ ОТНЕRWISЕ X•F(Х –
- 111. Скачать презентацию
Слайд 2ТЕРМИНОЛОГИЯ
Транслятор - это программа, которая переводит исходную программу в эквивалентную ей объектную
ТЕРМИНОЛОГИЯ
Транслятор - это программа, которая переводит исходную программу в эквивалентную ей объектную

Слайд 3Препроцессор
Препроцессор — это компьютерная программа — это компьютерная программа, принимающая данные на входе и
Препроцессор
Препроцессор — это компьютерная программа — это компьютерная программа, принимающая данные на входе и

Слайд 4«Границы моего языка есть границы моего мира»
Л.Витгенштейн
«Границы моего языка есть границы моего мира»
Л.Витгенштейн
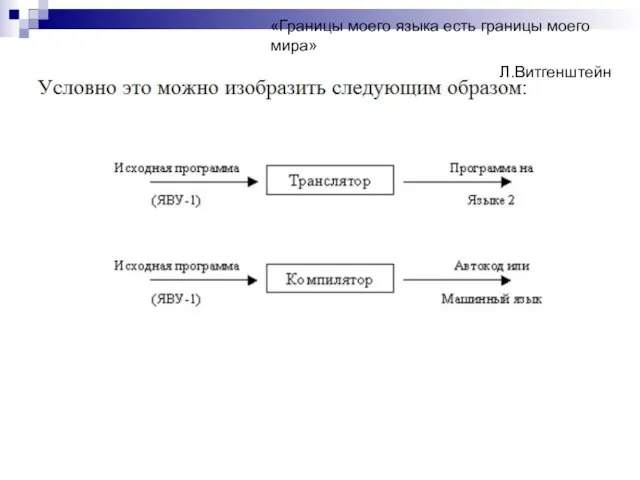
Слайд 5Компилятор компиляторов
Компилятор компиляторов (КК) – система, позволяющая генерировать компиляторы; на входе системы
Компилятор компиляторов
Компилятор компиляторов (КК) – система, позволяющая генерировать компиляторы; на входе системы

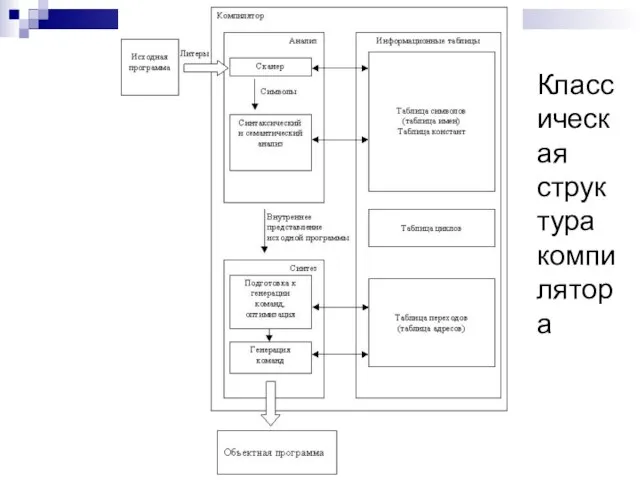
Слайд 6Классическая структура компилятора
Классическая структура компилятора
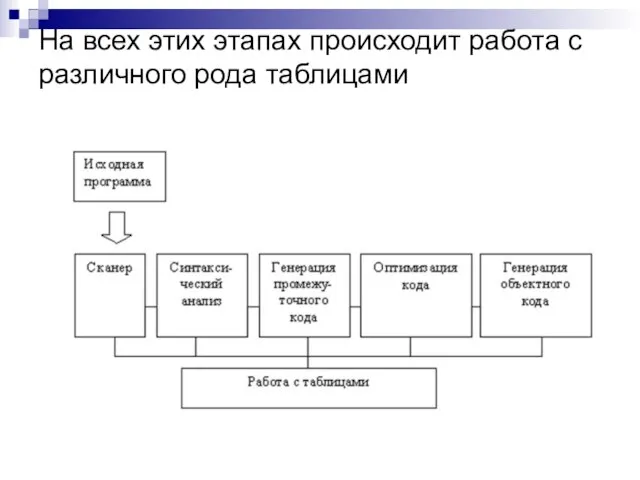
Слайд 7На всех этих этапах происходит работа с различного рода таблицами
На всех этих этапах происходит работа с различного рода таблицами
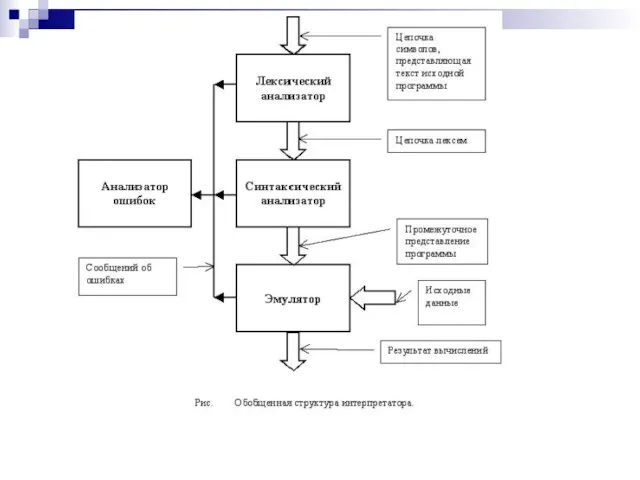
Слайд 9Синтаксис. Семантика. Синтаксический анализатор.
Синтаксис - совокупность правил некоторого языка, определяющих формирование
Синтаксис. Семантика. Синтаксический анализатор.
Синтаксис - совокупность правил некоторого языка, определяющих формирование

