- Классификация систем хранения и обработки данных

Содержание
- 2. Что общего в архитектуре любого web-приложения среднего уровня? у нас ~2.2 миллиона DAU, ~40kk php req,
- 3. Как мы классифицируем системы хранения 1) где и сколько храним данных, протокол Тип хранения Где именно
- 4. Как мы классифицируем системы хранения 2) что и как пишем Надежность записи (защита от сбоев, допустимая
- 5. Как мы классифицируем системы хранения 3) что и как читаем Надежность чтения (актуальность данных на момент
- 6. Как мы классифицируем системы хранения 4) как этим управлять Переносимость (доступность для альтернативной win32 платформы ;)
- 7. Как мы классифицируем «данные» 5) какой характер работы с данными Соотношение чтение\запись? Cложность выборок Оперативные данные
- 8. Классификация на практике Хранение
- 9. Классификация на практике Запись (часть 1)
- 10. Классификация на практике Запись (часть 2)
- 11. Классификация на практике Запись (часть 3)
- 12. Классификация на практике Чтение
- 13. Классификация на практике Управляемость (часть 1)
- 14. Классификация на практике Управляемость (часть 2)
- 15. Классификация на практике Управляемость (часть 3)
- 16. Ок, а теперь «грабли» ;-) MySQL InnoDB Все просто замечательно, пока какой то тип нагрузки преобладает
- 17. Ок, а теперь «грабли» ;-) memcache Dog-pile эффекты (lock через add при записи) Размер value одних
- 18. Ок, а теперь «грабли» ;-) APC ОЧЕНЬ быстрый, но Dog-pile эффекты никуда не делись (lock через
- 19. Ок, а теперь «грабли» ;-) FileSystem, GlusterFS Если «активная часть данных» умещается на SSD и есть
- 20. Ок, а теперь «грабли» ;-) Redis Все что справедливо для Memcache Single thread (пока еще) в
- 22. Скачать презентацию

Слайд 3Как мы классифицируем системы хранения
1) где и сколько храним данных, протокол
Тип хранения
Где
Как мы классифицируем системы хранения
1) где и сколько храним данных, протокол
Тип хранения
Где

Слайд 4Как мы классифицируем системы хранения
2) что и как пишем
Надежность записи (защита от
Как мы классифицируем системы хранения
2) что и как пишем
Надежность записи (защита от

Слайд 5Как мы классифицируем системы хранения
3) что и как читаем
Надежность чтения (актуальность данных
Как мы классифицируем системы хранения
3) что и как читаем
Надежность чтения (актуальность данных

Слайд 6Как мы классифицируем системы хранения
4) как этим управлять
Переносимость (доступность для альтернативной win32
Как мы классифицируем системы хранения
4) как этим управлять
Переносимость (доступность для альтернативной win32

Слайд 7Как мы классифицируем «данные»
5) какой характер работы с данными
Соотношение чтение\запись?
Cложность выборок
Оперативные данные
Как мы классифицируем «данные»
5) какой характер работы с данными
Соотношение чтение\запись?
Cложность выборок
Оперативные данные

