- данные

Содержание
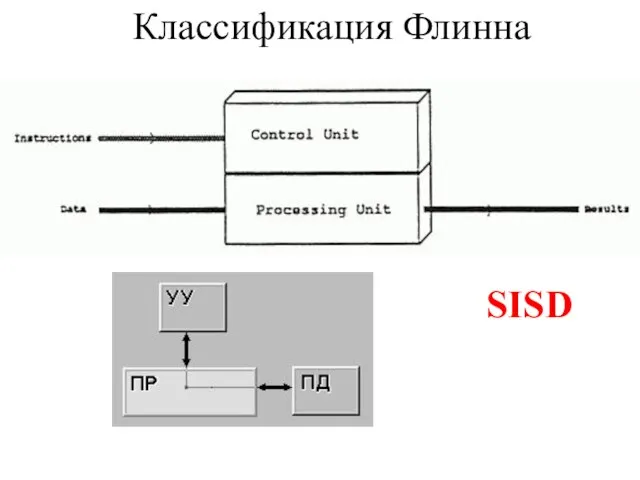
- 2. Классификация Флинна SISD
- 3. SIMD
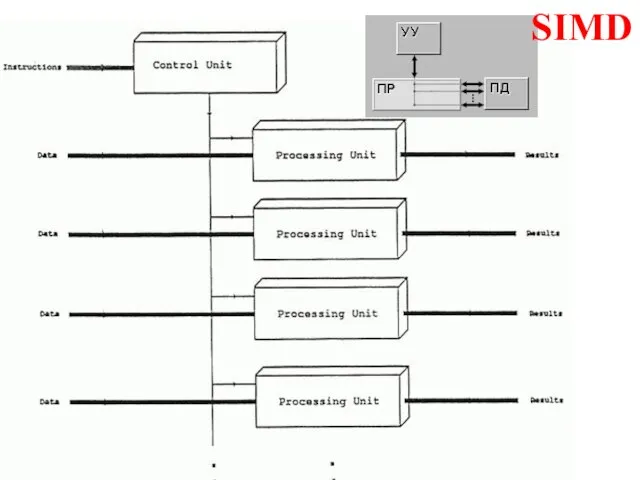
- 4. *Examples: Cray 1, NEC SX-2 Fujitsu VP, Hitachi S820
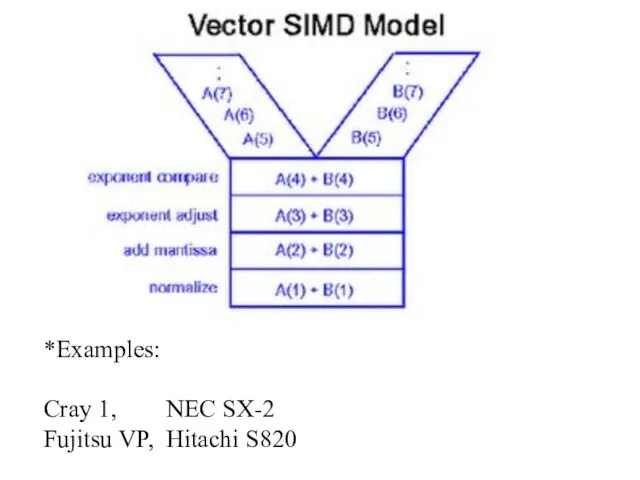
- 5. * Examples: Connection Machine CM-2 Maspar MP-1, MP-2
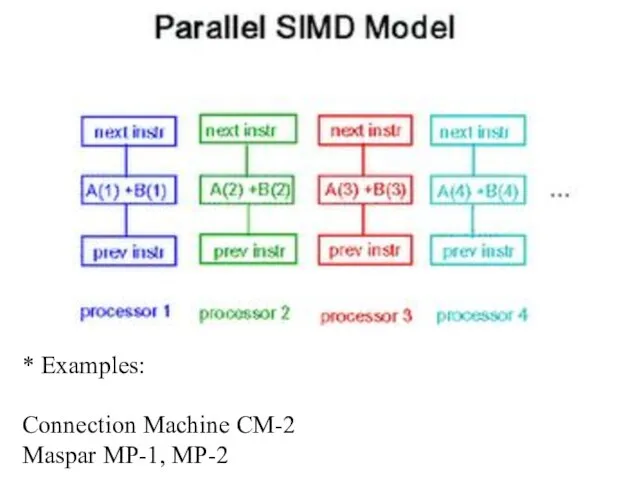
- 6. MISD
- 7. MIMD
- 9. Дополнения Ванга и Бриггса к классификации Флинна Класс SISD разбивается на два подкласса: архитектуры с единственным
- 10. Дополнения Ванга и Бриггса к классификации Флинна В класс SIMD также вводится два подкласса: архитектуры с
- 11. Дополнения Ванга и Бриггса к классификации Флинна В классе MIMD авторы различают вычислительные системы со слабой
- 12. Классификация Хокни
- 13. Классификация Хокни Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем
- 14. Классификация Хокни Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых вся память распределена
- 15. Классификация Хокни При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память,
- 17. Предлагается рассматривать архитектуру любого компьютера, как абстрактную структуру, состоящую из четырех компонент: процессор команд (IP -
- 18. Функции процессора команд во многом схожи с функциями устройств управления последовательных машин и, согласно Д.Скилликорну, сводятся
- 19. Функции процессора данных делают его во многом похожим на арифметическое устройство традиционных процессоров: DP получает от
- 20. В терминах таким образом определенных основных частей компьютера структуру традиционной фон-неймановской архитектуры можно представить в следующем
- 21. Для описания параллельных вычислительных систем автор зафиксировал четыре типа переключателей, без какой-либо явной связи с типом
- 22. Примеров подобных переключателей можно привести очень много. Так, все матричные процессоры имеют переключатель типа 1-n для
- 23. Классификация Д.Скилликорна состоит из двух уровней. На первом уровне она проводится на основе восьми характеристик: количество
- 24. Рассмотрим упомянутый выше компьютер Connection Machine 2. В терминах данных характеристик его можно описать: IP IM
- 25. Для сильно связанных мультипроцессоров (BBN Butterfly, C.mmp) ситуация иная. Такие системы состоят из множества процессоров, соединенных
- 26. Используя введенные характеристики и предполагая, что рассмотрение количественных характеристик можно ограничить только тремя возможными вариантами значений:
- 27. На втором уровне классификации Д.Скилликорн просто уточняет описание, сделанное на первом уровне, добавляя возможность конвейерной обработки
- 28. Классификация Дункана Из класса параллельных машин должны быть исключены те, в которых параллелизм заложен лишь на
- 29. Классификация Дункана Классификация должна быть согласованной с классификацией Флинна, показавшей правильность выбора идеи потоков команд и
