- Data Mining Что такое Data Mining

Содержание
- 2. Что такое Data Mining? "За последние годы, когда, стремясь к повышению эффективности и прибыльности бизнеса, при
- 3. Что такое Data Mining? Data Mining - мультидисциплинарная область, возникшая и развивающаяся на базе таких наук
- 4. Data Mining как мультидисциплинарная область
- 5. Понятие Статистики Статистика - это наука о методах сбора данных, их обработки и анализа для выявления
- 6. Понятие Машинного обучения Единого определения машинного обучения на сегодняшний день нет. Машинное обучение можно охарактеризовать как
- 7. Понятие Искусственного интеллекта Искусственный интеллект - научное направление, в рамках которого ставятся и решаются задачи аппаратного
- 8. Понятие Data Mining Data Mining - это процесс поддержки принятия решений, основанный на поиске в данных
- 9. Неочевидных - это значит, что найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем.
- 10. Data Mining - это процесс выделения из данных неявной и неструктурированной информации и представления ее в
- 11. Прежде чем использовать технологию Data Mining, необходимо тщательно проанализировать ее проблемы, ограничения и критические вопросы, с
- 12. Отличия Data Mining от других методов анализа данных Традиционные методы анализа данных (статистические методы) и OLAP
- 13. Перспективы технологии Data Mining выделение типов предметных областей с соответствующими им эвристиками, формализация которых облегчит решение
- 14. Данные Что такое данные? В широком понимании данные представляют собой факты, текст, графики, картинки, звуки, аналоговые
- 15. Набор данных и их атрибутов В таблице представлена двухмерная таблица, представляющая собой набор данных. Код Возраст
- 16. По горизонтали таблицы располагаются атрибуты объекта или его признаки. По вертикали таблицы - объекты. Объект описывается
- 17. Базы данных. Основные положения База данных (Database) - это особым образом организованные и хранимые в электронном
- 18. Методы и стадии Data Mining Основная особенность Data Mining - это сочетание широкого математического инструментария (от
- 19. Классификация стадий Data Mining Data Mining может состоять из двух или трех стадий Стадия 1. Выявление
- 20. Свободный поиск (Discovery) Свободный поиск представлен такими действиями: выявление закономерностей условной логики (conditional logic); выявление закономерностей
- 21. Могут быть найдены, например, такие закономерности "Если возраст 700 условных единиц, то в 75% случаев соискатель
- 22. Описанные действия, в рамках стадии свободного поиска, выполняются при помощи: индукции правил условной логики (задачи классификации
- 23. 2. Прогностическое моделирование (Predictive Modeling) Вторая стадия Data Mining - прогностическое моделирование - использует результаты работы
- 24. Продолжая рассмотренный пример первой стадии, можем сделать следующий вывод. Зная, что соискатель ищет руководящую работу и
- 25. Сравнение свободного поиска и прогностического моделирования с точки зрения логики Свободный поиск раскрывает общие закономерности. Он
- 26. 3. Анализ исключений (forensic analysis) На третьей стадии Data Mining анализируются исключения или аномалии, выявленные в
- 27. Классификация методов Data Mining В классификации различают две группы методов: статистические методы, основанные на использовании усредненного
- 28. Статистические методы Data mining 1. Дескриптивный анализ и описание исходных данных. 2. Анализ связей (корреляционный и
- 29. Кибернетические методы Data Mining Второе направление Data Mining - это множество подходов, объединенных идеей компьютерной математики
- 30. Задачи Data Mining Классификация (Classification) Краткое описание. Наиболее простая и распространенная задача Data Mining. В результате
- 31. Задачи Data Mining Кластеризация (Clustering) Краткое описание. Кластеризация является логическим продолжением идеи классификации. Это задача более
- 32. Задачи Data Mining Ассоциация (Associations) Краткое описание. В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности
- 33. Задачи Data Mining Последовательность (Sequence), или последовательная ассоциация (sequential association) Краткое описание. Последовательность позволяет найти временные
- 34. Задачи Data Mining Прогнозирование (Forecasting) Краткое описание. В результате решения задачи прогнозирования на основе особенностей исторических
- 35. Задачи Data Mining Определение отклонений или выбросов (Deviation Detection), анализ отклонений или Выбросов Краткое описание. Цель
- 36. Задачи Data Mining Оценивание (Estimation). Задача оценивания сводится к предсказанию непрерывных значений признака. Анализ связей (Link
- 37. Связь понятий
- 38. Задачи, действия, приложения
- 39. Верхний - уровень приложений - является уровнем бизнеса (если мы имеем дело с задачей бизнеса), на
- 40. Рассмотрим задачу удержания клиентов (определения надежности клиентов фирмы). Первый уровень. Данные - база данных по клиентам.
- 41. Информация. Свойства информации · Полнота информации. Это свойство характеризует качество информации и определяет достаточность данных для
- 42. Знания Знания - совокупность фактов, закономерностей и эвристических правил, с помощью которых решается поставленная задача. Знания
- 43. Задачи Data Mining. Классификация и кластеризация Задача классификации Классификация - упорядоченное по некоторому принципу множество объектов,
- 44. В зависимости от выбранных признаков, их сочетания и процедуры деления понятий классификация может быть: · простой
- 45. Рассмотрим задачу классификации на простом примере. Допустим, имеется база данных о клиентах туристического агентства с информацией
- 47. Процесс классификации состоит из двух этапов: конструирования модели и ее использования. 1. Конструирование модели: описание множества
- 48. Методы, применяемые для решения задач классификации Для классификации используются различные методы. Основные из них: · классификация
- 49. Решение задачи классификации методом нейронных сетей Решение задачи классификации методом линейной регрессии
- 50. Задача кластеризации Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные
- 51. Задачи Data Mining. Прогнозирование и визуализация Задача прогнозирования Прогнозирование направлено на определение тенденций динамики конкретного объекта
- 52. Точность прогноза Точность прогноза характеризуется ошибкой прогноза. Наиболее распространенные виды ошибок: · Средняя ошибка (СО). Она
- 53. Задача визуализации Визуализация - это инструментарий, который позволяет увидеть конечный результат вычислений, организовать управление вычислительным процессом
- 54. Методы классификации и прогнозирования. Деревья решений Метод деревьев решений (decision trees) является одним из наиболее популярных
- 55. Играть ли в гольф?
- 56. задача "Выдавать ли кредит клиенту?".
- 57. CRISP-DM методология CRISP-DM [100] (The Cross Industrie Standard Process for Data Mining – Стандартный межотраслевой процесс
- 59. SEMMA методология SEMMA методология реализована в среде SAS Data Mining Solution (SAS) [102]. Ее аббревиатура образована
- 62. Скачать презентацию

