- АВТОМАТИЗАЦИЯ ПОСТРОЕНИЯ АНГЛО-РУССКОГО WORDNET

Содержание
- 2. Организация WordNet WordNet – лексико-семантическая база данных, включающая: основную лексику языка (существительные, глаголы, прилагательные и наречия
- 3. Princeton WordNet 2.0.
- 4. Почему WordNet ? Наиболее полно отражает лексику английского и др. языков. Число входов (синсетов/слов) > 180
- 5. Проекты WordNet Английский Датский Испанский Итальянский Немецкий Французский Чешский Эстонский Греческий Болгарский Турецкий Румынский Сербский Индийский
- 6. Межъязыковой индекс ILI – Inter-lingual-index
- 7. WordNet русского языка Проект филологического факультета, кафедра компьютерной лингвистики СПбГУ http://www.phil.pu.ru/depts/12/RN/bibliography_ru.shtml http://www.kiberry.ru:8085/index.jsp Проект “УИС Россия” http://www.cir.ru/
- 8. Проект “Russian WordNet” 164 099 лемм и их парадигмы, более 3,5 млн. словоформ 202 866 синсетов
- 9. Основные этапы «Russian WordNet»
- 10. Особенности перевода WordNet В общем случае отображение L1->L2 невыполнимо, поскольку: - для некоторого слова WL1 может
- 11. Google сегодня Поисковый индекс, включающий порядка ~10 миллиардов документов, в т.ч. на русском языке (сколько?) Свободно
- 12. Яndex сегодня В поиске Яндекса сегодня: - уникальных серверов: 2 100 646, - уникальных документов: 727
- 13. Определение «семантического расстояния» между словами Пусть x – слово, w – страница (документ), проиндексированный поисковой машиной
- 14. Определение «семантического расстояния» между словами Условные вероятности появления слов в коллекции документов. Эти вероятности характеризуют зависимость,
- 15. Определение «семантического расстояния» между словами Normalized Google distance (NGD): Функция не определена для f(x)=f(y)=0 NGD=∞, при
- 16. Наши ресурсы New Oxford Dictionary (SGML-формат, по лицензии на использование в исследовательских целях) Более 180 тыс.
- 17. Автоматизированное построение ILI-индекса. Основные этапы. Подготовительный этап Построение частотных словарей для: 153 235 лемм Princeton WordNet
- 18. Автоматизированное построение ILI-индекса. Основные этапы. Подготовительный этап
- 19. Автоматизированное построение ILI-индекса. Основные этапы. Построение ILI-индекса Обход дерева гипонимии (затем – меронимии) PWN «в ширину»
- 20. Автоматизированное построение ILI-индекса. Перевод синсетов PWN. Вариант 1 Синсет PWN состоит более чем из 1 слова,
- 21. Демонстрация алгоритма построения ILI с использованием Google API. Вариант 1
- 22. Демонстрация алгоритма построения ILI с использованием Google API
- 23. Демонстрация алгоритма построения ILI с использованием Google API
- 24. Демонстрация алгоритма построения ILI с использованием Google API [carriage, equipage, rig] => [экипаж, карета, упряжка]
- 25. Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2 Синсет PWN состоит из 1 леммы
- 26. Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
- 27. Определяется гипероним синсета PWN. Например, для синсета [work] - activity directed toward making or doing something;
- 28. Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2 Для [work] в англо-русском словаре определены
- 29. Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2 [work] => {служба, работа}, {труд} Из
- 30. Статистика Russian WordNet Лемм: Синсетов:
- 32. Скачать презентацию
Слайд 2Организация WordNet
WordNet – лексико-семантическая база данных, включающая:
основную лексику языка (существительные,
Организация WordNet
WordNet – лексико-семантическая база данных, включающая:
основную лексику языка (существительные,

