- Lekciya4_2

Содержание
- 2. Качество любой ИТ зависит от того, насколько грамотно она адаптирована к конкретным условиям функционирования. В большей
- 3. За рубежом в первой половине 1970-х гг. появился термин workstation, смысл которого во многом совпадает с
- 4. Наметилась тенденция создания унифицированных АРМ, обслуживающих несколько предметных областей. Например, АРМ-аналитик, созданный на базе АРМ-статистика, значительно
- 6. В состав баз данных АРМ входят файлы, документы, показатели, данные, обеспечивающие решение задач по профилю специалиста.
- 7. Общими требованиями, предъявляемыми к АРМ, являются: удобство и простота общения с ними, в том числе настройка
- 8. АРМ конфигурируется с учетом следующих условий: содержания задач, решаемых пользователем; функциональных обязанностей пользователя; режимов работы и
- 9. Основное назначение АРМ состоит в повышении интеллектуального уровня решения задач и автоматизации рутинных процедур специалиста. Выделяют
- 10. Методы, средства и процедуры АРМ основаны на идентичных категориях, которые применяются в ИТ. В область режимов
- 11. При создании АРМ разработчики должны исходить из того, что в общем случае АРМ является квинтэссенцией ТПОД.
- 12. Для решения задач в АРМ могут быть реализованы следующие функции: ввод данных в ЭВМ с первичных
- 13. группировка данных по характеристикам предприятий и показателям; обработка и представление данных в различных разрезах; построение графиков
- 14. В результате работы АРМ полученная информация может быть выведена на печать, записана на магнитные носители, а
- 15. формирование электронных таблиц на основе документов с использованием необходимых расчетов и методов контроля информации; создание сводных
- 16. ИТ ЭЛЕКТРОННОГО ОФИСА Информационный обмен между людьми как в рамках предприятия, так и за его пределами
- 17. Коммерческий успех предприятия в значительной степени зависит от того, насколько его сотрудникам удается, во-первых, осмысливать и
- 18. Суть единой среды обмена сообщениями сводится к следующему. Вся входная информация — документы, голосовые и факсимильные
- 19. При работе в единой среде обмена сообщениями их физическая форма в принципе может оставаться почти полностью
- 20. При таком подходе часто бывает необходимо, чтобы в БД электронных писем имелись записи, соответствующие голосовым и
- 21. В частности, существуют программы, организующие единую среду обмена сообщениями на базе Мiсrоsоft Exchange, Lotus Notes и
- 22. При условии применения в качестве аппаратной базы для систем голосовой почты учрежденческих АТС всегда существовала проблема
- 23. Компания Octel Communications предлагает своим клиентам программу Octel Unified Messenger, представляющую собой надстройку над системой Мiсrоsоft
- 24. Как и другие современные продукты, система Octel Unified Messenger позволяет знакомиться с содержанием голосовых сообщений и
- 25. В офисной работе постоянно приходится обращаться к правовой информации. Это необходимо для того, чтобы принимаемые решения
- 26. Для актуализации и целостности БД правовых АИПС фирмы- разработчики обеспечивают сопровождение этих систем, как правило, на
- 27. Одной из рациональных форм построения ИТ электронного офиса являются пакеты программ, реализующие интеграцию офисных задач. Примером
- 28. Использование Интернета позволило создать разновидность электронного офиса, получившую название «виртуальный офис». В подобных случаях основные функции
- 29. ТЕХНОЛОГИИ ОБРАБОТКИ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ В последние годы в работе пользователей широкое распространение получили технологии обработки графической
- 30. Технология обработки графических образов — это разновидность ИТ по обработке и получению графических изображений и выдаче
- 31. Графическая информация на экране монитора компьютера образуется из точек. В графическом режиме экран монитора представляет совокупность
- 32. Преимущество использования графического интерфейса пользователя в ОС заключается в том, что он позволяет создавать одинаковые графические
- 33. Различают растровую, векторную и фрактальную компьютерную графику. Эти виды различаются принципами формирования изображения. Для каждого из
- 34. Файлы растровой (или битовой) графики содержат в определенной последовательности совокупность отдельных точек растровых изображений (от англ.
- 35. К недостаткам растровых изображений относят их большой объем и невозможность сильного увеличения рисунка, так как видны
- 36. Векторное изображение представляет графический объект, состоящий из линий — элементарных отрезков и дуг. Положение этих элементарных
- 37. В векторной графике объем памяти, занимаемый линией, не зависит от ее размеров, так как линия представляется
- 38. Векторная графика предназначена для создания иллюстраций и широко используется в рекламном деле, дизайне, редакционно-издательском деле. Оформительские
- 39. Векторные методы также широко применяются в автоматизированных системах проектирования (от англ. computer+aided design, CAD), используемых для
- 40. Фрактальные графические изображения создаются автоматически с помощью специальных математических вычислений, т.е. путем программирования, а не рисования.
- 41. Потребность использования графиков, диаграмм, схем, рисунков, этикеток в произвольном тексте или документе вызвала необходимость создания графических
- 42. ИТ коммерческой (или деловой) графики обеспечивают отображение информации, хранящейся в табличных процессорах, базах данных и отдельных
- 43. ИТ иллюстративной графики позволяют создавать иллюстрации — деловые схемы, эскизы, географические карты для различных текстовых документов
- 44. ИТ научной графики предназначены для оформления научных расчетов, содержащих химические, математические и прочие формулы, а также
- 45. Когнитивная графика — совокупность приемов и методов образного представления условий задачи, которая позволяет сразу увидеть решение
- 46. Когнитивные компьютерные средства представляют собой комплекс виртуальных устройств, программ и систем, реализующих совокупную обработку зрительной информации
- 47. ТЕХНОЛОГИИ ИНФОРМАЦИОННОГО ПОИСКА В процессе решения задач пользователь довольно часто вынужден осуществлять поиск необходимой информации по
- 49. В составе диверсифицированных баз данных АИПС хранятся обширные объемы информации различного содержания и форм. Для обеспечения
- 50. Базы данных АИПС База данных АИПС (автоматизированных информационно-поисковых систем) — это совокупность данных, организованных по определенным
- 51. По количеству форм представления данных различаются одноконтурные и многоконтурные БД. Основная форма представления БД — двухконтурная.
- 52. По характеру содержащейся информации различают фактографические, документальные и смешанные БД. Фактографическая БД отображает конкретные сведения, необходимые
- 53. Сам документ, например «Методика расчета амортизации оборудования металлургического производства», хранится, как правило, во внешнем контуре БД
- 54. При условии отсутствия дефицита внешней памяти и производительности ЭВМ документальные БД объединяют во внешней памяти ЭВМ
- 55. Файлы АИС Опорным структурным элементом БД является файл — поименованная область внешней памяти ЭВМ, содержащая данные.
- 56. Таблица — способ формализованного представления данных в виде двумерного массива. Таблица состоит из строк и столбцов.
- 57. Элементом записи является поле. Поле записи — часть записи файла, имеющая функционально самостоятельное значение и обрабатываемая
- 58. Для обеспечения доступа к записям и поиска нужной информации в БД, размещенной в памяти ЭВМ, применяются
- 59. Исходный, или внешний, ключ отображает значение ключевого поля записи, уникально идентифицирующее ее в файле. Поле ключа