Слайд 10Лексический анализ (сканер)
На входе сканера - цепочка символов некоторого алфавита (именно так
Лексический анализ (сканер)
На входе сканера - цепочка символов некоторого алфавита (именно так

Слайд 11Как будет интерпретироваться такая входная последовательность "567АВ" ?
Как будет интерпретироваться такая входная последовательность "567АВ" ?

Слайд 12Прямой ЛА и непрямой ЛА
Прямой ЛА определяет лексему, расположенную непосредственно справа
Прямой ЛА и непрямой ЛА
Прямой ЛА определяет лексему, расположенную непосредственно справа

Слайд 13DO5I=1,10
Фортран – это классический пример языка, использующего непрямой лексический анализатор. Все дело
DO5I=1,10
Фортран – это классический пример языка, использующего непрямой лексический анализатор. Все дело

Слайд 14Итак, на выходе сканера - внутреннее представление имен, разделителей и т.п.
Итак, на выходе сканера - внутреннее представление имен, разделителей и т.п.

Слайд 15Работа с таблицами
Таблица имен представляет собой структуру, подобную следующей:
Механизм работы с таблицами
Работа с таблицами
Таблица имен представляет собой структуру, подобную следующей:
Механизм работы с таблицами

Слайд 16Синтаксический и семантический анализ
Синтаксический анализ - это процесс, в котором исследуется цепочка
Синтаксический и семантический анализ
Синтаксический анализ - это процесс, в котором исследуется цепочка

Слайд 17Синтаксический анализатор расчленяет исходную программу на составные части, формирует ее внутреннее представление,
Синтаксический анализатор расчленяет исходную программу на составные части, формирует ее внутреннее представление,

Слайд 18Синтаксический анализатор можно разбить на следующие составляющие :
∙ распознаватель;
блок семантического анализа;
Синтаксический анализатор можно разбить на следующие составляющие :
∙ распознаватель;
блок семантического анализа;

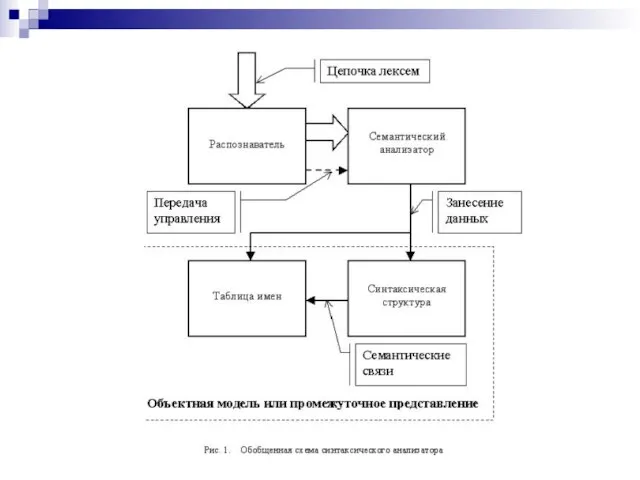
Слайд 20Предложения исходной программы обычно записываются в инфиксной форме
Предложения исходной программы обычно записываются в инфиксной форме

Слайд 21Три вида записи выражений
Существуют три вида записи выражений:
1. инфиксная форма, в которой
Три вида записи выражений
Существуют три вида записи выражений: 1. инфиксная форма, в которой

Слайд 22Обычно под польской формой понимают именно постфиксную форму записи. Кроме того, используются
Обычно под польской формой понимают именно постфиксную форму записи. Кроме того, используются

Слайд 23Дерево.
Допустим, имеется входная цепочка i=(a+b)*c. Тогда дерево будет выглядеть так:
У каждого элемента
Дерево.
Допустим, имеется входная цепочка i=(a+b)*c. Тогда дерево будет выглядеть так:
У каждого элемента

