- Индексирование текста для поиска с учетом орфографических ошибок

Содержание
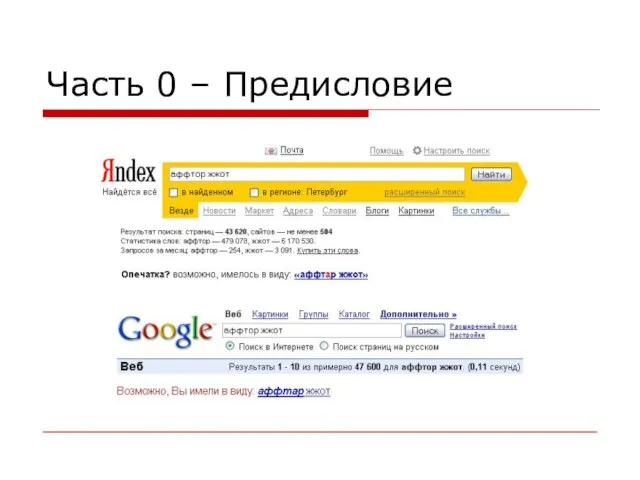
- 2. Часть 0 – Предисловие
- 3. Часть I - Введение Область применения Постановка задачи Примеры Имеющиеся результаты
- 4. Область применения Необходимость поиска с учетом ошибок: Поиск документов в Интернете Автоматическое исправление орфографических ошибок Вычислительная
- 5. Постановка задачи (1) Коллекция документов Т суммарного размера n Образец P длины m Предполагается не более
- 6. Постановка задачи (2) Требуется найти Все вхождения Все начальные позиции вхождений Все документы, содержащие образец
- 7. Пример Документы: GACTCAAAACGGGTGC GTGACCGACGGATGAC CCTACAAACATGTTCG TAAACCTGAGACCAAC Образец: ACAAC Разрешенное число ошибок: d = 1
- 8. Пример Документы: GACTCAAAACGGGTGC GTGACCGACGGATGAC CCTACAAACATGTTCG TAAACCTGAGACCAAC Образец: ACAAC Разрешенное число ошибок: d = 1 Различные вхождения:
- 9. Пример Документы: GACTCAAAACGGGTGC GTGACCGACGGATGAC CCTACAAACATGTTCG TAAACCTGAGACCAAC Образец: ACAAC Разрешенное число ошибок: d = 1 Начальные позиции
- 10. Пример Документы: GACTCAAAACGGGTGC GTGACCGACGGATGAC CCTACAAACATGTTCG TAAACCTGAGACCAAC Образец: ACAAC Разрешенное число ошибок: d = 1 Документы, содержащие
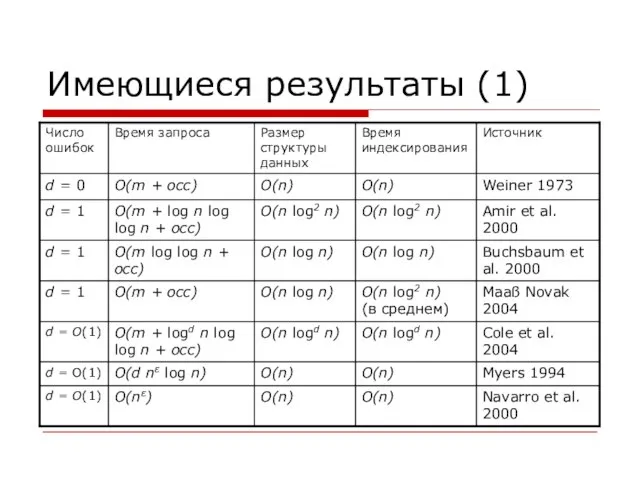
- 11. Имеющиеся результаты (1)
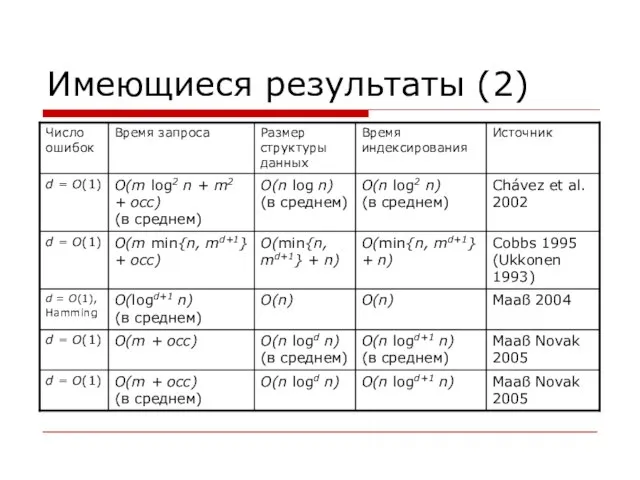
- 12. Имеющиеся результаты (2)
- 13. Часть II – Необходимые знания Расстояние Левенштейна Функция minpref Бор Сжатый бор l-слабый бор Интервальные запросы
- 14. Расстояние Левенштейна d(u,v) = наименьшее количество операций редактирования, необходимое, чтобы перевести u в v. Вычисляется методом
- 15. Расстояние Левенштейна (2) Пример: d(”АВТОР”, ”АФФТАР”) = 3 АВТОР АФТОР АФФТОР АФФТАР За время O((|u|+|v|)*k) можно
- 16. Функция minprefu(v) minprefu(v) = min l: d(prefl(u),prefl+|u|-|v|(v)) = d(u,v) suffl+1(u) = suffl+|u|-|v|+1(v) Пример: minpref”АВТОР”(”АФФТАР”) = 4
- 17. Лемма о minpref Пусть d(u,v)=k Обозначим за u(i) строку u после i из k операций редактирования
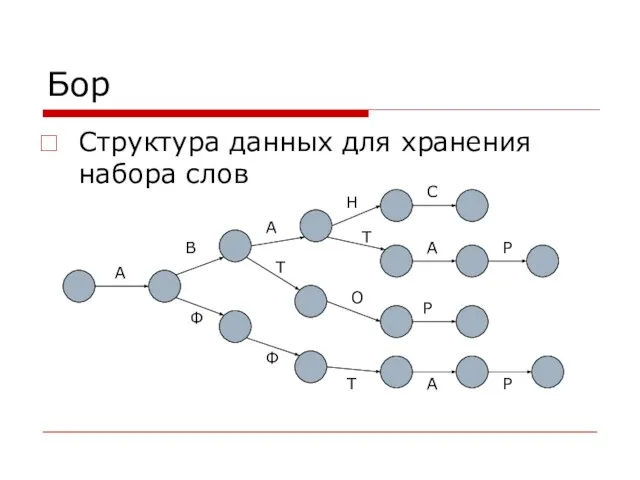
- 18. Бор Структура данных для хранения набора слов А В А Н С Т О Р А
- 19. Сжатый бор Структура данных для хранения набора слов А В А НС ТОР ТАР ФФТАР
