- Лекция 6. Многопользовательские БД. Распределенные БД. Архитектура клиент-сервер.

Содержание
- 2. Технологии доступа к данным В первых версиях операционной системы Windows пользователи могли совместно использовать данные в
- 3. Object Linking and Embedding (OLE). OLE – это технология, которая позволяет создавать составные приложения, включающие в
- 4. При связывании объектов в контейнере хранится лишь ссылка на объект-источник. После обновления исходного файла объекта обновляется
- 5. Компонентная модель объектов Component Object Model (СОМ) является объектно-ориентированной моделью, состоящей из спецификации, определяющей интерфейс между
- 6. Технология открытого доступа к данным Open Database Connectivity (ODBC) была разработана фирмой MS для обеспечения возможности
- 7. Таким образом, основное назначение ОDВС состоит в абстрагировании приложения от особенностей ядра используемой БД. Технология ODBC
- 8. Достоинством технологии ODBC является простота разработки приложений, обусловленная высоким уровнем абстрактности интерфейса доступа к данным практически
- 9. В технологии OLE DB используется механизм провайдеров, под которыми понимают поставщиков данных, находящихся в надстройке над
- 10. Хотя ODBC и OLE DB считаются хорошими интерфейсами передачи данных, но как программный интерфейс они имеют
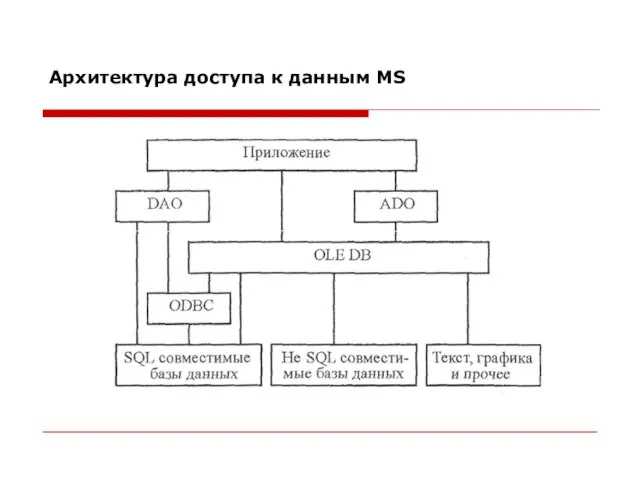
- 11. Архитектура доступа к данным MS
- 12. Архитектура файл-сервер, клиент-сервер Если речь идет о некоторой БД как самостоятельной функциональной единице, то под ней
- 13. В БД c применением файл-серверной архитектуры по запросам пользователей файлы БД передаются на персональные компьютеры (ПК),
- 14. Забота о целостности данных при такой организации работы целиком возлагается на программы клиентов. Если они недостаточно
- 15. Архитектура клиент-сервер разделяет приложение на две части, используя лучшие качества с обеих сторон. Клиентская часть (front-end)
- 16. Архитектура клиент-сервер предполагает централизованное хранение данных с двухзвенным распределением функций СУБД. В этой архитектуре данные обычно
- 17. В архитектуре клиент-сервер клиент устанавливает соединение с сервером и формирует запрос к серверу БД. Выполнение запроса
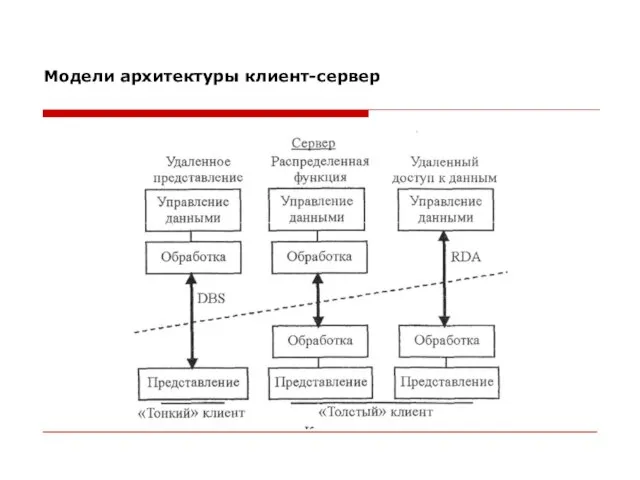
- 18. По разделению функций между клиентом и сервером можно выделить следующие типы архитектур: удаленное представление (Database Server
- 19. В модели удаленного доступа к данным (Remote Data Access - RDA) программы, реализующие функции представления информации
- 20. Модель удаленного представления, иначе модель сервера БД (Database Server - DBS), отличается от предыдущей модели тем,
- 21. В модели распределенной функции логика обработки данных распределена по двум узлам. Такую модель могут иметь БД,
- 22. В удаленном представлении основной функцией клиентской части является просто отображение информации на экране монитора и связь
- 23. Модели архитектуры клиент-сервер
- 24. Распределенные базы данных (РБД) можно рассматривать как подвид распределенных вычислительных систем, занимающихся обработкой данных. Распределенная вычислительная
- 25. Существуют два основных способа организации РБД с распределенным хранением данных: фрагментация и репликация (тиражирование). Фрагментация бывает
- 26. Если БД или хотя бы один фрагмент данных может располагаться более чем на одном компьютере, то
- 27. Например, если требуется максимальная степень доступности данных и нет необходимости в частом их обновлении, то полная
- 28. Первым фактором, по которому можно различать РБД, является степень однородности. Если все пользователи РБД используют одно
- 29. Федеративная СУБД может быть даже составлена из СУБД, поддерживающих различные модели данных, типы, ограничения и языки
- 30. Глобальная концептуальная схема представляет собой логическое описание всех БД, предоставляя ее так, как будто она не
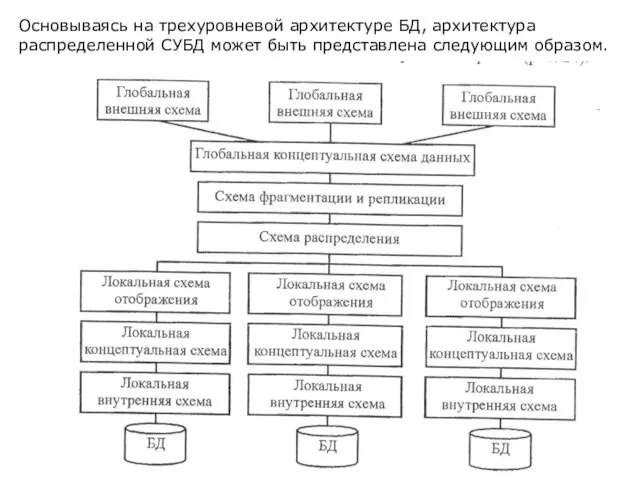
- 31. Основываясь на трехуровневой архитектуре БД, архитектура распределенной СУБД может быть представлена следующим образом.
- 32. РБД обладает следующими преимуществами. 1. Разделяемость и локальная автономность. Географическая распределеленность организации может быть отображена в
- 34. Скачать презентацию

