- Linux работа с файлами

Содержание
- 2. Содержание Команды работы с файлами: echo cat more less joe * nano* grep find sed cmp
- 3. echo ЗАПИСАТЬ АРГУМЕНТЫ В СТАНДАРТНЫЙ ВЫВОД echo [OPTION]... [STRING]... Выводит строку string на стандартный вывод (stdout).
- 4. cat ОБЪЕДИНИТЬ И НАПЕЧАТАТЬ ФАЙЛЫ cat [OPTION] [FILE]... Утилита cat последовательно читает файлы и пишет их
- 5. less ОТОБРАЖЕНИЕ СОДЕРЖИМОГО ФАЙЛА less [options] files ... Быстрое и гибкое отображение, перемещение, поиск в больших
- 6. Команды управления в less Q :q Q :Q ZZ Выход e ^E j ^N CR DownArrow
- 7. Команды управления в less :p Перейти к предыдущему файлу :d Удалить файл из списка = ^G
- 8. grep ПОИСК ПО ШАБЛОНУ В ФАЙЛЕ grep [options] PATTERN [FILE...] Поиск совпадений по шаблону в указанных
- 9. grep ПОИСК ПО ШАБЛОНУ В ФАЙЛЕ -l, --files-with-matches Отображать только имена файлов с совпадениями -n, --line-number
- 10. Регулярные выражения (REGEXP) Регулярные выражения (regular expressions) – это система синтаксического разбора текстовых фрагментов по формализованному
- 11. Синтаксис REGEXP Обычные символы (текст) Метасимволы (специальные символы) [ ] \ ^ $ . | ?
- 12. Синтаксис REGEXP Позиция в строке Начало строки – «^», конец строки – «$» Граница слова –
- 13. grep -E Расширенное выражение REGEXP GREP_OPTIONS Аргументы командной строки $ grep -woE “[[:alnum:]]+” text | sort
- 14. find ПОИСК ФАЙЛОВ find путь ... выражение Утилита find рекурсивно спускается по дереву каталогов каждого пути,
- 15. find -newer file Файл имеет более свежее время модификации чем file -type type Если типом текущего
- 16. sed ПОТОКОВЫЙ РЕДАКТОР sed {[-e cmd]|cmd} [-f cmd_file] [-i extension] [file ...] Считывает указанные файлы или
- 17. cmp СРАВНИТЬ ДВА ФАЙЛА cmp файл1 файл2 [пропуск1 [пропуск2]] Утилита cmp сравнивает два файла файл1 и
- 18. diff СРАВНИТЬ ФАЙЛЫ ПОСТРОЧНО diff [OPTION]... FILES -i, --ignore-case Игнорировать разницу в регистре букв -b Игнорировать
- 19. patch НАЛОЖИТЬ ПАТЧ patch [options] [origfile [patchfile]] [+ [options] [origfile]]... patch [options] Утилита накладывает патч(заплатку), созданный
- 20. cp КОПИРОВАТЬ ФАЙЛЫ cp [-R] [-f | -i | -n] [-lpv] исходный_файл целевой_файл cp [-R] [-f
- 21. mv ПЕРЕМЕСТИТЬ ФАЙЛЫ mv [-f | -i] [-v] источник цель mv [-f | -i] [-v] источник
- 22. head ВЫВЕСТИ ПЕРВЫЕ СТРОКИ ФАЙЛА head [-n число | -c байт] [файл ...] Этот фильтр выводит
- 23. tail ВЫВЕСТИ ПОСЛЕДНЮЮ ЧАСТЬ ФАЙЛА tail [-F | -f | -r] [-q] [-b номер | -c
