- Архитектура вычислительных систем

Содержание
- 3. АРХИТЕКТУРА – искусство строить сооружения, неразрывно сочетая решение практических и эстетических задач АРХИТЕКТУРА ВС - комплекс
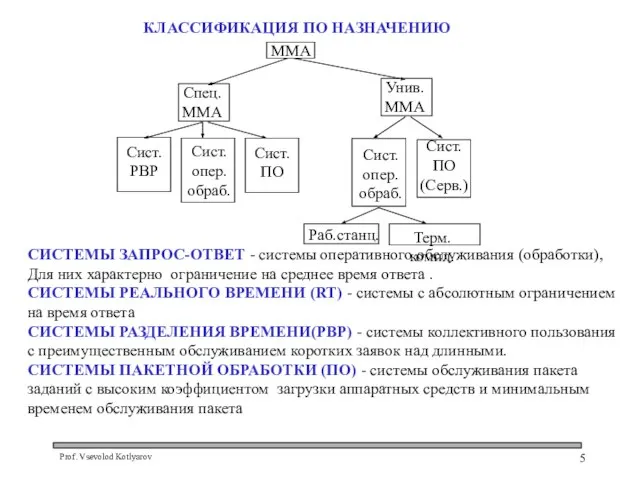
- 5. КЛАССИФИКАЦИЯ ПО НАЗНАЧЕНИЮ СИСТЕМЫ ЗАПРОС-ОТВЕТ - системы оперативного обслуживания (обработки), Для них характерно ограничение на среднее
- 6. КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
- 7. КЛАССЫ КЛАССИФИКАЦИИ ПО ПОТОКАМ SISD – фон-Неймановская архитектура: каждая команда арифметической обработки инициирует выполнение одной арифметической
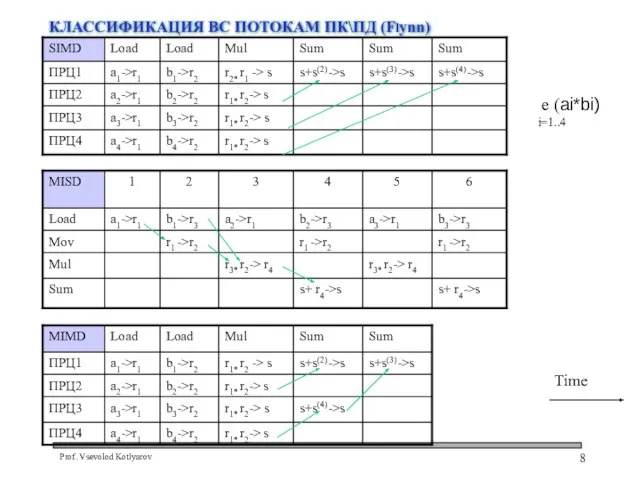
- 8. КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn) Time е (ai*bi) i=1..4
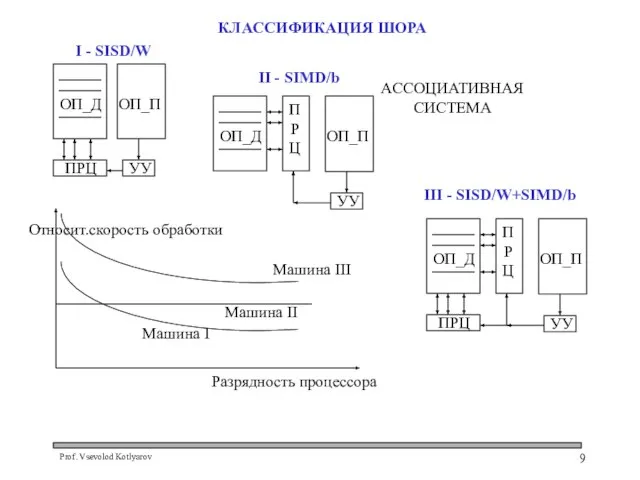
- 9. КЛАССИФИКАЦИЯ ШОРА
- 10. КЛАССЫ КЛАССИФИКАЦИИ ШОРА I – обычная ВМ с последовательной обработкой слов и параллельной обработкой разрядов слов
- 11. КЛАССИФИКАЦИЯ ШОРА
- 12. КЛАССЫ КЛАССИФИКАЦИИ ШОРА IV – ансамбль ПРЦ получается путем интеграции модулей машины I в единую вычислительную
- 13. КЛАССИФИКАЦИЯ ПО СТЕПЕНИ ПАРАЛЛЕЛИЗМА ОБРАБОТКИ 1 2 3 4 5 6 7 I-Обычн.ПРЦ II-Одноразр.ПРЦ III-Ансамбль ПРЦ
- 14. Закон Гроша: Производительность и стоимость ВС связаны квадратичным законом: p ~ C2 C/p 1990 2000 Закон
- 15. ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ 1. Параллельная ВС имеет более высокую производительность, чем последовательная при одинаковой стоимости. 2.
