- ИИМО ПИАШ 2022 Л02

Содержание
- 2. Пусть существуют два множества: Множество объектов – образов X Множество ответов Y Существует целевая функция значения
- 3. Модель алгоритма Требуется построить отображение (гипотезу) Пусть А – параметрическое семейство отображений Г – пространство допустимых
- 4. Замечание Гипотез, имеющих нулевой эмпирический риск может существовать неограниченное количество: Наиболее общая гипотеза Наиболее частная гипотеза
- 5. Эмпирический риск - обучающая выборка Эмпирический риск (ошибка тренировки): Метод минимизации эмпирического риска*: Таким образом задача
- 6. Обобщающая способность Обобщающая способность (generalization ability, generalization performance). Алгоритм обучения обладает способностью к обобщению, если вероятность
- 7. Основы теории вероятностей: Виды событий Достоверные события всегда происходят при осуществлении данной совокупности условий Невозможные события
- 8. Основы теории вероятностей: Случайные события Несовместными называются события, которые не могут одновременно произойти в одном испытании
- 9. Основы теории вероятностей: Случайные события Совместными называются события, которые могут одновременно произойти в одном испытании События
- 10. Основы теории вероятностей: Классическое определение вероятности Вероятностью события А называют отношение числа благоприятствующих этому событию элементарных
- 11. Статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём его сравнения с логистической кривой. Эта
- 12. Thomas Bayes (c. 1702 – April 17, 1761) Томас Байес Математические интересы Байеса относились к теории
- 13. Определение. Пусть Р(А)>0. Условной вероятностью Р(В/А) события В при условии, что событие А наступило, называется число
- 14. Независимые события Определение. События А и В называются независимыми, если Определение. Пусть Р(А)>0 и Р(В)>0. Событие
- 15. События образуют полную группу, если они 1) попарно несовместны 2) в результате эксперимента обязательно какое- либо
- 16. Формула полной вероятности Теорема. Если события образуют полную группу , то для любого события А справедлива
- 17. Формула Байеса Теорема. Пусть события образуют полную группу. Пусть событие А наступило ( Р(А)>0 ). Тогда
- 18. Формула Байеса. Частный случай Рассмотрим события они образуют полную группу. Пусть событие А наступило ( Р(А)>0
- 19. Пример: Какова вероятность увидеть на улице динозавра? Идя по улице вы видите такую сцену: Правдоподобие –
- 20. Пример: Какова вероятность увидеть на улице динозавра? Идя по улице вы видите такую сцену: Правдоподобие –
- 21. Вероятностная формулировка задачи машинного обучения Эмпирический риск: Общий риск: рассчитать невозможно требуется минимизировать Модель алгоритма и
- 22. Пример расчёта вероятности /45
- 23. Пример расчёта вероятности /45
- 24. Пример расчёта вероятности /45
- 25. Домашнее задание 1: Пример расчёта вероятности Пусть некий тест на какую-нибудь болезнь имеет вероятность успеха 95%
- 26. Наивный байесовский классификатор Предположения: Известна функция правдоподобия: Известны априорные вероятности: Принцип максимума апостериорной вероятности: Вероятность класса
- 27. Example. Play Tennis x=(Sunny, Cool, High, Strong) /45
- 28. Example. Learning. P(Play=Yes) = 9/14 P(Play=No) = 5/14 /45
- 29. Example.Test x=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(Outlook=Sunny|Play=No) = 3/5 P(Temperature=Cool|Play==No) = 1/5 P(Huminity=High|Play=No) = 4/5 P(Wind=Strong|Play=No) =
- 30. Особенности наивного байесовского классификатора Нужно знать функцию правдоподобия и априорные вероятности Отсутствуют априорные причины верить, что
- 31. Построение границы классов /45
- 32. Разбиение пространства, как задача классификации Задача классификации: определить вектор x в один из K классов Y
- 33. Разделение на несколько классов Классифицируем в Yk если соответствующий yk – максимален Можно рассмотреть поверхности вида
- 34. Задача линейной регрессии Нужно найти функцию, которая отображает зависимость одних переменных или данных от других. Зависимые
- 35. Задача линейной регрессии Через две точки на плоскости можно провести прямую и только одну А если
- 36. Scikit-learn Библиотека Scikit-learn — самый распространённый выбор для решения задач классического машинного обучения. Scikit-learn специализируется на
- 37. Scikit-learn Вход-выход (x-y) (зелёные круги) – результаты наблюдений. Оценочная функция регрессии (чёрная линия) выражается уравнением f(x)
- 38. Пример: Ирисы Фишера 150 цветков трех классов: Два параметра: длина чашелистика и длина лепестка. Два новых
- 39. Метод «k-ближайших соседей». Классификатор K-nearest neighbor – kNN Метод решения задачи классификации, который относит объекты к
- 40. 1-Nearest Neighbor /45
- 41. 3-Nearest Neighbor /45
- 42. Нормализация и вычисление расстояния Расстояние Махаланобиса Евклидово расстояние Предложено индийским статистиком Махаланобисом в 1936 году. С
- 43. Ирисы Фишера: Простое голосование Класс цветка 1: Iris Setosa /45
- 44. Ирисы Фишера: Простое голосование Класс цветка 2: Iris Virginica /45
- 46. Скачать презентацию
Слайд 2Пусть существуют два множества:
Множество объектов – образов X
Множество ответов Y
Существует целевая функция
значения
Пусть существуют два множества:
Множество объектов – образов X
Множество ответов Y
Существует целевая функция
значения

