- 8

Содержание
- 2. Постморфологический анализ =предсинтаксический анализ Предназначен для устранения морфологической омонимии (многозначности) слов Выбор правильной леммы Уточнение морфологических
- 3. Набор состояний: Процесс движется от одного состояния к другому, порождая последовательность состояний : Свойство марковской цепи:
- 4. Два состояния : ‘Rain’ и ‘Dry’ Вероятности переходов: P(‘Rain’|‘Rain’)=0.3 , P(‘Dry’|‘Rain’)=0.7 , P(‘Rain’|‘Dry’)=0.2, P(‘Dry’|‘Dry’)=0.8 Исходные вероятности:
- 5. По свойству марковской цепи, вероятность последовательности состояний может быть найдена по формуле Предположим, мы хотим подсчитать
- 6. Скрытые марковские модели Множество состояний: Процесс движется от состояния к состоянию : Выполняется свойство марковской цепи:
- 7. Dry 0.6 0.6 0.4 0.4 Пример скрытой марковской модели
- 8. Два состояния: ‘Низкое’ and ‘Высокое’ атм. давление. Два наблюдения: ‘Дождь’ and ‘Сухо’. Вероятности перехода: P(‘Low’|‘Low’)=0.3 ,
- 9. Хотим вычислить вероятность последовательности, {‘Dry’,’Rain’}. Рассмотрим все возможные скрытые состояния: P({‘Dry’,’Rain’} ) = P({‘Dry’,’Rain’} , {‘Low’,’Low’})
- 10. Почему важно рассмотрение HMM в автоматической обработке текста Непосредственно имеем дело с неоднозначными словами и конструкциями
- 11. Что такое HMM? Графическая модель Кружки – это состояния Стрелки обозначают вероятностные зависимости между состояниями
- 12. Что такое HMM? Зеленые кружки – это скрытые состояния Зависят только от предыдущего состояния
- 13. Что такое HMM? Фиолетовые кружки – это наблюдаемые состояния Зависят только от соответствующих скрытых состояний
- 14. HMM формализм {S, K, Π, Α, Β} S : {s1…sN } - значения скрытых состояний K
- 15. HMM формализм {S, K, Π, Α, Β} Π = {πι} - вероятности начальных состояний A =
- 16. Вывод HMM Вычислить вероятность последовательности наблюдаемых состояний (Evaluation) Имея последовательность наблюдаемых состояний, вычислить наиболее вероятную последовательность
- 17. o1 ot ot-1 ot+1 Имея последовательность наблюдаемых состояний и модель, вычислить вероятность последовательности наблюдаемых состояний Оценка
- 18. Оценка (Evaluation) Сложность O (NT), где N – число возможных вариантов состояний
- 19. Форвардная процедура Метод динамического программирования Определим переменную: Смысл переменной α: вероятность наблюдений o1, …ot и при
- 20. Форвардная процедура
- 21. Форвардная процедура
- 22. Вычисление вероятности последовательности наблюдаемых событий Можем эффективно вычислять αT(I)=P(o1, o2,…oT, xT=i|μ) Как вычислить P(o1, o2,…oT |μ)?
- 23. Вычисление вероятности последовательности наблюдаемых событий Можем эффективно вычислять αT(i)=P(o1, o2,…oT, xT=i|μ) Как вычислить P(o1, o2,…oT |μ)
- 24. Форвардный алгоритм: пример
- 25. Форвардный алгоритм Найти вероятность последовательности: s r r s r (s- sun, r – rain)
- 28. Декодирование Вычислить вероятность последовательности наблюдаемых состояний (Evaluation) Имея последовательность наблюдаемых состояний, вычислить наиболее вероятную последовательность скрытых
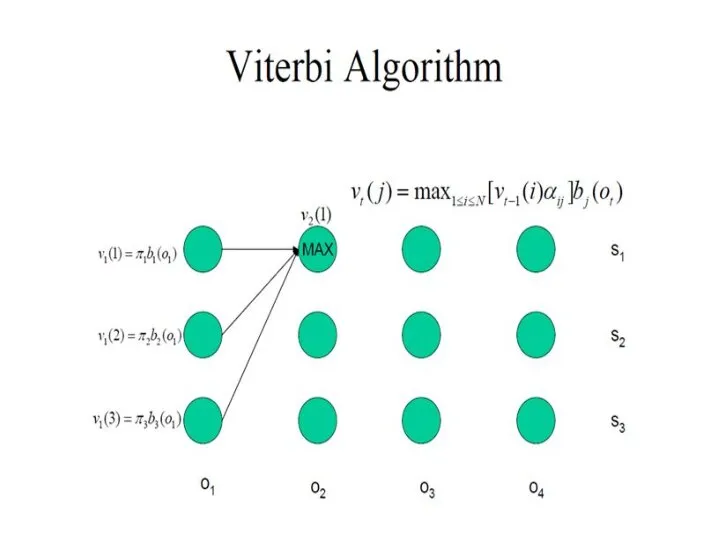
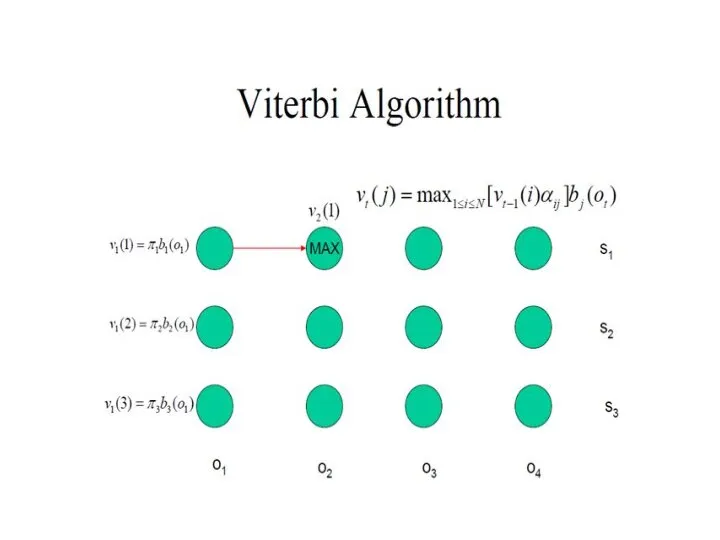
- 29. Декодирование: Best State Sequence Найти множество состояний, которые наилучшим образом объясняют последовательность видимых состояний Viterbi algorithm
- 30. oT o1 ot ot-1 ot+1 Алгоритм Витерби Последовательность состояний, которая максимизирует вероятность увидеть заданную последовательность видимых
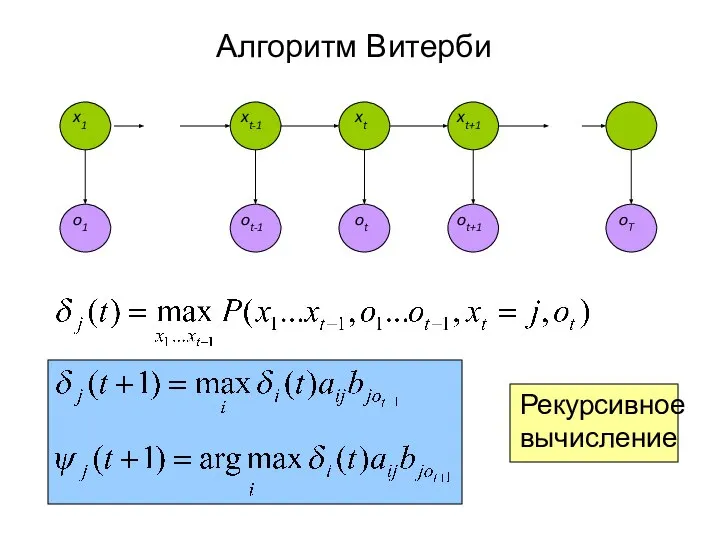
- 31. Алгоритм Витерби Рекурсивное вычисление x1 xt-1 xt xt+1
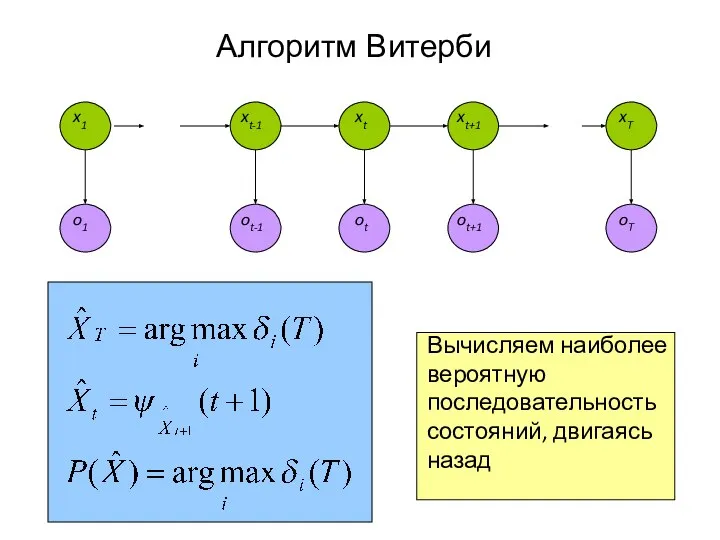
- 32. Алгоритм Витерби Вычисляем наиболее вероятную последовательность состояний, двигаясь назад x1 xt-1 xt xt+1 xT
- 39. Тот же пример для алгоритма Витерби
- 40. Пример: Алгоритм Витерби
- 41. Пример. Алгоритм Витерби
- 42. Применение HMM к POS-tagging POS-tagging – морфологическая разметка HMM tagger: выбирает наиболее вероятную последовательность тегов для
- 43. Пример: морфологическая неоднозначность
- 44. Откуда взять данные? Из корпуса с морфологической разметкой Русский язык: Корпус русского языка Открытый корпус (opencorpora.org)
- 45. Фрагмент морфологической разметки в Национальном корпусе русского языка Я сидел на барском сиденье, дышал горячим ветром,
- 46. Данные для примера
- 59. Лексические вероятности: уточнение Мы считали p(w|t) Но Слово могло отсутствовать в корпусе или отсутствовать в заданной
- 60. Лексические вероятности ~ p(t) – априорная вероятность метки p(t|w) – вероятность метки для данного слова Можно
- 61. Словарь и лексические вероятности Можно считать, что все словарные метки слова w входят в корпус α
- 62. Анализ статистических алгоритмов снятия морфологической омонимии в русском языке Егор Лакомкин Иван Пузыревский Дарья Рыжова (2013)
- 63. Разрешение морфологической неоднозначности в текстах на английском языке Методы: Как правило, статистические алгоритмы на основе марковских
- 64. Особенности английского языка Бедная морфология морфологическая разметка фактически сводится к POS-теггингу Фиксированный порядок слов можно опираться
- 65. Задача исследования: Проверить экспериментально, применимы ли статистические алгоритмы, основанные на марковских моделях, к задаче морфологической дизамбигуации
- 66. Алгоритмы Набор скрытых величин Y (состояний модели = наборов грамматических тегов); составляют марковскую цепь первого порядка
- 67. HMM Обучение: Сбор статистик по корпусу: P(yi|yj) – матрица переходов P(xk|yi) – вероятности наблюдений сущ прил
- 68. Задача алгоритмов: Вычисление наиболее вероятной последовательности скрытых величин
- 69. Деление выборки на обучающую и тестирующую: Кросс-валидация (5 фолдов): Деление выборки на 5 частей: 4 обучающие
- 70. Оценка качества Определение верхней и нижней границы: Верхняя граница: процент случаев, когда среди гипотез Mystem’а есть
- 71. Результаты
- 72. Выводы работы POS-теггинг – на приличном уровне, Разрешение неоднозначности по расширенным тегам – довольно низкий уровень
- 73. Проблемы HMM Метки рассматриваются как единое целое, невозможно извлечь отдельные признаки В русском языке: тег –
- 74. Как можно изменить процесс расчета переходов между состояниями? HMM: учитываются два фактора в простой комбинации Для
- 76. Скачать презентацию
Слайд 2Постморфологический анализ
=предсинтаксический анализ
Предназначен для устранения морфологической омонимии (многозначности) слов
Выбор правильной леммы
Уточнение морфологических
Постморфологический анализ
=предсинтаксический анализ
Предназначен для устранения морфологической омонимии (многозначности) слов
Выбор правильной леммы
Уточнение морфологических