- 60. Прямой файл — это вид файла, доступ к записям которого осуществляется по адресу либо последовательно путем
- 61. Смежным с индексным файлом является индексно-последовательный файл, у которого каждая запись снабжена своим ключом. Этим обеспечиваются
- 62. Противоположным прямому файлу по доступу является последовательный файл — файл, к записям которого доступ обеспечивается только
- 63. Отметим также инвентированный файл — файл, в котором записи упорядочены по неключевому полю. Кроме того, существует
- 64. Близким по значению записи является агрегат — структурированная совокупность информационных объектов, определяемая как единый тип данных.
- 65. В структуре БД, кроме файлов, присутствуют и другие единицы информации, например массивы информации. Массив информации —
- 66. БД имеют определенные способы построения. Эти способы построения определяются моделями БД: иерархические, сетевые, реляционные, объектно-ориентированные и
- 67. Иерархическая модель БД. Построена по принципу древовидного графа, в котором информационные элементы представлены по уровням их
- 68. При поиске необходимых данных происходит чтение записей от корня к листьям дерева, т.е. снизу вверх. Достоинством
- 69. Сетевая модель БД. Имеет независимые типы данных, т.е. «конкуренты», и зависимые типы данных — продукция и
- 70. Реляционная модель БД. Этот класс БД строится на применении отношения типа «сущность — связь». В основе
- 71. Достоинства реляционной модели объясняются тем, что в ее основе лежит строгий аппарат реляционной алгебры. В этой
- 72. Качество реляционных БД зависит от нормализации данных, придания им нормальной формы. Нормальная форма — требование, предъявляемое
- 73. Например, когда существует несколько одинаковых записей в таблице, есть риск нарушения целостности данных при обновлении таблицы.
- 74. Модель объектно-ориентированной БД (ООБД). Эта модель является примером реализации БД более высокого логического уровня. ООБД возникли
- 75. Объект — программно связанный набор процедур, методов и средств, реализующих определенную задачу. Процедура — это совокупность
- 76. Организация ООБД имеет несколько стадий: концептуальная модель, когда множество объектов БД прошли описание по соответствующим правилам;
- 77. Модель эволюционных БД. Кардинальным направлением улучшения качества удовлетворения информационных потребностей является поиск новых путей развития БД
- 78. Таким образом, сущность может быть свойством другой сущности или сущность может быть отношением других сущностей, и
- 79. Лингвистические средства. В реализации технологии информационного поиска применяются лингвистические средства — совокупность информационно-поисковых языков, методик индексирования
- 80. В решении задач информационного поиска связующим звеном между пользователем и ЭВМ является информационно-поисковый язык (ИПЯ). Информационно-поисковый
- 81. При условии устранения неоднозначности (омонимии) отдельных слов ключевые слова обозначаются как дескрипторы ИПЯ. Посредством ИПЯ в
- 82. При автоматическом индексировании ЭВМ поручаются функции дериватного, приписного индексирования и автоматической классификации. Так, дери- ватное индексирование,
- 83. В результате индексирования получаются поисковые образы документов и поисковые образы запросов. Поисковый образ документа (ПОД) —
- 84. Сюда входят классификаторы категорий, по которым строится принципиальная схема управления объектом. В современных технологиях поиска в
- 85. По применяемому способу кодирования классификаторы имеют следующие основные разновидности: десятичные классификации; библиотечно-библиографические классификации; фасетные классификации.
- 86. В десятичных классификациях множество объектов делится на десять частей, каждая из которых в свою очередь также
- 87. Библиотечно-библиографическая классификация (ББК) основана на порядке следования букв в том или ином алфавите. В России действует
- 88. Фасетная классификация (ФК) является разновидностью системы классификации, в которой реализована возможность классификации объектов параллельно по нескольким
- 89. В соответствии с принципом ФК в России применяется Единая система классификации и кодирования (ЕСКК). 1 Общегосударственные
- 90. Отраслевые классификаторы разрабатываются соответствующими отраслями для решения задач. Они в определенных случаях могут быть задействованы и
- 91. Локальные классификаторы разрабатываются предприятиями на номенклатуры, относящиеся только к данному предприятию, например коды предоставляемых услуг, коды
- 92. В начале 1970-х гг. для лингвистического обеспечения АИС в стране начали разрабатываться общегосударственные классификаторы. В настоящее
- 93. Классификаторы структуры отраслей народного хозяйства В эту группу входят, например, Общегосударственный классификатор отраслей народного хозяйства (ОКОНХ),
- 94. Классификаторы продукции, например, Общегосударственный классификатор промышленной и сельскохозяйственной продукции (ОКП)
- 95. Классификаторы ресурсов, например, Общегосударственный классификатор профессий рабочих, должностей служащих и тарифных разрядов (ОКПДТР)
- 96. Классификаторы информационных единиц, например, Общегосударственный классификатор технико-экономических показателей (ОКТЭП), Общегосударственный классификатор управленческой документации (ОКУД)
- 97. Эффективность автоматизированной обработки информации требует предварительного представления информации в удобной и компактной форме, что достигается в
- 98. охват всех объектов, подлежащих кодированию, и их однозначное обозначение; возможность расширения объектов кодирования без изменения правил
- 99. Для организации документальных БД и реализации поиска в них предназначены дескрипторные языки. Дескрипторный язык АИПС —
- 100. В основе координатного индексирования лежит представление о том, что содержание любого документа или текста можно отобразить
- 101. Поиск нужных документов АИПС может осуществляться при условии обеспечения единообразия индексирования документов и запросов. Существенными компонентами
- 102. Индексирование документов, содержащих фактографическую информацию, выполняется посредством применения в основном языков классификационного типа. Каждая классификационная рубрика
- 105. С целью получения необходимых документов или данных пользователь составляет запрос в произвольной форме на естественном языке
- 106. При вводе в ЭВМ проводятся лексический, синтаксический, логический и арифметический виды контроля в зависимости от характера
- 107. Технология поиска информации по запросу в значительной мере определяется характером БД. При поиске в документальной БД
- 108. Поиск в фактографической БД проходит несколько иначе. Анализу подвергается каждая запись документа, содержащая идентификаторы в соответствии
- 109. Результаты поиска могут быть выданы на видеотерминал или распечатаны на принтере (блок 14). Затем проводится контроль
- 110. Эффективный способ повышения релевантности поиска — использование так называемого языка запросов. С помощью языка запросов можно
- 111. каждая поисковая система «понимает» свой язык запросов, поэтому пользователям нужно помнить, что инструкцию по использованию языка
- 112. К наиболее известным в мире системам веб-поиска относятся Google, Alta Vista, Norbern Light, Yahoo!, Magellan, Excite,
- 113. По размерам баз данных (индексов) российские поисковые системы заметно проигрывают известным зарубежным, однако здесь собрана и
- 114. поиск по ключевым словам дает слишком много ссылок, и многие из них оказываются бесполезными; огромное количество
- 115. поисковые машины еще не столь совершенны, чтобы понимать естественный язык; по тому представлению результатов, которое обеспечивают
- 116. В последнее время потребности в интеллектуальной помощи быстро растут, помощь необходима для продуктивного поиска информации, для
- 118. Скачать презентацию