- 30. Классификация Дункана http://parallel.ru/computers/taxonomy/
- 31. Классификация Базу
- 32. Классификация Базу Конвейерные компьютеры, такие, как IBM 360/91, Amdahl 470/6 и многие современные RISC процессоры, разбивающие
- 33. Классификация Базу Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда можно корректно описать
- 34. Классификация Базу Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из разных групп данной
- 35. Классификация Хендлера http://parallel.ru/computers/taxonomy/ Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения
- 36. Классификация Хендлера http://parallel.ru/computers/taxonomy/ t(C) = (k, d, w)
- 37. t( MINIMA ) = (1,1,1); t( IBM 701 ) = (1,1,36); t( SOLOMON ) = (1,1024,1);
- 38. Классификация Хендлера t= (k×k',d×d',w×w') k - число процессоров (каждый со своим УУ), работающих параллельно k' -
- 39. Классификация Шора Машина I - это вычислительная система, которая содержит устройство управления, арифметико-логическое устройство, память команд
- 40. Классификация Шора Если в машине I осуществлять выборку не по словам, а выборкой содержимого одного разряда
- 41. Классификация Шора Если объединить принципы построения машин I и II, то получим машину III. Эта машина
- 42. Классификация Шора Если в машине I увеличить число пар арифметико-логическое устройство память данных (иногда эту пару
- 43. Классификация Шора Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV, например в виде
- 44. Классификация Шора Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения памяти данных и
- 45. Классификация Шнайдера В 1988 году Л.Шнайдер (L.Snyder) предложил новый подход [16] к описанию архитектур параллельных вычислительных
- 46. Пусть S произвольный поток ссылок. Последовательность адресов потока S, обозначаемая Sa, - это последовательность, чей i-й
- 47. Классификация Шнайдера Каждую пару (I, D) с потоком команд I и потоком данных D будем называть
- 48. Классификация Шнайдера Рассмотрим классическую последовательную машину. Согласно классификации Флинна, она попадает в класс SISD, следовательно |I|
- 49. Классификация Шнайдера Теперь возьмем две машину из класса SIMD Goodyear Aerospace MPP Единственный поток команд означает
- 50. Классификация Шнайдера В ILLIAC IV устройство управления, так же, как и в MPP, рассылает один и
- 51. Классификация Шнайдера Для более четкой классификации Шнайдер вводит три предиката для обозначения значений, которые могут принимать
- 53. Скачать презентацию
Слайд 3SIMD
SIMD
Слайд 4*Examples:
Cray 1, NEC SX-2
Fujitsu VP, Hitachi S820
*Examples:
Cray 1, NEC SX-2
Fujitsu VP, Hitachi S820
Слайд 5* Examples:
Connection Machine CM-2
Maspar MP-1, MP-2
* Examples:
Connection Machine CM-2
Maspar MP-1, MP-2
Слайд 6MISD
MISD
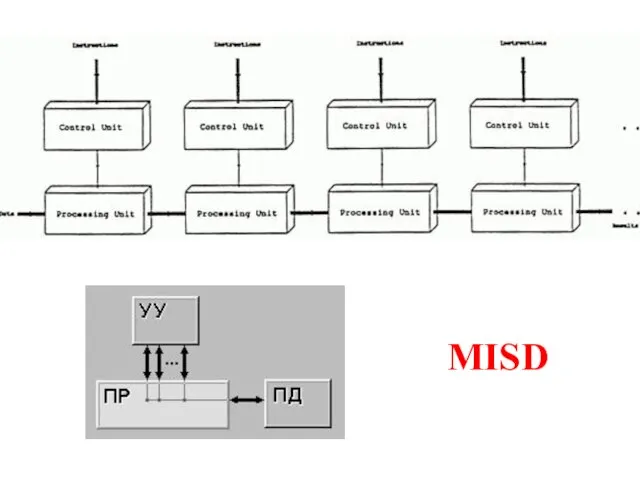
Слайд 7MIMD
MIMD
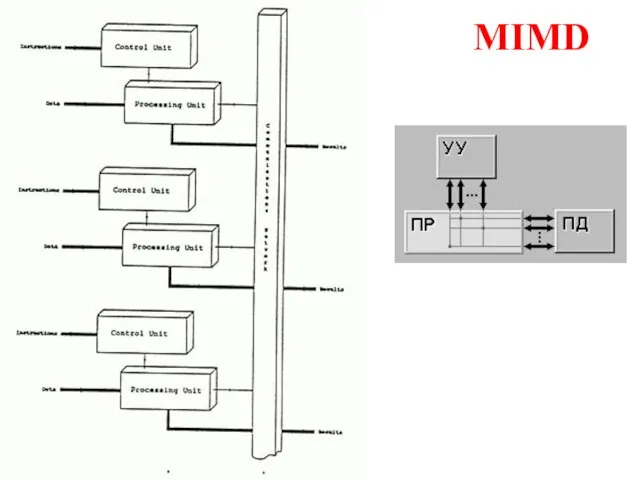