- 20. l-слабый бор Вершины глубины менее l имеют структуру сжатого бора После l-го уровня – никакого ветвления
- 21. Интервальные запросы Дан массив A длины n с целыми числами. Поступают запросы про числа в позициях
- 22. Интервальные запросы (2) RMQ – Range Minimum Query Запрос (i, j) – найти индекc l, такой
- 23. Интервальные запросы (3) BVRQ – Bounded Value Range Query Запрос (i, j, k) – найти множество
- 24. Часть III – Алгоритм Маасса-Новака Подход Маасса-Новака Случай d = 1 Общий случай Оценка времени поиска
- 25. Подход Маасса-Новака Старый подход №1: Выберем строку s из T. За время O(|P|d) можно сравнить ее
- 26. Подход Маасса-Новака Чем плохи старые подходы? Старый подход №1: Перебор всех строк из T - ВРЕМЯ
- 27. Подход Маасса-Новака Иногда: обнаружим один подходящий вариант и проверим его за O(|P|). Иногда: будем искать P
- 28. Случай d = 1 Пусть S – сжатый бор, содержащий все подстроки Т, h0 – высота
- 29. Случай d = 1 minprefs(P) > h0 Ищем P в боре S Доходим до листа Сверяем
- 30. Случай d = 1 minprefs(P) ≤ h0 Предподсчитаем все строки, отличающиеся от строк из T ровно
- 31. Общий случай Пусть P совпадает некоторой строкой s из S с d ошибками Если prefh0(P)=prefh0(s), дойдем
- 32. Общий случай (2) Снова два случая: minprefs(r)>h1 Дойдем в боре S’ до соответствующего листа, далее ”старый
- 33. Оценка времени поиска В боре не оказалось строки P O(m) Пройдя бор, мы дошли до листа
- 34. Оценка времени поиска (2) При обходе бора кончилась строка P O(m + occ) Итого: O(m +
- 35. Оценка времени индексирования Суммарный размер вспомогательных боров: O(h0h1…hd-1|S|) Время построения индекса: O(h0h1…hd|S|) hi=O(log n) В среднем
- 36. Использование интервальных запросов Необходимо за время O(occ) находить все первые позиции вхождений все документы, содержащие образец
- 37. Использование интервальных запросов (2) СRQ сводится к BVRQ Заведем массив B: B[i] = предыдущая позиция в
- 38. Использование интервальных запросов (3) BVRQ решается за время сведением к RMQ: Запрос (2,7,6): 2 4 4
- 40. Скачать презентацию
Слайд 3Часть I - Введение
Область применения
Постановка задачи
Примеры
Имеющиеся результаты
Часть I - Введение
Область применения
Постановка задачи
Примеры
Имеющиеся результаты