- 16. ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ Закон Джина Амдала в более точной формулировке: P=N/(X*N+1-X), где X – последовательная часть
- 17. КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
- 18. КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
- 19. ЧТО ПОСЛЕ СУПЕРСКАЛЯРНОЙ АРХИТЕКТУРЫ Суперскалярная архитектура обеспечивает параллелизм для традиционных последовательностей операций. Как ее улучшить: 1.
- 21. Скачать презентацию

Слайд 3АРХИТЕКТУРА – искусство строить сооружения, неразрывно сочетая решение практических и эстетических задач
АРХИТЕКТУРА
АРХИТЕКТУРА – искусство строить сооружения, неразрывно сочетая решение практических и эстетических задач
АРХИТЕКТУРА


Слайд 5 КЛАССИФИКАЦИЯ ПО НАЗНАЧЕНИЮ
СИСТЕМЫ ЗАПРОС-ОТВЕТ - системы оперативного обслуживания (обработки), Для них
КЛАССИФИКАЦИЯ ПО НАЗНАЧЕНИЮ
СИСТЕМЫ ЗАПРОС-ОТВЕТ - системы оперативного обслуживания (обработки), Для них
Слайд 6КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
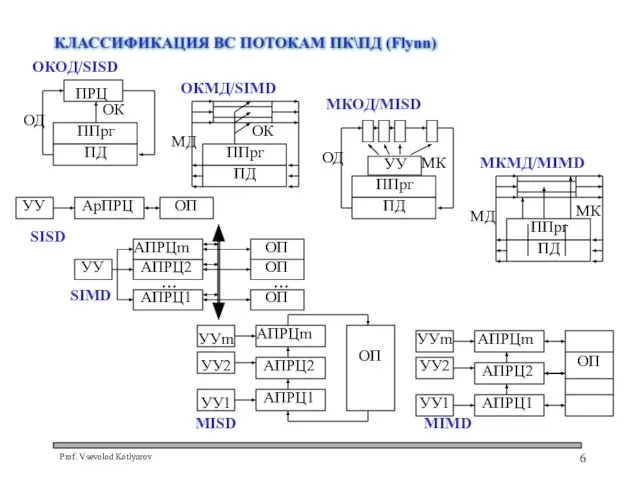
КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
Слайд 7КЛАССЫ КЛАССИФИКАЦИИ ПО ПОТОКАМ
SISD – фон-Неймановская архитектура: каждая команда арифметической обработки инициирует
КЛАССЫ КЛАССИФИКАЦИИ ПО ПОТОКАМ
SISD – фон-Неймановская архитектура: каждая команда арифметической обработки инициирует

Слайд 8КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
Time
е (ai*bi)
i=1..4
КЛАССИФИКАЦИЯ ВС ПОТОКАМ ПК\ПД (Flynn)
Time
е (ai*bi)
i=1..4
Слайд 9 КЛАССИФИКАЦИЯ ШОРА
КЛАССИФИКАЦИЯ ШОРА
Слайд 10КЛАССЫ КЛАССИФИКАЦИИ ШОРА
I – обычная ВМ с последовательной обработкой слов и параллельной
КЛАССЫ КЛАССИФИКАЦИИ ШОРА