Слайд 9Дополнения Ванга и Бриггса к
классификации Флинна
Класс SISD разбивается на два подкласса:
архитектуры с
Дополнения Ванга и Бриггса к
классификации Флинна
Класс SISD разбивается на два подкласса:
архитектуры с

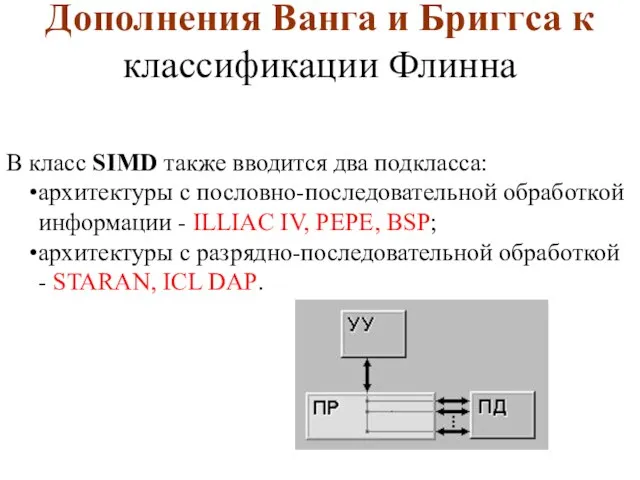
Слайд 10Дополнения Ванга и Бриггса к
классификации Флинна
В класс SIMD также вводится два подкласса:
архитектуры
Дополнения Ванга и Бриггса к
классификации Флинна
В класс SIMD также вводится два подкласса:
архитектуры
Слайд 11Дополнения Ванга и Бриггса к
классификации Флинна
В классе MIMD авторы различают
вычислительные системы со
Дополнения Ванга и Бриггса к
классификации Флинна
В классе MIMD авторы различают
вычислительные системы со

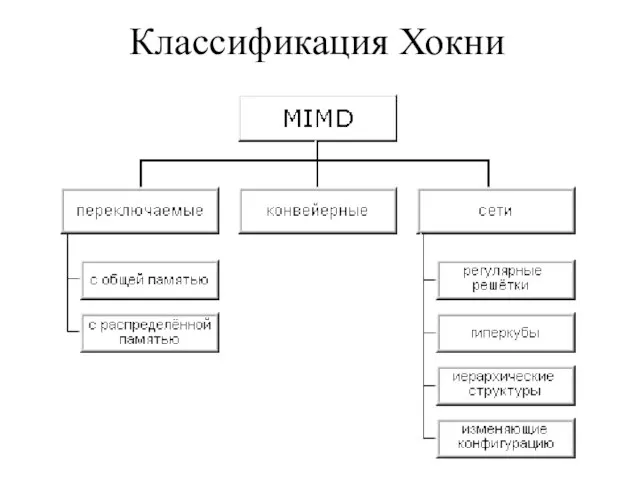
Слайд 12Классификация Хокни
Классификация Хокни
Слайд 13Классификация Хокни
Множественный поток команд может быть обработан двумя способами: либо одним конвейерным
Классификация Хокни
Множественный поток команд может быть обработан двумя способами: либо одним конвейерным