Слайд 3Модель алгоритма
Требуется построить отображение (гипотезу)
Пусть А – параметрическое семейство отображений
Г – пространство
Модель алгоритма
Требуется построить отображение (гипотезу)
Пусть А – параметрическое семейство отображений
Г – пространство

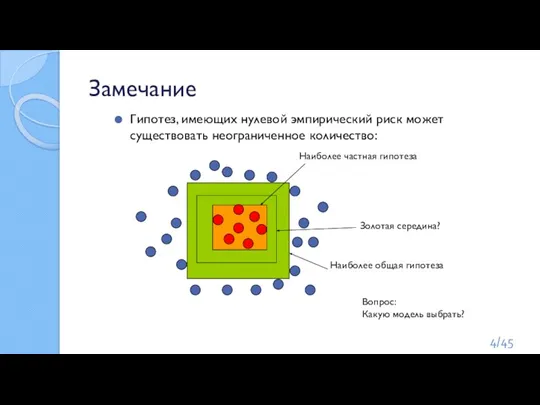
Слайд 4Замечание
Гипотез, имеющих нулевой эмпирический риск может существовать неограниченное количество:
Наиболее общая гипотеза
Наиболее частная
Замечание
Гипотез, имеющих нулевой эмпирический риск может существовать неограниченное количество:
Наиболее общая гипотеза
Наиболее частная
Слайд 5Эмпирический риск
- обучающая выборка
Эмпирический риск (ошибка тренировки):
Метод минимизации эмпирического риска*:
Таким образом
Эмпирический риск
- обучающая выборка
Эмпирический риск (ошибка тренировки):
Метод минимизации эмпирического риска*:
Таким образом