Слайд 3За рубежом в первой половине 1970-х гг. появился термин workstation, смысл которого
За рубежом в первой половине 1970-х гг. появился термин workstation, смысл которого

Слайд 4Наметилась тенденция создания унифицированных АРМ, обслуживающих несколько предметных областей. Например, АРМ-аналитик, созданный
Наметилась тенденция создания унифицированных АРМ, обслуживающих несколько предметных областей. Например, АРМ-аналитик, созданный

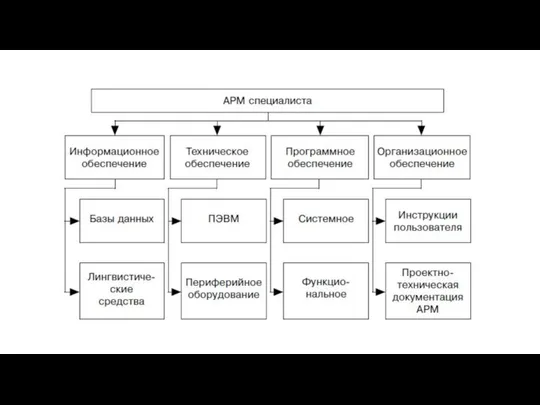
Слайд 6В состав баз данных АРМ входят файлы, документы, показатели, данные, обеспечивающие решение
В состав баз данных АРМ входят файлы, документы, показатели, данные, обеспечивающие решение