Слайд 14Классификация Хокни
Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых
Классификация Хокни
Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых

Слайд 15Классификация Хокни
При рассмотрении MIMD машин с сетевой структурой считается, что все они
Классификация Хокни
При рассмотрении MIMD машин с сетевой структурой считается, что все они


Слайд 17Предлагается рассматривать архитектуру любого компьютера, как абстрактную структуру, состоящую из четырех компонент:
Предлагается рассматривать архитектуру любого компьютера, как абстрактную структуру, состоящую из четырех компонент:

Слайд 18Функции процессора команд во многом схожи с функциями устройств управления последовательных машин
Функции процессора команд во многом схожи с функциями устройств управления последовательных машин

Слайд 19Функции процессора данных делают его во многом похожим на арифметическое устройство традиционных
Функции процессора данных делают его во многом похожим на арифметическое устройство традиционных

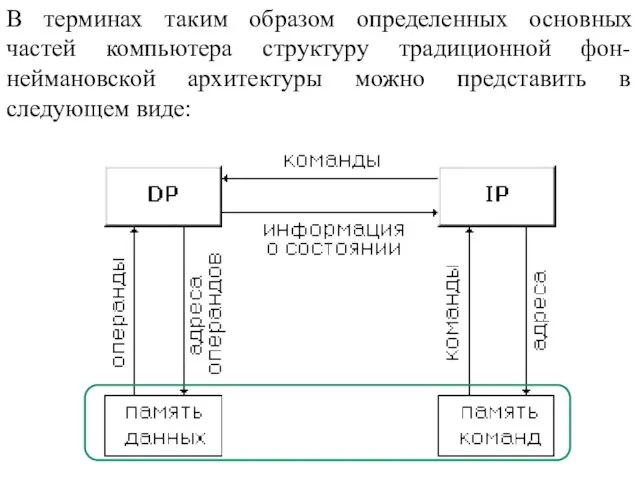
Слайд 20В терминах таким образом определенных основных частей компьютера структуру традиционной фон-неймановской архитектуры
В терминах таким образом определенных основных частей компьютера структуру традиционной фон-неймановской архитектуры
Слайд 21Для описания параллельных вычислительных систем автор зафиксировал четыре типа переключателей, без какой-либо
Для описания параллельных вычислительных систем автор зафиксировал четыре типа переключателей, без какой-либо

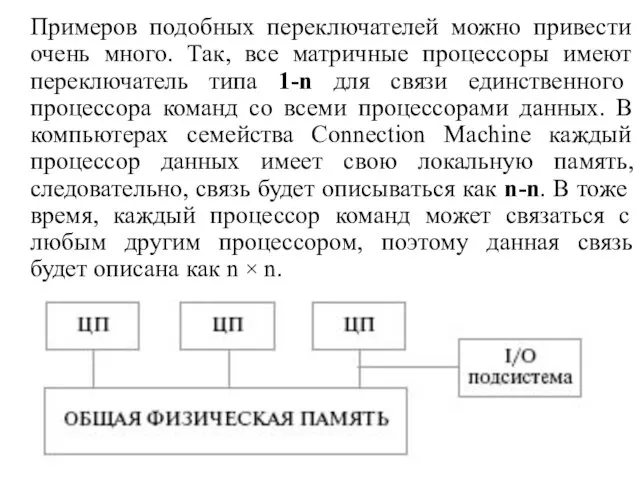
Слайд 22 Примеров подобных переключателей можно привести очень много. Так, все матричные процессоры имеют
Примеров подобных переключателей можно привести очень много. Так, все матричные процессоры имеют
Слайд 23Классификация Д.Скилликорна состоит из двух уровней. На первом уровне она проводится на
Классификация Д.Скилликорна состоит из двух уровней. На первом уровне она проводится на