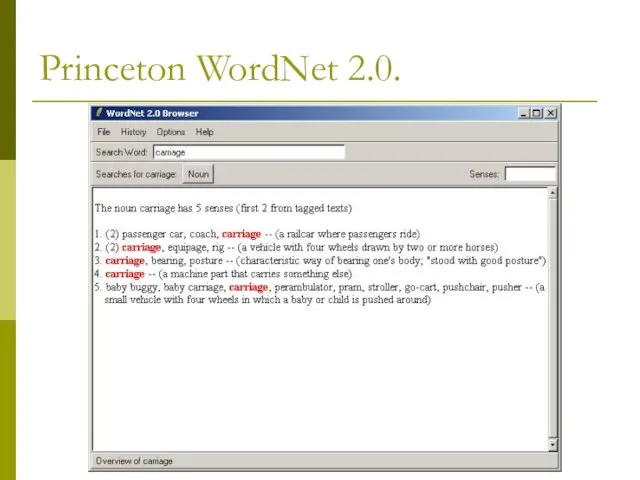
Слайд 3Princeton WordNet 2.0.
Princeton WordNet 2.0.
Слайд 4Почему WordNet ?
Наиболее полно отражает лексику английского и др. языков.
Число входов (синсетов/слов)
Почему WordNet ?
Наиболее полно отражает лексику английского и др. языков. Число входов (синсетов/слов)

Слайд 5Проекты WordNet
Английский
Датский
Испанский
Итальянский
Немецкий
Французский
Чешский
Эстонский
Греческий
Болгарский
Турецкий
Румынский
Сербский
Индийский
Китайский
Японский
GWA – Global WordNet Association (2001 г.)
Проекты WordNet
Английский
Датский
Испанский
Итальянский
Немецкий
Французский
Чешский
Эстонский
Греческий
Болгарский
Турецкий
Румынский
Сербский
Индийский
Китайский
Японский
GWA – Global WordNet Association (2001 г.)
Слайд 6Межъязыковой индекс
ILI – Inter-lingual-index
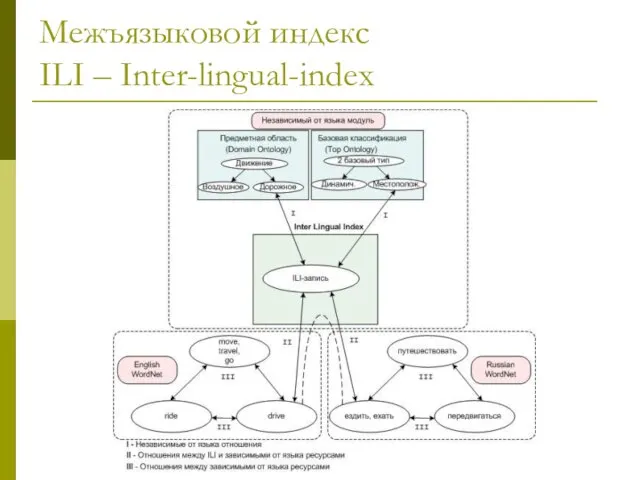
Межъязыковой индекс
ILI – Inter-lingual-index
Слайд 7WordNet русского языка
Проект филологического факультета, кафедра компьютерной лингвистики СПбГУ
http://www.phil.pu.ru/depts/12/RN/bibliography_ru.shtml
http://www.kiberry.ru:8085/index.jsp
Проект
WordNet русского языка
Проект филологического факультета, кафедра компьютерной лингвистики СПбГУ
http://www.phil.pu.ru/depts/12/RN/bibliography_ru.shtml
http://www.kiberry.ru:8085/index.jsp
Проект