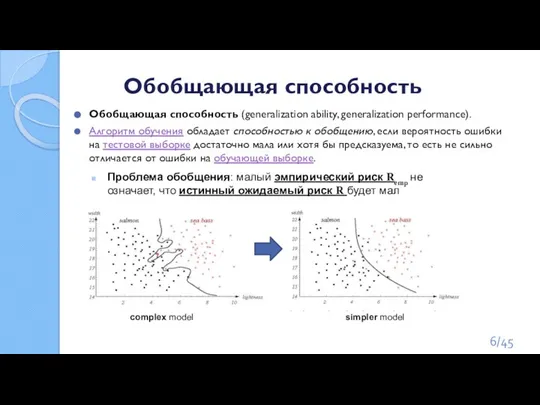
Слайд 6Обобщающая способность
Обобщающая способность (generalization ability, generalization performance).
Алгоритм обучения обладает способностью к обобщению, если вероятность
Обобщающая способность
Обобщающая способность (generalization ability, generalization performance).
Алгоритм обучения обладает способностью к обобщению, если вероятность
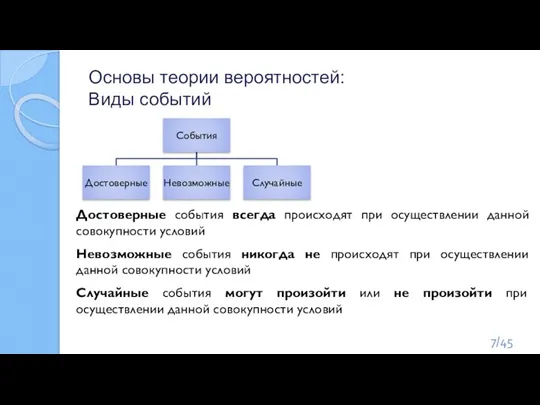
Слайд 7Основы теории вероятностей:
Виды событий
Достоверные события всегда происходят при осуществлении данной совокупности условий
Невозможные
Основы теории вероятностей:
Виды событий
Достоверные события всегда происходят при осуществлении данной совокупности условий
Невозможные
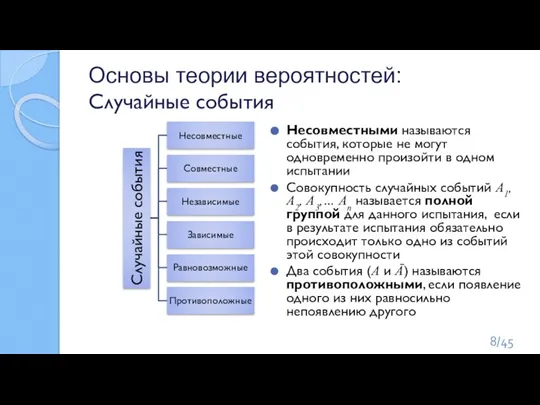
Слайд 8Основы теории вероятностей:
Случайные события
Несовместными называются события, которые не могут одновременно произойти в
Основы теории вероятностей:
Случайные события
Несовместными называются события, которые не могут одновременно произойти в
Слайд 9Основы теории вероятностей:
Случайные события
Совместными называются события, которые могут одновременно произойти в одном
Основы теории вероятностей:
Случайные события
Совместными называются события, которые могут одновременно произойти в одном
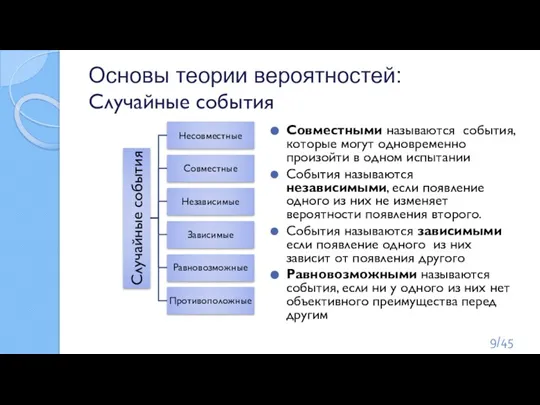
Слайд 10Основы теории вероятностей:
Классическое определение вероятности
Вероятностью события А называют отношение числа благоприятствующих этому
Основы теории вероятностей:
Классическое определение вероятности
Вероятностью события А называют отношение числа благоприятствующих этому

