- Классификация мер информации

Содержание
- 2. Классификация мер информации Синтаксическая мера информации Семантическая мера информации Прагматическая мера информации
- 3. Единицы измерения информации 1 бит = кол-во двоичных цифр (0 и 1) Пример: код 11001011 имеет
- 4. Вероятностный подход События, о которых нельзя сказать произойдут они или нет, пока не будет осуществлен эксперимент,
- 5. Энтропия (часть1) Энтропия – численная мера измеряющая неопределенность. Некоторые свойства функции: f (1)=0, так как при
- 6. общее число исходов М – число попыток (пример: Х = 62 = 36) Энтропия системы из
- 7. Обозначим через K Получим f(X) = K ∙ lnX или H = K ∙ lnX, таким
- 8. Сопоставление мер информации
- 9. Кодирование информации. Информатика
- 10. Абстрактный алфавит Алфавит - множество знаков, в котором определен их порядок (общеизвестен порядок знаков в русском
- 11. Математическая постановка задачи кодирования А - первичный алфавит. Состоит из N знаков со средней информацией на
- 12. IS (A) ≤ If (B) – условие обратимости кодирования, т.е не исчезновения информации. n* IА ≤
- 13. Первая теорема Шеннона Примером избыточности может служить предложение «в словох всо глосноо зомононо боквой о» Существует
- 14. Вторая теорема Шеннона При наличии помех в канале всегда можно найти такую систему кодирования, при которой
- 15. Вторая теорема Шеннона Это позволяет определять на приемной стороне канала, какому подмножеству принадлежит искаженная помехами принятая
- 17. Скачать презентацию
Слайд 2Классификация мер информации
Синтаксическая мера информации
Семантическая мера информации
Прагматическая мера информации
Классификация мер информации
Синтаксическая мера информации
Семантическая мера информации
Прагматическая мера информации

Слайд 3Единицы измерения информации
1 бит = кол-во двоичных цифр (0 и 1)
Пример: код
Единицы измерения информации
1 бит = кол-во двоичных цифр (0 и 1)
Пример: код

Слайд 4Вероятностный подход
События, о которых нельзя сказать произойдут они или нет, пока не
Вероятностный подход
События, о которых нельзя сказать произойдут они или нет, пока не

Слайд 5Энтропия (часть1)
Энтропия – численная мера измеряющая неопределенность.
Некоторые свойства функции:
f (1)=0, так как
Энтропия (часть1)
Энтропия – численная мера измеряющая неопределенность.
Некоторые свойства функции:
f (1)=0, так как

Слайд 6
общее число исходов
М – число попыток (пример: Х =
общее число исходов
М – число попыток (пример: Х =

Слайд 7
Обозначим через K
Получим f(X) = K ∙ lnX или
Обозначим через K
Получим f(X) = K ∙ lnX или

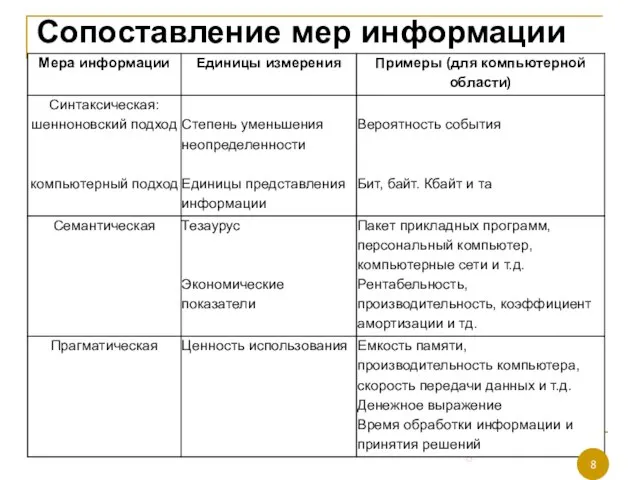
Слайд 8Сопоставление мер информации
Сопоставление мер информации
Слайд 9Кодирование информации.
Информатика
Кодирование информации.
Информатика