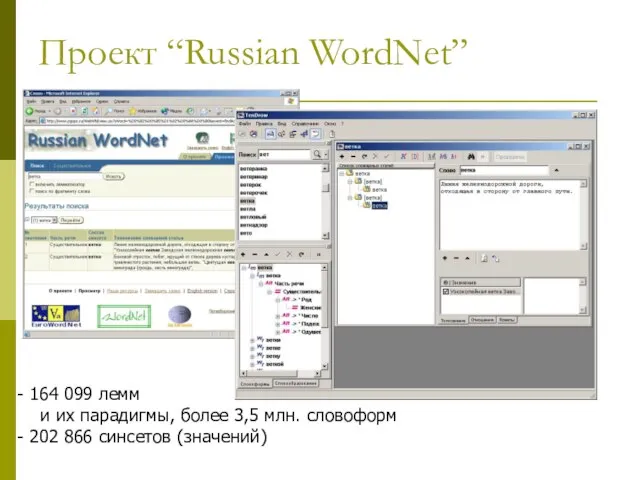
Слайд 8Проект “Russian WordNet”
164 099 лемм
и их парадигмы, более 3,5 млн.
Проект “Russian WordNet”
164 099 лемм
и их парадигмы, более 3,5 млн.
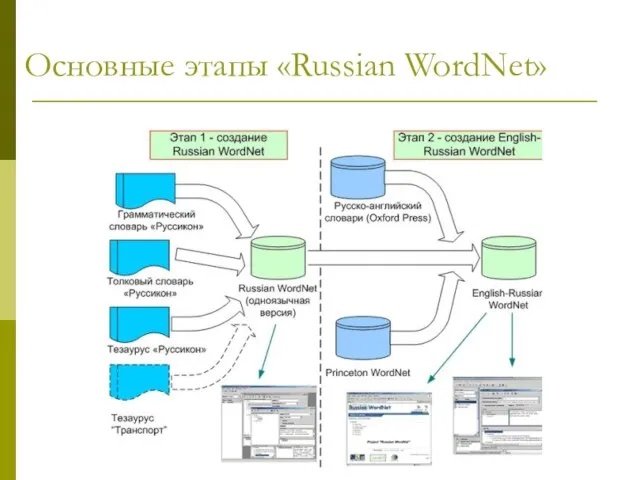
Слайд 9Основные этапы «Russian WordNet»
Основные этапы «Russian WordNet»
Слайд 10
Особенности перевода WordNet
В общем случае отображение L1->L2 невыполнимо, поскольку:
- для
Особенности перевода WordNet
В общем случае отображение L1->L2 невыполнимо, поскольку:
- для

Слайд 11Google сегодня
Поисковый индекс, включающий порядка ~10 миллиардов документов, в т.ч. на русском
Google сегодня
Поисковый индекс, включающий порядка ~10 миллиардов документов, в т.ч. на русском

Слайд 12Яndex сегодня
В поиске Яндекса сегодня: - уникальных серверов: 2 100 646, -
Яndex сегодня
В поиске Яндекса сегодня: - уникальных серверов: 2 100 646, -

Слайд 13Определение «семантического расстояния» между словами
Пусть x – слово, w – страница (документ),
Определение «семантического расстояния» между словами
Пусть x – слово, w – страница (документ),

Слайд 14Определение «семантического расстояния» между словами
Условные вероятности появления
слов в коллекции документов.
Эти вероятности характеризуют
Определение «семантического расстояния» между словами
Условные вероятности появления
слов в коллекции документов.
Эти вероятности характеризуют

Слайд 15Определение «семантического расстояния» между словами
Normalized Google distance (NGD):
Функция не определена для
Определение «семантического расстояния» между словами
Normalized Google distance (NGD):
Функция не определена для

Слайд 16Наши ресурсы
New Oxford Dictionary (SGML-формат, по лицензии на использование в исследовательских целях)
Наши ресурсы
New Oxford Dictionary (SGML-формат, по лицензии на использование в исследовательских целях)

Слайд 17Автоматизированное построение ILI-индекса. Основные этапы.
Подготовительный этап
Построение частотных словарей для:
153 235 лемм Princeton
Автоматизированное построение ILI-индекса. Основные этапы.
Подготовительный этап
Построение частотных словарей для:
153 235 лемм Princeton