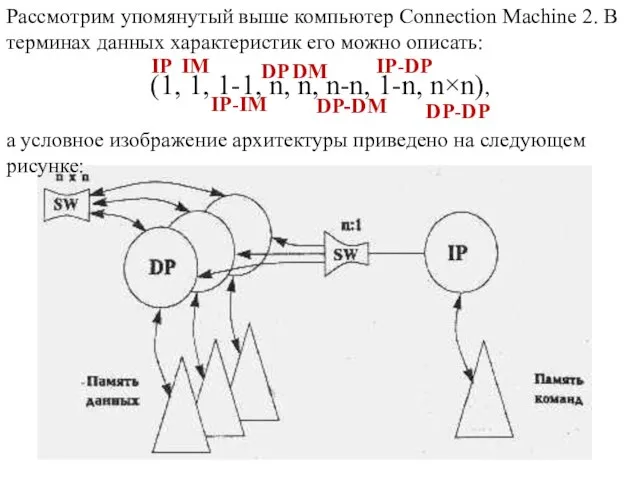
Слайд 24Рассмотрим упомянутый выше компьютер Connection Machine 2. В терминах данных характеристик его
Рассмотрим упомянутый выше компьютер Connection Machine 2. В терминах данных характеристик его
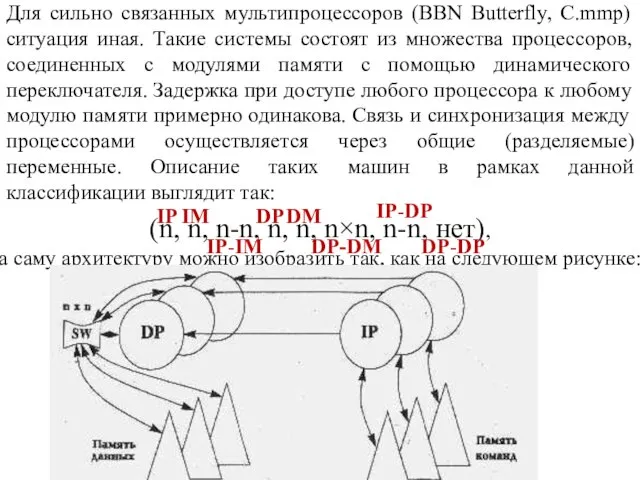
Слайд 25Для сильно связанных мультипроцессоров (BBN Butterfly, C.mmp) ситуация иная. Такие системы состоят
Для сильно связанных мультипроцессоров (BBN Butterfly, C.mmp) ситуация иная. Такие системы состоят
Слайд 26Используя введенные характеристики и предполагая, что рассмотрение количественных характеристик можно ограничить только
Используя введенные характеристики и предполагая, что рассмотрение количественных характеристик можно ограничить только

Слайд 27На втором уровне классификации Д.Скилликорн просто уточняет описание, сделанное на первом уровне,
На втором уровне классификации Д.Скилликорн просто уточняет описание, сделанное на первом уровне,

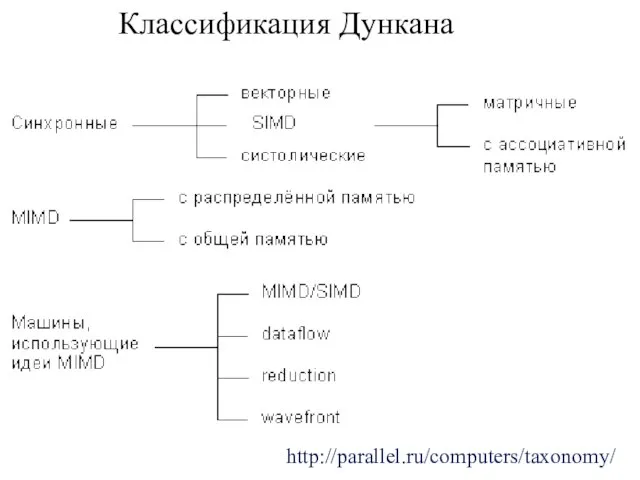
Слайд 28Классификация Дункана
Из класса параллельных машин должны быть исключены те, в которых параллелизм
Классификация Дункана
Из класса параллельных машин должны быть исключены те, в которых параллелизм

Слайд 29Классификация Дункана
Классификация должна быть согласованной с классификацией Флинна, показавшей правильность выбора идеи
Классификация Дункана
Классификация должна быть согласованной с классификацией Флинна, показавшей правильность выбора идеи

Слайд 30Классификация Дункана
http://parallel.ru/computers/taxonomy/
Классификация Дункана
http://parallel.ru/computers/taxonomy/
Слайд 31Классификация Базу
Классификация Базу
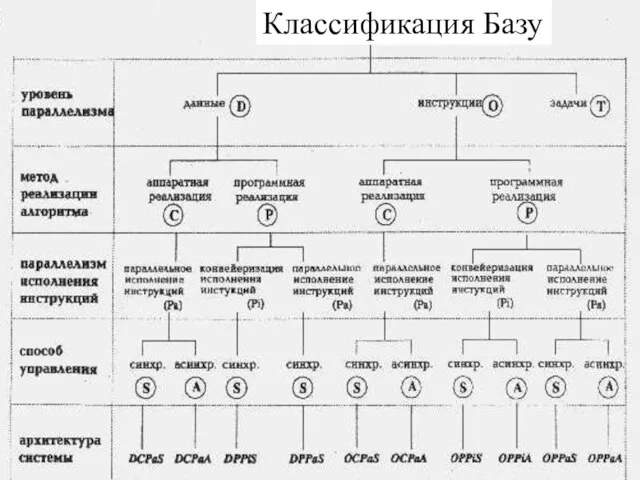
Слайд 32Классификация Базу
Конвейерные компьютеры, такие, как IBM 360/91, Amdahl 470/6 и многие современные
Классификация Базу
Конвейерные компьютеры, такие, как IBM 360/91, Amdahl 470/6 и многие современные

Слайд 33Классификация Базу
Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда
Классификация Базу
Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда

Слайд 34Классификация Базу
Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из
Классификация Базу
Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из