Слайд 3 Набор состояний:
Процесс движется от одного состояния к другому, порождая последовательность состояний
Набор состояний:
Процесс движется от одного состояния к другому, порождая последовательность состояний

Слайд 4 Два состояния : ‘Rain’ и ‘Dry’
Вероятности переходов: P(‘Rain’|‘Rain’)=0.3 , P(‘Dry’|‘Rain’)=0.7
Два состояния : ‘Rain’ и ‘Dry’
Вероятности переходов: P(‘Rain’|‘Rain’)=0.3 , P(‘Dry’|‘Rain’)=0.7
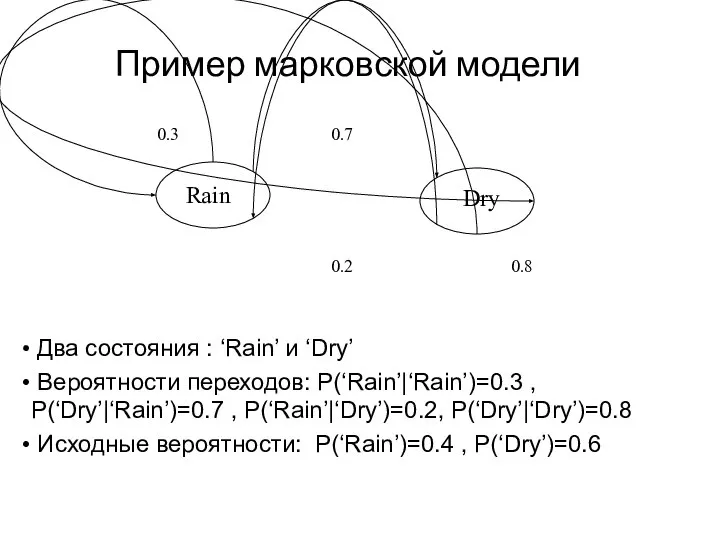
Слайд 5 По свойству марковской цепи, вероятность последовательности состояний может быть найдена по
По свойству марковской цепи, вероятность последовательности состояний может быть найдена по