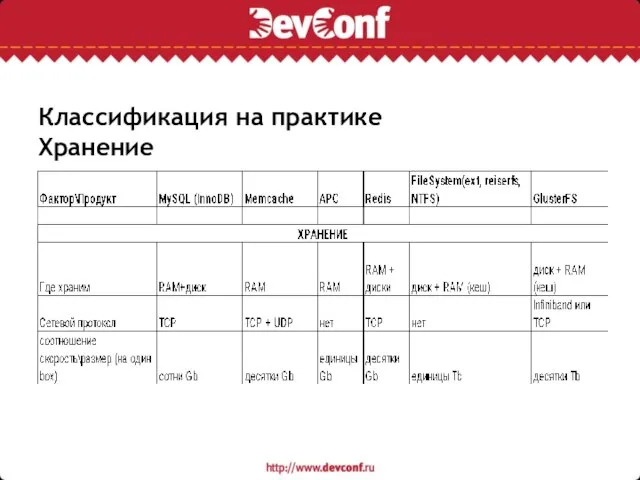
Слайд 8Классификация на практике
Хранение
Классификация на практике
Хранение
Слайд 9Классификация на практике
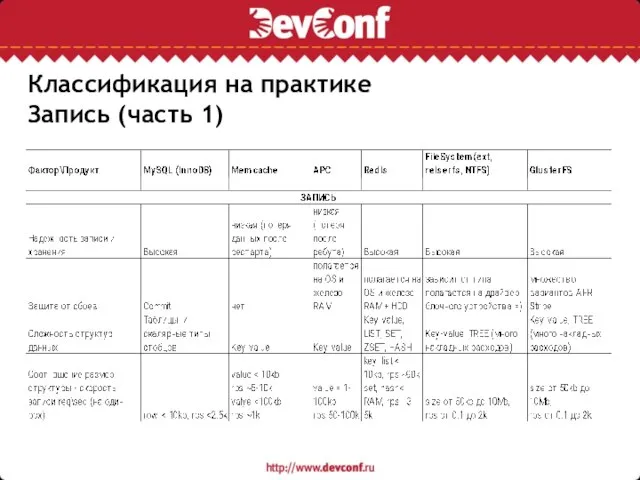
Запись (часть 1)
Классификация на практике
Запись (часть 1)
Слайд 10Классификация на практике
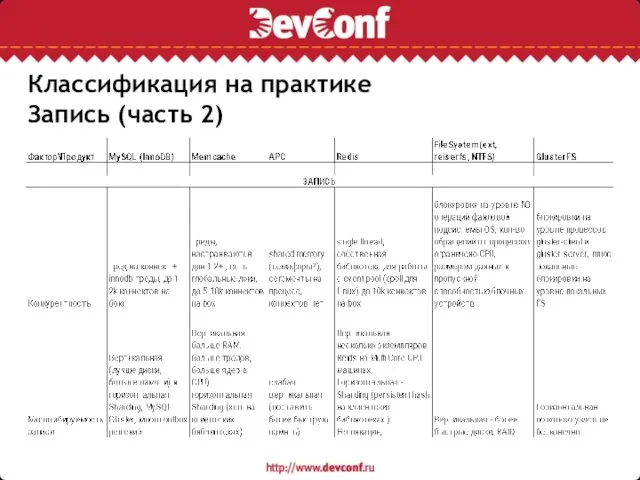
Запись (часть 2)
Классификация на практике
Запись (часть 2)
Слайд 11Классификация на практике
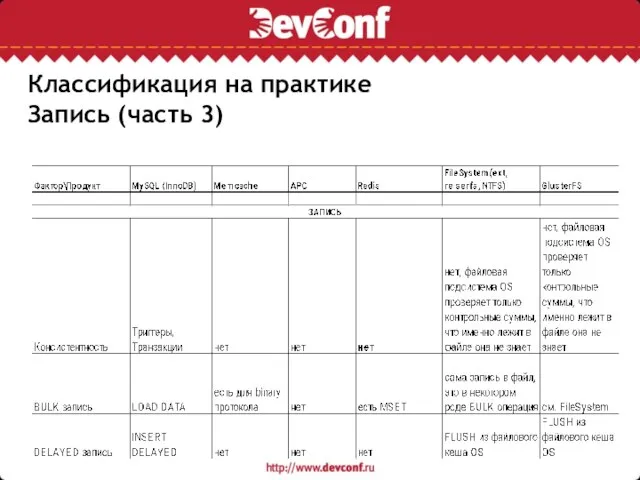
Запись (часть 3)
Классификация на практике
Запись (часть 3)
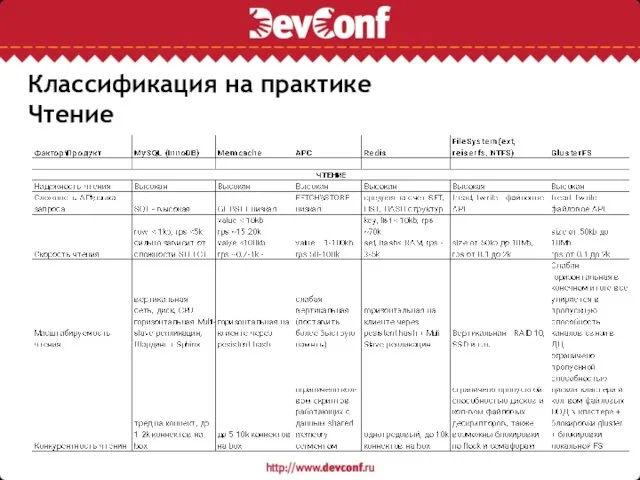
Слайд 12Классификация на практике
Чтение
Классификация на практике