Слайд 3Что такое Data Mining?
Data Mining - мультидисциплинарная область, возникшая и развивающаяся на
Что такое Data Mining?
Data Mining - мультидисциплинарная область, возникшая и развивающаяся на

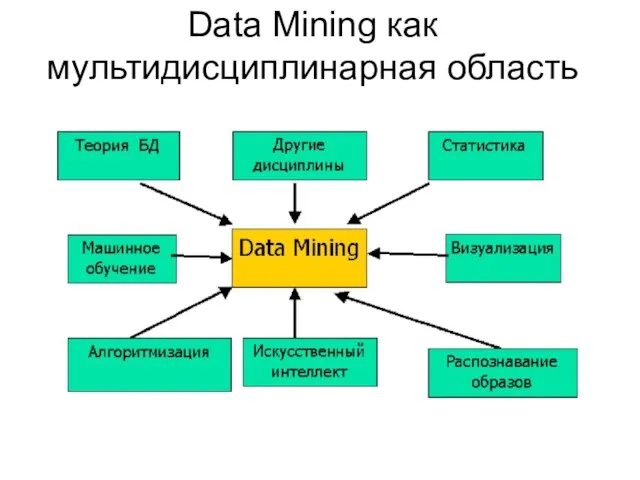
Слайд 4Data Mining как мультидисциплинарная область
Data Mining как мультидисциплинарная область
Слайд 5Понятие Статистики
Статистика - это наука о методах сбора данных, их обработки и
Понятие Статистики
Статистика - это наука о методах сбора данных, их обработки и