Слайд 6Скрытые марковские модели
Множество состояний:
Процесс движется от состояния к состоянию
Скрытые марковские модели
Множество состояний:
Процесс движется от состояния к состоянию

Слайд 7Dry
0.6
0.6
0.4
0.4
Пример скрытой марковской модели
Dry
0.6
0.6
0.4
0.4
Пример скрытой марковской модели
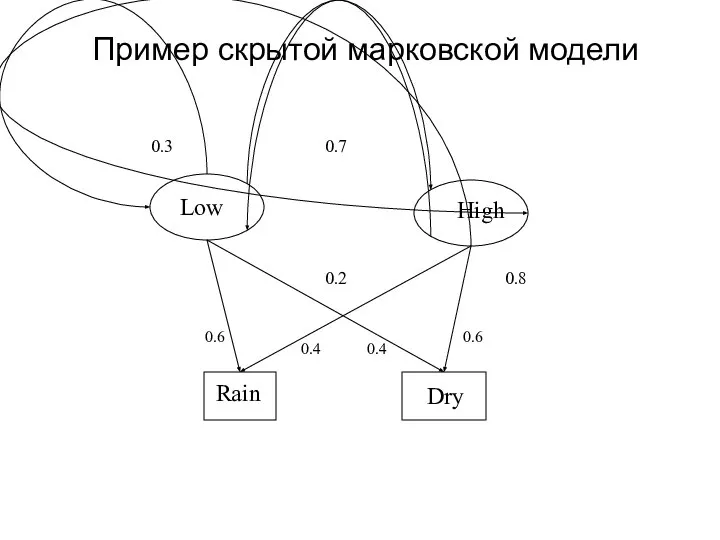
Слайд 8 Два состояния: ‘Низкое’ and ‘Высокое’ атм. давление.
Два наблюдения: ‘Дождь’ and
Два состояния: ‘Низкое’ and ‘Высокое’ атм. давление.
Два наблюдения: ‘Дождь’ and

Слайд 9 Хотим вычислить вероятность последовательности, {‘Dry’,’Rain’}.
Рассмотрим все возможные скрытые состояния:
P({‘Dry’,’Rain’}
Хотим вычислить вероятность последовательности, {‘Dry’,’Rain’}.
Рассмотрим все возможные скрытые состояния:
P({‘Dry’,’Rain’}

Слайд 10Почему важно рассмотрение HMM в автоматической обработке текста
Непосредственно имеем дело с неоднозначными
Почему важно рассмотрение HMM в автоматической обработке текста
Непосредственно имеем дело с неоднозначными