- 24. tee ДУБЛИРОВАТЬ СТАНДАРТНЫЙ ВВОД tee [-a] [файл ...] Утилита tee копирует стандартный ввод в стандартный вывод,
- 25. touch ИЗМЕНИТЬ ВРЕМЯ ДОСТУПА И МОДИФИКАЦИИ ФАЙЛА, СОЗДАТЬ ФАЙЛ touch [OPTION]... FILE... Установка времени модификации и
- 26. dd КОНВЕРТИРОВАТЬ И КОПИРОВАТЬ ФАЙЛ dd [operands ...] Утилита dd копирует стандартный ввод на стандартный вывод
- 27. tr ПРЕОБРАЗОВАТЬ СИМВОЛЫ tr [OPTION]... SET1 [SET2] Преобразование, сжатие и/или удаление символов со стандартного ввода в
- 28. cut ВЫРЕЗАТЬ ОПРЕДЕЛЁННЫЕ ЧАСТИ ИЗ КАЖДОЙ СТРОКИ ФАЙЛА cut -b список [файл ...] cut -c список
- 29. basename, dirname ВЕРНУТЬ ФАЙЛОВУЮ ИЛИ КАТАЛОГОВУЮ ЧАСТЬ ПУТИ basename NAME [SUFFIX] dirname NAME Утилита basename удаляет
- 30. wc ПОДСЧЁТ КОЛИЧЕСТВА СЛОВ, СТРОК, СИМВОЛОВ И БАЙТОВ wc [-clmw] [файл ...] Утилита wc пишет в
- 31. uniq ВЫВЕСТИ ИЛИ ОТФИЛЬТРОВАТЬ ПОВТОРЯЮЩИЕСЯ СТРОКИ В ФАЙЛЕ uniq [OPTION]... [INPUT [OUTPUT]] Утилита uniq читает вход_файл,
- 32. sort СОРТИРОВАТЬ СТРОКИ ТЕКСТОВЫХ ФАЙЛОВ sort [OPTION]... [FILE]... -f, --ignore-case Игнорировать регистр символов -M, --month-sort Сортировать
- 33. YES yes [STRING] yes — UNIX-команда, бесконечно выводящая аргументы командной строки, разделённые пробелами до тех пор,
- 34. softlink СИМВОЛЬНЫЕ ССЫЛКИ Символьная ссылка (также симлинк от англ. Symbolic link, символическая ссылка) — специальный файл
- 35. hardlink ЖЕСТКИЕ ССЫЛКИ Жёсткой ссылкой (англ. hard link) в UFS-совместимых файловых системах называется структурная составляющая файла
- 37. Скачать презентацию
Слайд 2Содержание
Команды работы с файлами:
echo
cat
more
less
joe *
nano*
grep
find
sed
cmp
diff
patch
touch
cp
mv
rm *
dd
head
tail
tee
cut
tr
echo(bash)
basename
dirname
wc
uniq
sort
yes *
Содержание
Команды работы с файлами:
echo
cat
more
less
joe *
nano*
grep
find
sed
cmp
diff
patch
touch
cp
mv
rm *
dd
head
tail
tee
cut
tr
echo(bash)
basename
dirname
wc
uniq
sort
yes *

Слайд 3echo
ЗАПИСАТЬ АРГУМЕНТЫ В СТАНДАРТНЫЙ ВЫВОД
echo [OPTION]... [STRING]...
Выводит строку string на стандартный вывод
echo
ЗАПИСАТЬ АРГУМЕНТЫ В СТАНДАРТНЫЙ ВЫВОД
echo [OPTION]... [STRING]...
Выводит строку string на стандартный вывод
![echo ЗАПИСАТЬ АРГУМЕНТЫ В СТАНДАРТНЫЙ ВЫВОД echo [OPTION]... [STRING]... Выводит строку string](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-2.jpg)
Слайд 4cat
ОБЪЕДИНИТЬ И НАПЕЧАТАТЬ ФАЙЛЫ
cat [OPTION] [FILE]...
Утилита cat последовательно читает файлы и пишет
cat
ОБЪЕДИНИТЬ И НАПЕЧАТАТЬ ФАЙЛЫ
cat [OPTION] [FILE]...
