- Метод скользящего контроля для оценки качества рекомендательных интернет-сервисов

Содержание
- 2. Содержание Постановка задачи Мотивация Примеры моделей рекомендательных систем User-based RS Item-based RS Выбор меры (метрики) сходства
- 3. Постановка задачи Зная предпочтения конкретного пользователя и остальных, выдать ему релевантную рекомендацию Оценка (проверка) качества рекомендаций
- 4. Мотивация Существует огромное количество РС Требуются эффективные алгоритмы Время выполнения Качество рекомендаций Количество ошибок и полнота
- 5. User-based RS целевой пользователь - предметы, которые он оценивал - сходство с пользователем - top-n ближайших
- 6. Item-based RS целевой пользователь - предметы, которые он оценивал - сходство товара i с товаром j
- 7. Пример User-based RS
- 8. Выбор меры (метрики) сходства Сходство, основанное на расстоянии: Евклида Хемминга Корреляция как сходство: коэффициент Пирсона Косинусная
- 9. Корреляция Пирсона Недостатки не определена на векторах с постоянными значениями: (4,4,4,...,4) теряются рекомендации a=(0,5,5,4) b=(0,4,5,0)
- 10. Методика сравнения Метрики качества: точность и полнота рекомендаций Скользящий контроль (кросс-валидация)
- 11. Точность и полнота Полнота – число релевантных рекомендаций к числу всех выбранных пользователем товаров Точность –
- 12. Скользящий контроль Разбиение на тестовую и обучающую выборки: Сокрытие признаков для тестирования рекомендаций: Вычисление точности и
- 13. Точность и полнота: раскрытие неопределенностей else
- 14. Алгоритм Параметры: test% - размер тестового множества hidden% - размер скрытого множества признаков p – число
- 15. Данные MovieLens и Yahoo MovieLens 100K dataset: 943 пользователя 1,682 фильма Каждый оценил как минимум 20
- 16. Результаты
- 17. Результаты
- 18. Результаты
- 19. Результаты
- 20. Результаты
- 21. Результаты
- 22. Результаты
- 23. Выводы и дальнейшая работа Предложенная методика позволяет оценить качество работы рекомендательной системы вне зависимости от выбора
- 25. Скачать презентацию
Слайд 2Содержание
Постановка задачи
Мотивация
Примеры моделей рекомендательных систем
User-based RS
Item-based RS
Выбор меры (метрики) сходства
Методика сравнения
Данные MovieLens
Содержание
Постановка задачи
Мотивация
Примеры моделей рекомендательных систем
User-based RS
Item-based RS
Выбор меры (метрики) сходства
Методика сравнения
Данные MovieLens

Слайд 3Постановка задачи
Зная предпочтения конкретного пользователя и остальных, выдать ему релевантную рекомендацию
Оценка (проверка)
Постановка задачи
Зная предпочтения конкретного пользователя и остальных, выдать ему релевантную рекомендацию
Оценка (проверка)

Слайд 4Мотивация
Существует огромное количество РС
Требуются эффективные алгоритмы
Время выполнения
Качество рекомендаций
Количество ошибок и полнота рекомендаций
Мотивация
Существует огромное количество РС
Требуются эффективные алгоритмы
Время выполнения
Качество рекомендаций
Количество ошибок и полнота рекомендаций

Слайд 5User-based RS
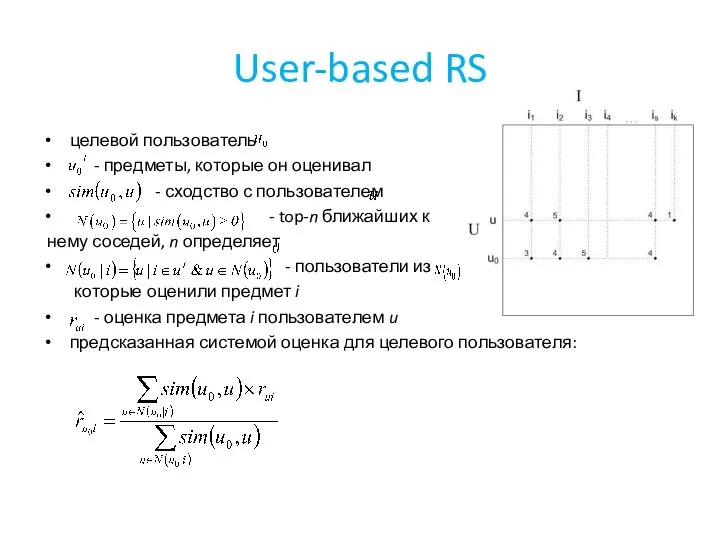
целевой пользователь
- предметы, которые он оценивал
- сходство
User-based RS
целевой пользователь
- предметы, которые он оценивал
- сходство
Слайд 6Item-based RS
целевой пользователь
- предметы, которые он оценивал
- сходство
Item-based RS
целевой пользователь
- предметы, которые он оценивал
- сходство