Слайд 4Область применения
Необходимость поиска с учетом ошибок:
Поиск документов в Интернете
Автоматическое исправление орфографических ошибок
Вычислительная
Область применения
Необходимость поиска с учетом ошибок:
Поиск документов в Интернете
Автоматическое исправление орфографических ошибок
Вычислительная

Слайд 5Постановка задачи (1)
Коллекция документов Т суммарного размера n
Образец P длины m
Предполагается не
Постановка задачи (1)
Коллекция документов Т суммарного размера n
Образец P длины m
Предполагается не

Слайд 6Постановка задачи (2)
Требуется найти
Все вхождения
Все начальные позиции вхождений
Все документы, содержащие образец
Постановка задачи (2)
Требуется найти
Все вхождения
Все начальные позиции вхождений
Все документы, содержащие образец

Слайд 7Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1
Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1

Слайд 8Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1
Различные вхождения:
1-й документ: (6, 10), (7,
Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1
Различные вхождения: 1-й документ: (6, 10), (7,

Слайд 9Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1
Начальные позиции вхождений:
1-й документ: 6, 7
3-й
Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1
Начальные позиции вхождений: 1-й документ: 6, 7 3-й

Слайд 10Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1
Документы, содержащие образец:
1, 3, 4
Пример
Документы:
GACTCAAAACGGGTGC
GTGACCGACGGATGAC
CCTACAAACATGTTCG
TAAACCTGAGACCAAC
Образец: ACAAC
Разрешенное число ошибок: d = 1
Документы, содержащие образец:
1, 3, 4

Слайд 11Имеющиеся результаты (1)
Имеющиеся результаты (1)
Слайд 12Имеющиеся результаты (2)
Имеющиеся результаты (2)
Слайд 13Часть II – Необходимые знания
Расстояние Левенштейна
Функция minpref
Бор
Сжатый бор
l-слабый бор
Интервальные запросы
Часть II – Необходимые знания
Расстояние Левенштейна
Функция minpref
Бор
Сжатый бор
l-слабый бор
Интервальные запросы

Слайд 14Расстояние Левенштейна
d(u,v) = наименьшее количество операций редактирования, необходимое, чтобы перевести u в
Расстояние Левенштейна
d(u,v) = наименьшее количество операций редактирования, необходимое, чтобы перевести u в

Слайд 15Расстояние Левенштейна (2)
Пример:
d(”АВТОР”, ”АФФТАР”) = 3
АВТОР
АФТОР
АФФТОР
АФФТАР
За время O((|u|+|v|)*k) можно найти min(d(u,v),k) [Укконен
Расстояние Левенштейна (2)
Пример:
d(”АВТОР”, ”АФФТАР”) = 3
АВТОР
АФТОР
АФФТОР
АФФТАР
За время O((|u|+|v|)*k) можно найти min(d(u,v),k) [Укконен

Слайд 16Функция minprefu(v)
minprefu(v) = min l:
d(prefl(u),prefl+|u|-|v|(v)) = d(u,v)
suffl+1(u) = suffl+|u|-|v|+1(v)
Пример:
minpref”АВТОР”(”АФФТАР”) = 4
AВТО●Р
AФФТА●Р
d(”АВТО”,”АФФТА”)=3
Функция minprefu(v)
minprefu(v) = min l:
d(prefl(u),prefl+|u|-|v|(v)) = d(u,v)
suffl+1(u) = suffl+|u|-|v|+1(v)
Пример:
minpref”АВТОР”(”АФФТАР”) = 4
AВТО●Р
AФФТА●Р
d(”АВТО”,”АФФТА”)=3