Утилита cat последовательно читает файлы и пишет
![cat ОБЪЕДИНИТЬ И НАПЕЧАТАТЬ ФАЙЛЫ cat [OPTION] [FILE]... Утилита cat последовательно читает](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-3.jpg)
Слайд 5less
ОТОБРАЖЕНИЕ СОДЕРЖИМОГО ФАЙЛА
less [options] files ...
Быстрое и гибкое отображение, перемещение, поиск в
less
ОТОБРАЖЕНИЕ СОДЕРЖИМОГО ФАЙЛА
less [options] files ...
Быстрое и гибкое отображение, перемещение, поиск в
![less ОТОБРАЖЕНИЕ СОДЕРЖИМОГО ФАЙЛА less [options] files ... Быстрое и гибкое отображение,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-4.jpg)
Слайд 6Команды управления в less
Q :q Q :Q ZZ Выход
e ^E j ^N CR
Команды управления в less
Q :q Q :Q ZZ Выход
e ^E j ^N CR

Слайд 7Команды управления в less
:p Перейти к предыдущему файлу
:d Удалить файл из списка
= ^G :f Отобразить
Команды управления в less
:p Перейти к предыдущему файлу
:d Удалить файл из списка
= ^G :f Отобразить

Слайд 8grep
ПОИСК ПО ШАБЛОНУ В ФАЙЛЕ
grep [options] PATTERN [FILE...]
Поиск совпадений по шаблону в
grep
ПОИСК ПО ШАБЛОНУ В ФАЙЛЕ
grep [options] PATTERN [FILE...]
Поиск совпадений по шаблону в
![grep ПОИСК ПО ШАБЛОНУ В ФАЙЛЕ grep [options] PATTERN [FILE...] Поиск совпадений](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-7.jpg)
Слайд 9grep
ПОИСК ПО ШАБЛОНУ В ФАЙЛЕ
-l, --files-with-matches Отображать только имена файлов с совпадениями
-n, --line-number Отображать
grep
ПОИСК ПО ШАБЛОНУ В ФАЙЛЕ
-l, --files-with-matches Отображать только имена файлов с совпадениями
-n, --line-number Отображать

Слайд 10Регулярные выражения (REGEXP)
Регулярные выражения (regular expressions) – это система синтаксического разбора текстовых
Регулярные выражения (REGEXP)
Регулярные выражения (regular expressions) – это система синтаксического разбора текстовых

Слайд 11Синтаксис REGEXP
Обычные символы (текст)
Метасимволы (специальные символы)
[ ] \ ^ $ .
Синтаксис REGEXP
Обычные символы (текст)
Метасимволы (специальные символы)
[ ] \ ^ $ .
![Синтаксис REGEXP Обычные символы (текст) Метасимволы (специальные символы) [ ] \ ^](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-10.jpg)
Слайд 12Синтаксис REGEXP
Позиция в строке
Начало строки – «^», конец строки – «$»
Граница
Синтаксис REGEXP
Позиция в строке
Начало строки – «^», конец строки – «$»
Граница

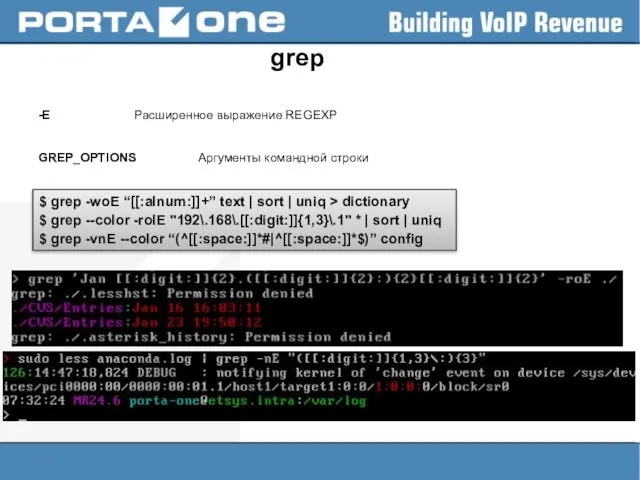
Слайд 13grep
-E Расширенное выражение REGEXP
GREP_OPTIONS Аргументы командной строки
$ grep -woE “[[:alnum:]]+” text | sort |
grep
-E Расширенное выражение REGEXP
GREP_OPTIONS Аргументы командной строки
$ grep -woE “[[:alnum:]]+” text | sort |
Слайд 14find
ПОИСК ФАЙЛОВ
find путь ... выражение
Утилита find рекурсивно спускается по дереву каталогов каждого
find
ПОИСК ФАЙЛОВ
find путь ... выражение
Утилита find рекурсивно спускается по дереву каталогов каждого

Слайд 15find
-newer file Файл имеет более свежее время модификации чем file
-type type Если типом текущего
find
-newer file Файл имеет более свежее время модификации чем file
-type type Если типом текущего

Слайд 16sed
ПОТОКОВЫЙ РЕДАКТОР
sed {[-e cmd]|cmd} [-f cmd_file] [-i extension] [file ...]