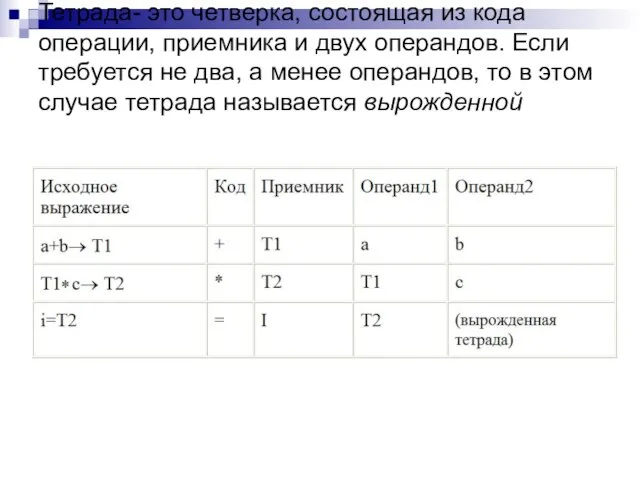
Слайд 24Тетрада- это четверка, состоящая из кода операции, приемника и двух операндов. Если
Тетрада- это четверка, состоящая из кода операции, приемника и двух операндов. Если
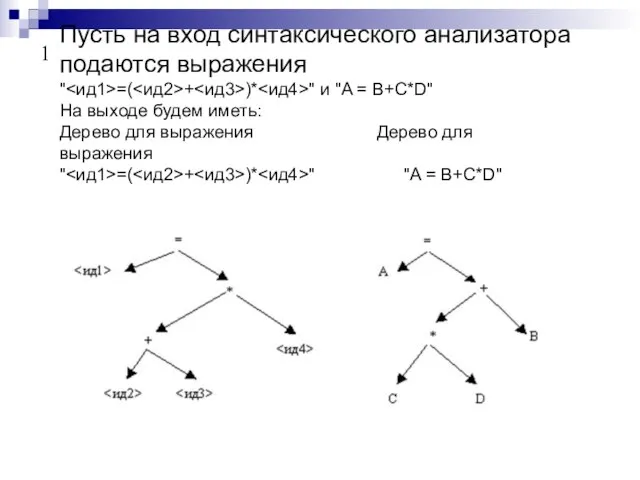
Слайд 25Пусть на вход синтаксического анализатора подаются выражения
"<ид1>=(<ид2>+<ид3>)*<ид4>" и "A = B+C*D"
На выходе
Пусть на вход синтаксического анализатора подаются выражения "<ид1>=(<ид2>+<ид3>)*<ид4>" и "A = B+C*D" На выходе
Слайд 26Тетрады для
"<ид1> = (<ид2>+<ид3>)*<ид4>"
+, <ид2>, <ид3>, T1
*, T1, <ид4>, T2
=,
Тетрады для
"<ид1> = (<ид2>+<ид3>)*<ид4>"
+, <ид2>, <ид3>, T1
*, T1, <ид4>, T2
=,

Слайд 273
Польская форма для "<ид1> = (<ид2>+<ид3>)*<ид4>":
<ид1> <ид2> <ид3> + <ид4> *
3
Польская форма для "<ид1> = (<ид2>+<ид3>)*<ид4>":
<ид1> <ид2> <ид3> + <ид4> *

Слайд 28Алгоритм вычисления польской формы записи очень прост:
Просматриваем последовательно символы входной цепочки. Если
Алгоритм вычисления польской формы записи очень прост:
Просматриваем последовательно символы входной цепочки. Если

Слайд 29ТЕОРИЯ ФОРМАЛЬНЫХ ЯЗЫКОВ ГРАММАТИКИ
ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЕ
Общение на каком-либо языке – искусственном или естественном-
ТЕОРИЯ ФОРМАЛЬНЫХ ЯЗЫКОВ ГРАММАТИКИ
ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЕ
Общение на каком-либо языке – искусственном или естественном-

Слайд 30Определение: Язык L - это множество цепочек конечной длины в алфавите Σ
Определение: Язык L - это множество цепочек конечной длины в алфавите Σ

Слайд 31Если ∑ - множество (алфавит или словарь), то ∑ * - замыкание
Если ∑ - множество (алфавит или словарь), то ∑ * - замыкание

Слайд 32Определение. Грамматика - это четверка G = (N, Σ ,P,S),
где
N - конечное
Определение. Грамматика - это четверка G = (N, Σ ,P,S),
где
N - конечное