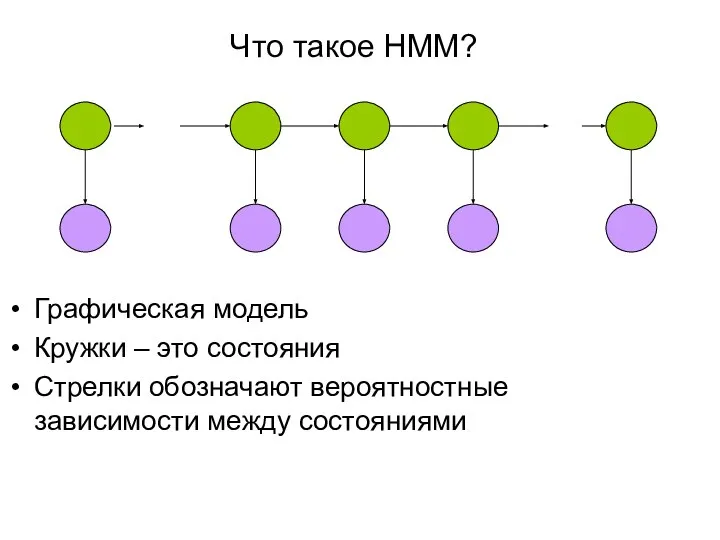
Слайд 11Что такое HMM?
Графическая модель
Кружки – это состояния
Стрелки обозначают вероятностные зависимости между состояниями
Что такое HMM?
Графическая модель
Кружки – это состояния
Стрелки обозначают вероятностные зависимости между состояниями
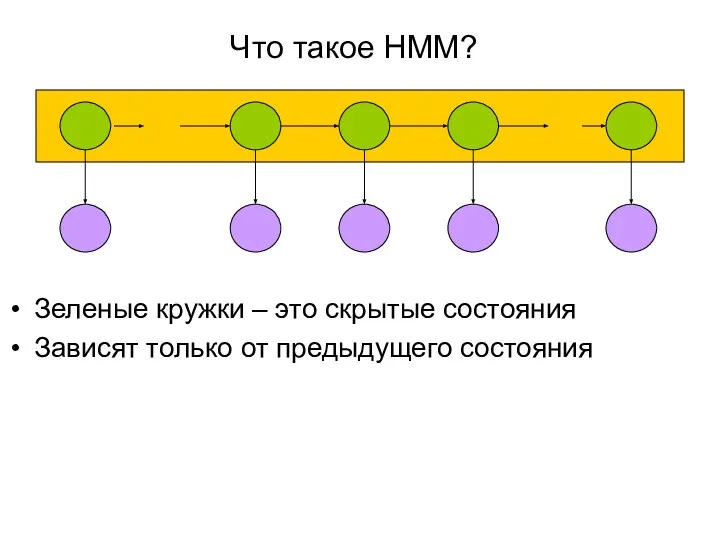
Слайд 12Что такое HMM?
Зеленые кружки – это скрытые состояния
Зависят только от предыдущего
Что такое HMM?
Зеленые кружки – это скрытые состояния
Зависят только от предыдущего
Слайд 13Что такое HMM?
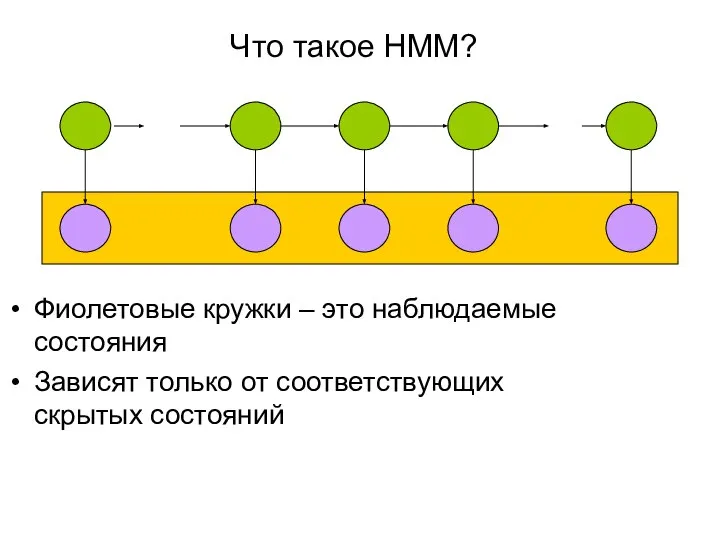
Фиолетовые кружки – это наблюдаемые состояния
Зависят только от соответствующих скрытых
Что такое HMM?
Фиолетовые кружки – это наблюдаемые состояния
Зависят только от соответствующих скрытых
Слайд 14HMM формализм
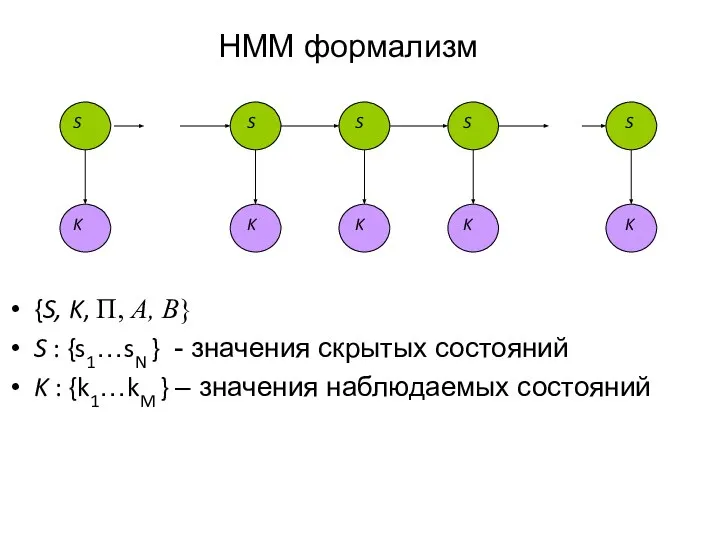
{S, K, Π, Α, Β}
S : {s1…sN } - значения
HMM формализм
{S, K, Π, Α, Β}
S : {s1…sN } - значения
Слайд 15HMM формализм
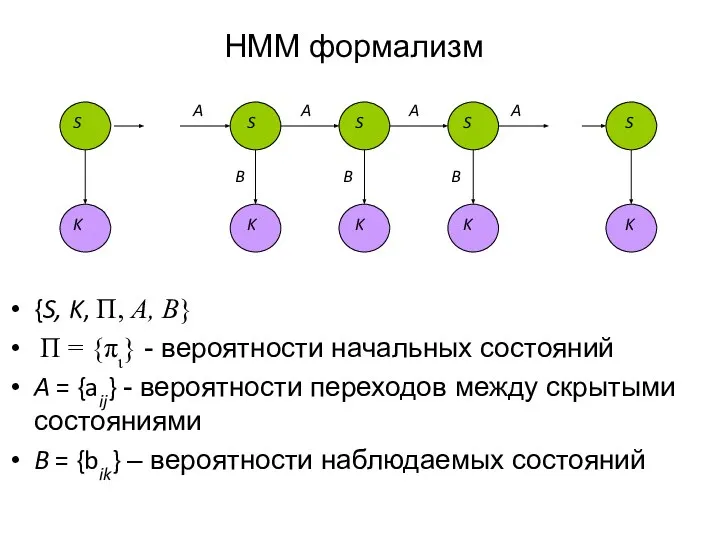
{S, K, Π, Α, Β}
Π = {πι} - вероятности
HMM формализм
{S, K, Π, Α, Β}
Π = {πι} - вероятности
Слайд 16Вывод HMM
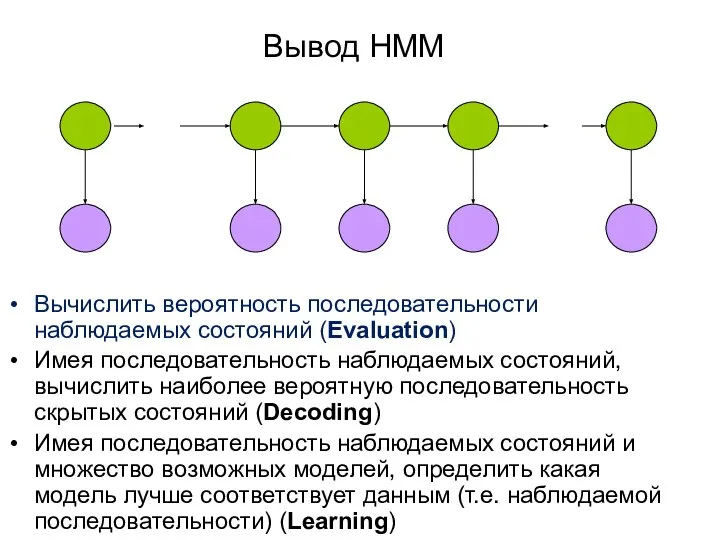
Вычислить вероятность последовательности наблюдаемых состояний (Evaluation)
Имея последовательность наблюдаемых состояний, вычислить наиболее
Вывод HMM
Вычислить вероятность последовательности наблюдаемых состояний (Evaluation)
Имея последовательность наблюдаемых состояний, вычислить наиболее
Слайд 17o1
ot
ot-1
ot+1
Имея последовательность наблюдаемых состояний и модель, вычислить вероятность последовательности наблюдаемых состояний
Оценка (Evaluation)
o1
ot
ot-1
ot+1
Имея последовательность наблюдаемых состояний и модель, вычислить вероятность последовательности наблюдаемых состояний
Оценка (Evaluation)
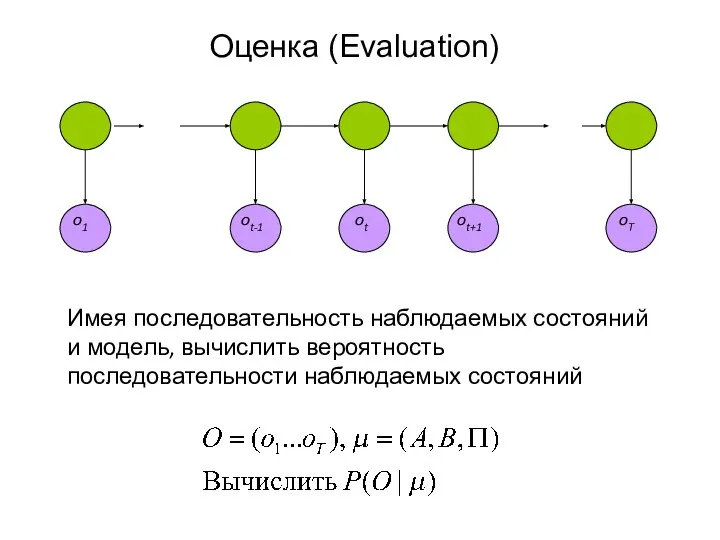
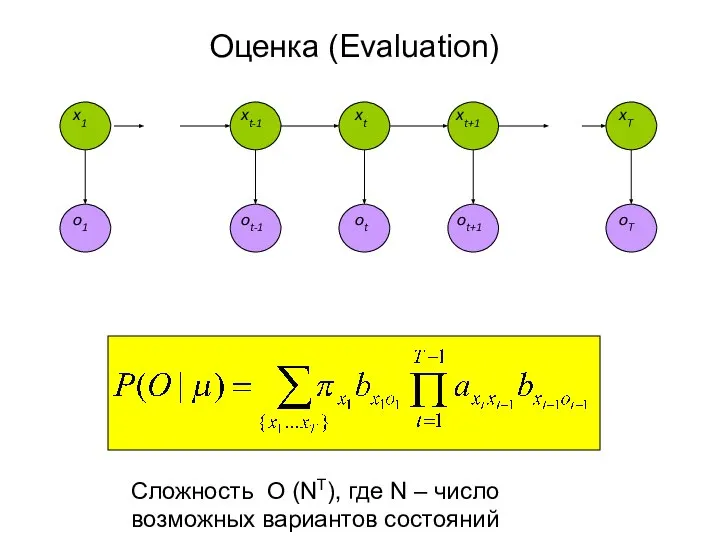
Слайд 18Оценка (Evaluation)
Сложность O (NT), где N – число возможных вариантов состояний
Оценка (Evaluation)
Сложность O (NT), где N – число возможных вариантов состояний
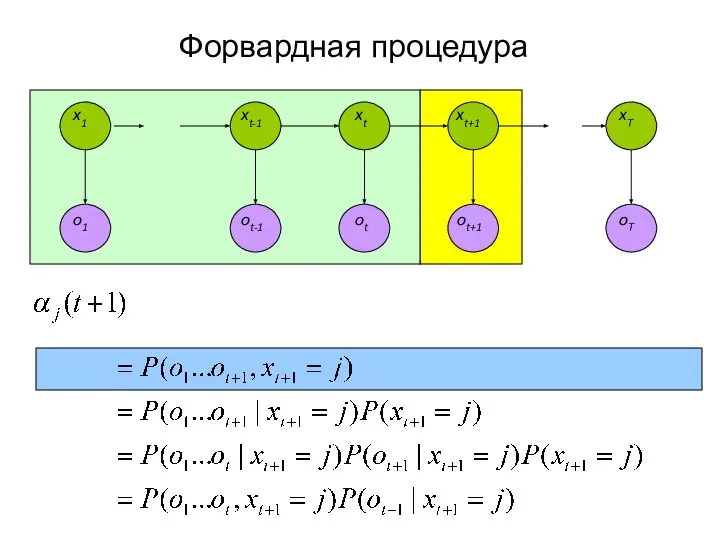
Слайд 19Форвардная процедура
Метод динамического программирования
Определим переменную:
Смысл переменной α: вероятность наблюдений o1, …ot и
Форвардная процедура
Метод динамического программирования
Определим переменную:
Смысл переменной α: вероятность наблюдений o1, …ot и