Слайд 3Object Linking and Embedding (OLE).
OLE – это технология, которая позволяет создавать
Object Linking and Embedding (OLE).
OLE – это технология, которая позволяет создавать

Слайд 4При связывании объектов в контейнере хранится лишь ссылка на объект-источник. После обновления
При связывании объектов в контейнере хранится лишь ссылка на объект-источник. После обновления

Слайд 5Компонентная модель объектов Component Object Model (СОМ) является объектно-ориентированной моделью, состоящей из
Компонентная модель объектов Component Object Model (СОМ) является объектно-ориентированной моделью, состоящей из

Слайд 6Технология открытого доступа к данным Open Database Connectivity (ODBC) была разработана фирмой
Технология открытого доступа к данным Open Database Connectivity (ODBC) была разработана фирмой

Слайд 7Таким образом, основное назначение ОDВС состоит в абстрагировании приложения от особенностей ядра
Таким образом, основное назначение ОDВС состоит в абстрагировании приложения от особенностей ядра

Слайд 8Достоинством технологии ODBC является простота разработки приложений, обусловленная высоким уровнем абстрактности интерфейса
Достоинством технологии ODBC является простота разработки приложений, обусловленная высоким уровнем абстрактности интерфейса

Слайд 9В технологии OLE DB используется механизм провайдеров, под которыми понимают поставщиков данных,
В технологии OLE DB используется механизм провайдеров, под которыми понимают поставщиков данных,

Слайд 10Хотя ODBC и OLE DB считаются хорошими интерфейсами передачи данных, но как
Хотя ODBC и OLE DB считаются хорошими интерфейсами передачи данных, но как

Слайд 11Архитектура доступа к данным MS
Архитектура доступа к данным MS
Слайд 12Архитектура файл-сервер, клиент-сервер
Если речь идет о некоторой БД как самостоятельной функциональной
Архитектура файл-сервер, клиент-сервер
Если речь идет о некоторой БД как самостоятельной функциональной

Слайд 13В БД c применением файл-серверной архитектуры по запросам пользователей файлы БД передаются
В БД c применением файл-серверной архитектуры по запросам пользователей файлы БД передаются

Слайд 14Забота о целостности данных при такой организации работы целиком возлагается на программы
Забота о целостности данных при такой организации работы целиком возлагается на программы

Слайд 15Архитектура клиент-сервер разделяет приложение на две части, используя лучшие качества с обеих
Архитектура клиент-сервер разделяет приложение на две части, используя лучшие качества с обеих

Слайд 16Архитектура клиент-сервер предполагает централизованное хранение данных с двухзвенным распределением функций СУБД. В
Архитектура клиент-сервер предполагает централизованное хранение данных с двухзвенным распределением функций СУБД. В

Слайд 17В архитектуре клиент-сервер клиент устанавливает соединение с сервером и формирует запрос к
В архитектуре клиент-сервер клиент устанавливает соединение с сервером и формирует запрос к