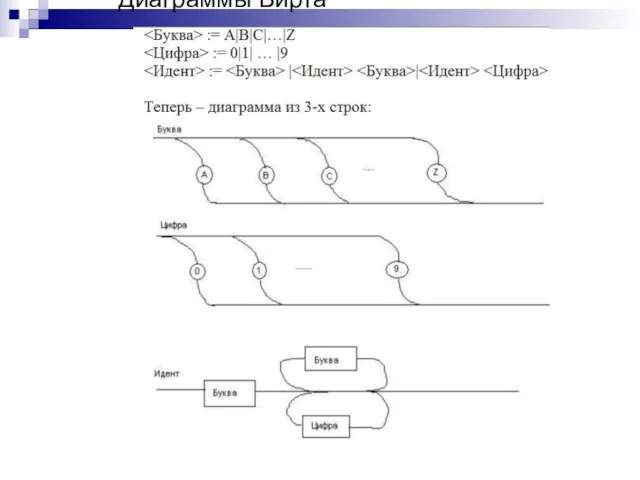
Слайд 33Нормальная форма Бэкуса-Наура
<Буква> := A|B|C|…|Z
<Цифра> := 0|1| … |9
<Идент> := <Буква> {<Буква>|<Цифра>}
Грамматика
Нормальная форма Бэкуса-Наура
<Буква> := A|B|C|…|Z
<Цифра> := 0|1| … |9
<Идент> := <Буква> {<Буква>|<Цифра>}
Грамматика

Слайд 34Формула с плюсами и минусами без скобок
<формула> := <число>|<формула><знак><число>
<знак> := +|-
Формула с плюсами и минусами без скобок
<формула> := <число>|<формула><знак><число>
<знак> := +|-

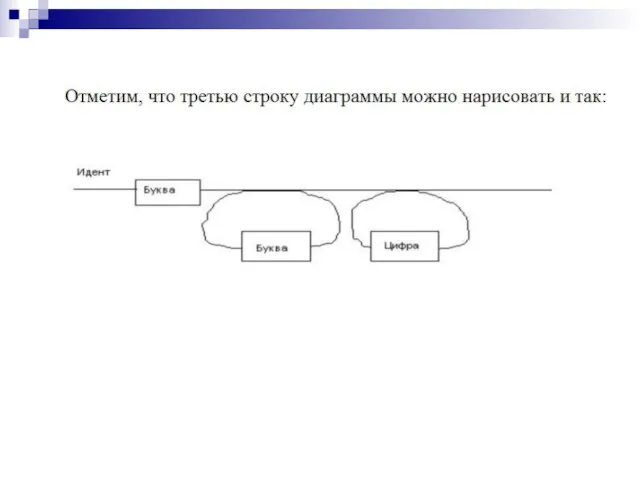
Слайд 35Диаграммы Вирта
Диаграммы Вирта
Слайд 37
ИЕРАРХИЯ ХОМСКОГО
Иерархия Хомского — классификация формальных языков — классификация формальных языков и
ИЕРАРХИЯ ХОМСКОГО
Иерархия Хомского — классификация формальных языков — классификация формальных языков и

Слайд 38Конечные автоматы
Конечные автоматы

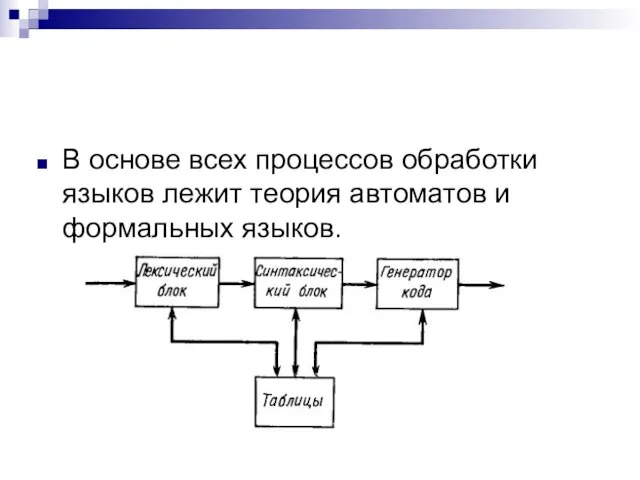
Слайд 39В основе всех процессов обработки языков лежит теория автоматов и формальных языков.
В основе всех процессов обработки языков лежит теория автоматов и формальных языков.
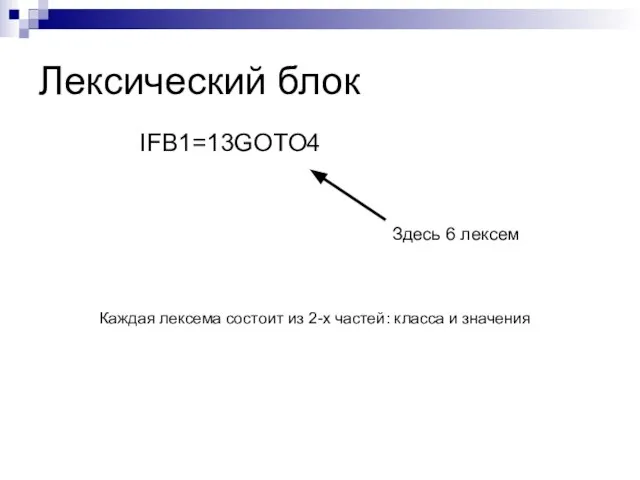
Слайд 40Лексический блок
IFB1=13GOTO4
Здесь 6 лексем
Каждая лексема состоит из 2-х частей: класса и значения
Лексический блок
IFB1=13GOTO4
Здесь 6 лексем
Каждая лексема состоит из 2-х частей: класса и значения
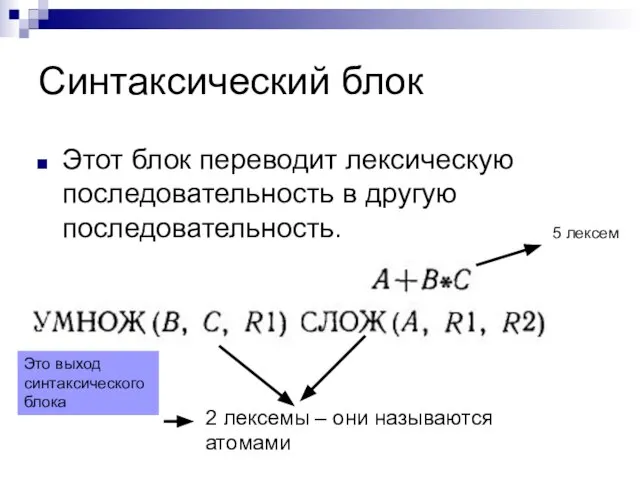
Слайд 41Синтаксический блок
Этот блок переводит лексическую последовательность в другую последовательность.
5 лексем
2 лексемы –
Синтаксический блок
Этот блок переводит лексическую последовательность в другую последовательность.
5 лексем
2 лексемы –
Слайд 42Генератор кода
Генератор кода