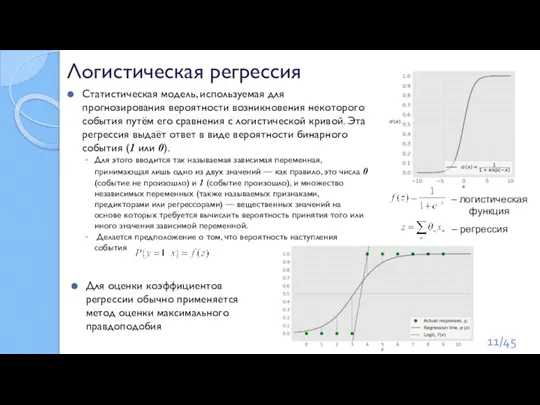
Слайд 11Статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём его сравнения
Статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём его сравнения
Слайд 12Thomas Bayes
(c. 1702 – April 17, 1761)
Томас Байес
Математические интересы Байеса относились
Thomas Bayes
(c. 1702 – April 17, 1761)
Томас Байес
Математические интересы Байеса относились

Слайд 13Определение.
Пусть Р(А)>0.
Условной вероятностью Р(В/А) события В при условии, что
событие А
Определение.
Пусть Р(А)>0.
Условной вероятностью Р(В/А) события В при условии, что
событие А

Слайд 14Независимые события
Определение.
События А и В называются независимыми, если
Определение. Пусть Р(А)>0 и Р(В)>0.
Независимые события
Определение.
События А и В называются независимыми, если
Определение. Пусть Р(А)>0 и Р(В)>0.

Слайд 15События образуют полную группу, если они
1) попарно несовместны
2) в результате
События образуют полную группу, если они
1) попарно несовместны
2) в результате

Слайд 16Формула полной вероятности
Теорема.
Если события
образуют полную группу ,
то для любого события А
Формула полной вероятности
Теорема.
Если события
образуют полную группу ,
то для любого события А

Слайд 17Формула Байеса
Теорема.
Пусть события
образуют полную группу.
Пусть событие А наступило ( Р(А)>0 ).
Тогда вероятность
Формула Байеса
Теорема.
Пусть события
образуют полную группу.
Пусть событие А наступило ( Р(А)>0 ).
Тогда вероятность

Слайд 18Формула Байеса. Частный случай
Рассмотрим события
они образуют полную группу.
Пусть событие А
Формула Байеса. Частный случай
Рассмотрим события
они образуют полную группу.
Пусть событие А

Слайд 19Пример:
Какова вероятность увидеть на улице динозавра?
Идя по улице вы видите такую сцену:
Правдоподобие
Пример:
Какова вероятность увидеть на улице динозавра?
Идя по улице вы видите такую сцену:
Правдоподобие

Слайд 20Пример:
Какова вероятность увидеть на улице динозавра?
Идя по улице вы видите такую сцену:
Правдоподобие
Пример:
Какова вероятность увидеть на улице динозавра?
Идя по улице вы видите такую сцену:
Правдоподобие

Слайд 21Вероятностная формулировка задачи машинного обучения
Эмпирический риск:
Общий риск:
рассчитать невозможно
требуется минимизировать
Модель алгоритма и метод
Вероятностная формулировка задачи машинного обучения
Эмпирический риск:
Общий риск:
рассчитать невозможно
требуется минимизировать
Модель алгоритма и метод

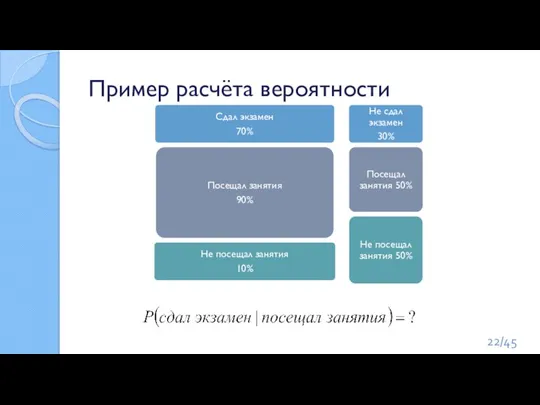
Слайд 22Пример расчёта вероятности
/45
Пример расчёта вероятности
/45
Слайд 23Пример расчёта вероятности
/45
Пример расчёта вероятности
/45