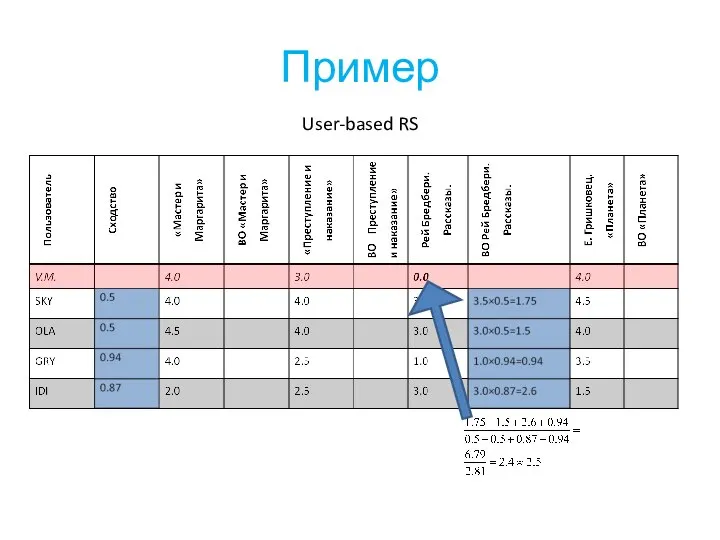
Слайд 7Пример
User-based RS
Пример
User-based RS
Слайд 8
Выбор меры (метрики) сходства
Сходство, основанное на расстоянии:
Евклида
Хемминга
Корреляция как сходство:
коэффициент Пирсона
Косинусная мера
Коэффициент
Выбор меры (метрики) сходства
Сходство, основанное на расстоянии:
Евклида
Хемминга
Корреляция как сходство:
коэффициент Пирсона
Косинусная мера
Коэффициент

Слайд 9Корреляция Пирсона
Недостатки
не определена на векторах с постоянными значениями: (4,4,4,...,4)
теряются рекомендации
Корреляция Пирсона
Недостатки
не определена на векторах с постоянными значениями: (4,4,4,...,4)
теряются рекомендации

Слайд 10
Методика сравнения
Метрики качества: точность и полнота рекомендаций
Скользящий контроль (кросс-валидация)
Методика сравнения
Метрики качества: точность и полнота рекомендаций
Скользящий контроль (кросс-валидация)

Слайд 11Точность и полнота
Полнота – число релевантных рекомендаций к числу всех выбранных пользователем
Точность и полнота
Полнота – число релевантных рекомендаций к числу всех выбранных пользователем

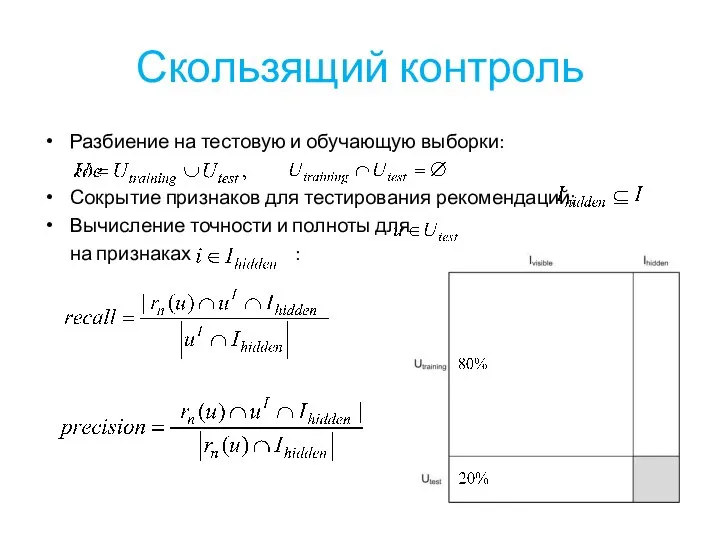
Слайд 12Скользящий контроль
Разбиение на тестовую и обучающую выборки:
Сокрытие признаков для тестирования рекомендаций:
Вычисление точности
Скользящий контроль
Разбиение на тестовую и обучающую выборки:
Сокрытие признаков для тестирования рекомендаций:
Вычисление точности
Слайд 13Точность и полнота: раскрытие неопределенностей
else
Точность и полнота: раскрытие неопределенностей
else