Слайд 43Семантическая обработка
Семантическая обработка

Слайд 44Оптимизация
Оптимизация

Слайд 45Блоки и проходы компилятора
Блоки и проходы компилятора




Слайд 49Конечные автоматы
Конечные автоматы

Слайд 50Конечные распознаватели
Конечные распознаватели

Слайд 51Контроль нечетности
Контроль нечетности

Слайд 52Входной алфавит
Входной алфавит


Слайд 54Переходы
Переходы

Слайд 55Функция переходов
Функция переходов

Слайд 56Конечный автомат
Конечный автомат

Слайд 571101
1101

Слайд 58Регулярные множества
Регулярные множества

Слайд 59Таблица переходов
Таблица переходов

Слайд 60Таким образом таблица переходов создаёт конечный автомат:
Таким образом таблица переходов создаёт конечный автомат:

Слайд 61Ещё один автомат
Ещё один автомат

Слайд 62Концевые маркеры и выходы из распознавания
Концевые маркеры и выходы из распознавания


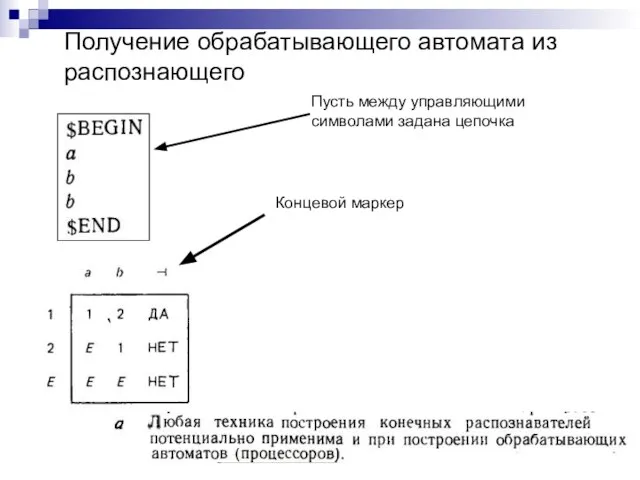
Слайд 64Пусть между управляющими символами задана цепочка
Концевой маркер
Получение обрабатывающего автомата из распознающего
Пусть между управляющими символами задана цепочка
Концевой маркер
Получение обрабатывающего автомата из распознающего
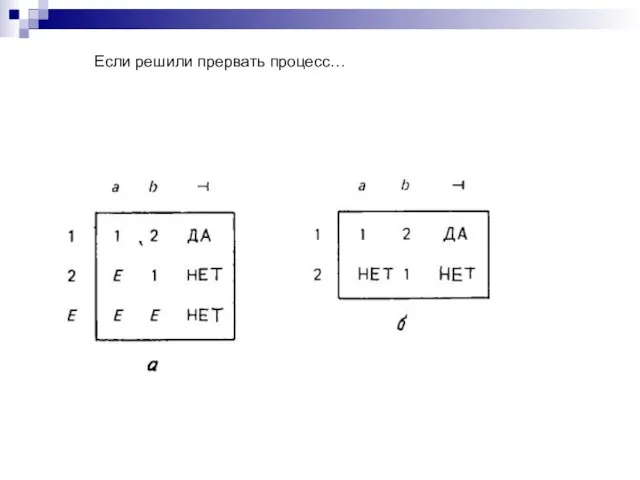
Слайд 65Если решили прервать процесс…
Если решили прервать процесс…