Слайд 24Пример расчёта вероятности
/45
Пример расчёта вероятности
/45

Слайд 25Домашнее задание 1:
Пример расчёта вероятности
Пусть некий тест на какую-нибудь болезнь имеет вероятность
Домашнее задание 1:
Пример расчёта вероятности
Пусть некий тест на какую-нибудь болезнь имеет вероятность

Слайд 26Наивный байесовский классификатор
Предположения:
Известна функция правдоподобия:
Известны априорные вероятности:
Принцип максимума апостериорной вероятности:
Вероятность класса
Вероятность наблюдения
Правдоподобие
Наивный байесовский классификатор
Предположения:
Известна функция правдоподобия:
Известны априорные вероятности:
Принцип максимума апостериорной вероятности:
Вероятность класса
Вероятность наблюдения
Правдоподобие

Слайд 27Example. Play Tennis
x=(Sunny, Cool, High, Strong)
/45
Example. Play Tennis
x=(Sunny, Cool, High, Strong)
/45

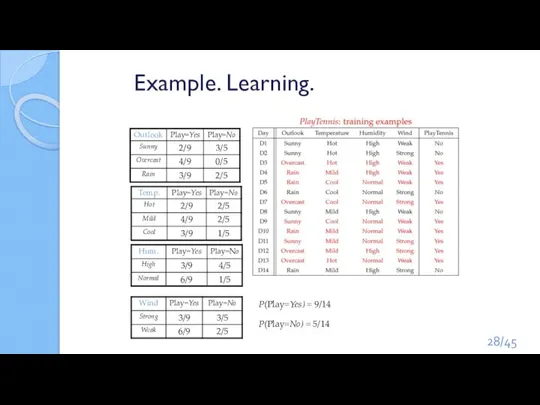
Слайд 28Example. Learning.
P(Play=Yes) = 9/14
P(Play=No) = 5/14
/45
Example. Learning.
P(Play=Yes) = 9/14
P(Play=No) = 5/14
/45
Слайд 29Example.Test
x=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong)
P(Outlook=Sunny|Play=No) = 3/5
P(Temperature=Cool|Play==No) = 1/5
P(Huminity=High|Play=No) = 4/5
P(Wind=Strong|Play=No) = 3/5
P(Play=No)
Example.Test
x=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong)
P(Outlook=Sunny|Play=No) = 3/5
P(Temperature=Cool|Play==No) = 1/5
P(Huminity=High|Play=No) = 4/5
P(Wind=Strong|Play=No) = 3/5
P(Play=No)

Слайд 30Особенности наивного байесовского классификатора
Нужно знать функцию правдоподобия и априорные вероятности
Отсутствуют априорные причины
Особенности наивного байесовского классификатора
Нужно знать функцию правдоподобия и априорные вероятности
Отсутствуют априорные причины

Слайд 31Построение границы классов
/45
Построение границы классов
/45
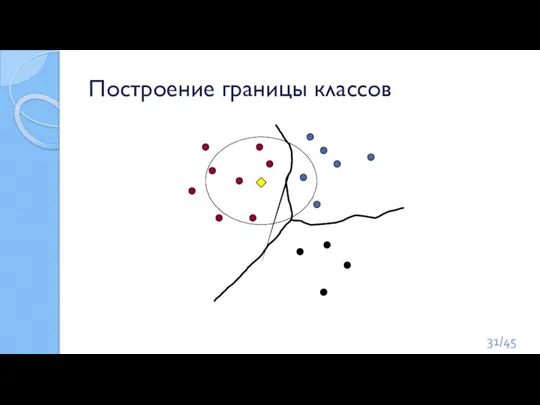
Слайд 32Разбиение пространства,
как задача классификации
Задача классификации: определить вектор x в один из
Разбиение пространства,
как задача классификации
Задача классификации: определить вектор x в один из

Слайд 33Разделение на несколько классов
Классифицируем в Yk если соответствующий yk – максимален
Можно рассмотреть
Разделение на несколько классов
Классифицируем в Yk если соответствующий yk – максимален
Можно рассмотреть