Слайд 7Общими требованиями, предъявляемыми к АРМ, являются: удобство и простота общения с ними,
Общими требованиями, предъявляемыми к АРМ, являются: удобство и простота общения с ними,

Слайд 8АРМ конфигурируется с учетом следующих условий:
содержания задач, решаемых пользователем;
функциональных обязанностей
АРМ конфигурируется с учетом следующих условий:
содержания задач, решаемых пользователем;
функциональных обязанностей

Слайд 9Основное назначение АРМ состоит в повышении интеллектуального уровня решения задач и автоматизации
Основное назначение АРМ состоит в повышении интеллектуального уровня решения задач и автоматизации

Слайд 10Методы, средства и процедуры АРМ основаны на идентичных категориях, которые применяются в
Методы, средства и процедуры АРМ основаны на идентичных категориях, которые применяются в

Слайд 11При создании АРМ разработчики должны исходить из того, что в общем случае
При создании АРМ разработчики должны исходить из того, что в общем случае

Слайд 12Для решения задач в АРМ могут быть реализованы следующие функции:
ввод данных в
Для решения задач в АРМ могут быть реализованы следующие функции:
ввод данных в

Слайд 13группировка данных по характеристикам предприятий и показателям;
обработка и представление данных в различных
группировка данных по характеристикам предприятий и показателям;
обработка и представление данных в различных

Слайд 14В результате работы АРМ полученная информация может быть выведена на печать, записана
В результате работы АРМ полученная информация может быть выведена на печать, записана

Слайд 15формирование электронных таблиц на основе документов с использованием необходимых расчетов и методов
формирование электронных таблиц на основе документов с использованием необходимых расчетов и методов

Слайд 16ИТ ЭЛЕКТРОННОГО ОФИСА
Информационный обмен между людьми как в рамках предприятия, так и
ИТ ЭЛЕКТРОННОГО ОФИСА
Информационный обмен между людьми как в рамках предприятия, так и

Слайд 17Коммерческий успех предприятия в значительной степени зависит от того, насколько его сотрудникам
Коммерческий успех предприятия в значительной степени зависит от того, насколько его сотрудникам

Слайд 18Суть единой среды обмена сообщениями сводится к следующему. Вся входная информация —
Суть единой среды обмена сообщениями сводится к следующему. Вся входная информация —

Слайд 19При работе в единой среде обмена сообщениями их физическая форма в принципе
При работе в единой среде обмена сообщениями их физическая форма в принципе

Слайд 20При таком подходе часто бывает необходимо, чтобы в БД электронных писем имелись
При таком подходе часто бывает необходимо, чтобы в БД электронных писем имелись

Слайд 21В частности, существуют программы, организующие единую среду обмена сообщениями на базе Мiсrоsоft
В частности, существуют программы, организующие единую среду обмена сообщениями на базе Мiсrоsоft

Слайд 22При условии применения в качестве аппаратной базы для систем голосовой почты учрежденческих
При условии применения в качестве аппаратной базы для систем голосовой почты учрежденческих

Слайд 23Компания Octel Communications предлагает своим клиентам программу Octel Unified Messenger, представляющую собой
Компания Octel Communications предлагает своим клиентам программу Octel Unified Messenger, представляющую собой

Слайд 24Как и другие современные продукты, система Octel Unified Messenger позволяет знакомиться с
Как и другие современные продукты, система Octel Unified Messenger позволяет знакомиться с

Слайд 25В офисной работе постоянно приходится обращаться к правовой информации. Это необходимо для
В офисной работе постоянно приходится обращаться к правовой информации. Это необходимо для

Слайд 26Для актуализации и целостности БД правовых АИПС фирмы- разработчики обеспечивают сопровождение этих
Для актуализации и целостности БД правовых АИПС фирмы- разработчики обеспечивают сопровождение этих

Слайд 27Одной из рациональных форм построения ИТ электронного офиса являются пакеты программ, реализующие
Одной из рациональных форм построения ИТ электронного офиса являются пакеты программ, реализующие

Слайд 28Использование Интернета позволило создать разновидность электронного офиса, получившую название «виртуальный офис». В
Использование Интернета позволило создать разновидность электронного офиса, получившую название «виртуальный офис». В

Слайд 29ТЕХНОЛОГИИ ОБРАБОТКИ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ
В последние годы в работе пользователей широкое распространение получили
ТЕХНОЛОГИИ ОБРАБОТКИ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ
В последние годы в работе пользователей широкое распространение получили

Слайд 30Технология обработки графических образов — это разновидность ИТ по обработке и получению
Технология обработки графических образов — это разновидность ИТ по обработке и получению

Слайд 31Графическая информация на экране монитора компьютера образуется из точек. В графическом режиме
Графическая информация на экране монитора компьютера образуется из точек. В графическом режиме