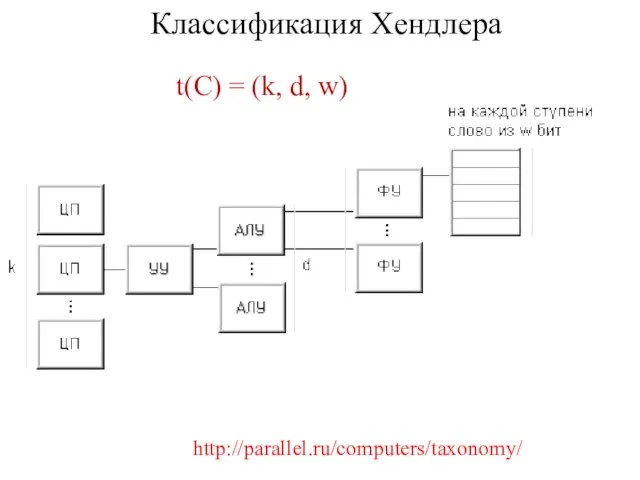
Слайд 35Классификация Хендлера
http://parallel.ru/computers/taxonomy/
Предложенная классификация базируется на различии между тремя уровнями обработки данных в
Классификация Хендлера
http://parallel.ru/computers/taxonomy/
Предложенная классификация базируется на различии между тремя уровнями обработки данных в

Слайд 36Классификация Хендлера
http://parallel.ru/computers/taxonomy/
t(C) = (k, d, w)
Классификация Хендлера
http://parallel.ru/computers/taxonomy/
t(C) = (k, d, w)
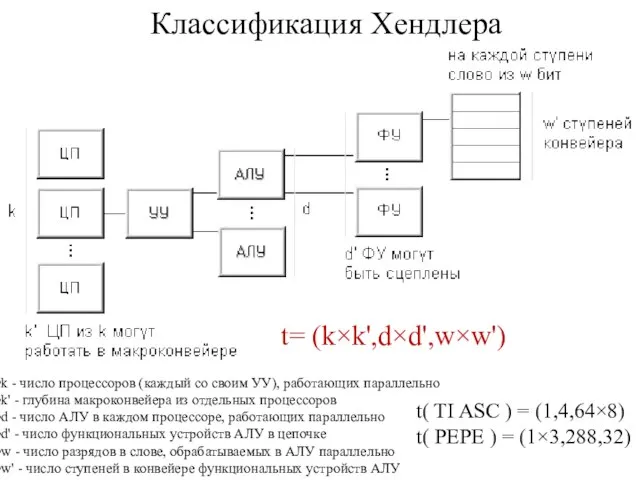
Слайд 37t( MINIMA ) = (1,1,1);
t( IBM 701 ) = (1,1,36);
t( SOLOMON )
t( MINIMA ) = (1,1,1); t( IBM 701 ) = (1,1,36); t( SOLOMON )