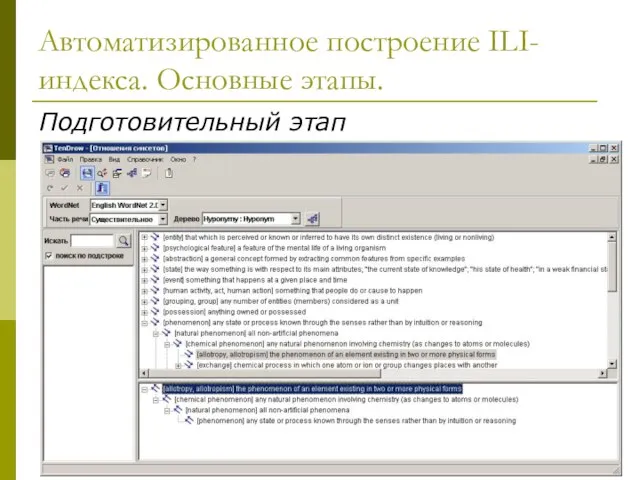
Слайд 18Автоматизированное построение ILI-индекса. Основные этапы.
Подготовительный этап
Автоматизированное построение ILI-индекса. Основные этапы.
Подготовительный этап
Слайд 19Автоматизированное построение ILI-индекса. Основные этапы.
Построение ILI-индекса
Обход дерева гипонимии (затем – меронимии) PWN
Автоматизированное построение ILI-индекса. Основные этапы.
Построение ILI-индекса
Обход дерева гипонимии (затем – меронимии) PWN

Слайд 20Автоматизированное построение ILI-индекса. Перевод синсетов PWN.
Вариант 1
Синсет PWN состоит более чем из
Автоматизированное построение ILI-индекса. Перевод синсетов PWN.
Вариант 1
Синсет PWN состоит более чем из