Слайд 32Преимущество использования графического интерфейса пользователя в ОС заключается в том, что он
Преимущество использования графического интерфейса пользователя в ОС заключается в том, что он

Слайд 33Различают растровую, векторную и фрактальную компьютерную графику. Эти виды различаются принципами формирования
Различают растровую, векторную и фрактальную компьютерную графику. Эти виды различаются принципами формирования

Слайд 34Файлы растровой (или битовой) графики содержат в определенной последовательности совокупность отдельных точек
Файлы растровой (или битовой) графики содержат в определенной последовательности совокупность отдельных точек

Слайд 35К недостаткам растровых изображений относят их большой объем и невозможность сильного увеличения
К недостаткам растровых изображений относят их большой объем и невозможность сильного увеличения

Слайд 36Векторное изображение представляет графический объект, состоящий из линий — элементарных отрезков и
Векторное изображение представляет графический объект, состоящий из линий — элементарных отрезков и

Слайд 37В векторной графике объем памяти, занимаемый линией, не зависит от ее размеров,
В векторной графике объем памяти, занимаемый линией, не зависит от ее размеров,

Слайд 38Векторная графика предназначена для создания иллюстраций и широко используется в рекламном деле,
Векторная графика предназначена для создания иллюстраций и широко используется в рекламном деле,

Слайд 39Векторные методы также широко применяются в автоматизированных системах проектирования (от англ. computer+aided
Векторные методы также широко применяются в автоматизированных системах проектирования (от англ. computer+aided

Слайд 40Фрактальные графические изображения создаются автоматически с помощью специальных математических вычислений, т.е. путем
Фрактальные графические изображения создаются автоматически с помощью специальных математических вычислений, т.е. путем

Слайд 41Потребность использования графиков, диаграмм, схем, рисунков, этикеток в произвольном тексте или документе
Потребность использования графиков, диаграмм, схем, рисунков, этикеток в произвольном тексте или документе

Слайд 42ИТ коммерческой (или деловой) графики обеспечивают отображение информации, хранящейся в табличных процессорах,
ИТ коммерческой (или деловой) графики обеспечивают отображение информации, хранящейся в табличных процессорах,

Слайд 43ИТ иллюстративной графики позволяют создавать иллюстрации — деловые схемы, эскизы, географические карты
ИТ иллюстративной графики позволяют создавать иллюстрации — деловые схемы, эскизы, географические карты

Слайд 44ИТ научной графики предназначены для оформления научных расчетов, содержащих химические, математические и
ИТ научной графики предназначены для оформления научных расчетов, содержащих химические, математические и

Слайд 45Когнитивная графика — совокупность приемов и методов образного представления условий задачи, которая
Когнитивная графика — совокупность приемов и методов образного представления условий задачи, которая

Слайд 46Когнитивные компьютерные средства представляют собой комплекс виртуальных устройств, программ и систем, реализующих
Когнитивные компьютерные средства представляют собой комплекс виртуальных устройств, программ и систем, реализующих

Слайд 47ТЕХНОЛОГИИ ИНФОРМАЦИОННОГО ПОИСКА
В процессе решения задач пользователь довольно часто вынужден осуществлять поиск
ТЕХНОЛОГИИ ИНФОРМАЦИОННОГО ПОИСКА
В процессе решения задач пользователь довольно часто вынужден осуществлять поиск

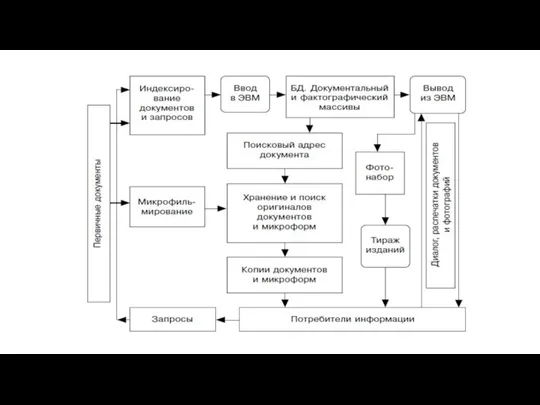
Слайд 49В составе диверсифицированных баз данных АИПС хранятся обширные объемы информации различного содержания
В составе диверсифицированных баз данных АИПС хранятся обширные объемы информации различного содержания

Слайд 50Базы данных АИПС
База данных АИПС (автоматизированных информационно-поисковых систем) — это совокупность
Базы данных АИПС
База данных АИПС (автоматизированных информационно-поисковых систем) — это совокупность

Слайд 51По количеству форм представления данных различаются одноконтурные и многоконтурные БД. Основная форма
По количеству форм представления данных различаются одноконтурные и многоконтурные БД. Основная форма

Слайд 52По характеру содержащейся информации различают фактографические, документальные и смешанные БД.
Фактографическая БД отображает
По характеру содержащейся информации различают фактографические, документальные и смешанные БД.
Фактографическая БД отображает

Слайд 53Сам документ, например «Методика расчета амортизации оборудования металлургического производства», хранится, как правило,
Сам документ, например «Методика расчета амортизации оборудования металлургического производства», хранится, как правило,

Слайд 54При условии отсутствия дефицита внешней памяти и производительности ЭВМ документальные БД объединяют
При условии отсутствия дефицита внешней памяти и производительности ЭВМ документальные БД объединяют