Слайд 17Лемма о minpref
Пусть d(u,v)=k
Обозначим за u(i) строку u после i из k
Лемма о minpref
Пусть d(u,v)=k
Обозначим за u(i) строку u после i из k

Слайд 18Бор
Структура данных для хранения набора слов
А
В
А
Н
С
Т
О
Р
А
Т
Р
А
Т
Р
Ф
Ф
Бор
Структура данных для хранения набора слов
А
В
А
Н
С
Т
О
Р
А
Т
Р
А
Т
Р
Ф
Ф
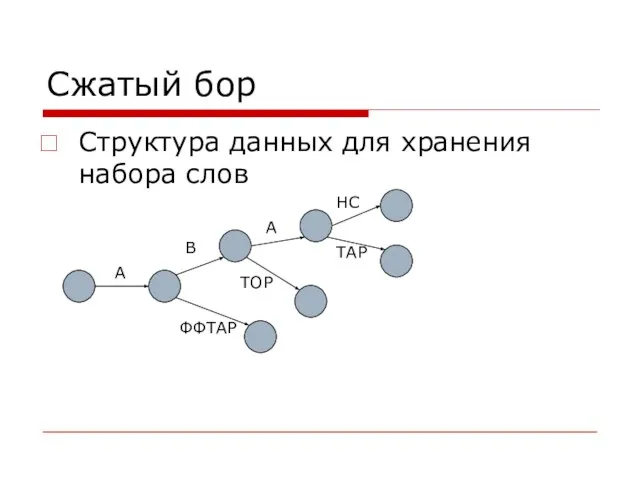
Слайд 19Сжатый бор
Структура данных для хранения набора слов
А
В
А
НС
ТОР
ТАР
ФФТАР
Сжатый бор
Структура данных для хранения набора слов
А
В
А
НС
ТОР
ТАР
ФФТАР
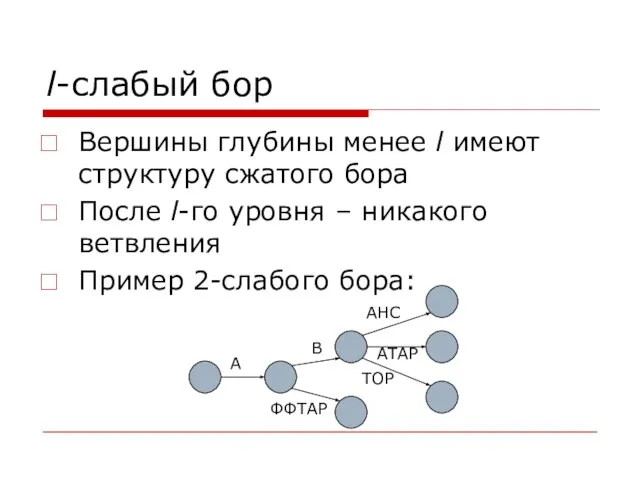
Слайд 20l-слабый бор
Вершины глубины менее l имеют структуру сжатого бора
После l-го уровня –
l-слабый бор
Вершины глубины менее l имеют структуру сжатого бора
После l-го уровня –
Слайд 21Интервальные запросы
Дан массив A длины n с целыми числами.
Поступают запросы про числа
Интервальные запросы
Дан массив A длины n с целыми числами.
Поступают запросы про числа

Слайд 22Интервальные запросы (2)
RMQ – Range Minimum Query
Запрос (i, j) – найти индекc
Интервальные запросы (2)
RMQ – Range Minimum Query
Запрос (i, j) – найти индекc

Слайд 23Интервальные запросы (3)
BVRQ – Bounded Value Range Query
Запрос (i, j, k) –
Интервальные запросы (3)
BVRQ – Bounded Value Range Query
Запрос (i, j, k) –

Слайд 24Часть III – Алгоритм Маасса-Новака
Подход Маасса-Новака
Случай d = 1
Общий случай
Оценка времени поиска
Оценка
Часть III – Алгоритм Маасса-Новака
Подход Маасса-Новака
Случай d = 1
Общий случай
Оценка времени поиска
Оценка