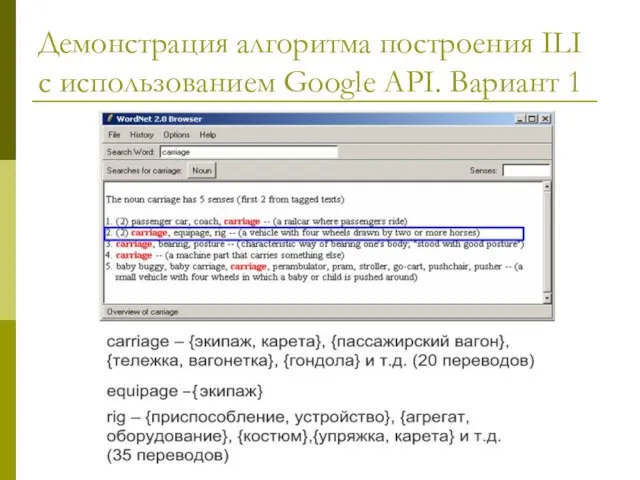
Слайд 21Демонстрация алгоритма построения ILI с использованием Google API. Вариант 1
Демонстрация алгоритма построения ILI с использованием Google API. Вариант 1
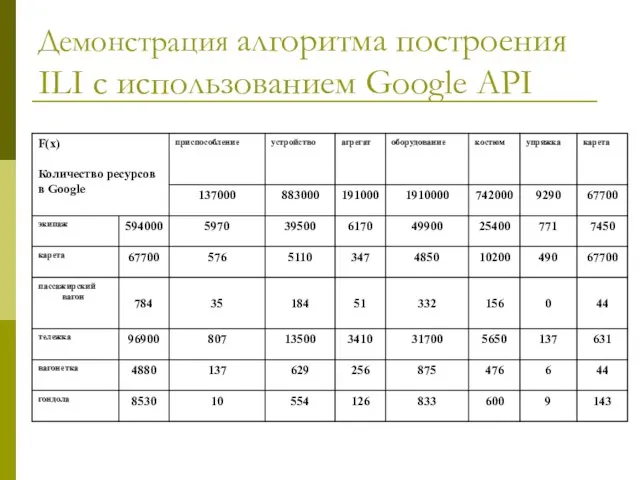
Слайд 22Демонстрация алгоритма построения ILI с использованием Google API
Демонстрация алгоритма построения ILI с использованием Google API
Слайд 23Демонстрация алгоритма построения ILI с использованием Google API
Демонстрация алгоритма построения ILI с использованием Google API
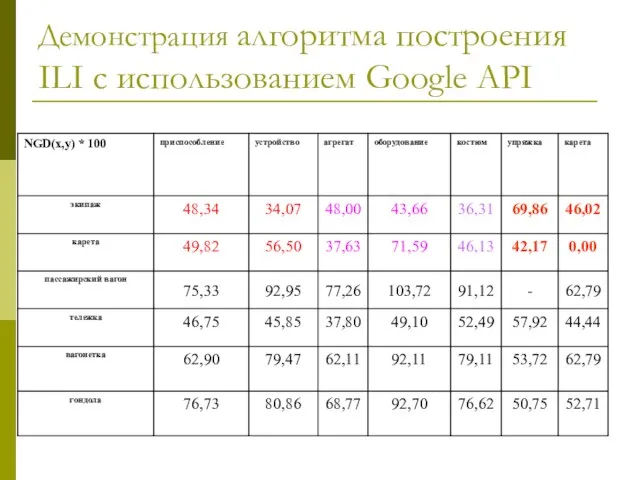
Слайд 24Демонстрация алгоритма построения ILI с использованием Google API
[carriage, equipage, rig] => [экипаж,
Демонстрация алгоритма построения ILI с использованием Google API
[carriage, equipage, rig] => [экипаж,
![Демонстрация алгоритма построения ILI с использованием Google API [carriage, equipage, rig] => [экипаж, карета, упряжка]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/460431/slide-23.jpg)
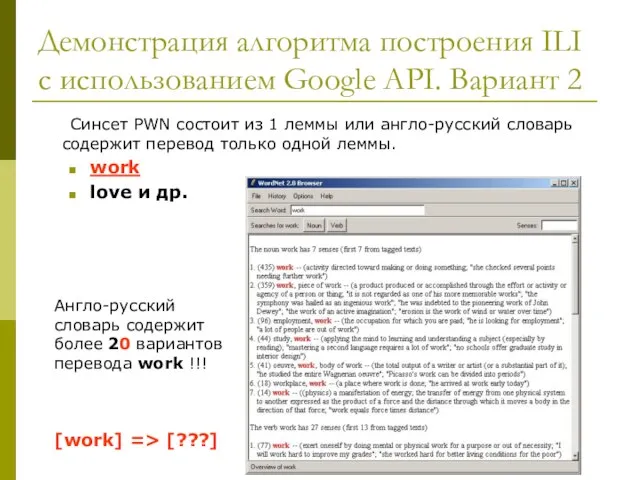
Слайд 25Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
Синсет PWN состоит
Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
Синсет PWN состоит
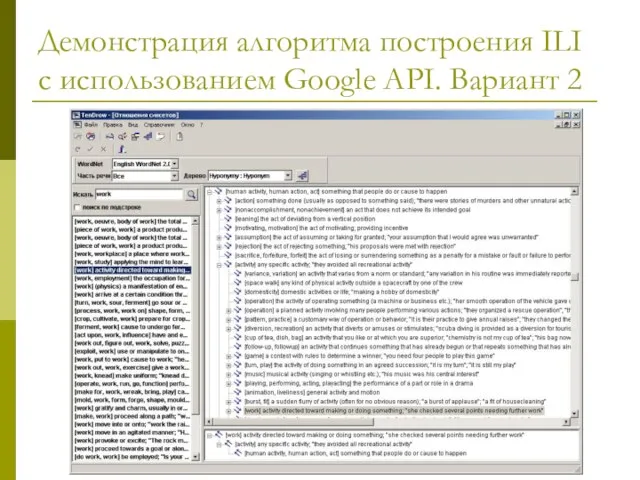
Слайд 26Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
Слайд 27Определяется гипероним синсета PWN. Например, для синсета
[work] - activity directed toward
Определяется гипероним синсета PWN. Например, для синсета
[work] - activity directed toward
![Определяется гипероним синсета PWN. Например, для синсета [work] - activity directed toward](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/460431/slide-26.jpg)
Слайд 28Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
Для [work] в
Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
Для [work] в
![Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2 Для [work]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/460431/slide-27.jpg)
Слайд 29Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
[work] => {служба,
Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2
[work] => {служба,
![Демонстрация алгоритма построения ILI с использованием Google API. Вариант 2 [work] =>](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/460431/slide-28.jpg)
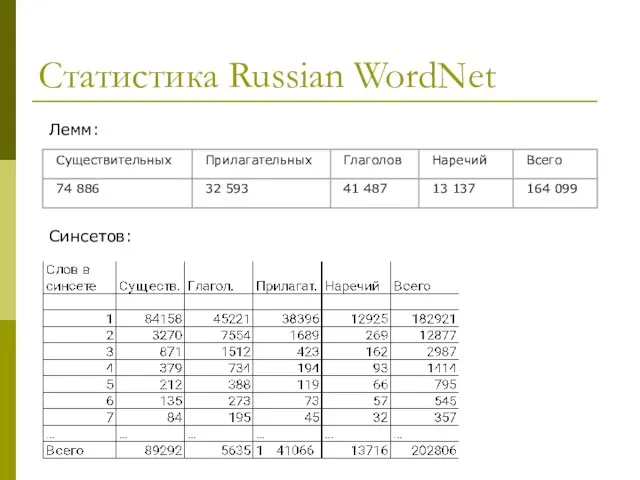
Слайд 30Статистика Russian WordNet