Считывает указанные файлы
sed
ПОТОКОВЫЙ РЕДАКТОР
sed {[-e cmd]|cmd} [-f cmd_file] [-i extension] [file ...]
Считывает указанные файлы
![sed ПОТОКОВЫЙ РЕДАКТОР sed {[-e cmd]|cmd} [-f cmd_file] [-i extension] [file ...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-15.jpg)
Слайд 17cmp
СРАВНИТЬ ДВА ФАЙЛА
cmp файл1 файл2 [пропуск1 [пропуск2]]
Утилита cmp сравнивает два файла файл1
cmp
СРАВНИТЬ ДВА ФАЙЛА
cmp файл1 файл2 [пропуск1 [пропуск2]]
Утилита cmp сравнивает два файла файл1
![cmp СРАВНИТЬ ДВА ФАЙЛА cmp файл1 файл2 [пропуск1 [пропуск2]] Утилита cmp сравнивает](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-16.jpg)
Слайд 18diff
СРАВНИТЬ ФАЙЛЫ ПОСТРОЧНО
diff [OPTION]... FILES
-i, --ignore-case Игнорировать разницу в регистре букв
-b Игнорировать разницу в
diff
СРАВНИТЬ ФАЙЛЫ ПОСТРОЧНО
diff [OPTION]... FILES
-i, --ignore-case Игнорировать разницу в регистре букв
-b Игнорировать разницу в
![diff СРАВНИТЬ ФАЙЛЫ ПОСТРОЧНО diff [OPTION]... FILES -i, --ignore-case Игнорировать разницу в](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-17.jpg)
Слайд 19patch
НАЛОЖИТЬ ПАТЧ
patch [options] [origfile [patchfile]] [+ [options] [origfile]]...
patch [options] < patchfile
Утилита накладывает
patch
НАЛОЖИТЬ ПАТЧ
patch [options] [origfile [patchfile]] [+ [options] [origfile]]...
patch [options] < patchfile
Утилита накладывает
![patch НАЛОЖИТЬ ПАТЧ patch [options] [origfile [patchfile]] [+ [options] [origfile]]... patch [options]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-18.jpg)
Слайд 20cp
КОПИРОВАТЬ ФАЙЛЫ
cp [-R] [-f | -i | -n] [-lpv] исходный_файл целевой_файл
cp [-R]
cp
КОПИРОВАТЬ ФАЙЛЫ
cp [-R] [-f | -i | -n] [-lpv] исходный_файл целевой_файл
cp [-R]
![cp КОПИРОВАТЬ ФАЙЛЫ cp [-R] [-f | -i | -n] [-lpv] исходный_файл](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-19.jpg)
Слайд 21mv
ПЕРЕМЕСТИТЬ ФАЙЛЫ
mv [-f | -i] [-v] источник цель
mv [-f | -i] [-v]
mv
ПЕРЕМЕСТИТЬ ФАЙЛЫ
mv [-f | -i] [-v] источник цель
mv [-f | -i] [-v]
![mv ПЕРЕМЕСТИТЬ ФАЙЛЫ mv [-f | -i] [-v] источник цель mv [-f](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-20.jpg)
Слайд 22head
ВЫВЕСТИ ПЕРВЫЕ СТРОКИ ФАЙЛА
head [-n число | -c байт] [файл ...]
