- Моделирование контентных сетей

Содержание
- 2. Complex Networks В настоящее время наряду с традиционным теориями графов, систем и сетей массового обслуживания активно
- 3. Основы концепции Практически все современные сети можно считать сложными. Так, например, известная задача синтеза топологии сети
- 4. Направления теории сложных сетей В теории сложных сетей выделяют три основных направления: - исследование статистических свойств,
- 5. Параметры сложных сетей В прикладных исследованиях обычно применяют такие типичные для сетевого анализа характеристики, как размер
- 6. Параметры узлов сети Выделяют следующие параметры: входная степень связности узла – количество ребер, которые входят в
- 7. Общие параметры сети Наиболее часто используются такие параметры: количество узлов, число ребер, среднее расстояние от одного
- 8. Распределение степеней связности узлов Важной характеристикой сети является функция распределения степеней узлов P(k), которая определяется как
- 9. Путь между узлами Если два узла i и j можно соединить с помощью последовательности из m
- 10. Глобальная эффективность Некоторые сети могут оказаться несвязными. Соответственно, средний путь может оказаться также равным бесконечности. Для
- 11. Коэффициент кластеризации Дункан Уаттс и Стив Строгатц определили коэффициент кластерности, который Данный Коэффициент характеризует тенденцию к
- 12. Сложные сети и задачи компьютерной лингвистики Первым шагом при применении теории сложных сетей к анализу текста
- 13. Простейшие типы сетей в лингвистике L-пространство. Связываются соседние слова, которые принадлежат одному предложению. Количество соседей для
- 14. Экспериментальные данные В случае рассмотрения L-пространства языка количество соседних слов, между которыми строятся связи, определяется параметром
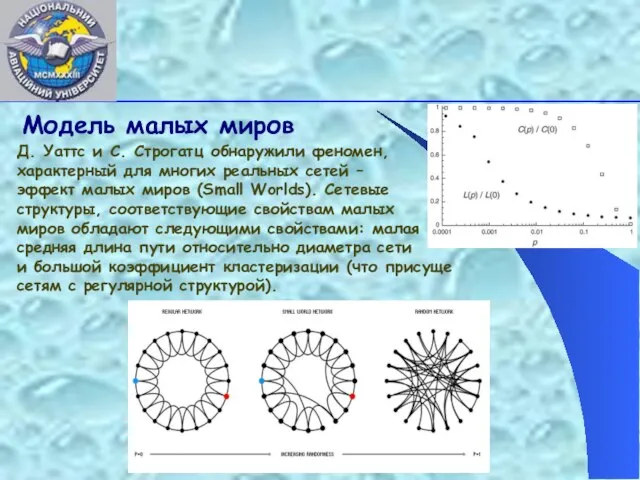
- 15. Модель малых миров Д. Уаттс и С. Строгатц обнаружили феномен, характерный для многих реальных сетей –
- 16. Модель случайной сети Эрдоша-Рени Существует две модели классического случайного графа: в первой считается, что M ребер
- 17. Модель случайной сети Барабаши-Альберта Сценарий базируется на двух механизмах – росте и преимущественном присоединении (preferentіal attachment).
- 18. Сложные сети с заданным распределением формируется степенная последовательность, выбирая N чисел ki согласно заданному распределению; -
- 19. Алгоритм построения контентной сети Алгоритм Барабаши-Альберта позволяет генерировать сети со степенным распределением, однако эти сети слишком
- 20. Распределения в модели Изначально предполагается, что распределение количества документов по узлам – степенное (аналог – распределение
- 21. Основные шаги алгоритма 1. Выбирается количество узлов сети N; 2. Для каждого узла генерируется число, соответствующее
- 22. Преимущества модели 1. Ориентация на контент документов при установлении связей (построении ребер); 2. При построении сети
- 23. Решаемые задачи Полученная в результате моделирования сеть, обладает многими параметрами, близкими к реальной сети, что по-видимому,
- 25. Скачать презентацию

Слайд 3Основы концепции
Практически все современные сети можно считать сложными. Так, например, известная
Основы концепции
Практически все современные сети можно считать сложными. Так, например, известная

Слайд 4Направления теории сложных сетей
В теории сложных сетей выделяют три основных направления:
Направления теории сложных сетей
В теории сложных сетей выделяют три основных направления:

Слайд 5Параметры сложных сетей
В прикладных исследованиях обычно применяют такие типичные для сетевого
Параметры сложных сетей
В прикладных исследованиях обычно применяют такие типичные для сетевого

Слайд 6Параметры узлов сети
Выделяют следующие параметры:
входная степень связности узла – количество
Параметры узлов сети
Выделяют следующие параметры:
входная степень связности узла – количество

Слайд 7Общие параметры сети
Наиболее часто используются такие параметры:
количество узлов, число ребер,
Общие параметры сети
Наиболее часто используются такие параметры:
количество узлов, число ребер,