Слайд 38Классификация Хендлера
t= (k×k',d×d',w×w')
k - число процессоров (каждый со своим УУ), работающих
Классификация Хендлера
t= (k×k',d×d',w×w')
k - число процессоров (каждый со своим УУ), работающих
Слайд 39Классификация Шора
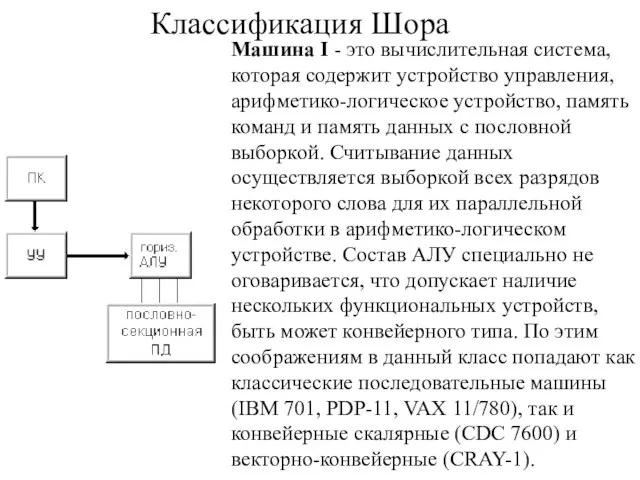
Машина I - это вычислительная система, которая содержит устройство управления, арифметико-логическое
Классификация Шора
Машина I - это вычислительная система, которая содержит устройство управления, арифметико-логическое
Слайд 40Классификация Шора
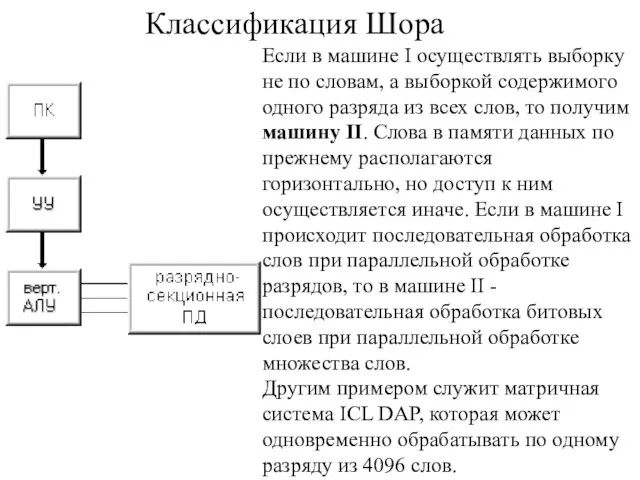
Если в машине I осуществлять выборку не по словам, а выборкой
Классификация Шора
Если в машине I осуществлять выборку не по словам, а выборкой
Слайд 41Классификация Шора
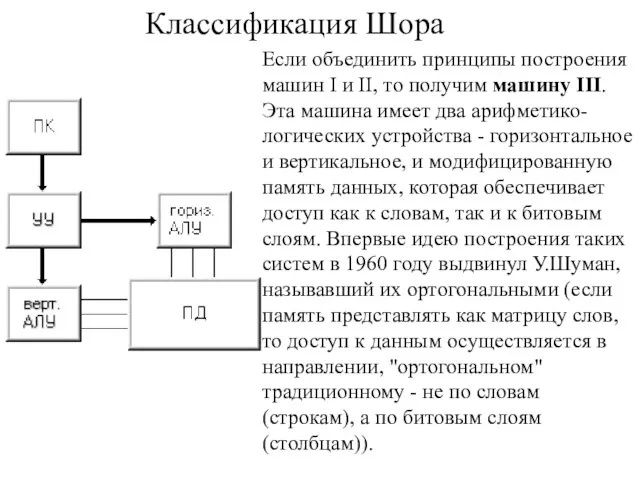
Если объединить принципы построения машин I и II, то получим машину
Классификация Шора
Если объединить принципы построения машин I и II, то получим машину
Слайд 42Классификация Шора
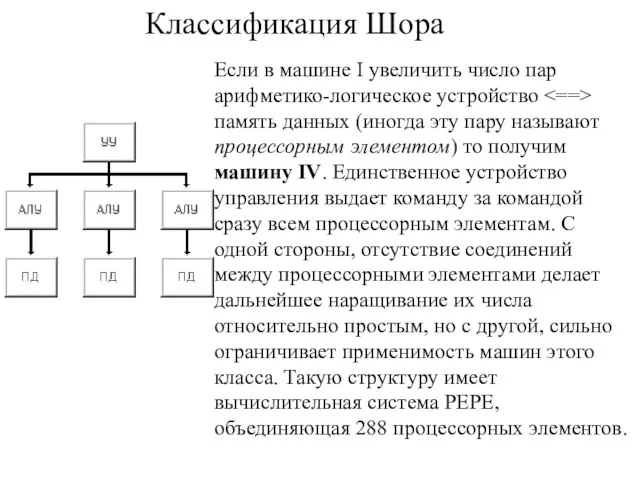
Если в машине I увеличить число пар арифметико-логическое устройство <==> память
Классификация Шора
Если в машине I увеличить число пар арифметико-логическое устройство <==> память
Слайд 43Классификация Шора
Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV,
Классификация Шора
Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV,
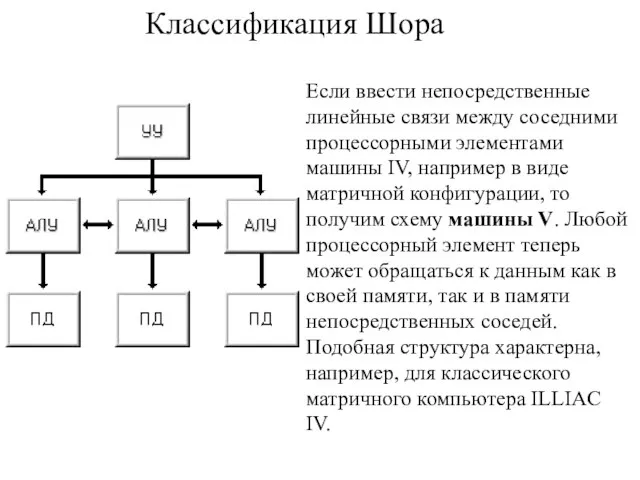
Слайд 44Классификация Шора
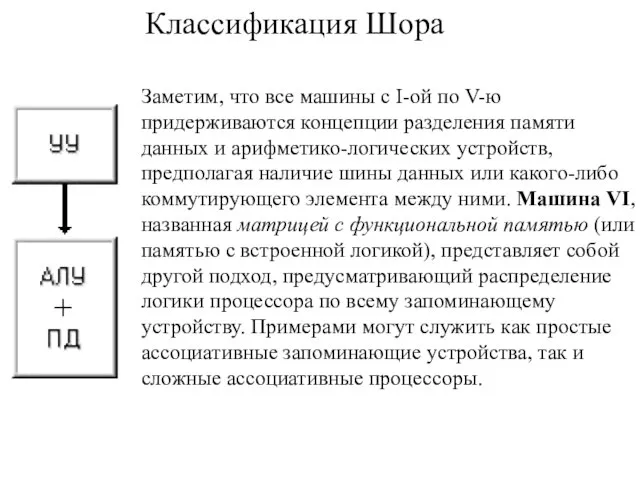
Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения
Классификация Шора
Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения
Слайд 45Классификация Шнайдера
В 1988 году Л.Шнайдер (L.Snyder) предложил новый подход [16] к описанию
Классификация Шнайдера
В 1988 году Л.Шнайдер (L.Snyder) предложил новый подход [16] к описанию
![Классификация Шнайдера В 1988 году Л.Шнайдер (L.Snyder) предложил новый подход [16] к](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/409374/slide-44.jpg)
Слайд 46Пусть S произвольный поток ссылок.
Последовательность адресов потока S, обозначаемая Sa, -
Пусть S произвольный поток ссылок.
Последовательность адресов потока S, обозначаемая Sa, -

