- Методы искусственного интеллекта

Содержание
- 2. 1. НАПРАВЛЕНИЯ
- 3. ПОДРАЗДЕЛЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
- 4. ОБРАБОТКА ЕСТЕСТВЕННОГО ЯЗЫКА a. Синтаксис b. Поиск c. Семантика d. Векторная модель и машинное обучение
- 5. СИНТАКСИС Формальные грамматики, грамматики Хомского Прагматика, семантика и синтаксис Применение синтаксиса для токенизации Применения синтаксиса для
- 6. 21.09.2021 — https://yandex.ru/dev/tomita/ — парсер для русского — https://github.com/natasha/natasha — NLP-библиотека для русского — https://github.com/kmike/pymorphy2 —
- 7. ПОИСК Предобработка текста Построение поискового индекса Выполнение запроса Закон Ципфа и его влияние на селективность и
- 8. ПОИСК Предобработка текста Построение поискового индекса Выполнение запроса Закон Ципфа и его влияние на селективность и
- 9. СЕМАНТИКА Дистрибутивная гипотеза и избыточность языка На небе только и разговоров , что о море и
- 10. СЕМАНТИКА Векторная модель : концепты , ортогональность и метрика Vector Space Model (VSM) – это математическая
- 11. 2. ВЕКТОРНЫЕ МОДЕЛИ И МАШИННОЕ ОБУЧЕНИЕ
- 12. 21.09.2021 ЗАДАЧА Метод главных компонент рассматривает текст как мешок слов . Для коротких текстов это работает
- 13. 21.09.2021 В УГОДУ СКОРОСТИ Натренированные векторные представления: EN: English word vectors · fastText RU: natasha/navec; RusVectōrēs:
- 14. 3. GOOGLE COLAB NOTEBOOK
- 15. ТЕСТ Почему использование Jupyter Notebooks и Google Colab для упаковки кода и текстов сейчас наиболее распространена
- 16. ТЕСТ Почему использование Jupyter Notebooks и Google Colab для упаковки кода и текстов сейчас наиболее распространена
- 18. Скачать презентацию

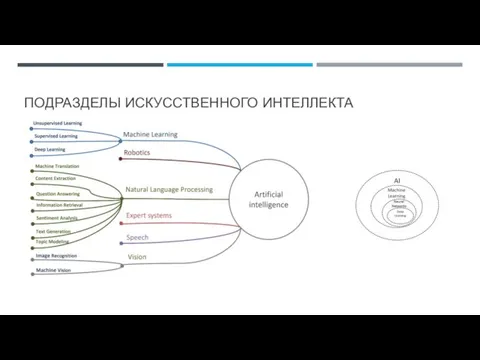
Слайд 3ПОДРАЗДЕЛЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
ПОДРАЗДЕЛЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Слайд 4ОБРАБОТКА ЕСТЕСТВЕННОГО ЯЗЫКА
a. Синтаксис
b. Поиск
c. Семантика
d. Векторная модель и машинное обучение
ОБРАБОТКА ЕСТЕСТВЕННОГО ЯЗЫКА
a. Синтаксис
b. Поиск
c. Семантика
d. Векторная модель и машинное обучение

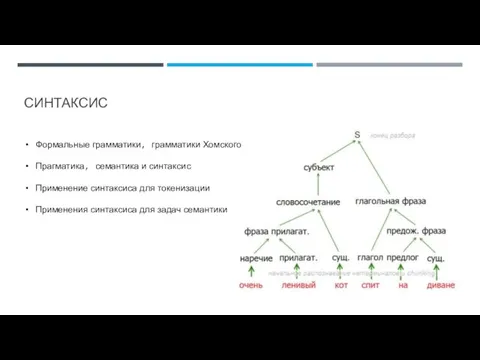
Слайд 5СИНТАКСИС
Формальные грамматики, грамматики Хомского
Прагматика, семантика и синтаксис
Применение синтаксиса для токенизации
Применения синтаксиса для
СИНТАКСИС
Формальные грамматики, грамматики Хомского
Прагматика, семантика и синтаксис
Применение синтаксиса для токенизации
Применения синтаксиса для
Слайд 621.09.2021
— https://yandex.ru/dev/tomita/ — парсер для русского
— https://github.com/natasha/natasha — NLP-библиотека для русского
— https://github.com/kmike/pymorphy2
21.09.2021
— https://yandex.ru/dev/tomita/ — парсер для русского
— https://github.com/natasha/natasha — NLP-библиотека для русского
— https://github.com/kmike/pymorphy2

Слайд 7ПОИСК
Предобработка текста
Построение поискового индекса
Выполнение запроса
Закон Ципфа и его влияние на селективность и
ПОИСК
Предобработка текста
Построение поискового индекса
Выполнение запроса
Закон Ципфа и его влияние на селективность и