Слайд 6Понятие Машинного обучения
Единого определения машинного обучения на сегодняшний день нет.
Машинное обучение можно
Понятие Машинного обучения
Единого определения машинного обучения на сегодняшний день нет.
Машинное обучение можно

Слайд 7Понятие Искусственного интеллекта
Искусственный интеллект - научное направление, в рамках которого ставятся и
Понятие Искусственного интеллекта
Искусственный интеллект - научное направление, в рамках которого ставятся и

Слайд 8Понятие Data Mining
Data Mining - это процесс поддержки принятия решений, основанный на
Понятие Data Mining
Data Mining - это процесс поддержки принятия решений, основанный на

Слайд 9Неочевидных - это значит, что найденные закономерности не обнаруживаются стандартными методами обработки
Неочевидных - это значит, что найденные закономерности не обнаруживаются стандартными методами обработки

Слайд 10Data Mining - это процесс выделения из данных неявной и неструктурированной информации
Data Mining - это процесс выделения из данных неявной и неструктурированной информации

Слайд 11Прежде чем использовать технологию Data Mining, необходимо тщательно проанализировать ее проблемы, ограничения
Прежде чем использовать технологию Data Mining, необходимо тщательно проанализировать ее проблемы, ограничения

Слайд 12Отличия Data Mining от других методов анализа данных
Традиционные методы анализа данных (статистические
Отличия Data Mining от других методов анализа данных
Традиционные методы анализа данных (статистические

Слайд 13Перспективы технологии Data Mining
выделение типов предметных областей с соответствующими им эвристиками,
Перспективы технологии Data Mining
выделение типов предметных областей с соответствующими им эвристиками,

Слайд 14Данные
Что такое данные?
В широком понимании данные представляют собой факты, текст, графики,
Данные
Что такое данные?
В широком понимании данные представляют собой факты, текст, графики,

Слайд 15Набор данных и их атрибутов
В таблице представлена двухмерная таблица, представляющая собой набор
Набор данных и их атрибутов
В таблице представлена двухмерная таблица, представляющая собой набор

Слайд 16По горизонтали таблицы располагаются атрибуты объекта или его признаки. По вертикали таблицы
По горизонтали таблицы располагаются атрибуты объекта или его признаки. По вертикали таблицы

Слайд 17Базы данных. Основные положения
База данных (Database) - это особым образом организованные и
Базы данных. Основные положения
База данных (Database) - это особым образом организованные и

Слайд 18Методы и стадии Data Mining
Основная особенность Data Mining - это сочетание широкого
Методы и стадии Data Mining
Основная особенность Data Mining - это сочетание широкого

Слайд 19Классификация стадий Data Mining
Data Mining может состоять из двух или трех
Классификация стадий Data Mining
Data Mining может состоять из двух или трех

Слайд 20Свободный поиск (Discovery)
Свободный поиск представлен такими действиями:
выявление закономерностей условной логики (conditional logic);
выявление
Свободный поиск (Discovery)
Свободный поиск представлен такими действиями:
выявление закономерностей условной логики (conditional logic);
выявление

Слайд 21 Могут быть найдены, например, такие закономерности
"Если возраст < 20 лет и
Могут быть найдены, например, такие закономерности
"Если возраст < 20 лет и

Слайд 22Описанные действия, в рамках стадии свободного поиска, выполняются при помощи:
индукции правил условной
Описанные действия, в рамках стадии свободного поиска, выполняются при помощи:
индукции правил условной

Слайд 232. Прогностическое моделирование (Predictive Modeling)
Вторая стадия Data Mining - прогностическое моделирование
2. Прогностическое моделирование (Predictive Modeling)
Вторая стадия Data Mining - прогностическое моделирование

Слайд 24 Продолжая рассмотренный пример первой стадии, можем сделать следующий вывод.
Зная, что соискатель
Продолжая рассмотренный пример первой стадии, можем сделать следующий вывод.
Зная, что соискатель

Слайд 25Сравнение свободного поиска и прогностического моделирования с точки зрения логики
Свободный поиск раскрывает
Сравнение свободного поиска и прогностического моделирования с точки зрения логики
Свободный поиск раскрывает