I – обычная ВМ с последовательной обработкой слов и параллельной

Слайд 11 КЛАССИФИКАЦИЯ ШОРА
КЛАССИФИКАЦИЯ ШОРА
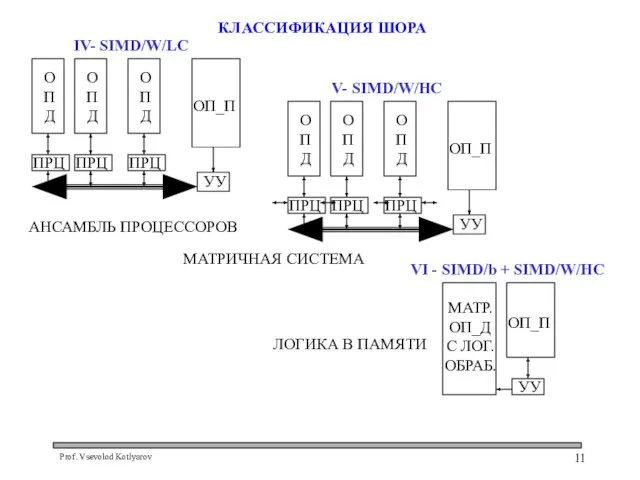
Слайд 12КЛАССЫ КЛАССИФИКАЦИИ ШОРА
IV – ансамбль ПРЦ получается путем интеграции модулей машины I
КЛАССЫ КЛАССИФИКАЦИИ ШОРА
IV – ансамбль ПРЦ получается путем интеграции модулей машины I

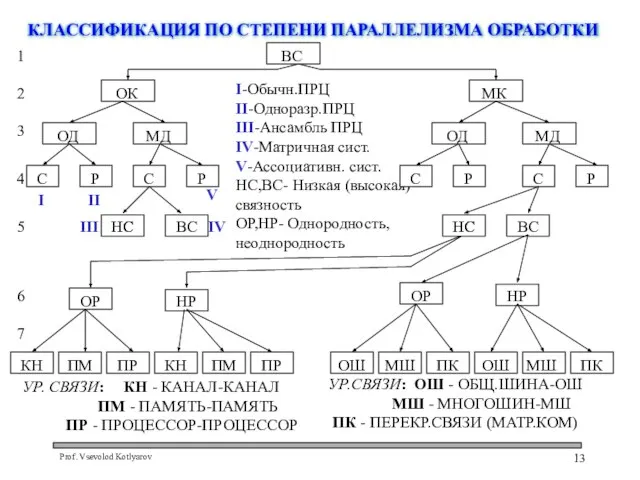
Слайд 13КЛАССИФИКАЦИЯ ПО СТЕПЕНИ ПАРАЛЛЕЛИЗМА ОБРАБОТКИ
1
2
3
4
5
6
7
I-Обычн.ПРЦ
II-Одноразр.ПРЦ
III-Ансамбль ПРЦ
IV-Матричная сист.
V-Ассоциативн. сист.
НС,ВС- Низкая (высокая)
связность
ОР,НР- Однородность,
неоднородность
КЛАССИФИКАЦИЯ ПО СТЕПЕНИ ПАРАЛЛЕЛИЗМА ОБРАБОТКИ
1
2
3
4
5
6
7
I-Обычн.ПРЦ II-Одноразр.ПРЦ III-Ансамбль ПРЦ IV-Матричная сист. V-Ассоциативн. сист. НС,ВС- Низкая (высокая) связность ОР,НР- Однородность, неоднородность
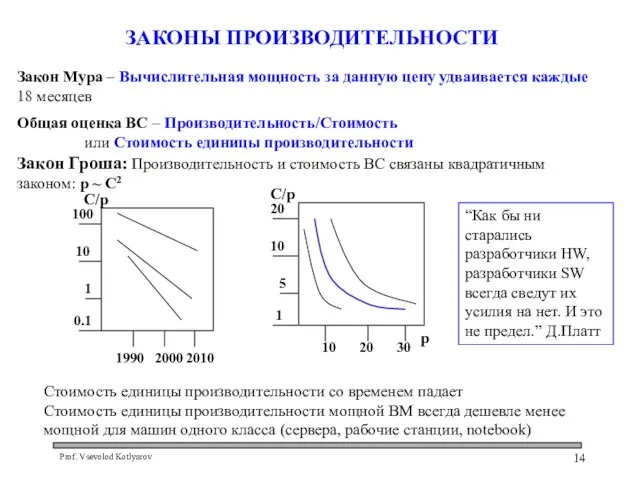
Слайд 14Закон Гроша: Производительность и стоимость ВС связаны квадратичным законом: p ~ C2
C/p
1990
2000
Закон
Закон Гроша: Производительность и стоимость ВС связаны квадратичным законом: p ~ C2
C/p
1990
2000
Закон
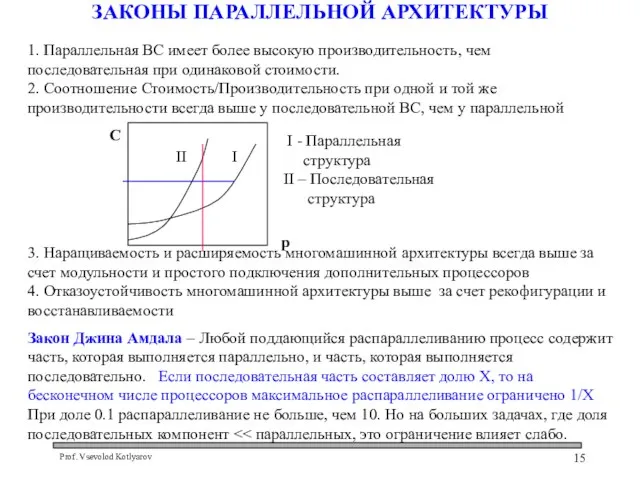
Слайд 15ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ
1. Параллельная ВС имеет более высокую производительность, чем последовательная при
ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ
1. Параллельная ВС имеет более высокую производительность, чем последовательная при
Слайд 16ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ
Закон Джина Амдала в более точной формулировке:
P=N/(X*N+1-X),
где X – последовательная
ЗАКОНЫ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРЫ
Закон Джина Амдала в более точной формулировке:
P=N/(X*N+1-X),