Этот фильтр
head
ВЫВЕСТИ ПЕРВЫЕ СТРОКИ ФАЙЛА
head [-n число | -c байт] [файл ...]
Этот фильтр
![head ВЫВЕСТИ ПЕРВЫЕ СТРОКИ ФАЙЛА head [-n число | -c байт] [файл](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-21.jpg)
Слайд 23tail
ВЫВЕСТИ ПОСЛЕДНЮЮ ЧАСТЬ ФАЙЛА
tail [-F | -f | -r] [-q] [-b номер
tail
ВЫВЕСТИ ПОСЛЕДНЮЮ ЧАСТЬ ФАЙЛА
tail [-F | -f | -r] [-q] [-b номер
![tail ВЫВЕСТИ ПОСЛЕДНЮЮ ЧАСТЬ ФАЙЛА tail [-F | -f | -r] [-q]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-22.jpg)
Слайд 24tee
ДУБЛИРОВАТЬ СТАНДАРТНЫЙ ВВОД
tee [-a] [файл ...]
Утилита tee копирует стандартный ввод в стандартный
tee
ДУБЛИРОВАТЬ СТАНДАРТНЫЙ ВВОД
tee [-a] [файл ...]
Утилита tee копирует стандартный ввод в стандартный
![tee ДУБЛИРОВАТЬ СТАНДАРТНЫЙ ВВОД tee [-a] [файл ...] Утилита tee копирует стандартный](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-23.jpg)
Слайд 25touch
ИЗМЕНИТЬ ВРЕМЯ ДОСТУПА И МОДИФИКАЦИИ ФАЙЛА, СОЗДАТЬ ФАЙЛ
touch [OPTION]... FILE...
Установка времени модификации
touch
ИЗМЕНИТЬ ВРЕМЯ ДОСТУПА И МОДИФИКАЦИИ ФАЙЛА, СОЗДАТЬ ФАЙЛ
touch [OPTION]... FILE...
Установка времени модификации
![touch ИЗМЕНИТЬ ВРЕМЯ ДОСТУПА И МОДИФИКАЦИИ ФАЙЛА, СОЗДАТЬ ФАЙЛ touch [OPTION]... FILE...](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-24.jpg)
Слайд 26dd
КОНВЕРТИРОВАТЬ И КОПИРОВАТЬ ФАЙЛ
dd [operands ...]
Утилита dd копирует стандартный ввод на стандартный
dd
КОНВЕРТИРОВАТЬ И КОПИРОВАТЬ ФАЙЛ
dd [operands ...]
Утилита dd копирует стандартный ввод на стандартный
![dd КОНВЕРТИРОВАТЬ И КОПИРОВАТЬ ФАЙЛ dd [operands ...] Утилита dd копирует стандартный](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-25.jpg)
Слайд 27tr
ПРЕОБРАЗОВАТЬ СИМВОЛЫ
tr [OPTION]... SET1 [SET2]
Преобразование, сжатие и/или удаление символов со стандартного ввода
tr
ПРЕОБРАЗОВАТЬ СИМВОЛЫ
tr [OPTION]... SET1 [SET2]
Преобразование, сжатие и/или удаление символов со стандартного ввода
![tr ПРЕОБРАЗОВАТЬ СИМВОЛЫ tr [OPTION]... SET1 [SET2] Преобразование, сжатие и/или удаление символов](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-26.jpg)
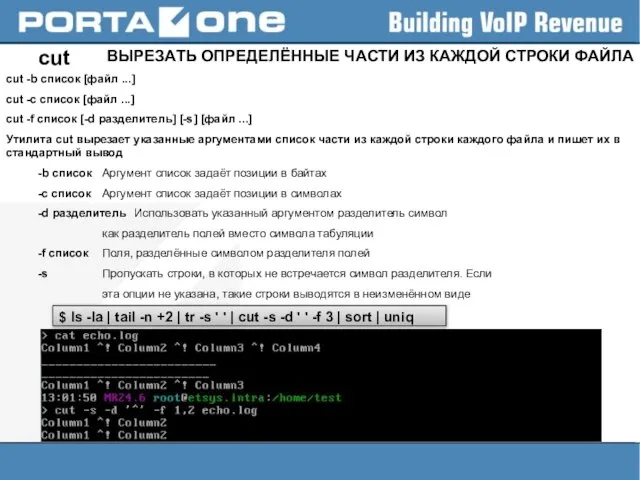
Слайд 28cut
ВЫРЕЗАТЬ ОПРЕДЕЛЁННЫЕ ЧАСТИ ИЗ КАЖДОЙ СТРОКИ ФАЙЛА
cut -b список [файл ...]