Слайд 55Файлы АИС
Опорным структурным элементом БД является файл — поименованная область внешней
Файлы АИС
Опорным структурным элементом БД является файл — поименованная область внешней

Слайд 56Таблица — способ формализованного представления данных в виде двумерного массива. Таблица состоит
Таблица — способ формализованного представления данных в виде двумерного массива. Таблица состоит

Слайд 57Элементом записи является поле. Поле записи — часть записи файла, имеющая функционально
Элементом записи является поле. Поле записи — часть записи файла, имеющая функционально

Слайд 58Для обеспечения доступа к записям и поиска нужной информации в БД, размещенной
Для обеспечения доступа к записям и поиска нужной информации в БД, размещенной

Слайд 59Исходный, или внешний, ключ отображает значение ключевого поля записи, уникально идентифицирующее ее
Исходный, или внешний, ключ отображает значение ключевого поля записи, уникально идентифицирующее ее

Слайд 60Прямой файл — это вид файла, доступ к записям которого осуществляется по
Прямой файл — это вид файла, доступ к записям которого осуществляется по

Слайд 61Смежным с индексным файлом является индексно-последовательный файл, у которого каждая запись снабжена
Смежным с индексным файлом является индексно-последовательный файл, у которого каждая запись снабжена

Слайд 62Противоположным прямому файлу по доступу является последовательный файл — файл, к записям
Противоположным прямому файлу по доступу является последовательный файл — файл, к записям

Слайд 63Отметим также инвентированный файл — файл, в котором записи упорядочены по неключевому
Отметим также инвентированный файл — файл, в котором записи упорядочены по неключевому

Слайд 64Близким по значению записи является агрегат — структурированная совокупность информационных объектов, определяемая
Близким по значению записи является агрегат — структурированная совокупность информационных объектов, определяемая

Слайд 65В структуре БД, кроме файлов, присутствуют и другие единицы информации, например массивы
В структуре БД, кроме файлов, присутствуют и другие единицы информации, например массивы

Слайд 66БД имеют определенные способы построения. Эти способы построения определяются моделями БД: иерархические,
БД имеют определенные способы построения. Эти способы построения определяются моделями БД: иерархические,

Слайд 67Иерархическая модель БД. Построена по принципу древовидного графа, в котором информационные элементы
Иерархическая модель БД. Построена по принципу древовидного графа, в котором информационные элементы

Слайд 68При поиске необходимых данных происходит чтение записей от корня к листьям дерева,
При поиске необходимых данных происходит чтение записей от корня к листьям дерева,

Слайд 69Сетевая модель БД. Имеет независимые типы данных, т.е. «конкуренты», и зависимые типы
Сетевая модель БД. Имеет независимые типы данных, т.е. «конкуренты», и зависимые типы

Слайд 70Реляционная модель БД. Этот класс БД строится на применении отношения типа «сущность
Реляционная модель БД. Этот класс БД строится на применении отношения типа «сущность

Слайд 71Достоинства реляционной модели объясняются тем, что в ее основе лежит строгий аппарат
Достоинства реляционной модели объясняются тем, что в ее основе лежит строгий аппарат

Слайд 72Качество реляционных БД зависит от нормализации данных, придания им нормальной формы. Нормальная
Качество реляционных БД зависит от нормализации данных, придания им нормальной формы. Нормальная

Слайд 73Например, когда существует несколько одинаковых записей в таблице, есть риск нарушения целостности
Например, когда существует несколько одинаковых записей в таблице, есть риск нарушения целостности

Слайд 74Модель объектно-ориентированной БД (ООБД). Эта модель является примером реализации БД более высокого
Модель объектно-ориентированной БД (ООБД). Эта модель является примером реализации БД более высокого

Слайд 75Объект — программно связанный набор процедур, методов и средств, реализующих определенную задачу.
Объект — программно связанный набор процедур, методов и средств, реализующих определенную задачу.

Слайд 76Организация ООБД имеет несколько стадий:
концептуальная модель, когда множество объектов БД прошли описание
Организация ООБД имеет несколько стадий:
концептуальная модель, когда множество объектов БД прошли описание

Слайд 77Модель эволюционных БД. Кардинальным направлением улучшения качества удовлетворения информационных потребностей является поиск
Модель эволюционных БД. Кардинальным направлением улучшения качества удовлетворения информационных потребностей является поиск

Слайд 78Таким образом, сущность может быть свойством другой сущности или сущность может быть
Таким образом, сущность может быть свойством другой сущности или сущность может быть

Слайд 79Лингвистические средства. В реализации технологии информационного поиска применяются лингвистические средства — совокупность
Лингвистические средства. В реализации технологии информационного поиска применяются лингвистические средства — совокупность

Слайд 80В решении задач информационного поиска связующим звеном между пользователем и ЭВМ является
В решении задач информационного поиска связующим звеном между пользователем и ЭВМ является

Слайд 81При условии устранения неоднозначности (омонимии) отдельных слов ключевые слова обозначаются как дескрипторы
При условии устранения неоднозначности (омонимии) отдельных слов ключевые слова обозначаются как дескрипторы

Слайд 82При автоматическом индексировании ЭВМ поручаются функции дериватного, приписного индексирования и автоматической классификации.
При автоматическом индексировании ЭВМ поручаются функции дериватного, приписного индексирования и автоматической классификации.