Слайд 263. Анализ исключений (forensic analysis)
На третьей стадии Data Mining анализируются исключения
3. Анализ исключений (forensic analysis)
На третьей стадии Data Mining анализируются исключения

Слайд 27Классификация методов Data Mining
В классификации различают две группы методов:
статистические методы, основанные на
Классификация методов Data Mining
В классификации различают две группы методов:
статистические методы, основанные на

Слайд 28Статистические методы Data mining
1. Дескриптивный анализ и описание исходных данных.
2. Анализ связей
Статистические методы Data mining
1. Дескриптивный анализ и описание исходных данных.
2. Анализ связей

Слайд 29Кибернетические методы Data Mining
Второе направление Data Mining - это множество подходов, объединенных
Кибернетические методы Data Mining
Второе направление Data Mining - это множество подходов, объединенных

Слайд 30Задачи Data Mining
Классификация (Classification)
Краткое описание. Наиболее простая и распространенная задача Data Mining.
Задачи Data Mining
Классификация (Classification)
Краткое описание. Наиболее простая и распространенная задача Data Mining.

Слайд 31Задачи Data Mining
Кластеризация (Clustering)
Краткое описание. Кластеризация является логическим продолжением идеи классификации. Это
Задачи Data Mining
Кластеризация (Clustering)
Краткое описание. Кластеризация является логическим продолжением идеи классификации. Это

Слайд 32Задачи Data Mining
Ассоциация (Associations)
Краткое описание. В ходе решения задачи поиска ассоциативных правил
Задачи Data Mining
Ассоциация (Associations)
Краткое описание. В ходе решения задачи поиска ассоциативных правил

Слайд 33Задачи Data Mining
Последовательность (Sequence), или последовательная ассоциация (sequential association)
Краткое описание. Последовательность позволяет
Задачи Data Mining
Последовательность (Sequence), или последовательная ассоциация (sequential association)
Краткое описание. Последовательность позволяет

Слайд 34Задачи Data Mining
Прогнозирование (Forecasting)
Краткое описание. В результате решения задачи прогнозирования на основе
Задачи Data Mining
Прогнозирование (Forecasting)
Краткое описание. В результате решения задачи прогнозирования на основе

Слайд 35Задачи Data Mining
Определение отклонений или выбросов (Deviation Detection), анализ отклонений или Выбросов
Задачи Data Mining
Определение отклонений или выбросов (Deviation Detection), анализ отклонений или Выбросов

Слайд 36Задачи Data Mining
Оценивание (Estimation). Задача оценивания сводится к предсказанию непрерывных значений признака.
Анализ
Задачи Data Mining
Оценивание (Estimation). Задача оценивания сводится к предсказанию непрерывных значений признака.
Анализ

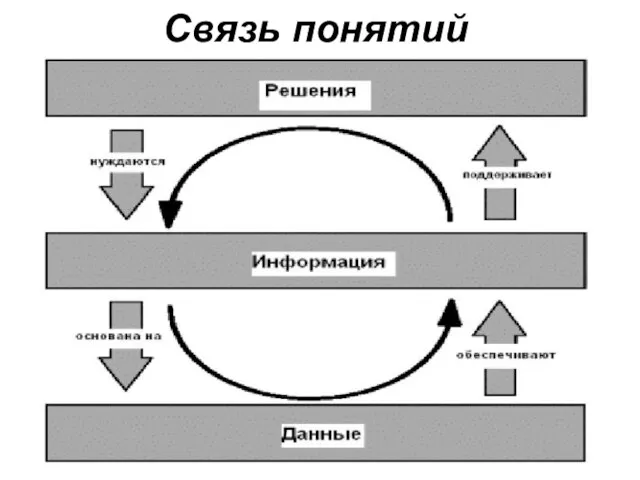
Слайд 37Связь понятий
Связь понятий
Слайд 38Задачи, действия, приложения
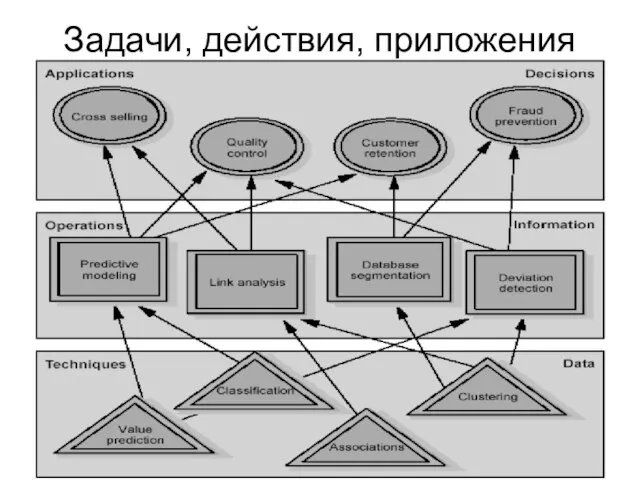
Задачи, действия, приложения
Слайд 39Верхний - уровень приложений - является уровнем бизнеса (если мы имеем дело
Верхний - уровень приложений - является уровнем бизнеса (если мы имеем дело