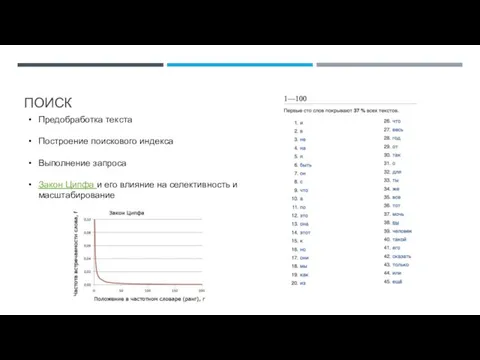
Слайд 8ПОИСК
Предобработка текста
Построение поискового индекса
Выполнение запроса
Закон Ципфа и его влияние на селективность и
ПОИСК
Предобработка текста
Построение поискового индекса
Выполнение запроса
Закон Ципфа и его влияние на селективность и
Слайд 9СЕМАНТИКА
Дистрибутивная гипотеза и избыточность языка
На небе только и разговоров , что
СЕМАНТИКА
Дистрибутивная гипотеза и избыточность языка
На небе только и разговоров , что

Слайд 10СЕМАНТИКА
Векторная модель : концепты , ортогональность и метрика
Vector Space Model (VSM)
СЕМАНТИКА
Векторная модель : концепты , ортогональность и метрика
Vector Space Model (VSM)

Слайд 112. ВЕКТОРНЫЕ МОДЕЛИ И МАШИННОЕ ОБУЧЕНИЕ
2. ВЕКТОРНЫЕ МОДЕЛИ И МАШИННОЕ ОБУЧЕНИЕ

Слайд 1221.09.2021
ЗАДАЧА
Метод главных компонент рассматривает текст как мешок слов . Для коротких текстов
21.09.2021
ЗАДАЧА
Метод главных компонент рассматривает текст как мешок слов . Для коротких текстов

Слайд 1321.09.2021
В УГОДУ СКОРОСТИ
Натренированные векторные представления:
EN: English word vectors · fastText
RU: natasha/navec; RusVectōrēs:
21.09.2021
В УГОДУ СКОРОСТИ
Натренированные векторные представления:
EN: English word vectors · fastText
RU: natasha/navec; RusVectōrēs:
Слайд 143. GOOGLE COLAB NOTEBOOK
3. GOOGLE COLAB NOTEBOOK

Слайд 15ТЕСТ
Почему использование Jupyter Notebooks и Google Colab для упаковки кода и текстов
ТЕСТ
Почему использование Jupyter Notebooks и Google Colab для упаковки кода и текстов

Слайд 16ТЕСТ
Почему использование Jupyter Notebooks и Google Colab для упаковки кода и текстов
ТЕСТ
Почему использование Jupyter Notebooks и Google Colab для упаковки кода и текстов

 Простое прошедшее время
Простое прошедшее время Народный русский костюм
Народный русский костюм Три состояния воды
Три состояния воды Потолочные системы
Потолочные системы Сообщество краткосрочная стратегическая терапия
Сообщество краткосрочная стратегическая терапия Ремонт электролизёров на месте установки
Ремонт электролизёров на месте установки Проектное управление
Проектное управление Итоги рубежной аттестации на специальности 140448 «Техническая эксплуатация и обслуживание электрического и электромеханического
Итоги рубежной аттестации на специальности 140448 «Техническая эксплуатация и обслуживание электрического и электромеханического  Презентация на тему Культура самураев
Презентация на тему Культура самураев  Поддержи свое здоровье. Стань на 10 лет моложе. Программа по снижению веса
Поддержи свое здоровье. Стань на 10 лет моложе. Программа по снижению веса Объявление. В охранную службу ООО ЧОО Страж требуются охранники
Объявление. В охранную службу ООО ЧОО Страж требуются охранники ПУТЕШЕСТВИЕ ПО МАТЕРИКАМ
ПУТЕШЕСТВИЕ ПО МАТЕРИКАМ Проблема текста
Проблема текста Weihnachtskarten. Dezember feiern die Deutschen Weihnachten. An diesem Tag ist Jesus Christus geboren
Weihnachtskarten. Dezember feiern die Deutschen Weihnachten. An diesem Tag ist Jesus Christus geboren Make your soul happy here
Make your soul happy here Проверка фактического проведения работы с персоналом. Вопрос №5
Проверка фактического проведения работы с персоналом. Вопрос №5 Отдых в Daima biz
Отдых в Daima biz Стройкузбасс. Почему не получается с первого раза
Стройкузбасс. Почему не получается с первого раза Россия рубежа XIX – XX веков
Россия рубежа XIX – XX веков Сохранение жизни и здоровья работников – приоритетное направление государственной политики в области охраны труда Заместитель
Сохранение жизни и здоровья работников – приоритетное направление государственной политики в области охраны труда Заместитель  DeVita Cosmo - цифровое устройство оздоровления
DeVita Cosmo - цифровое устройство оздоровления Гипсонаполненные системы строительных смесях
Гипсонаполненные системы строительных смесях «Завоевание» или «присоединение» Сибири? Распространение русского владычества и русской колонизации в Сибири, прерванное Смутой
«Завоевание» или «присоединение» Сибири? Распространение русского владычества и русской колонизации в Сибири, прерванное Смутой  Санкт - Петербург - мировой город
Санкт - Петербург - мировой город Куклы Тильды
Куклы Тильды ПОДТВЕРЖДЕНИЕ СООТВЕСТВИЯ
ПОДТВЕРЖДЕНИЕ СООТВЕСТВИЯ Понятие уголовного права
Понятие уголовного права Мой любимый учитель
Мой любимый учитель