Слайд 25Подход Маасса-Новака
Старый подход №1:
Выберем строку s из T. За время O(|P|d) можно
Подход Маасса-Новака
Старый подход №1:
Выберем строку s из T. За время O(|P|d) можно

Слайд 26Подход Маасса-Новака
Чем плохи старые подходы?
Старый подход №1:
Перебор всех строк из T -
Подход Маасса-Новака
Чем плохи старые подходы?
Старый подход №1:
Перебор всех строк из T -

Слайд 27Подход Маасса-Новака
Иногда: обнаружим один подходящий вариант и проверим его за O(|P|).
Иногда: будем
Подход Маасса-Новака
Иногда: обнаружим один подходящий вариант и проверим его за O(|P|).
Иногда: будем

Слайд 28Случай d = 1
Пусть S – сжатый бор, содержащий все подстроки Т,
Случай d = 1
Пусть S – сжатый бор, содержащий все подстроки Т,

Слайд 29Случай d = 1
minprefs(P) > h0
Ищем P в боре S
Доходим до листа
Сверяем
Случай d = 1
minprefs(P) > h0
Ищем P в боре S
Доходим до листа
Сверяем

Слайд 30Случай d = 1
minprefs(P) ≤ h0
Предподсчитаем все строки, отличающиеся от строк из
Случай d = 1
minprefs(P) ≤ h0
Предподсчитаем все строки, отличающиеся от строк из

Слайд 31Общий случай
Пусть P совпадает некоторой строкой s из S с d ошибками
Если
Общий случай
Пусть P совпадает некоторой строкой s из S с d ошибками
Если

Слайд 32Общий случай (2)
Снова два случая:
minprefs(r)>h1
Дойдем в боре S’ до соответствующего листа, далее
Общий случай (2)
Снова два случая:
minprefs(r)>h1
Дойдем в боре S’ до соответствующего листа, далее

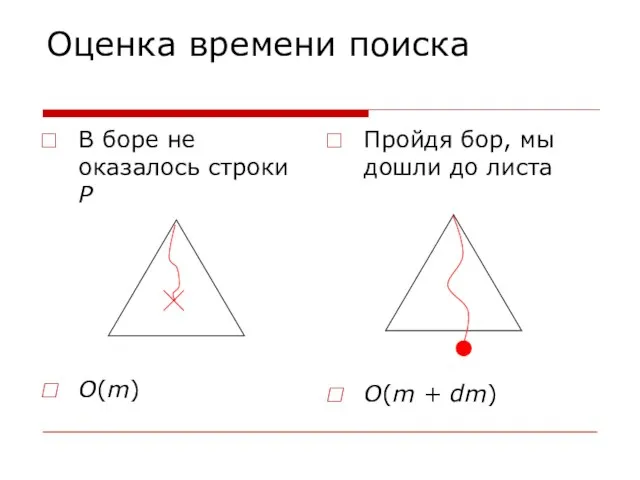
Слайд 33Оценка времени поиска
В боре не оказалось строки P
O(m)
Пройдя бор, мы дошли до
Оценка времени поиска
В боре не оказалось строки P
O(m)
Пройдя бор, мы дошли до
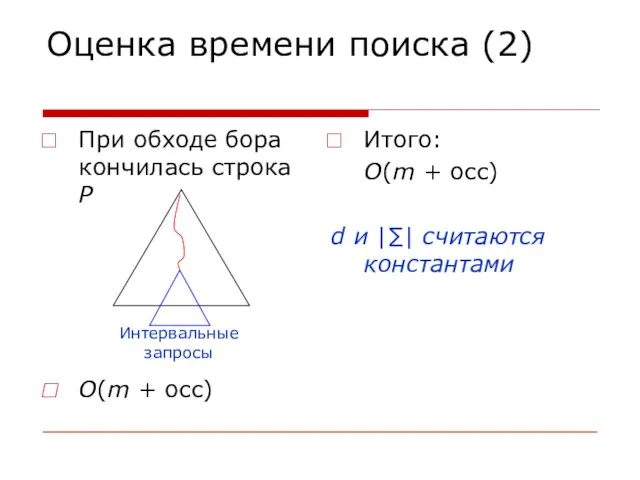
Слайд 34Оценка времени поиска (2)
При обходе бора кончилась строка P
O(m + occ)
Итого:
O(m
Оценка времени поиска (2)
При обходе бора кончилась строка P
O(m + occ)
Итого:
O(m
Слайд 35Оценка времени индексирования
Суммарный размер вспомогательных боров:
O(h0h1…hd-1|S|)
Время построения индекса:
O(h0h1…hd|S|)
hi=O(log n)
В среднем
С высокой вероятностью
Доказано
Оценка времени индексирования
Суммарный размер вспомогательных боров:
O(h0h1…hd-1|S|)
Время построения индекса:
O(h0h1…hd|S|)
hi=O(log n)
В среднем
С высокой вероятностью
Доказано