Чтение
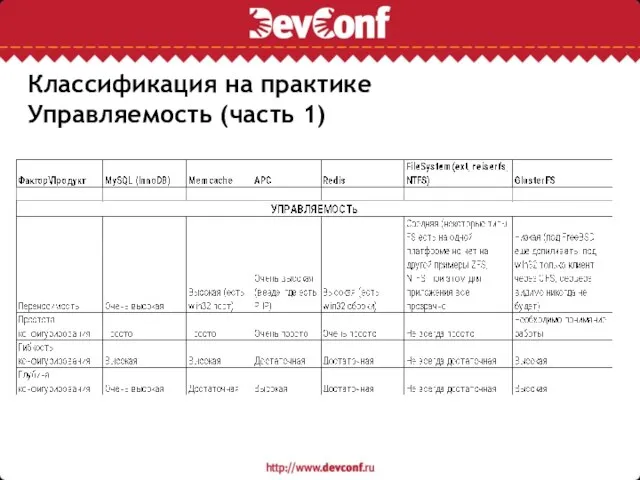
Слайд 13Классификация на практике
Управляемость (часть 1)
Классификация на практике
Управляемость (часть 1)
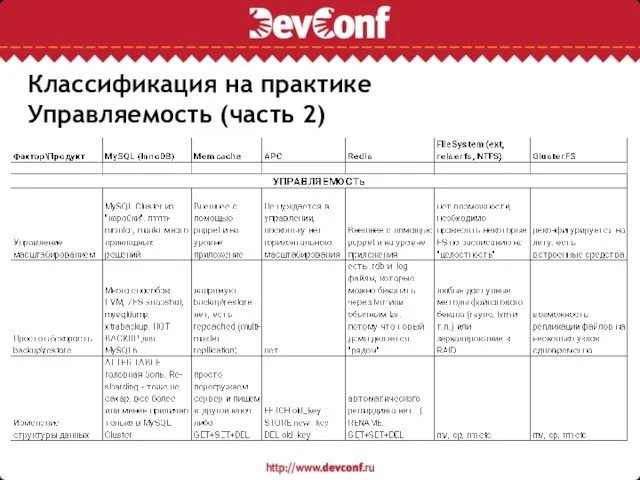
Слайд 14Классификация на практике
Управляемость (часть 2)
Классификация на практике
Управляемость (часть 2)
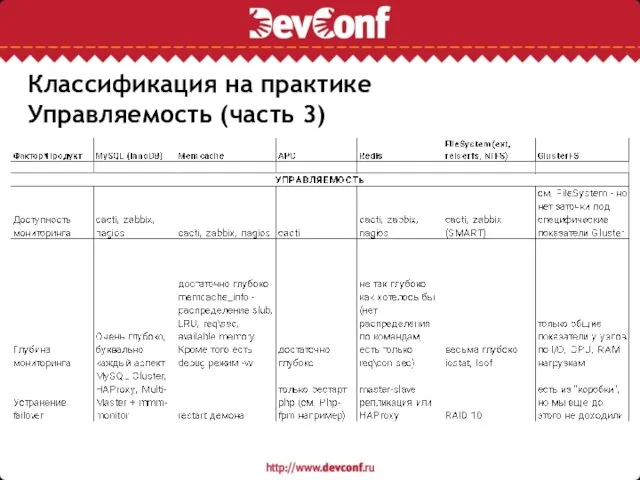
Слайд 15Классификация на практике
Управляемость (часть 3)
Классификация на практике
Управляемость (часть 3)
Слайд 16Ок, а теперь «грабли» ;-)
MySQL InnoDB
Все просто замечательно, пока какой то тип
Ок, а теперь «грабли» ;-)
MySQL InnoDB
Все просто замечательно, пока какой то тип