Слайд 68Лексический анализ входного языка транслятора (работа по курсу «Теория вычислительных процессов и
Лексический анализ входного языка транслятора (работа по курсу «Теория вычислительных процессов и

Слайд 69Процесс трансляции с алгоритмического языка можно условно разбить на три этапа:
лексический
Процесс трансляции с алгоритмического языка можно условно разбить на три этапа: лексический

Слайд 70Лексический анализ
Под лексическим анализом понимают процесс предварительной обработки исходной программы, на котором
Лексический анализ
Под лексическим анализом понимают процесс предварительной обработки исходной программы, на котором

Слайд 71Дескриптор
Дескриптор- это пара вида: ( . < указатель>), где - это, как
Дескриптор
Дескриптор- это пара вида: ( . < указатель>), где - это, как

Слайд 72После проведения успешной идентификации лексемы формируется её образ
- дескриптор, он помещается в
После проведения успешной идентификации лексемы формируется её образ - дескриптор, он помещается в

Слайд 73PROGRAM PRIMER;
VAR X,Y,Z : REAL;
BEGIN
X:=5;
Y:=6;
Z:=X+Y;
END;
Применим следующие коды для типов лексем:
К1- ключевое слово;
К2-
PROGRAM PRIMER;
VAR X,Y,Z : REAL;
BEGIN
X:=5;
Y:=6;
Z:=X+Y;
END;
Применим следующие коды для типов лексем:
К1- ключевое слово;
К2-

Слайд 74Лексический анализ можно производить, если нам задан алфавит, список ключевых слов языка
Лексический анализ можно производить, если нам задан алфавит, список ключевых слов языка

Слайд 75На основании составленных таблиц можно записать входной текст через введённые дескрипторы (дескрипторный
На основании составленных таблиц можно записать входной текст через введённые дескрипторы (дескрипторный

Слайд 76Схемы программ
Схема программ— математическая модель программ, в которой такие понятия, как оператор,
Схемы программ
Схема программ— математическая модель программ, в которой такие понятия, как оператор,

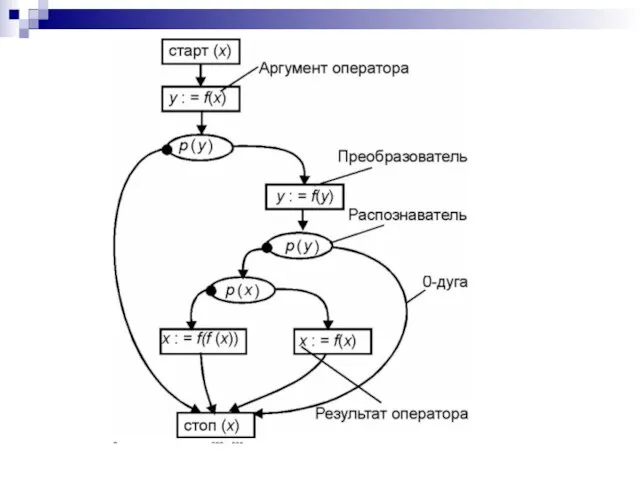
Слайд 77Стандартные схемы
Стандартные схемы — схемы алголоподобных программ, исследование которых составляет основное содержание
Стандартные схемы
Стандартные схемы — схемы алголоподобных программ, исследование которых составляет основное содержание

Слайд 79Доказательство правильности программ
Принцип математической индукции
Принцип простой индукции
Обычно математическую индукцию вводят
Доказательство правильности программ
Принцип математической индукции
Принцип простой индукции
Обычно математическую индукцию вводят

Слайд 80Принцип модифицированной простой индукции
Иногда необходимо доказать, что высказывание S(n) справедливо для всех
Принцип модифицированной простой индукции
Иногда необходимо доказать, что высказывание S(n) справедливо для всех

Слайд 81ПРИМЕР. Для любого неотрицательного числа n доказать, что
20 + 21 + 22
ПРИМЕР. Для любого неотрицательного числа n доказать, что 20 + 21 + 22

Слайд 82Иногда нужно доказать справедливость высказывания S(n) для целых n, удовлетворяющих условию n0≤n≤m0.
Иногда нужно доказать справедливость высказывания S(n) для целых n, удовлетворяющих условию n0≤n≤m0.