где X – последовательная

Слайд 17 КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
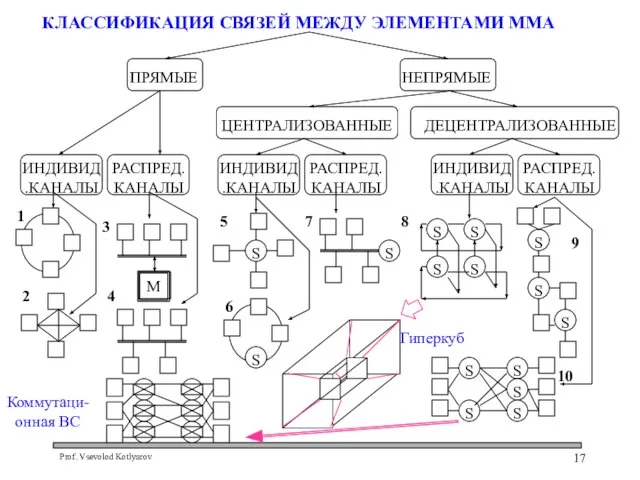
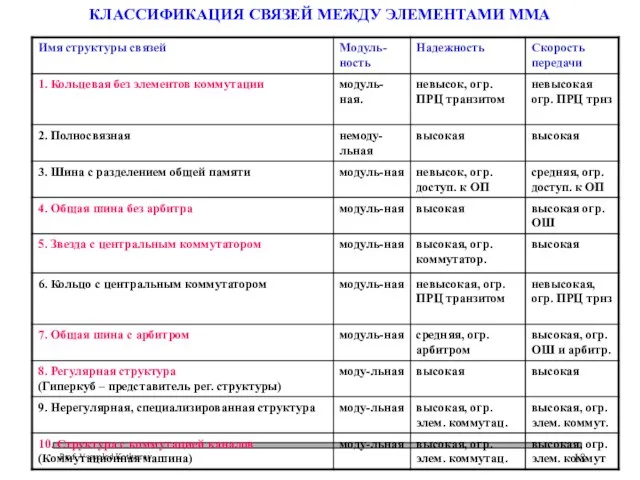
Слайд 18КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
КЛАССИФИКАЦИЯ СВЯЗЕЙ МЕЖДУ ЭЛЕМЕНТАМИ ММА
Слайд 19 ЧТО ПОСЛЕ СУПЕРСКАЛЯРНОЙ АРХИТЕКТУРЫ
Суперскалярная архитектура обеспечивает параллелизм для традиционных
последовательностей операций. Как
ЧТО ПОСЛЕ СУПЕРСКАЛЯРНОЙ АРХИТЕКТУРЫ
Суперскалярная архитектура обеспечивает параллелизм для традиционных последовательностей операций. Как
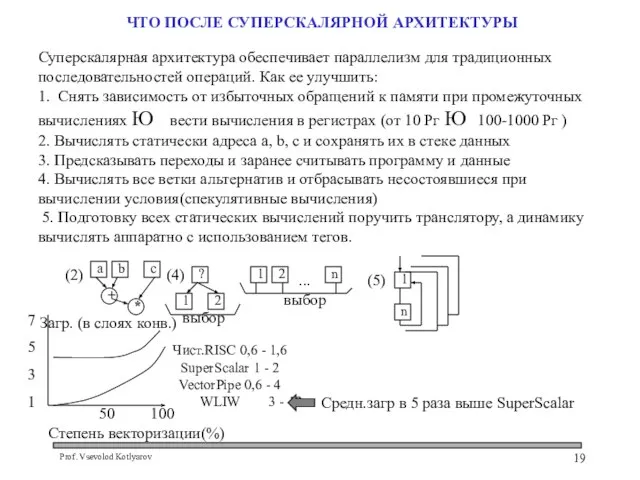
 Unit Testing
Unit Testing «Формирование человечности как социального капитала подрастающего поколения России»Школа – лаборатория как модель инновационн
«Формирование человечности как социального капитала подрастающего поколения России»Школа – лаборатория как модель инновационн Добро пожаловать в Венгрию
Добро пожаловать в Венгрию Имбирные пряники
Имбирные пряники Спортивная игра Баскетбол
Спортивная игра Баскетбол Япония (7 класс)
Япония (7 класс) Вскрытие шахтного поля. Основы горного дела. Лекция 4
Вскрытие шахтного поля. Основы горного дела. Лекция 4 Презентация на тему Методы обучения
Презентация на тему Методы обучения СИЛЬНЫЙ БИЗНЕС НА ПРОЧНОЙ ОСНОВЕ 2011. 2 ИНДУСТРИАЛЬНЫЙ ПАРК ТЕРМИНОЛОГИЯ 2 Индустриальный парк это специально организованная для ра
СИЛЬНЫЙ БИЗНЕС НА ПРОЧНОЙ ОСНОВЕ 2011. 2 ИНДУСТРИАЛЬНЫЙ ПАРК ТЕРМИНОЛОГИЯ 2 Индустриальный парк это специально организованная для ра Apostel Paulus/ Paulus von Tarsus
Apostel Paulus/ Paulus von Tarsus Биохимические основы созревания мяса