Слайд 17Ок, а теперь «грабли» ;-)
memcache
Dog-pile эффекты (lock через add при записи)
Размер value
Ок, а теперь «грабли» ;-)
memcache
Dog-pile эффекты (lock через add при записи)
Размер value

Слайд 18Ок, а теперь «грабли» ;-)
APC
ОЧЕНЬ быстрый, но Dog-pile эффекты никуда не делись
Ок, а теперь «грабли» ;-)
APC
ОЧЕНЬ быстрый, но Dog-pile эффекты никуда не делись

Слайд 19Ок, а теперь «грабли» ;-)
FileSystem, GlusterFS
Если «активная часть данных» умещается на SSD
Ок, а теперь «грабли» ;-)
FileSystem, GlusterFS
Если «активная часть данных» умещается на SSD

Слайд 20Ок, а теперь «грабли» ;-)
Redis
Все что справедливо для Memcache
Single thread (пока еще)
Ок, а теперь «грабли» ;-)
Redis
Все что справедливо для Memcache
Single thread (пока еще)

 Международный спутниковый канал Интер+
Международный спутниковый канал Интер+ Проблемы и парадоксы введения ФГОС начального и основного общего образования
Проблемы и парадоксы введения ФГОС начального и основного общего образования Уважаемые собственники бизнеса, руководители предприятий! Мы поможем Вам провести: - логистический аудит и консультирование; - опт
Уважаемые собственники бизнеса, руководители предприятий! Мы поможем Вам провести: - логистический аудит и консультирование; - опт Презентация на тему Подготовка к сочинению-рассуждению (поле С)
Презентация на тему Подготовка к сочинению-рассуждению (поле С) Занятие № 1: Организация, вооружение и военная техника взвода
Занятие № 1: Организация, вооружение и военная техника взвода Antibiotic (Антибиотики)
Antibiotic (Антибиотики) Школьная форма
Школьная форма Портфолио студента
Портфолио студента Домашние опасности (2 класс)
Домашние опасности (2 класс) Пенсионные фонды, способы формирования и назначение
Пенсионные фонды, способы формирования и назначение Волшебная принцесса
Волшебная принцесса Distributed Version Control Systems
Distributed Version Control Systems Изображение и реальность
Изображение и реальность Возрастные особенности интеллектуального развития учащихся начальной школы
Возрастные особенности интеллектуального развития учащихся начальной школы  Проект«Создание элективного курса по географии для предпрофильной подготовки учащихся 9 классов».
Проект«Создание элективного курса по географии для предпрофильной подготовки учащихся 9 классов». Католическая церковь: путь к вершине могущества
Католическая церковь: путь к вершине могущества Рельеф Южной Америки
Рельеф Южной Америки Метод проектов: общие положения. Проектная и исследовательская деятельность: сходство и различие
Метод проектов: общие положения. Проектная и исследовательская деятельность: сходство и различие Управленческий учет (лекции)
Управленческий учет (лекции) Александр Иванович Куприн
Александр Иванович Куприн Урок на тему : «Исследование функции с помощью производной»с использованием компьютерных технологийУчитель математики Бахт
Урок на тему : «Исследование функции с помощью производной»с использованием компьютерных технологийУчитель математики Бахт Закономерности управления персоналом
Закономерности управления персоналом 1 2 На протяжении 60 лет ISKRAEMECO является одним из мировых лидеров в области производства приборов и систем учета. На сегодняшний день I
1 2 На протяжении 60 лет ISKRAEMECO является одним из мировых лидеров в области производства приборов и систем учета. На сегодняшний день I Презентация на тему Образование и философия
Презентация на тему Образование и философия  Сертификация продукции
Сертификация продукции ДО АВГУСТА 2008
ДО АВГУСТА 2008 Железнодорожные перевозки по всей России!
Железнодорожные перевозки по всей России! Микены и Троя. История Древнего мира
Микены и Троя. История Древнего мира