Слайд 83ДОКАЗАТЕЛЬСТВО ПРАВИЛЬНОСТИ
БЛОК-СХЕМ ПРОГРАММ
Если мы хотим доказать, что некоторая программа правильна или
ДОКАЗАТЕЛЬСТВО ПРАВИЛЬНОСТИ
БЛОК-СХЕМ ПРОГРАММ
Если мы хотим доказать, что некоторая программа правильна или

Слайд 84Высказывание о входных данных
Утверждение, относящееся к данным (или высказывание о входных данных),
Высказывание о входных данных
Утверждение, относящееся к данным (или высказывание о входных данных),

Слайд 85Инвариант цикла
Инвариант цикла

Слайд 86Инвариант цикла
Под инвариантом цикла будем понимать утверждение, связывающее переменные, изменяющиеся внутри тела
Инвариант цикла
Под инвариантом цикла будем понимать утверждение, связывающее переменные, изменяющиеся внутри тела

Слайд 87Конечность цикла
Кроме того, припишем к этой же точке ключевое утверждение о конечности
Конечность цикла
Кроме того, припишем к этой же точке ключевое утверждение о конечности

Слайд 88При доказательстве правильности блок-схем являются:
1) доказательство того, что при попадании во входную
При доказательстве правильности блок-схем являются:
1) доказательство того, что при попадании во входную

Слайд 89ПРИМЕР 2. Предположим, что нужно вычислить произведение двух любых целых чисел M,
ПРИМЕР 2. Предположим, что нужно вычислить произведение двух любых целых чисел M,

Слайд 90Доказательства правильности для блок-схемы очень простой программы
Доказательства правильности для блок-схемы очень простой программы
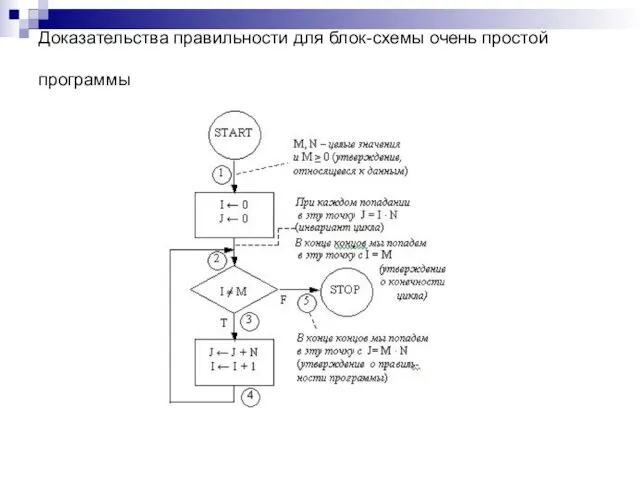
Слайд 91Докажем теперь, что приведенная на рис. блок-схема правильна, т. е. если ее
Докажем теперь, что приведенная на рис. блок-схема правильна, т. е. если ее



Слайд 94МЕТОД ИНДУКТИВНЫХ УТВЕРЖДЕНИЙ
При доказательстве правильности программ методом индуктивных утверждений доказательство конечности программы
МЕТОД ИНДУКТИВНЫХ УТВЕРЖДЕНИЙ
При доказательстве правильности программ методом индуктивных утверждений доказательство конечности программы

Слайд 95Пусть A – некоторое утверждение, описывающее предполагаемые свойства данных в программе (блок-схеме),
Пусть A – некоторое утверждение, описывающее предполагаемые свойства данных в программе (блок-схеме),

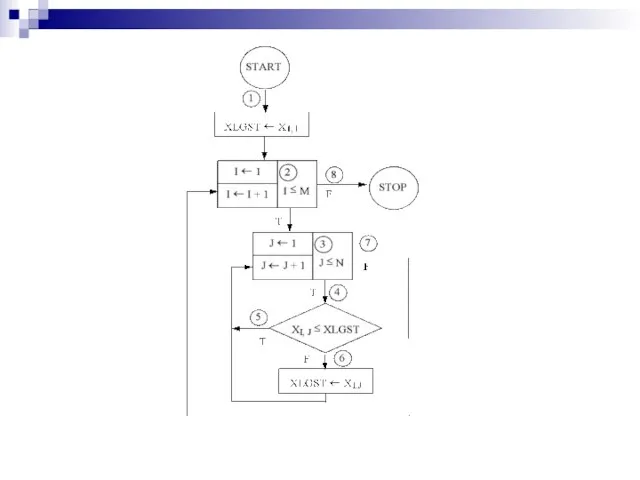
Слайд 96Метод индуктивных утверждений
Свяжем утверждение A с началом программы, а утверждение С
Метод индуктивных утверждений
Свяжем утверждение A с началом программы, а утверждение С

Слайд 98Конечность программы
Сначала надо удостовериться, что программа закончится. Отметим, что единственными местами в
Конечность программы
Сначала надо удостовериться, что программа закончится. Отметим, что единственными местами в

Слайд 99Для доказательства правильности рассмотрим все пути
1. Путь из точки 1 в точку
Для доказательства правильности рассмотрим все пути
1. Путь из точки 1 в точку

Слайд 1002. Путь из точки 2 в точку 3. Предположим, что мы находимся
2. Путь из точки 2 в точку 3. Предположим, что мы находимся

Слайд 1013. Путь из точки 3 через точки 4, 5 к точке 3.
3. Путь из точки 3 через точки 4, 5 к точке 3.