Слайд 14Алгоритм
Параметры:
test% - размер тестового множества
hidden% - размер скрытого множества признаков
p – число
Алгоритм
Параметры:
test% - размер тестового множества
hidden% - размер скрытого множества признаков
p – число

Слайд 15
Данные MovieLens и Yahoo
MovieLens 100K dataset:
943 пользователя
1,682 фильма
Каждый оценил как минимум 20
Данные MovieLens и Yahoo
MovieLens 100K dataset:
943 пользователя
1,682 фильма
Каждый оценил как минимум 20

Слайд 16Результаты
Результаты
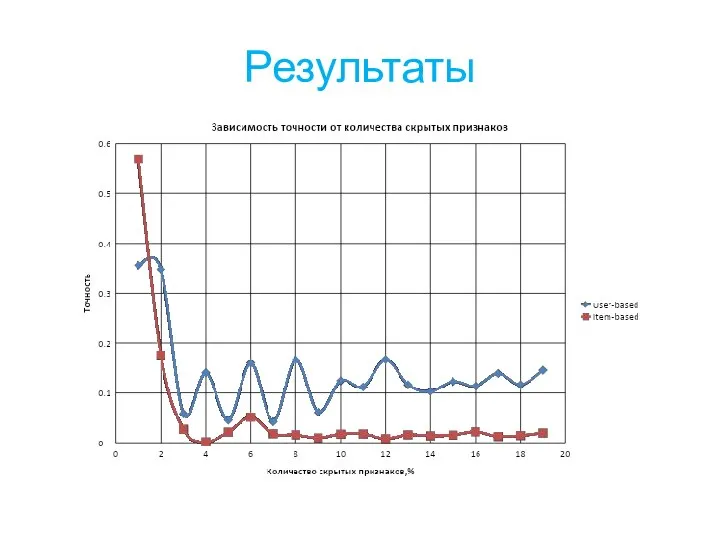
Слайд 17Результаты
Результаты
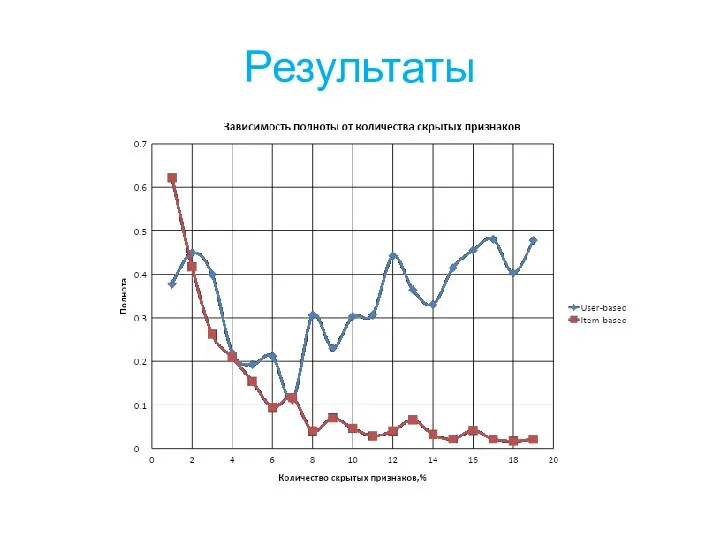