Биохимические основы созревания мяса Роль факультатива в формировании языковой компетенции учащихся Факультатив в 7 классе «По странам и континентам. Достопримечател
Роль факультатива в формировании языковой компетенции учащихся Факультатив в 7 классе «По странам и континентам. Достопримечател Джон Китс
Джон Китс simple-present-tense-warmup-powerpoint-_ver_2
simple-present-tense-warmup-powerpoint-_ver_2 Величины
Величины Дезинфицирующее средство СаБиДез - щит от вирусов, бактерий и микробов
Дезинфицирующее средство СаБиДез - щит от вирусов, бактерий и микробов Интернет-УниверситетИнформационных Технологийwww.intuit.ru
Интернет-УниверситетИнформационных Технологийwww.intuit.ru Метод фундаментального проектирования Мэтчетта
Метод фундаментального проектирования Мэтчетта Задачи
Задачи Валентность и степень окисления 8 класс
Валентность и степень окисления 8 класс Электромонтажник электрических сетей и электрооборудования
Электромонтажник электрических сетей и электрооборудования Старшая Эдда. Песни о богах
Старшая Эдда. Песни о богах КП новогодние подарки
КП новогодние подарки Предпосылки разработки закона об учете древесины
Предпосылки разработки закона об учете древесины Утонем?
Утонем? Презентация продуктов инновационной деятельности МИП «Служба примирения как инновационный метод работы по профилактике правона
Презентация продуктов инновационной деятельности МИП «Служба примирения как инновационный метод работы по профилактике правона Формирование репродуктивного здоровья девочки. Основы полового воспитания.Психогигиена полового воспитания.
Формирование репродуктивного здоровья девочки. Основы полового воспитания.Психогигиена полового воспитания. What is the link
What is the link