Слайд 47Классификация Шнайдера
Каждую пару (I, D) с потоком команд I и потоком данных
Классификация Шнайдера
Каждую пару (I, D) с потоком команд I и потоком данных

Слайд 48Классификация Шнайдера
Рассмотрим классическую последовательную машину. Согласно классификации Флинна, она попадает в класс
Классификация Шнайдера
Рассмотрим классическую последовательную машину. Согласно классификации Флинна, она попадает в класс

Слайд 49Классификация Шнайдера
Теперь возьмем две машину из класса SIMD Goodyear Aerospace MPP Единственный
Классификация Шнайдера
Теперь возьмем две машину из класса SIMD Goodyear Aerospace MPP Единственный

Слайд 50Классификация Шнайдера
В ILLIAC IV устройство управления, так же, как и в MPP,
Классификация Шнайдера
В ILLIAC IV устройство управления, так же, как и в MPP,

Слайд 51Классификация Шнайдера
Для более четкой классификации Шнайдер вводит три предиката для обозначения значений,
Классификация Шнайдера
Для более четкой классификации Шнайдер вводит три предиката для обозначения значений,

 Характеристика детей с ЗПР. Неблагоприятные семейные факторы влияющие на ребенка с ЗПР
Характеристика детей с ЗПР. Неблагоприятные семейные факторы влияющие на ребенка с ЗПР road monitoring 2020
road monitoring 2020 Круги на полях
Круги на полях Основные различия между руководителем по теории «Х» и по теории «Y»
Основные различия между руководителем по теории «Х» и по теории «Y» Средства и методы решения анимационных задачв сети INTERNET
Средства и методы решения анимационных задачв сети INTERNET Презентация на тему ЛАТВИЯ
Презентация на тему ЛАТВИЯ Развитие общества
Развитие общества 18.02.2008 г.
18.02.2008 г. Луг и его обитатели
Луг и его обитатели Стратегия по всем каналам: индивидуальный подход к каждому партнеру
Стратегия по всем каналам: индивидуальный подход к каждому партнеру Пути реализации инклюзивного образования средствами инновационной деятельности
Пути реализации инклюзивного образования средствами инновационной деятельности Документационное обеспечение управления и фукционирование организации
Документационное обеспечение управления и фукционирование организации Игрушки из полхов-майдана
Игрушки из полхов-майдана Ювенальная юстиция «за» и «против»
Ювенальная юстиция «за» и «против» С Днём матери
С Днём матери Графики линейных функций
Графики линейных функций Презентация на тему Влияние солнечной активности на процессы, происходящие на Земле
Презентация на тему Влияние солнечной активности на процессы, происходящие на Земле  ICN Holding
ICN Holding Феномен канона в искусстве Древнего Египта
Феномен канона в искусстве Древнего Египта Общество как сложная динамичная система
Общество как сложная динамичная система Социальные сети Презентацию разработала ученица 11 класса «А» Рязанова Анастасия.
Социальные сети Презентацию разработала ученица 11 класса «А» Рязанова Анастасия. New Jersey Employment Law Attorneys
New Jersey Employment Law Attorneys Willst du glücklich sein im Leben, trage bei zu andrer Glück, denn die Freude, die wir geben, kehrt ins eigene Herz zurück. Willst du glücklich sein im. - презентация
Willst du glücklich sein im Leben, trage bei zu andrer Glück, denn die Freude, die wir geben, kehrt ins eigene Herz zurück. Willst du glücklich sein im. - презентация Образ матери в искусстве
Образ матери в искусстве Гиподинамия
Гиподинамия  Здоровье, как его сберечь
Здоровье, как его сберечь Презентация на тему Возникновение искусства и религиозных верований
Презентация на тему Возникновение искусства и религиозных верований  Городской центр социальных и спортивных программ г. Севастополя Детско-юношеский клуб Салют
Городской центр социальных и спортивных программ г. Севастополя Детско-юношеский клуб Салют