Слайд 10Абстрактный алфавит
Алфавит - множество знаков, в котором определен их порядок (общеизвестен порядок
Абстрактный алфавит
Алфавит - множество знаков, в котором определен их порядок (общеизвестен порядок

Слайд 11Математическая постановка задачи кодирования
А - первичный алфавит. Состоит из N
знаков со
Математическая постановка задачи кодирования
А - первичный алфавит. Состоит из N
знаков со

Слайд 12IS (A) ≤ If (B) – условие обратимости кодирования, т.е не исчезновения
IS (A) ≤ If (B) – условие обратимости кодирования, т.е не исчезновения

Слайд 13Первая теорема Шеннона
Примером избыточности может служить предложение
«в словох всо глосноо зомононо
Первая теорема Шеннона
Примером избыточности может служить предложение
«в словох всо глосноо зомононо

Слайд 14Вторая теорема Шеннона
При наличии помех в канале всегда можно найти такую систему
Вторая теорема Шеннона
При наличии помех в канале всегда можно найти такую систему

Слайд 15Вторая теорема Шеннона
Это позволяет определять на приемной стороне канала, какому подмножеству принадлежит
Вторая теорема Шеннона
Это позволяет определять на приемной стороне канала, какому подмножеству принадлежит

 Правовая семья
Правовая семья Развитие эмоций у детей дошкольного возраста
Развитие эмоций у детей дошкольного возраста Автоматизация очистных сооружений
Автоматизация очистных сооружений Нормирование труда, как эффективный инструмент управления медицинской организацией
Нормирование труда, как эффективный инструмент управления медицинской организацией Внутренняя политика Екатерины II. Была ли она противоречивой?
Внутренняя политика Екатерины II. Была ли она противоречивой? Становление среднего класса и политические изменения в современной России
Становление среднего класса и политические изменения в современной России Презентация на тему Показатели динамики рынка зерна в рф
Презентация на тему Показатели динамики рынка зерна в рф  Использование сети Интернет в обучении математике и подготовке к ЕГЭ
Использование сети Интернет в обучении математике и подготовке к ЕГЭ Педагогические технологии контроля знаний обучающихся
Педагогические технологии контроля знаний обучающихся Современные источники света
Современные источники света Прыжок в высоту с разбега способом перешагивание
Прыжок в высоту с разбега способом перешагивание Создание учебно-методического комплекса по дисциплине«Интегрированные издательские системы» средствами программы Front Page
Создание учебно-методического комплекса по дисциплине«Интегрированные издательские системы» средствами программы Front Page Банковские карты это современный способ оплаты различных услуг и товаров. Пластиковые банковские карты ООО КБ "Евроазиатский Инве
Банковские карты это современный способ оплаты различных услуг и товаров. Пластиковые банковские карты ООО КБ "Евроазиатский Инве Общие подходы к задачам планирования и оптимизации 2G - 4G сетей подвижной связи
Общие подходы к задачам планирования и оптимизации 2G - 4G сетей подвижной связи Рождество, да святки – ряженье, колядки.
Рождество, да святки – ряженье, колядки. Войлок - новое хобби или забытое мастерство
Войлок - новое хобби или забытое мастерство Общественный договор и естественное право в трудах
Общественный договор и естественное право в трудах ПРЕЗЕНТАЦИЯ ПО ПСИХОЛОГИИ
ПРЕЗЕНТАЦИЯ ПО ПСИХОЛОГИИ Комплекс в процессе строительcтва
Комплекс в процессе строительcтва Панорама педагогических технологий
Панорама педагогических технологий Простые питательные среды
Простые питательные среды  Региональная экономика как наука. Лекция 3
Региональная экономика как наука. Лекция 3 Оконешниковская сош
Оконешниковская сош Реализация лекарственных препаратов
Реализация лекарственных препаратов Салат Несвижский
Салат Несвижский М.А.Шолохов. Жизнь,творчество, личность
М.А.Шолохов. Жизнь,творчество, личность Энергосбережение – не мода, а необходимость
Энергосбережение – не мода, а необходимость Основы цветоведения. Наука о цвете
Основы цветоведения. Наука о цвете