Слайд 18По разделению функций между клиентом и сервером можно выделить следующие типы архитектур:
удаленное
По разделению функций между клиентом и сервером можно выделить следующие типы архитектур:
удаленное

Слайд 19В модели удаленного доступа к данным (Remote Data Access - RDA) программы,
В модели удаленного доступа к данным (Remote Data Access - RDA) программы,

Слайд 20Модель удаленного представления, иначе модель сервера БД (Database Server - DBS), отличается
Модель удаленного представления, иначе модель сервера БД (Database Server - DBS), отличается

Слайд 21В модели распределенной функции логика обработки данных распределена по двум узлам. Такую
В модели распределенной функции логика обработки данных распределена по двум узлам. Такую

Слайд 22В удаленном представлении основной функцией клиентской части является просто отображение информации на
В удаленном представлении основной функцией клиентской части является просто отображение информации на

Слайд 23Модели архитектуры клиент-сервер
Модели архитектуры клиент-сервер
Слайд 24Распределенные базы данных (РБД) можно рассматривать как подвид распределенных вычислительных систем, занимающихся
Распределенные базы данных (РБД) можно рассматривать как подвид распределенных вычислительных систем, занимающихся

Слайд 25Существуют два основных способа организации РБД с распределенным хранением данных: фрагментация и
Существуют два основных способа организации РБД с распределенным хранением данных: фрагментация и

Слайд 26Если БД или хотя бы один фрагмент данных может располагаться более чем
Если БД или хотя бы один фрагмент данных может располагаться более чем

Слайд 27Например, если требуется максимальная степень доступности данных и нет необходимости в частом
Например, если требуется максимальная степень доступности данных и нет необходимости в частом

Слайд 28Первым фактором, по которому можно различать РБД, является степень однородности. Если все
Первым фактором, по которому можно различать РБД, является степень однородности. Если все

Слайд 29Федеративная СУБД может быть даже составлена из СУБД, поддерживающих различные модели данных,
Федеративная СУБД может быть даже составлена из СУБД, поддерживающих различные модели данных,

Слайд 30Глобальная концептуальная схема представляет собой логическое описание всех БД, предоставляя ее так,
Глобальная концептуальная схема представляет собой логическое описание всех БД, предоставляя ее так,

Слайд 31Основываясь на трехуровневой архитектуре БД, архитектура распределенной СУБД может быть представлена следующим
Основываясь на трехуровневой архитектуре БД, архитектура распределенной СУБД может быть представлена следующим
Слайд 32РБД обладает следующими преимуществами.
1. Разделяемость и локальная автономность. Географическая распределеленность организации может
РБД обладает следующими преимуществами.
1. Разделяемость и локальная автономность. Географическая распределеленность организации может

 Гостевой дом Аленький цветочек
Гостевой дом Аленький цветочек Исследовательская деятельность на уроках литературы
Исследовательская деятельность на уроках литературы Россия в Первой мировой войне
Россия в Первой мировой войне Концепт «Петербург» в повестях Н.В Гоголя «Портрет» и «Шинель»
Концепт «Петербург» в повестях Н.В Гоголя «Портрет» и «Шинель» Подпрограмма «Развитие Москвы как Международного финансового центра»
Подпрограмма «Развитие Москвы как Международного финансового центра» Кружок «Юный друг природы» 1класс« Народная праздничная одежда»
Кружок «Юный друг природы» 1класс« Народная праздничная одежда» ИТОГИ ГОДА 2021 для ПП!!!!
ИТОГИ ГОДА 2021 для ПП!!!! Тестирование в Agile
Тестирование в Agile Стратегический Аудит России
Стратегический Аудит России Софизмы
Софизмы Синонимия словосочетаний
Синонимия словосочетаний Дела по защите прав группы лиц
Дела по защите прав группы лиц Технологии дифференцированного и игрового обучения
Технологии дифференцированного и игрового обучения Медиация в нашей жизни. Нам нужна служба школьной медиации
Медиация в нашей жизни. Нам нужна служба школьной медиации Стратегия развития банковского сектора до 2020 года
Стратегия развития банковского сектора до 2020 года Традиционная кухня Японии на английском
Традиционная кухня Японии на английском Страны Азии
Страны Азии Ф.И.Тютчев-тайновидец человеческого сердца
Ф.И.Тютчев-тайновидец человеческого сердца Романова Д.С.
Романова Д.С. Физиология высшей нервной деятельности
Физиология высшей нервной деятельности «Конструирование рукава» 9 класс
«Конструирование рукава» 9 класс Складання та оформлення номенклатури справ у діловодстві
Складання та оформлення номенклатури справ у діловодстві Политические режимы
Политические режимы Древнегреческий театр
Древнегреческий театр Презентация на тему На пути к индустриальной эре
Презентация на тему На пути к индустриальной эре  Эффективное управление затратной частью 28 е ноября 2011. - презентация
Эффективное управление затратной частью 28 е ноября 2011. - презентация SYM MAXSYM TL 500
SYM MAXSYM TL 500 Экология в политике XXI века
Экология в политике XXI века