Слайд 83В результате индексирования получаются поисковые образы документов и поисковые образы запросов. Поисковый
В результате индексирования получаются поисковые образы документов и поисковые образы запросов. Поисковый

Слайд 84Сюда входят классификаторы категорий, по которым строится принципиальная схема управления объектом. В
Сюда входят классификаторы категорий, по которым строится принципиальная схема управления объектом. В

Слайд 85По применяемому способу кодирования классификаторы имеют следующие основные разновидности:
десятичные классификации;
библиотечно-библиографические классификации;
фасетные классификации.
По применяемому способу кодирования классификаторы имеют следующие основные разновидности:
десятичные классификации;
библиотечно-библиографические классификации;
фасетные классификации.

Слайд 86В десятичных классификациях множество объектов делится на десять частей, каждая из которых
В десятичных классификациях множество объектов делится на десять частей, каждая из которых

Слайд 87Библиотечно-библиографическая классификация (ББК) основана на порядке следования букв в том или ином
Библиотечно-библиографическая классификация (ББК) основана на порядке следования букв в том или ином

Слайд 88Фасетная классификация (ФК) является разновидностью системы классификации, в которой реализована возможность классификации
Фасетная классификация (ФК) является разновидностью системы классификации, в которой реализована возможность классификации

Слайд 89В соответствии с принципом ФК в России применяется Единая система классификации и
В соответствии с принципом ФК в России применяется Единая система классификации и

Слайд 90Отраслевые классификаторы
разрабатываются соответствующими отраслями для решения задач. Они в определенных случаях
Отраслевые классификаторы
разрабатываются соответствующими отраслями для решения задач. Они в определенных случаях

Слайд 91Локальные классификаторы
разрабатываются предприятиями на номенклатуры, относящиеся только к данному предприятию, например коды
Локальные классификаторы
разрабатываются предприятиями на номенклатуры, относящиеся только к данному предприятию, например коды

Слайд 92В начале 1970-х гг. для лингвистического обеспечения АИС в стране начали разрабатываться
В начале 1970-х гг. для лингвистического обеспечения АИС в стране начали разрабатываться

Слайд 93Классификаторы структуры отраслей народного хозяйства
В эту группу входят, например, Общегосударственный классификатор отраслей
Классификаторы структуры отраслей народного хозяйства
В эту группу входят, например, Общегосударственный классификатор отраслей

Слайд 94Классификаторы продукции, например, Общегосударственный классификатор промышленной и сельскохозяйственной продукции (ОКП)
Классификаторы продукции, например, Общегосударственный классификатор промышленной и сельскохозяйственной продукции (ОКП)

Слайд 95Классификаторы ресурсов, например, Общегосударственный классификатор профессий рабочих, должностей служащих и тарифных разрядов
Классификаторы ресурсов, например, Общегосударственный классификатор профессий рабочих, должностей служащих и тарифных разрядов

Слайд 96Классификаторы информационных единиц, например, Общегосударственный классификатор технико-экономических показателей (ОКТЭП), Общегосударственный классификатор управленческой
Классификаторы информационных единиц, например, Общегосударственный классификатор технико-экономических показателей (ОКТЭП), Общегосударственный классификатор управленческой

Слайд 97Эффективность автоматизированной обработки информации требует предварительного представления информации в удобной и компактной
Эффективность автоматизированной обработки информации требует предварительного представления информации в удобной и компактной

Слайд 98охват всех объектов, подлежащих кодированию, и их однозначное обозначение;
возможность расширения объектов кодирования
охват всех объектов, подлежащих кодированию, и их однозначное обозначение;
возможность расширения объектов кодирования

Слайд 99Для организации документальных БД и реализации поиска в них предназначены дескрипторные языки.
Для организации документальных БД и реализации поиска в них предназначены дескрипторные языки.

Слайд 100В основе координатного индексирования лежит представление о том, что содержание любого документа
В основе координатного индексирования лежит представление о том, что содержание любого документа

Слайд 101Поиск нужных документов АИПС может осуществляться при условии обеспечения единообразия индексирования документов
Поиск нужных документов АИПС может осуществляться при условии обеспечения единообразия индексирования документов

Слайд 102Индексирование документов, содержащих фактографическую информацию, выполняется посредством применения в основном языков классификационного
Индексирование документов, содержащих фактографическую информацию, выполняется посредством применения в основном языков классификационного

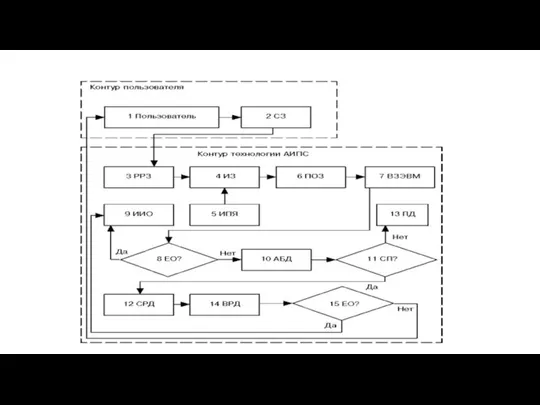

Слайд 105С целью получения необходимых документов или данных пользователь составляет запрос в произвольной
С целью получения необходимых документов или данных пользователь составляет запрос в произвольной