Слайд 40Рассмотрим задачу удержания клиентов (определения надежности клиентов фирмы).
Первый уровень. Данные - база
Рассмотрим задачу удержания клиентов (определения надежности клиентов фирмы).
Первый уровень. Данные - база

Слайд 41Информация. Свойства информации
· Полнота информации.
Это свойство характеризует качество информации и определяет достаточность
Информация. Свойства информации
· Полнота информации.
Это свойство характеризует качество информации и определяет достаточность

Слайд 42Знания
Знания - совокупность фактов, закономерностей и эвристических правил, с помощью которых решается
Знания
Знания - совокупность фактов, закономерностей и эвристических правил, с помощью которых решается

Слайд 43Задачи Data Mining. Классификация и кластеризация
Задача классификации
Классификация - упорядоченное по некоторому принципу
Задачи Data Mining. Классификация и кластеризация
Задача классификации
Классификация - упорядоченное по некоторому принципу

Слайд 44В зависимости от выбранных признаков, их сочетания и процедуры деления понятий классификация
В зависимости от выбранных признаков, их сочетания и процедуры деления понятий классификация

Слайд 45Рассмотрим задачу классификации на простом примере. Допустим, имеется база данных о клиентах
Рассмотрим задачу классификации на простом примере. Допустим, имеется база данных о клиентах


Слайд 47Процесс классификации состоит из двух этапов: конструирования модели и ее использования.
1. Конструирование
Процесс классификации состоит из двух этапов: конструирования модели и ее использования.
1. Конструирование

Слайд 48Методы, применяемые для решения задач классификации
Для классификации используются различные методы.
Основные из
Методы, применяемые для решения задач классификации
Для классификации используются различные методы.
Основные из

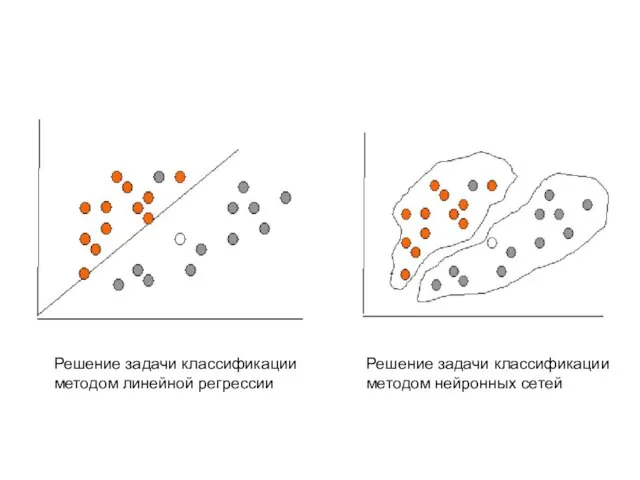
Слайд 49Решение задачи классификации
методом нейронных сетей
Решение задачи классификации
методом линейной регрессии
Решение задачи классификации
методом нейронных сетей
Решение задачи классификации
методом линейной регрессии
Слайд 50Задача кластеризации
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или
Задача кластеризации
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или

Слайд 51Задачи Data Mining. Прогнозирование и визуализация
Задача прогнозирования
Прогнозирование направлено на определение тенденций динамики
Задачи Data Mining. Прогнозирование и визуализация
Задача прогнозирования
Прогнозирование направлено на определение тенденций динамики

Слайд 52Точность прогноза
Точность прогноза характеризуется ошибкой прогноза.
Наиболее распространенные виды ошибок:
· Средняя ошибка (СО).
Точность прогноза
Точность прогноза характеризуется ошибкой прогноза.
Наиболее распространенные виды ошибок:
· Средняя ошибка (СО).