Слайд 34Задача линейной регрессии
Нужно найти функцию, которая отображает зависимость одних переменных или данных
Задача линейной регрессии
Нужно найти функцию, которая отображает зависимость одних переменных или данных

Слайд 35Задача линейной регрессии
Через две точки на плоскости можно провести прямую и только
Задача линейной регрессии
Через две точки на плоскости можно провести прямую и только

Слайд 36Scikit-learn
Библиотека Scikit-learn — самый распространённый выбор для решения задач классического машинного обучения.
Scikit-learn специализируется
Scikit-learn
Библиотека Scikit-learn — самый распространённый выбор для решения задач классического машинного обучения.
Scikit-learn специализируется

Слайд 37Scikit-learn
Вход-выход (x-y) (зелёные круги) – результаты наблюдений.
Оценочная функция регрессии (чёрная линия) выражается
Scikit-learn
Вход-выход (x-y) (зелёные круги) – результаты наблюдений.
Оценочная функция регрессии (чёрная линия) выражается

Слайд 38Пример: Ирисы Фишера
150 цветков трех классов:
Два параметра: длина чашелистика и длина лепестка.
Два
Пример: Ирисы Фишера
150 цветков трех классов:
Два параметра: длина чашелистика и длина лепестка.
Два
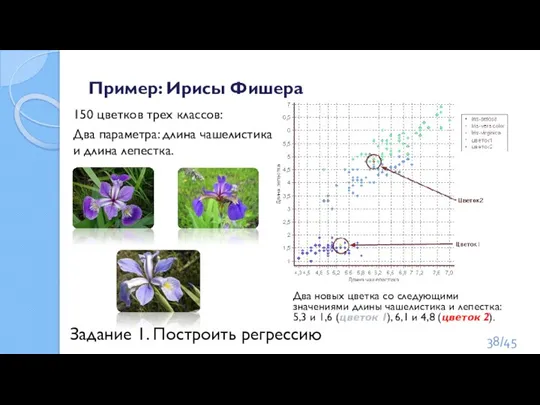
Слайд 39Метод «k-ближайших соседей». Классификатор
K-nearest neighbor – kNN
Метод решения задачи классификации, который относит
Метод «k-ближайших соседей». Классификатор
K-nearest neighbor – kNN
Метод решения задачи классификации, который относит

Слайд 401-Nearest Neighbor
/45
1-Nearest Neighbor
/45
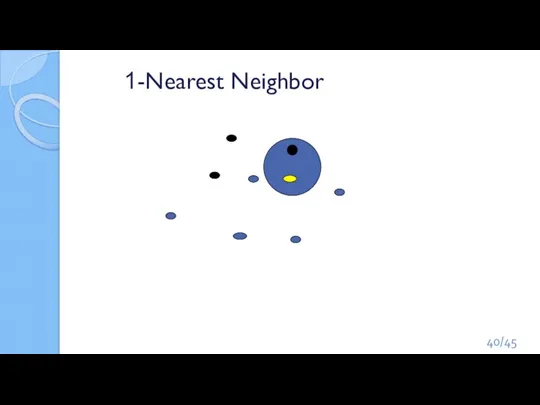
Слайд 413-Nearest Neighbor
/45
3-Nearest Neighbor
/45
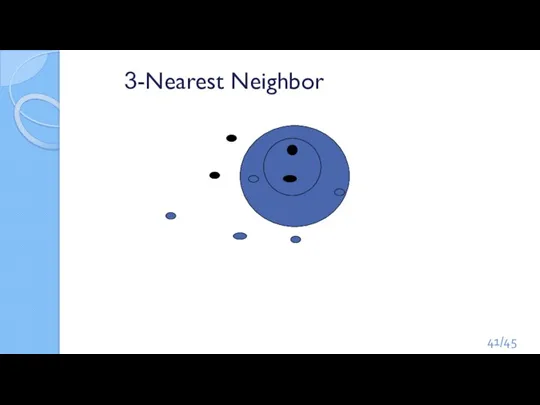
Слайд 42Нормализация и вычисление расстояния
Расстояние Махаланобиса
Евклидово расстояние
Предложено индийским статистиком Махаланобисом в 1936 году.
Нормализация и вычисление расстояния
Расстояние Махаланобиса
Евклидово расстояние
Предложено индийским статистиком Махаланобисом в 1936 году.