Слайд 106При вводе в ЭВМ проводятся лексический, синтаксический, логический и арифметический виды контроля
При вводе в ЭВМ проводятся лексический, синтаксический, логический и арифметический виды контроля

Слайд 107Технология поиска информации по запросу в значительной мере определяется характером БД. При
Технология поиска информации по запросу в значительной мере определяется характером БД. При

Слайд 108Поиск в фактографической БД проходит несколько иначе. Анализу подвергается каждая запись документа,
Поиск в фактографической БД проходит несколько иначе. Анализу подвергается каждая запись документа,

Слайд 109Результаты поиска могут быть выданы на видеотерминал или распечатаны на принтере (блок
Результаты поиска могут быть выданы на видеотерминал или распечатаны на принтере (блок

Слайд 110Эффективный способ повышения релевантности поиска — использование так называемого языка запросов. С
Эффективный способ повышения релевантности поиска — использование так называемого языка запросов. С

Слайд 111каждая поисковая система «понимает» свой язык запросов, поэтому пользователям нужно помнить, что
каждая поисковая система «понимает» свой язык запросов, поэтому пользователям нужно помнить, что

Слайд 112К наиболее известным в мире системам веб-поиска относятся Google, Alta Vista, Norbern
К наиболее известным в мире системам веб-поиска относятся Google, Alta Vista, Norbern

Слайд 113По размерам баз данных (индексов) российские поисковые системы заметно проигрывают известным зарубежным,
По размерам баз данных (индексов) российские поисковые системы заметно проигрывают известным зарубежным,

Слайд 114поиск по ключевым словам дает слишком много ссылок, и многие из них

Слайд 115поисковые машины еще не столь совершенны, чтобы понимать естественный язык;
по тому
по тому

Слайд 116В последнее время потребности в интеллектуальной помощи быстро растут, помощь необходима для
В последнее время потребности в интеллектуальной помощи быстро растут, помощь необходима для

 Промени в хармонизираните изисквания за етикетиране на храни. Регламент на Европейския парламент и на Съвета относно предоставянето на потребителите на информация за храните Жана Величкова – началник отдел Дирекция “Техническа хармонизация и политика
Промени в хармонизираните изисквания за етикетиране на храни. Регламент на Европейския парламент и на Съвета относно предоставянето на потребителите на информация за храните Жана Величкова – началник отдел Дирекция “Техническа хармонизация и политика Классы органических веществ
Классы органических веществ Русский алфавит
Русский алфавит ПРОФЕССИОНАЛЬНОЕ САМООПРЕДЕЛЕНИЕ УЧАЩИХСЯ.
ПРОФЕССИОНАЛЬНОЕ САМООПРЕДЕЛЕНИЕ УЧАЩИХСЯ. Алексей Бродович и Harper's Bazaar
Алексей Бродович и Harper's Bazaar Судьба фразеологизма так же интересна, как и судьба человека
Судьба фразеологизма так же интересна, как и судьба человека Презентация на тему Использование фольклора в духовно-нравственном воспитании дошкольников
Презентация на тему Использование фольклора в духовно-нравственном воспитании дошкольников Числа в народном творчестве
Числа в народном творчестве Пионербол
Пионербол ЦЕЛЬ: РАСШИРИТЬ ЗНАНИЕ УЧАЩИХСЯ О ПРАВИЛЬНОМ ПИТАНИИ
ЦЕЛЬ: РАСШИРИТЬ ЗНАНИЕ УЧАЩИХСЯ О ПРАВИЛЬНОМ ПИТАНИИ Как подобрать планшет для игр
Как подобрать планшет для игр Компания ГлавКерамика - предприятие оптовой и розничной торговли, комплектации объектов строительства
Компания ГлавКерамика - предприятие оптовой и розничной торговли, комплектации объектов строительства Презентация на тему Принцип действия ламп накаливания
Презентация на тему Принцип действия ламп накаливания Международная политика России в отношении США
Международная политика России в отношении США Коллекция «Velvet Touch»
Коллекция «Velvet Touch» Презентация на тему Russia
Презентация на тему Russia  Автоматизация слогослияния
Автоматизация слогослияния Кампилобактериоз
Кампилобактериоз Презентация на тему Земля Луна
Презентация на тему Земля Луна  Роль психолога в период адаптации первоклассников
Роль психолога в период адаптации первоклассников Европейский Север России
Европейский Север России  Презентация на тему Витаминная семейка
Презентация на тему Витаминная семейка Черная металлургия мира
Черная металлургия мира Мышцы верхней конечности
Мышцы верхней конечности Relații. Proprietăți. Operații. Relații remarcabile
Relații. Proprietăți. Operații. Relații remarcabile Организация работы зон кухни, предназначенных для обработки сырья
Организация работы зон кухни, предназначенных для обработки сырья История школы
История школы Государственная символика Российской Федерации. География и право вокруг нас
Государственная символика Российской Федерации. География и право вокруг нас