Слайд 53Задача визуализации
Визуализация - это инструментарий, который позволяет увидеть конечный результат вычислений, организовать
Задача визуализации
Визуализация - это инструментарий, который позволяет увидеть конечный результат вычислений, организовать

Слайд 54Методы классификации и прогнозирования. Деревья решений
Метод деревьев решений (decision trees) является одним
Методы классификации и прогнозирования. Деревья решений
Метод деревьев решений (decision trees) является одним

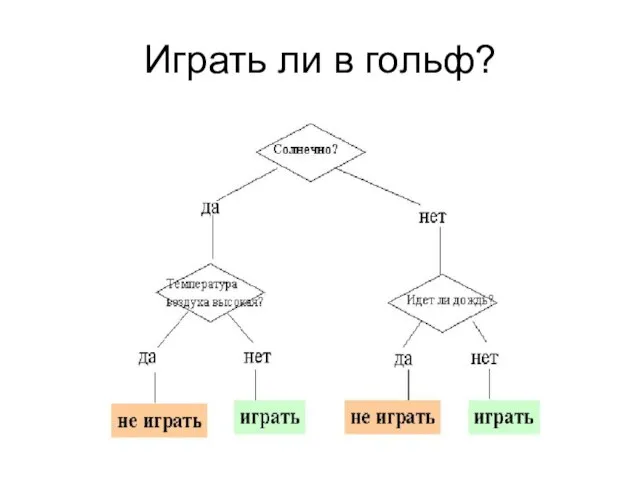
Слайд 55Играть ли в гольф?
Играть ли в гольф?
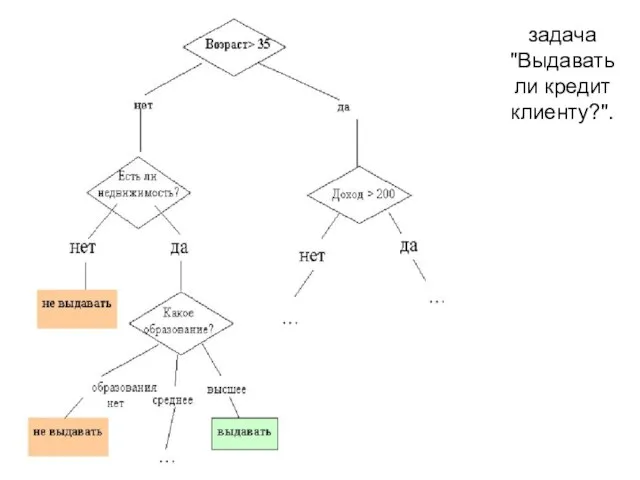
Слайд 56задача "Выдавать ли кредит клиенту?".
задача "Выдавать ли кредит клиенту?".
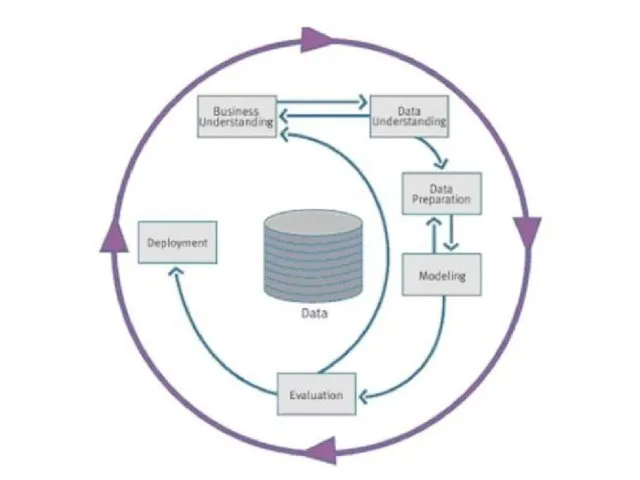
Слайд 57CRISP-DM методология
CRISP-DM [100] (The Cross Industrie Standard Process for Data Mining –
CRISP-DM методология
CRISP-DM [100] (The Cross Industrie Standard Process for Data Mining –
![CRISP-DM методология CRISP-DM [100] (The Cross Industrie Standard Process for Data Mining](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/374246/slide-56.jpg)
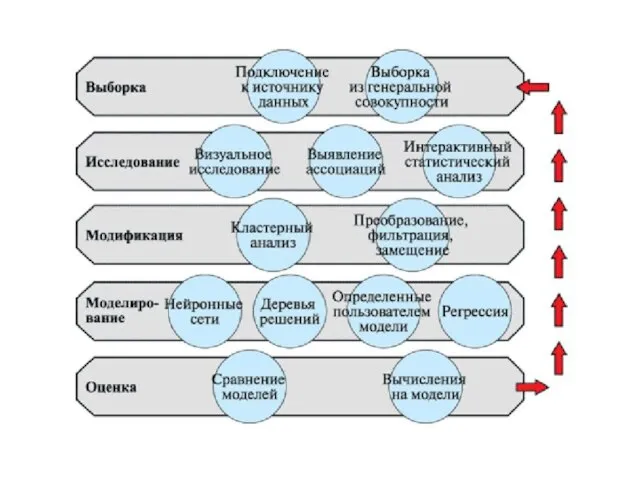
Слайд 59SEMMA методология
SEMMA методология реализована в среде SAS Data Mining Solution (SAS) [102].
SEMMA методология
SEMMA методология реализована в среде SAS Data Mining Solution (SAS) [102].