cut -c
cut
ВЫРЕЗАТЬ ОПРЕДЕЛЁННЫЕ ЧАСТИ ИЗ КАЖДОЙ СТРОКИ ФАЙЛА
cut -b список [файл ...]
cut -c
Слайд 29basename, dirname
ВЕРНУТЬ ФАЙЛОВУЮ ИЛИ КАТАЛОГОВУЮ ЧАСТЬ ПУТИ
basename NAME [SUFFIX]
dirname NAME
Утилита basename удаляет
basename, dirname
ВЕРНУТЬ ФАЙЛОВУЮ ИЛИ КАТАЛОГОВУЮ ЧАСТЬ ПУТИ
basename NAME [SUFFIX]
dirname NAME
Утилита basename удаляет
![basename, dirname ВЕРНУТЬ ФАЙЛОВУЮ ИЛИ КАТАЛОГОВУЮ ЧАСТЬ ПУТИ basename NAME [SUFFIX] dirname](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-28.jpg)
Слайд 30wc
ПОДСЧЁТ КОЛИЧЕСТВА СЛОВ, СТРОК, СИМВОЛОВ И БАЙТОВ
wc [-clmw] [файл ...]
Утилита wc пишет
wc
ПОДСЧЁТ КОЛИЧЕСТВА СЛОВ, СТРОК, СИМВОЛОВ И БАЙТОВ
wc [-clmw] [файл ...]
Утилита wc пишет
![wc ПОДСЧЁТ КОЛИЧЕСТВА СЛОВ, СТРОК, СИМВОЛОВ И БАЙТОВ wc [-clmw] [файл ...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-29.jpg)
Слайд 31uniq
ВЫВЕСТИ ИЛИ ОТФИЛЬТРОВАТЬ ПОВТОРЯЮЩИЕСЯ СТРОКИ В ФАЙЛЕ
uniq [OPTION]... [INPUT [OUTPUT]]
Утилита uniq читает
uniq
ВЫВЕСТИ ИЛИ ОТФИЛЬТРОВАТЬ ПОВТОРЯЮЩИЕСЯ СТРОКИ В ФАЙЛЕ
uniq [OPTION]... [INPUT [OUTPUT]]
Утилита uniq читает
![uniq ВЫВЕСТИ ИЛИ ОТФИЛЬТРОВАТЬ ПОВТОРЯЮЩИЕСЯ СТРОКИ В ФАЙЛЕ uniq [OPTION]... [INPUT [OUTPUT]]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-30.jpg)
Слайд 32sort
СОРТИРОВАТЬ СТРОКИ ТЕКСТОВЫХ ФАЙЛОВ
sort [OPTION]... [FILE]...
-f, --ignore-case Игнорировать регистр символов
-M, --month-sort Сортировать как названия
sort
СОРТИРОВАТЬ СТРОКИ ТЕКСТОВЫХ ФАЙЛОВ
sort [OPTION]... [FILE]...