Слайд 20Форвардная процедура
Форвардная процедура
Слайд 21Форвардная процедура
Форвардная процедура
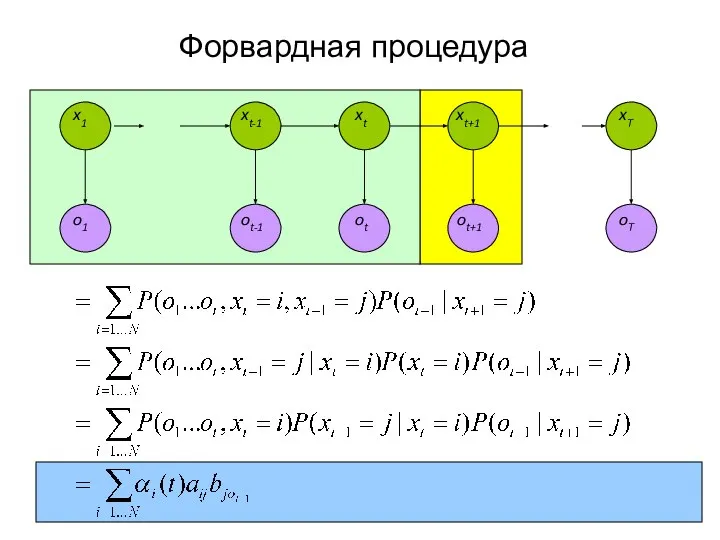
Слайд 22Вычисление вероятности последовательности
наблюдаемых событий
Можем эффективно вычислять
αT(I)=P(o1, o2,…oT, xT=i|μ)
Как вычислить
P(o1, o2,…oT |μ)?
Как
Вычисление вероятности последовательности
наблюдаемых событий
Можем эффективно вычислять
αT(I)=P(o1, o2,…oT, xT=i|μ)
Как вычислить
P(o1, o2,…oT |μ)?
Как

Слайд 23Вычисление вероятности последовательности
наблюдаемых событий
Можем эффективно вычислять
αT(i)=P(o1, o2,…oT, xT=i|μ)
Как вычислить
P(o1, o2,…oT |μ)
Вычисление вероятности последовательности
наблюдаемых событий
Можем эффективно вычислять
αT(i)=P(o1, o2,…oT, xT=i|μ)
Как вычислить
P(o1, o2,…oT |μ)

Слайд 24Форвардный алгоритм: пример
Форвардный алгоритм: пример
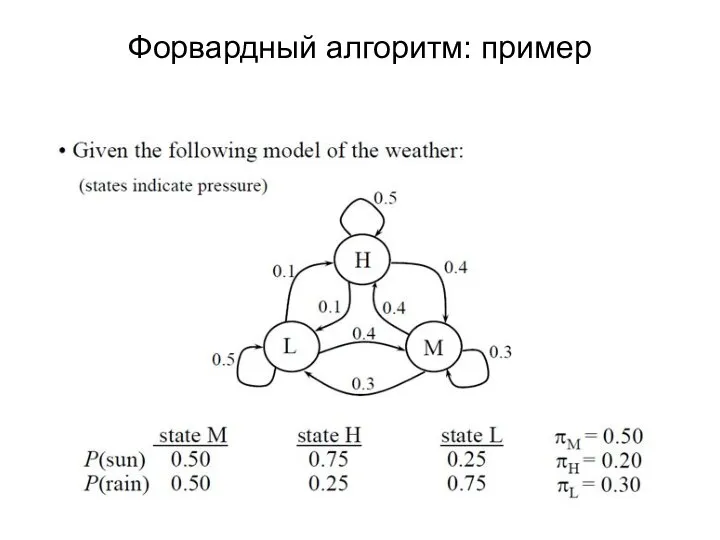
Слайд 25Форвардный алгоритм
Найти вероятность последовательности:
s r r s r (s- sun, r –
Форвардный алгоритм
Найти вероятность последовательности:
s r r s r (s- sun, r –