Слайд 43Ирисы Фишера: Простое голосование
Класс цветка 1: Iris Setosa
/45
Ирисы Фишера: Простое голосование
Класс цветка 1: Iris Setosa
/45

Слайд 44Ирисы Фишера: Простое голосование
Класс цветка 2: Iris Virginica
/45
Ирисы Фишера: Простое голосование
Класс цветка 2: Iris Virginica
/45

 Презентация нового продукта «Обзор заработных плат»
Презентация нового продукта «Обзор заработных плат» ПЛЮСЫ И МИНУСЫ, ПОЛОЖИТЕЛЬНОЕ И ОТРИЦАТЕЛЬНОЕ В МАТЕМАТИКЕ И В ЖИЗНИ
ПЛЮСЫ И МИНУСЫ, ПОЛОЖИТЕЛЬНОЕ И ОТРИЦАТЕЛЬНОЕ В МАТЕМАТИКЕ И В ЖИЗНИ Фриденсрайх Хундертвассер
Фриденсрайх Хундертвассер Аналоговые и цифровые сигналы
Аналоговые и цифровые сигналы Право для школьников
Право для школьников 6b8c575b324073cbf02a3d966912b4c92047c6ed — копия
6b8c575b324073cbf02a3d966912b4c92047c6ed — копия Реклама ВКонтакте
Реклама ВКонтакте В поход всей семьей – это здорово! Семейный выходной
В поход всей семьей – это здорово! Семейный выходной Акцизы с 1 января 2009 года
Акцизы с 1 января 2009 года Презентация на тему: Оценка качества предоставляемых образовательных услуг
Презентация на тему: Оценка качества предоставляемых образовательных услуг Презентация на тему Средства для борьбы с насекомыми
Презентация на тему Средства для борьбы с насекомыми Презентация на тему Классическая теория экономического риска
Презентация на тему Классическая теория экономического риска  Луна
Луна Обучающая интерактивная игра на тематику Управление проектами
Обучающая интерактивная игра на тематику Управление проектами Пришкольный лагерь "Солнышко"
Пришкольный лагерь "Солнышко" Управление комплексом маркетинговых коммуникаций
Управление комплексом маркетинговых коммуникаций Информационная безопасность
Информационная безопасность НОВОСТИ ЕГЭ
НОВОСТИ ЕГЭ О чем идет речь - Об оценке деятельности подразделения Единица оценки – подразделение Оценка работы сотрудника – не включаетс
О чем идет речь - Об оценке деятельности подразделения Единица оценки – подразделение Оценка работы сотрудника – не включаетс Физика в музыке
Физика в музыке LFood. Сэндвичи
LFood. Сэндвичи Сложение сил, действующих вдоль одной прямой. Равнодействующая
Сложение сил, действующих вдоль одной прямой. Равнодействующая «Мастерская чтения – идеи, проекты, воплощения»
«Мастерская чтения – идеи, проекты, воплощения» Использование Интернет-тренажеров при подготовке студентов к аккредитационному тестированию Сайт www.i-exam.ru
Использование Интернет-тренажеров при подготовке студентов к аккредитационному тестированию Сайт www.i-exam.ru Куликовская битва
Куликовская битва Архитектурные стили Петербурга
Архитектурные стили Петербурга Модернизация ЛВС в рамках создания регионального фрагмента единой государственной информационной системы в сфере здравоохране
Модернизация ЛВС в рамках создания регионального фрагмента единой государственной информационной системы в сфере здравоохране 3 Ховайло ВВ - Презентация проекта на открытие - СОГЛ (С) 20.10
3 Ховайло ВВ - Презентация проекта на открытие - СОГЛ (С) 20.10