-f, --ignore-case Игнорировать регистр символов
-M, --month-sort Сортировать как названия
![sort СОРТИРОВАТЬ СТРОКИ ТЕКСТОВЫХ ФАЙЛОВ sort [OPTION]... [FILE]... -f, --ignore-case Игнорировать регистр](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-31.jpg)
Слайд 33YES
yes [STRING]
yes — UNIX-команда, бесконечно выводящая аргументы командной строки, разделённые пробелами до
YES
yes [STRING]
yes — UNIX-команда, бесконечно выводящая аргументы командной строки, разделённые пробелами до
![YES yes [STRING] yes — UNIX-команда, бесконечно выводящая аргументы командной строки, разделённые](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/380773/slide-32.jpg)
Слайд 34softlink
СИМВОЛЬНЫЕ ССЫЛКИ
Символьная ссылка (также симлинк от англ. Symbolic link, символическая ссылка) —
softlink
СИМВОЛЬНЫЕ ССЫЛКИ
Символьная ссылка (также симлинк от англ. Symbolic link, символическая ссылка) —

Слайд 35hardlink
ЖЕСТКИЕ ССЫЛКИ
Жёсткой ссылкой (англ. hard link) в UFS-совместимых файловых системах называется структурная
hardlink
ЖЕСТКИЕ ССЫЛКИ
Жёсткой ссылкой (англ. hard link) в UFS-совместимых файловых системах называется структурная

 КУРСОВАЯ РАБОТА по дисциплине «Контракты в международной торговле» на тему «Особенности заключения и исполнения договоров перев
КУРСОВАЯ РАБОТА по дисциплине «Контракты в международной торговле» на тему «Особенности заключения и исполнения договоров перев ИНФОРМАЦИОННАЯ СПРАВКА
ИНФОРМАЦИОННАЯ СПРАВКА Путешествие в Архангельскую область
Путешествие в Архангельскую область Н.В.Гоголь Поэма «Мёртвые души»
Н.В.Гоголь Поэма «Мёртвые души» До свидания начальная школа
До свидания начальная школа Тепловые двигатели и их применение
Тепловые двигатели и их применение Почему мы все разные ?
Почему мы все разные ? Приоритетные современные направленияучета в России
Приоритетные современные направленияучета в России Зимующие птицы Московской области
Зимующие птицы Московской области Реакции в искусстве
Реакции в искусстве Класс Многощетинковые черви (Полихеты)
Класс Многощетинковые черви (Полихеты) Фасады зданий
Фасады зданий В гости к зиме (2 класс)
В гости к зиме (2 класс) Создание робота. Extra IQ
Создание робота. Extra IQ Вид рекламных услугРазмер, количество/ тираж Период размещения Место размещения Предоставление компании статуса «Генеральный сп
Вид рекламных услугРазмер, количество/ тираж Период размещения Место размещения Предоставление компании статуса «Генеральный сп Конкурс. Чем занимается психолог
Конкурс. Чем занимается психолог Управление рисками проекта
Управление рисками проекта Афинский акрополь
Афинский акрополь Презентация на тему Изображение рельефа на географической карте
Презентация на тему Изображение рельефа на географической карте УМК «Школа России»
УМК «Школа России» Чувства, их внешнее проявление, условия формирования
Чувства, их внешнее проявление, условия формирования Красная книга Ленинградской области
Красная книга Ленинградской области Национальная кухня Германии
Национальная кухня Германии Доступность лекарств для лечения бронхиальной астмы в рамках Программы Государственных Гарантий Исполнитель: ОО «Легочное здоро
Доступность лекарств для лечения бронхиальной астмы в рамках Программы Государственных Гарантий Исполнитель: ОО «Легочное здоро Презентация на тему Архитектура Древнего Египта
Презентация на тему Архитектура Древнего Египта Деление дробных чисел
Деление дробных чисел А я все чаще замечаю, что скоро в армию пойду
А я все чаще замечаю, что скоро в армию пойду ТРЕНИЕ СИЛА ТРЕНИЯ
ТРЕНИЕ СИЛА ТРЕНИЯ