Слайд 28Декодирование
Вычислить вероятность последовательности наблюдаемых состояний (Evaluation)
Имея последовательность наблюдаемых состояний, вычислить наиболее вероятную
Декодирование
Вычислить вероятность последовательности наблюдаемых состояний (Evaluation)
Имея последовательность наблюдаемых состояний, вычислить наиболее вероятную
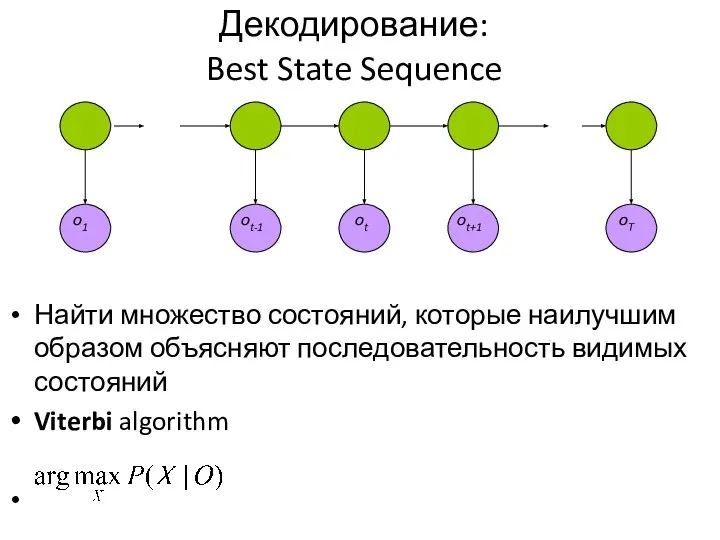
Слайд 29Декодирование:
Best State Sequence
Найти множество состояний, которые наилучшим образом объясняют последовательность видимых состояний
Viterbi
Декодирование:
Best State Sequence
Найти множество состояний, которые наилучшим образом объясняют последовательность видимых состояний
Viterbi
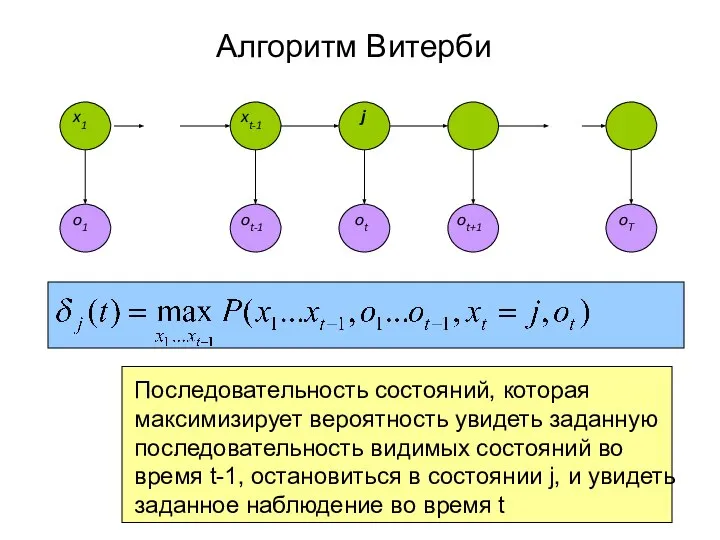
Слайд 30oT
o1
ot
ot-1
ot+1
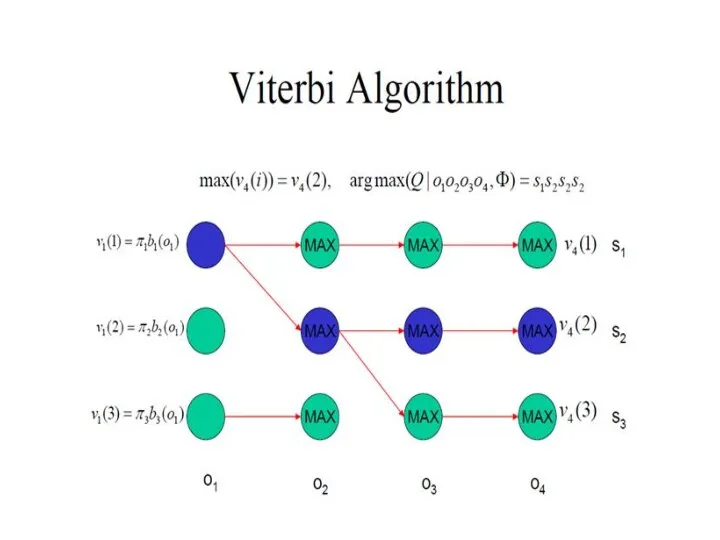
Алгоритм Витерби
Последовательность состояний, которая максимизирует вероятность увидеть заданную последовательность видимых состояний во
oT
o1
ot
ot-1
ot+1
Алгоритм Витерби
Последовательность состояний, которая максимизирует вероятность увидеть заданную последовательность видимых состояний во
Слайд 31Алгоритм Витерби
Рекурсивное
вычисление
x1
xt-1
xt
xt+1
Алгоритм Витерби
Рекурсивное
вычисление
x1
xt-1
xt
xt+1
Слайд 32Алгоритм Витерби
Вычисляем наиболее вероятную последовательность состояний, двигаясь назад
x1
xt-1
xt
xt+1
xT
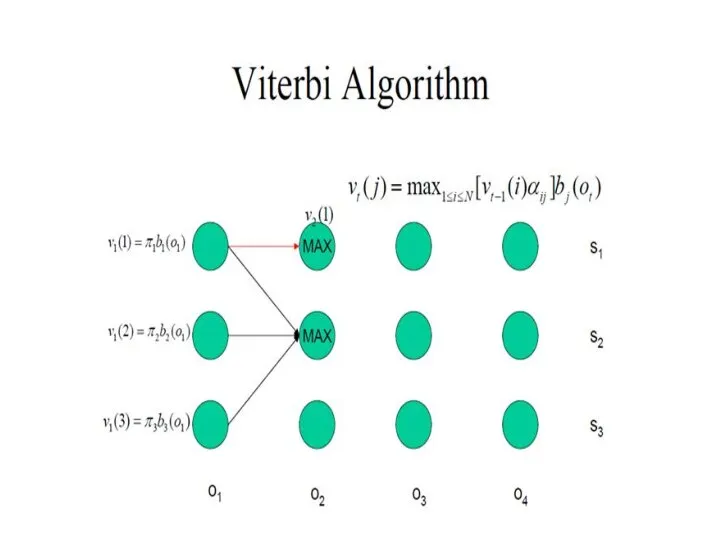
Алгоритм Витерби
Вычисляем наиболее вероятную последовательность состояний, двигаясь назад
x1
xt-1
xt
xt+1
xT