Слайд 36Использование интервальных запросов
Необходимо за время O(occ) находить
все первые позиции вхождений
все документы, содержащие
Использование интервальных запросов
Необходимо за время O(occ) находить
все первые позиции вхождений
все документы, содержащие

Слайд 37Использование интервальных запросов (2)
СRQ сводится к BVRQ
Заведем массив B:
B[i] = предыдущая позиция
Использование интервальных запросов (2)
СRQ сводится к BVRQ
Заведем массив B:
B[i] = предыдущая позиция
![Использование интервальных запросов (2) СRQ сводится к BVRQ Заведем массив B: B[i]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/387389/slide-36.jpg)
Слайд 38Использование интервальных запросов (3)
BVRQ решается за время сведением к RMQ:
Запрос (2,7,6):
2
4
4
Использование интервальных запросов (3)
BVRQ решается за время 2 4 4
Запрос (2,7,6):

 Реклама - двигатель торговли
Реклама - двигатель торговли ИНТЕЛЛЕКТУАЛЬНАЯ ИГРА«АШКИ ИЛИ ГЭШКИ?»
ИНТЕЛЛЕКТУАЛЬНАЯ ИГРА«АШКИ ИЛИ ГЭШКИ?» Забастовка. Право на забастовку
Забастовка. Право на забастовку Какой бывает транспорт
Какой бывает транспорт Построение осей складок
Построение осей складок Kimono shop
Kimono shop Открытие Show-room РуДа в ТРЦ
Открытие Show-room РуДа в ТРЦ Решение задач на сложение и вычитание смешанных чисел
Решение задач на сложение и вычитание смешанных чисел Критерии деятельности классных руководителей начального звена за 2 полугодие
Критерии деятельности классных руководителей начального звена за 2 полугодие Презентация на тему Решение логарифмических уравнений
Презентация на тему Решение логарифмических уравнений Преподаватель: Жирнова Н.Ю. ОБ УЧАСТИИ ВО ВСЕРОССИЙСКИХ ПЕДАГОГИЧЕСКИХ КОНКУРСАХ.
Преподаватель: Жирнова Н.Ю. ОБ УЧАСТИИ ВО ВСЕРОССИЙСКИХ ПЕДАГОГИЧЕСКИХ КОНКУРСАХ. Яңы йыл байрамы
Яңы йыл байрамы Осциллограф H3015
Осциллограф H3015 Хранение и распределение нефти, нефтепродуктов и газа
Хранение и распределение нефти, нефтепродуктов и газа Кузмицкий Василий Федорович
Кузмицкий Василий Федорович Интересная физика
Интересная физика Как древние люди представляли себе Вселенную
Как древние люди представляли себе Вселенную Школа творческих открытий Русский авангард для детей. Контраст Встреча противоположностей
Школа творческих открытий Русский авангард для детей. Контраст Встреча противоположностей Вознекновение театрв 18 веке
Вознекновение театрв 18 веке История российского парламентаризма
История российского парламентаризма Группа в VKontakte Сообщество инфобизнесменов, проект ИнфоХит
Группа в VKontakte Сообщество инфобизнесменов, проект ИнфоХит Концепция «Единого окна»: ключевой инструмент упрощения процедур торговли и надлежащего управления Марио Апостолов, Р
Концепция «Единого окна»: ключевой инструмент упрощения процедур торговли и надлежащего управления Марио Апостолов, Р Романтизм 11 класс
Романтизм 11 класс Тест на тему: Сила упругости. Закон Гука
Тест на тему: Сила упругости. Закон Гука Manhattan
Manhattan Différenciation sociale du lexique
Différenciation sociale du lexique Samp Stories Epesode one(1)
Samp Stories Epesode one(1) Регрессивный анализ для выявления лучших агентов. Росгосстрах
Регрессивный анализ для выявления лучших агентов. Росгосстрах