Слайд 18Результаты
Результаты
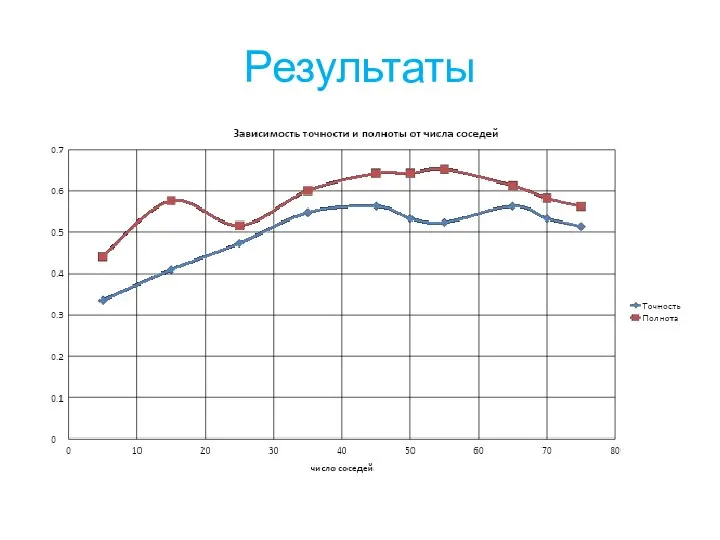
Слайд 19Результаты
Результаты
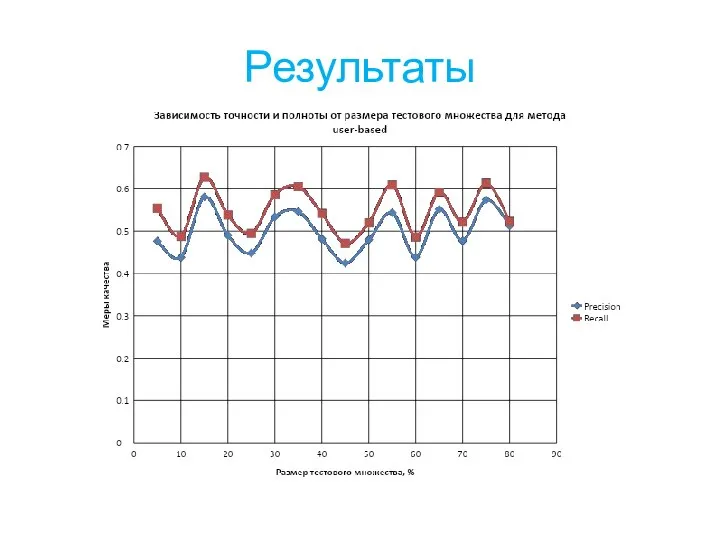
Слайд 20Результаты
Результаты
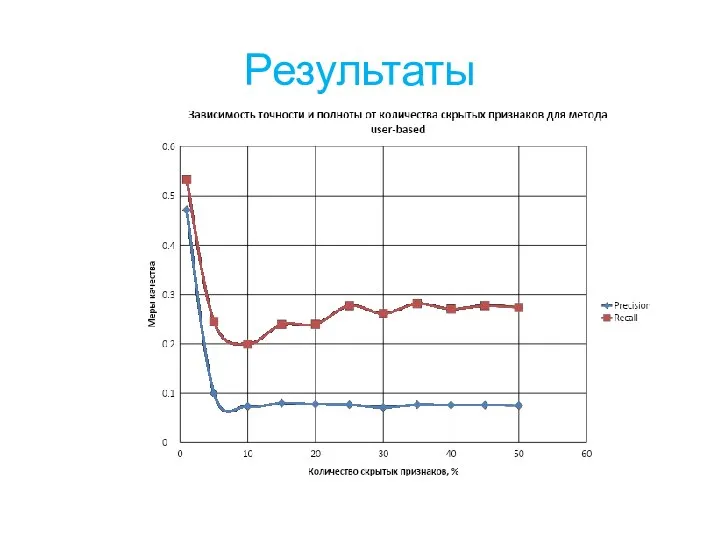
Слайд 21Результаты
Результаты
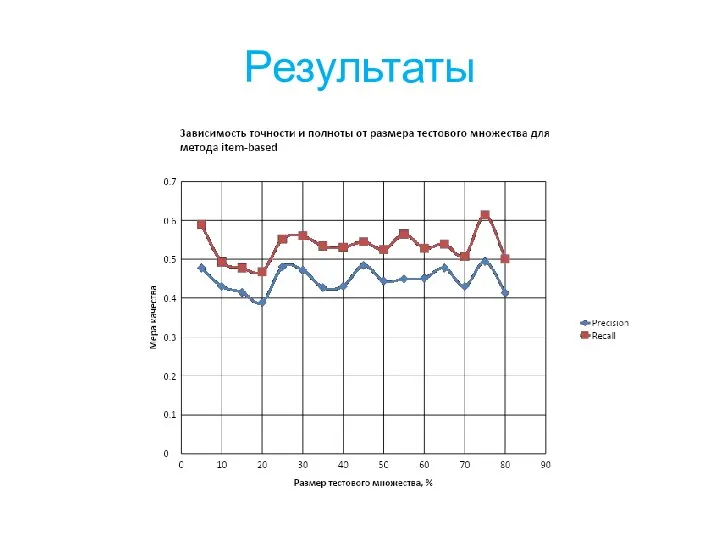
Слайд 22Результаты
Результаты
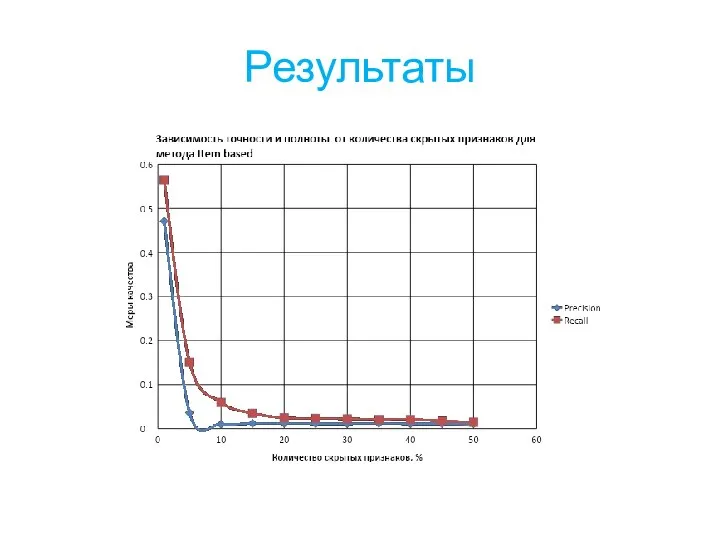
Слайд 23Выводы и дальнейшая работа
Предложенная методика позволяет оценить качество работы рекомендательной системы вне
Выводы и дальнейшая работа
Предложенная методика позволяет оценить качество работы рекомендательной системы вне