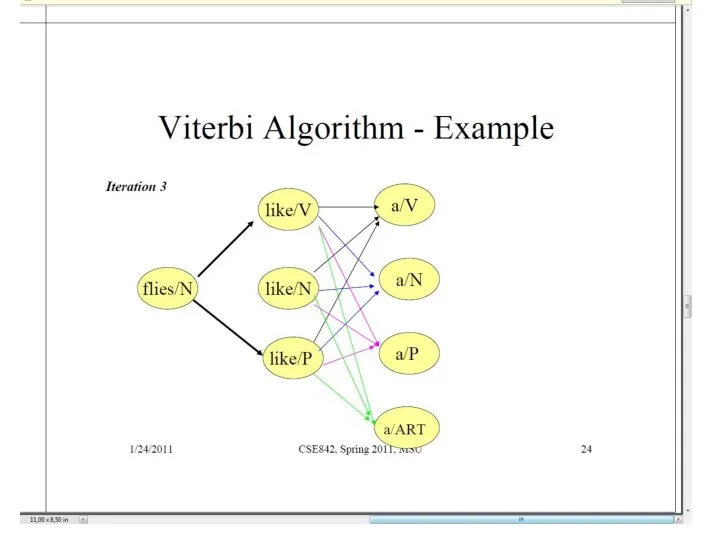
Слайд 39Тот же пример для алгоритма Витерби
Тот же пример для алгоритма Витерби
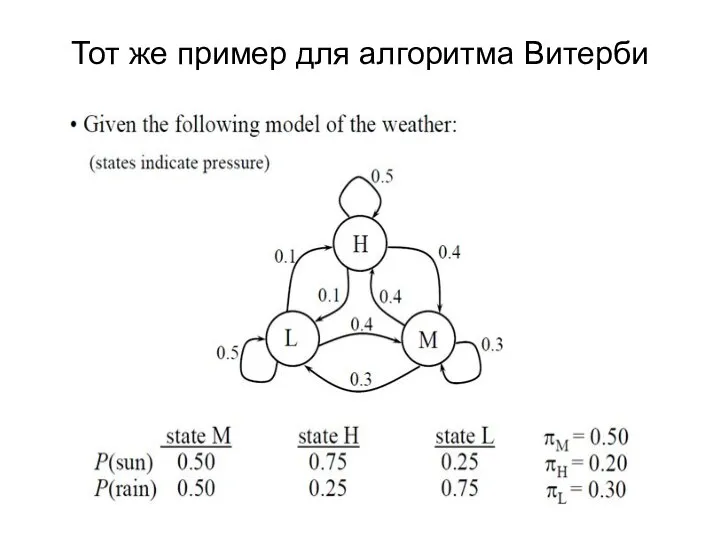
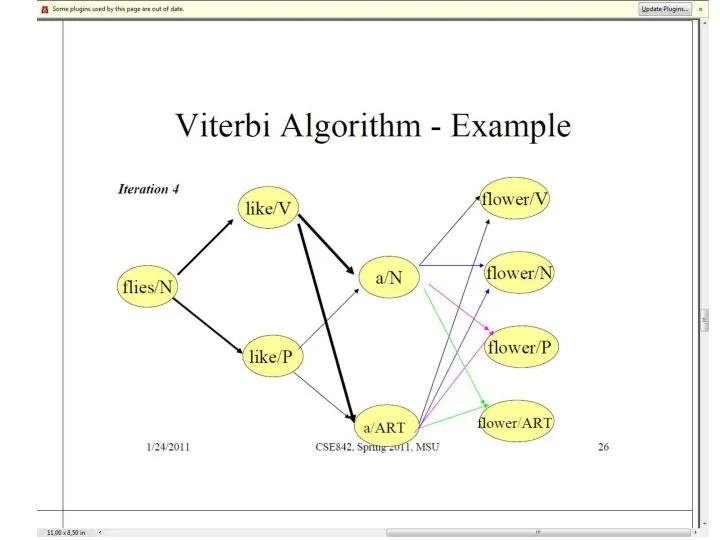
Слайд 40Пример: Алгоритм Витерби
Пример: Алгоритм Витерби

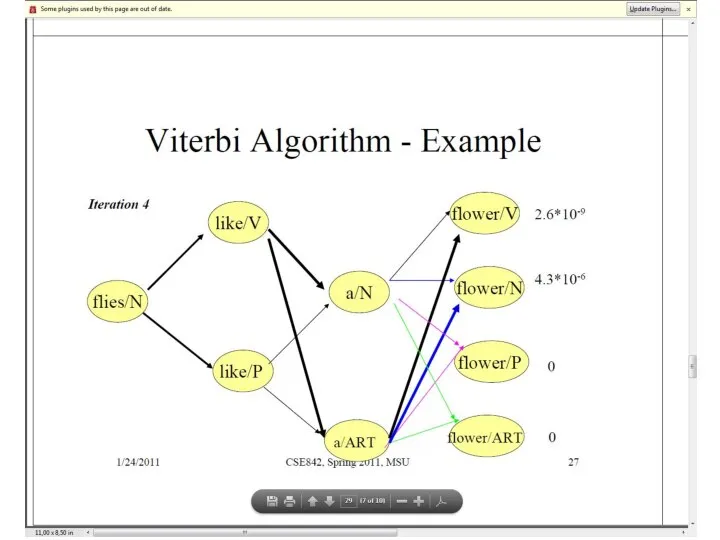
Слайд 41Пример. Алгоритм Витерби
Пример. Алгоритм Витерби

Слайд 42Применение HMM к POS-tagging
POS-tagging – морфологическая разметка
HMM tagger: выбирает наиболее вероятную последовательность
Применение HMM к POS-tagging
POS-tagging – морфологическая разметка
HMM tagger: выбирает наиболее вероятную последовательность

Слайд 43Пример: морфологическая неоднозначность
Пример: морфологическая неоднозначность

Слайд 44Откуда взять данные?
Из корпуса с морфологической разметкой
Русский язык:
Корпус русского языка
Открытый
Откуда взять данные?
Из корпуса с морфологической разметкой
Русский язык:
Корпус русского языка
Открытый

Слайд 45Фрагмент морфологической разметки в Национальном корпусе русского языка
Я сидел на барском сиденье,
Фрагмент морфологической разметки в Национальном корпусе русского языка
Я сидел на барском сиденье,

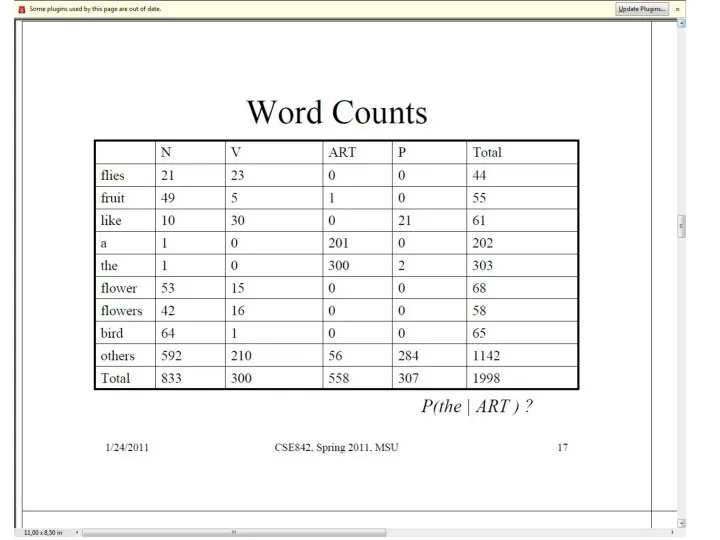
Слайд 46Данные для примера
Данные для примера








Слайд 59Лексические вероятности: уточнение
Мы считали p(w|t)
Но
Слово могло отсутствовать в корпусе или
Лексические вероятности: уточнение
Мы считали p(w|t)
Но
Слово могло отсутствовать в корпусе или

Слайд 60Лексические вероятности
~
p(t) – априорная вероятность метки
p(t|w) – вероятность метки для
Лексические вероятности
~
p(t) – априорная вероятность метки
p(t|w) – вероятность метки для

Слайд 61Словарь и лексические вероятности
Можно считать, что все словарные метки слова w входят
Словарь и лексические вероятности
Можно считать, что все словарные метки слова w входят

Слайд 62Анализ статистических алгоритмов снятия морфологической омонимии в русском языке
Егор Лакомкин
Иван Пузыревский
Дарья
Анализ статистических алгоритмов снятия морфологической омонимии в русском языке
Егор Лакомкин
Иван Пузыревский
Дарья

Слайд 63Разрешение морфологической неоднозначности в текстах на английском языке
Методы:
Как правило, статистические алгоритмы на
Разрешение морфологической неоднозначности в текстах на английском языке
Методы:
Как правило, статистические алгоритмы на

Слайд 64Особенности английского языка
Бедная морфология
морфологическая разметка фактически сводится к POS-теггингу
Фиксированный порядок слов
можно опираться
Особенности английского языка
Бедная морфология
морфологическая разметка фактически сводится к POS-теггингу
Фиксированный порядок слов
можно опираться