Слайд 1024. Путь из точки 3 через точки 4, 6 в точку 3.
4. Путь из точки 3 через точки 4, 6 в точку 3.

Слайд 1035. Путь из точки 3 через точку 7 в точку 2. Предположим,
5. Путь из точки 3 через точку 7 в точку 2. Предположим,

Слайд 1046. Путь от точки 2 в точку 8. Предположим, что мы находимся
6. Путь от точки 2 в точку 8. Предположим, что мы находимся

Слайд 105Основной метод при доказательстве правильности рекурсивных программ называется методом структурной индукции.
F(Х1,
Основной метод при доказательстве правильности рекурсивных программ называется методом структурной индукции.
F(Х1,

Слайд 106Пример 7.1. Рассмотрим рекурсивную программу, определенную для любого положительного целого числа X:
F(Х)
Пример 7.1. Рассмотрим рекурсивную программу, определенную для любого положительного целого числа X:
F(Х)

Слайд 107Чтобы сделать наш язык программирования точным, нам нужно задать правила вычислений для
Чтобы сделать наш язык программирования точным, нам нужно задать правила вычислений для

Слайд 108Структурная индукция
Рекурсивные программы обычно строятся по следующей схеме: сначала в них
Структурная индукция
Рекурсивные программы обычно строятся по следующей схеме: сначала в них

Слайд 109Докажем правильность рекурсивной программы:
F(Х) ≡ IF X = 1 ТНЕN 1
ЕLSЕ
Докажем правильность рекурсивной программы:
F(Х) ≡ IF X = 1 ТНЕN 1
ЕLSЕ

 Планировка кухни
Планировка кухни 30 червня 2011 року м. Київ, УНЦПД РЕЗУЛЬТАТИ МОНІТОРИНГУ ІНФОРМАЦІЙНОГО НАПОВНЕННЯ ОФІЦІЙНИХ ВЕБ-СТОРІНОК МІСЦЕВИХ ДЕРЖАВНИХ АДМІНІ
30 червня 2011 року м. Київ, УНЦПД РЕЗУЛЬТАТИ МОНІТОРИНГУ ІНФОРМАЦІЙНОГО НАПОВНЕННЯ ОФІЦІЙНИХ ВЕБ-СТОРІНОК МІСЦЕВИХ ДЕРЖАВНИХ АДМІНІ Структура информационного обеспечения процесса обучения
Структура информационного обеспечения процесса обучения Ударно-тяговые приборы
Ударно-тяговые приборы Одномерные массивы. Вставка и удаление элемента
Одномерные массивы. Вставка и удаление элемента Презентация на тему Деятельность римских юристов
Презентация на тему Деятельность римских юристов Морской транспорт
Морской транспорт Актив. Экономика и финансы проекта
Актив. Экономика и финансы проекта HR В УПРАВЛЕНЧЕСКОЙ КОМАНДЕ: роли, функции, формы взаимодействия с менеджментом
HR В УПРАВЛЕНЧЕСКОЙ КОМАНДЕ: роли, функции, формы взаимодействия с менеджментом Работа с источником
Работа с источником Презентация на тему Обучение грамоте 1 класс "Знакомство со звуком а, буквой А"
Презентация на тему Обучение грамоте 1 класс "Знакомство со звуком а, буквой А" В гости на Креатиду
В гости на Креатиду Бокс и борьба как основные виды силовых состязаний
Бокс и борьба как основные виды силовых состязаний ХРАНИЛИЩЕ БЕСЦЕННЫХ РЕЛИКВИЙ
ХРАНИЛИЩЕ БЕСЦЕННЫХ РЕЛИКВИЙ Подготовка учащихсяк ЕГЭ по математике
Подготовка учащихсяк ЕГЭ по математике Новогоднее мероприятие в стиле «Фильм! Фильм ! Фильм!»
Новогоднее мероприятие в стиле «Фильм! Фильм ! Фильм!» Деревянная архитектура. Рисунок карандашом
Деревянная архитектура. Рисунок карандашом А. П. Чехов «Ионыч»
А. П. Чехов «Ионыч» Оптимизация документооборота на предприятияхжелезнодорожного транспорта
Оптимизация документооборота на предприятияхжелезнодорожного транспорта Формы получения смешанного образования
Формы получения смешанного образования Освоение космоса и условия жизни на космическом корабле
Освоение космоса и условия жизни на космическом корабле Презентация Беларусь
Презентация Беларусь Откуда произошло название наших улиц
Откуда произошло название наших улиц Презентация на тему ДНК и РНК - нуклеиновые кислоты
Презентация на тему ДНК и РНК - нуклеиновые кислоты Loving Hut. Контент-план
Loving Hut. Контент-план Японская мифология
Японская мифология Сторителлинг Пишем с пользой!
Сторителлинг Пишем с пользой! Африка: ФГП и характер поверхности материка
Африка: ФГП и характер поверхности материка