Лемм:
Синсетов:
Статистика Russian WordNet
Лемм:
Синсетов:
 Краткая история профилактики передозировок
Краткая история профилактики передозировок Маркетинг Marketing
Маркетинг Marketing Зайка моя. Драматическая комедия
Зайка моя. Драматическая комедия Презентация на тему жанр рецензии
Презентация на тему жанр рецензии  Презентация на тему Того Тоголезская Республика
Презентация на тему Того Тоголезская Республика Лучше один раз увидеть?
Лучше один раз увидеть? Энергия атома
Энергия атома Друг Нечаева Ивана, Вячеслав Пирогов
Друг Нечаева Ивана, Вячеслав Пирогов Планирование журналистского расследования:
Планирование журналистского расследования: Презентация на тему Горы Южной Сибири
Презентация на тему Горы Южной Сибири Модернизация транспортёра Накопителя участка отделки катанки прокатного цеха с последующей модернизацией палет всего участка
Модернизация транспортёра Накопителя участка отделки катанки прокатного цеха с последующей модернизацией палет всего участка Презентация компании
Презентация компании «ПОИСК»
«ПОИСК» Презентация на тему Тульский пряник
Презентация на тему Тульский пряник Диванная подушка "Братец Лис"
Диванная подушка "Братец Лис" Сокровища Земли под охраной человечества
Сокровища Земли под охраной человечества Основные группы антигипертензивных средств
Основные группы антигипертензивных средств Рекомендация к электронному ресурсу МГУ
Рекомендация к электронному ресурсу МГУ Комиссионный осмотр обустройств станции
Комиссионный осмотр обустройств станции Все начиналось в XVIII веке
Все начиналось в XVIII веке Финансовый конструктор бизнеса: творчески и легко
Финансовый конструктор бизнеса: творчески и легко Презентация на тему Классификация углеводов
Презентация на тему Классификация углеводов  Психологическая помощь подросткам и их родителям в период подготовки к экзаменам
Психологическая помощь подросткам и их родителям в период подготовки к экзаменам Автоматизация процесса сбора информации
Автоматизация процесса сбора информации Алмазы 3 класс
Алмазы 3 класс Оценка эффективности применения прощенной формы ведения бухгалтерского учета на предприятиях малого бизнеса
Оценка эффективности применения прощенной формы ведения бухгалтерского учета на предприятиях малого бизнеса Маленькие радости жизни
Маленькие радости жизни Наука. Образование.
Наука. Образование.