Слайд 65Задача исследования:
Проверить экспериментально, применимы ли статистические алгоритмы, основанные на марковских моделях, к
Задача исследования:
Проверить экспериментально, применимы ли статистические алгоритмы, основанные на марковских моделях, к

Слайд 66Алгоритмы
Набор скрытых величин Y (состояний модели = наборов грамматических тегов); составляют марковскую
Алгоритмы
Набор скрытых величин Y (состояний модели = наборов грамматических тегов); составляют марковскую

Слайд 67HMM
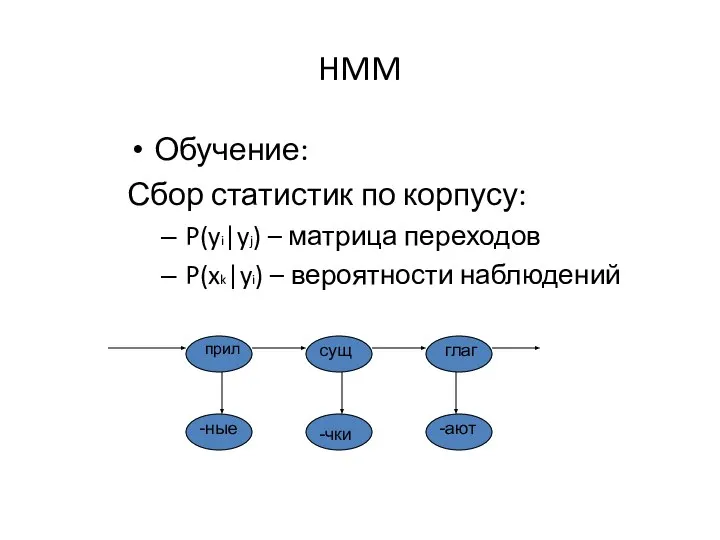
Обучение:
Сбор статистик по корпусу:
P(yi|yj) – матрица переходов
P(xk|yi) – вероятности наблюдений
сущ
прил
глаг
-ные
-чки
-ают
HMM
Обучение:
Сбор статистик по корпусу:
P(yi|yj) – матрица переходов
P(xk|yi) – вероятности наблюдений
сущ
прил
глаг
-ные
-чки
-ают
Слайд 68Задача алгоритмов:
Вычисление наиболее вероятной последовательности скрытых величин
Задача алгоритмов:
Вычисление наиболее вероятной последовательности скрытых величин

Слайд 69Деление выборки на обучающую и тестирующую:
Кросс-валидация (5 фолдов):
Деление выборки на 5 частей:
4
Деление выборки на обучающую и тестирующую:
Кросс-валидация (5 фолдов):
Деление выборки на 5 частей:
4

Слайд 70Оценка качества
Определение верхней и нижней границы:
Верхняя граница: процент случаев, когда среди гипотез
Оценка качества
Определение верхней и нижней границы:
Верхняя граница: процент случаев, когда среди гипотез

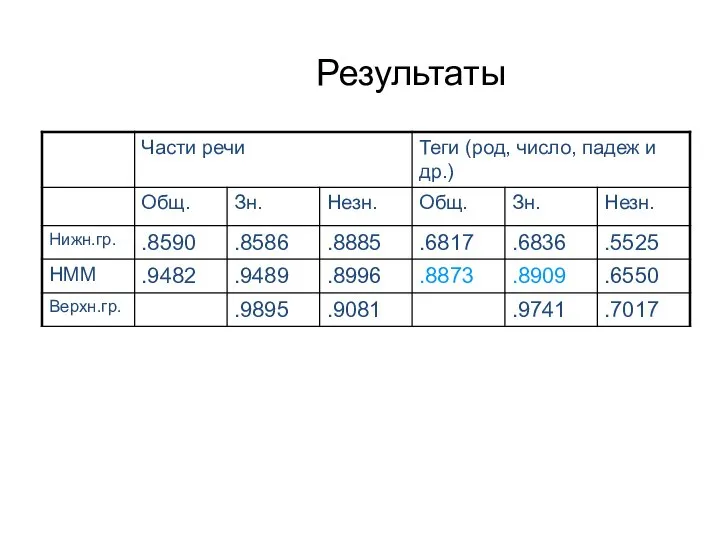
Слайд 71Результаты
Результаты
Слайд 72Выводы работы
POS-теггинг – на приличном уровне,
Разрешение неоднозначности по расширенным тегам –
Выводы работы
POS-теггинг – на приличном уровне,
Разрешение неоднозначности по расширенным тегам –

Слайд 73Проблемы HMM
Метки рассматриваются как единое целое, невозможно извлечь отдельные признаки
В русском языке:
Проблемы HMM
Метки рассматриваются как единое целое, невозможно извлечь отдельные признаки
В русском языке:

Слайд 74Как можно изменить процесс расчета переходов между состояниями?
HMM: учитываются два фактора в
Как можно изменить процесс расчета переходов между состояниями?
HMM: учитываются два фактора в

 ГМО
ГМО Современная Россия
Современная Россия История ЭВМ
История ЭВМ Защита для сварщиков Продакт-менеджер направления Средства Индивидуальной Защиты ГК «Восток-Сервис» Гуреев Михаил.
Защита для сварщиков Продакт-менеджер направления Средства Индивидуальной Защиты ГК «Восток-Сервис» Гуреев Михаил. Педагоги - организаторы
Педагоги - организаторы Презентация на тему Травмы глаз
Презентация на тему Травмы глаз  Команда: « Божья коровка» МАОУ СОШ №59 ДОШКОЛЬНОЕ ОТДЕЛЕНИЕ КОРПУС №2
Команда: « Божья коровка» МАОУ СОШ №59 ДОШКОЛЬНОЕ ОТДЕЛЕНИЕ КОРПУС №2 Международное движение капитала
Международное движение капитала  Who are the Amish?
Who are the Amish? Доверительное управление. Российские акции АО ИФК Солид
Доверительное управление. Российские акции АО ИФК Солид Семейные традиции
Семейные традиции Птицы на кормушке
Птицы на кормушке Массовая культура
Массовая культура Презентация на тему Взаимодействие людей в многонациональном обществе
Презентация на тему Взаимодействие людей в многонациональном обществе Business enviroment in Russia
Business enviroment in Russia Биосфера – глобальная экологическая система, ее границы
Биосфера – глобальная экологическая система, ее границы Агрессивность у детей дошкольного возраста
Агрессивность у детей дошкольного возраста Традиционная обувь бурят
Традиционная обувь бурят Устная и письменная речь
Устная и письменная речь Робота з базами даних
Робота з базами даних Образ дома в произведениях русских писателей
Образ дома в произведениях русских писателей Торговый и интернет-эквайринг
Торговый и интернет-эквайринг Строение животной клетки
Строение животной клетки Создание условий для духовно-нравственного развития и воспитания в современной школе
Создание условий для духовно-нравственного развития и воспитания в современной школе «Источники загрязнения Атмосферы»
«Источники загрязнения Атмосферы» Психология – удивительная наука
Психология – удивительная наука С днём ракетных войск и артиллерии
С днём ракетных войск и артиллерии Фотосинтетический аппарат у прокариот. Пигменты. Функциональные структуры
Фотосинтетический аппарат у прокариот. Пигменты. Функциональные структуры