 Все о полиграфическом рынке
Все о полиграфическом рынке Компания Ракурс
Компания Ракурс Эмпирические социальные достижения
Эмпирические социальные достижения  Как возникло франкское государство
Как возникло франкское государство Сложение чисел с помощью координатной прямой
Сложение чисел с помощью координатной прямой Значение творчества В.А.Серова для развития отечественной живописи
Значение творчества В.А.Серова для развития отечественной живописи CIVIL LAW Concept and grounds
CIVIL LAW Concept and grounds Неополис - город будущего. Город на реке: бренд успешной столицы
Неополис - город будущего. Город на реке: бренд успешной столицы Магистральные модели
Магистральные модели Тонкослойная хроматография
Тонкослойная хроматография Презентация на тему Строение цветка
Презентация на тему Строение цветка  Основные устройства компьютера,их функции и взаимосвязь.
Основные устройства компьютера,их функции и взаимосвязь. Молекулярная эволюция и филогенетика
Молекулярная эволюция и филогенетика  КОНДИЦИОНЕРЫ Samsung 2009
КОНДИЦИОНЕРЫ Samsung 2009 Пришедшая выручка
Пришедшая выручка Первобытные люди 4 класс
Первобытные люди 4 класс Италия после второй мировой войны
Италия после второй мировой войны Магический кубик
Магический кубик Закон о воспитании: план действий дошкольной организации по реализации новых положений законодательства
Закон о воспитании: план действий дошкольной организации по реализации новых положений законодательства d4798d3f5a007823a7d4b1743d3eced2
d4798d3f5a007823a7d4b1743d3eced2 Армянский Петербург
Армянский Петербург НАЦИОНАЛЬНЫЙ ПЛАН УПРАВЛЕНИЯ ЗАСУХАМИ ПО ГРУЗИИ
НАЦИОНАЛЬНЫЙ ПЛАН УПРАВЛЕНИЯ ЗАСУХАМИ ПО ГРУЗИИ Презентация на тему Вакуумные приборы
Презентация на тему Вакуумные приборы  Тема лекции:«Электронная цифровая подпись»
Тема лекции:«Электронная цифровая подпись» Электронный дневник и электронный журнал в NetSchool как часть комплексной информационной системы (с) 2001-2011 ИРТех
Электронный дневник и электронный журнал в NetSchool как часть комплексной информационной системы (с) 2001-2011 ИРТех А.С. Пушкин Краткая биография в картинках
А.С. Пушкин Краткая биография в картинках Перейти Рубикон
Перейти Рубикон Презентация на тему A history about David Livingstone
Презентация на тему A history about David Livingstone