 Комиссии по улучшению инвестиционного климата, снижению административных барьеров и развитию малого и среднего предпринимательс
Комиссии по улучшению инвестиционного климата, снижению административных барьеров и развитию малого и среднего предпринимательс Правомерное поведение и правонарушения
Правомерное поведение и правонарушения Презентация на тему Музыка начала ХХ века
Презентация на тему Музыка начала ХХ века  Спортивный клуб Политехник
Спортивный клуб Политехник Расчет тихоходного вала одноступенчатого цилиндрического редуктора
Расчет тихоходного вала одноступенчатого цилиндрического редуктора "Новые подходы в области сервиса при ипотечном кредитовании"
"Новые подходы в области сервиса при ипотечном кредитовании" Понятие и признаки субъекта преступления в доктрине уголовного права
Понятие и признаки субъекта преступления в доктрине уголовного права Аномалии развития и заболевания плода
Аномалии развития и заболевания плода Презентация к конкурсу «Педагогический дебют»
Презентация к конкурсу «Педагогический дебют» Характер и особенности ментальности русского человека
Характер и особенности ментальности русского человека  Славянская мифология
Славянская мифология BusyFly platform. Запуск кикшеринга. Четыре бизнес-решения
BusyFly platform. Запуск кикшеринга. Четыре бизнес-решения Что такое химия
Что такое химия Что скрывается в кружке чая?
Что скрывается в кружке чая? Тема: «Коммуникационные технологии »
Тема: «Коммуникационные технологии » Кейсы - необходимый элемент образования
Кейсы - необходимый элемент образования Политические реформы 1860-1870-х годов
Политические реформы 1860-1870-х годов Всего семь нот, а столько славных песен
Всего семь нот, а столько славных песен DVIZH_Present_Perfect (1)
DVIZH_Present_Perfect (1) Влияние возраста пациентов на ангиогенные свойства мезенхимальных стволовых клеток жировой ткани
Влияние возраста пациентов на ангиогенные свойства мезенхимальных стволовых клеток жировой ткани Что такое электричество (4 класс)
Что такое электричество (4 класс) Свобода воли, нейронаука, пришельцы и роботы
Свобода воли, нейронаука, пришельцы и роботы Прялки
Прялки Подростковый возраст
Подростковый возраст Периодическая система химических элементов Д.И. Менделеева
Периодическая система химических элементов Д.И. Менделеева История немецкого театрального искусства в России
История немецкого театрального искусства в России Примеры задач с циклами while и repeat
Примеры задач с циклами while и repeat корпоративное мероприятие для…
корпоративное мероприятие для…