Слайд 8Распределение степеней
связности узлов
Важной характеристикой сети является функция распределения степеней узлов
Распределение степеней
связности узлов
Важной характеристикой сети является функция распределения степеней узлов

Слайд 9Путь между узлами
Если два узла i и j можно соединить с помощью
Путь между узлами
Если два узла i и j можно соединить с помощью

Слайд 10Глобальная эффективность
Некоторые сети могут оказаться несвязными. Соответственно, средний путь может оказаться также
Глобальная эффективность
Некоторые сети могут оказаться несвязными. Соответственно, средний путь может оказаться также

Слайд 11Коэффициент кластеризации
Дункан Уаттс и Стив Строгатц определили
коэффициент кластерности, который Данный
Коэффициент характеризует тенденцию
Коэффициент кластеризации
Дункан Уаттс и Стив Строгатц определили
коэффициент кластерности, который Данный
Коэффициент характеризует тенденцию

Слайд 12Сложные сети и задачи компьютерной лингвистики
Первым шагом при применении теории сложных
Сложные сети и задачи компьютерной лингвистики
Первым шагом при применении теории сложных

Слайд 13Простейшие типы сетей в лингвистике
L-пространство. Связываются соседние слова, которые принадлежат одному предложению.
Простейшие типы сетей в лингвистике
L-пространство. Связываются соседние слова, которые принадлежат одному предложению.

Слайд 14Экспериментальные данные
В случае рассмотрения L-пространства языка количество соседних слов, между которыми строятся
Экспериментальные данные
В случае рассмотрения L-пространства языка количество соседних слов, между которыми строятся

Слайд 15Модель малых миров
Д. Уаттс и С. Строгатц обнаружили феномен, характерный для многих реальных сетей
Модель малых миров
Д. Уаттс и С. Строгатц обнаружили феномен, характерный для многих реальных сетей
Слайд 16Модель случайной сети Эрдоша-Рени
Существует две модели классического случайного графа: в первой считается,
Модель случайной сети Эрдоша-Рени
Существует две модели классического случайного графа: в первой считается,

Слайд 17Модель случайной сети Барабаши-Альберта
Сценарий базируется на двух механизмах – росте и
Модель случайной сети Барабаши-Альберта
Сценарий базируется на двух механизмах – росте и

Слайд 18Сложные сети с заданным распределением
формируется степенная последовательность,
выбирая N чисел ki
Сложные сети с заданным распределением
формируется степенная последовательность,
выбирая N чисел ki

Слайд 19Алгоритм построения контентной сети
Алгоритм Барабаши-Альберта позволяет
генерировать сети со степенным распределением, однако
Алгоритм построения контентной сети
Алгоритм Барабаши-Альберта позволяет
генерировать сети со степенным распределением, однако

Слайд 20Распределения в модели
Изначально предполагается, что распределение количества документов по узлам – степенное
Распределения в модели
Изначально предполагается, что распределение количества документов по узлам – степенное

Слайд 21Основные шаги алгоритма
1. Выбирается количество узлов сети N;
2. Для каждого узла генерируется
Основные шаги алгоритма
1. Выбирается количество узлов сети N;
2. Для каждого узла генерируется

Слайд 22Преимущества модели
1. Ориентация на контент документов при
установлении связей (построении ребер);
2. При
Преимущества модели
1. Ориентация на контент документов при
установлении связей (построении ребер);
2. При

Слайд 23Решаемые задачи
Полученная в результате моделирования сеть, обладает многими параметрами, близкими к
реальной
Решаемые задачи
Полученная в результате моделирования сеть, обладает многими параметрами, близкими к
реальной

 Музей Люфтваффе
Музей Люфтваффе 20170327_prezentatsiya_mirovye_resursy
20170327_prezentatsiya_mirovye_resursy SDL Trados Studio 2009 SP3 SDL Trados Team SDL MultiTerm Team
SDL Trados Studio 2009 SP3 SDL Trados Team SDL MultiTerm Team характеристика
характеристика Презентация на тему КУЛЬТУРА Культура в переводе с латинского означает возделывание, взращивание
Презентация на тему КУЛЬТУРА Культура в переводе с латинского означает возделывание, взращивание  Общие принципы диспансерного наблюдения
Общие принципы диспансерного наблюдения Верификацияавтоматных программ
Верификацияавтоматных программ Программирование на Бейсик
Программирование на Бейсик Интеллектуальное оповещение дежурно-диспетчерского персонала ДЦС-7
Интеллектуальное оповещение дежурно-диспетчерского персонала ДЦС-7 УЧИСЬ В ГОЛЛАНДИИ
УЧИСЬ В ГОЛЛАНДИИ  Неделя английского языка2011-2012
Неделя английского языка2011-2012 Презентация Microsoft PowerPoint
Презентация Microsoft PowerPoint 12 апреля –День космонавтики
12 апреля –День космонавтики Водоросли
Водоросли Корейская культура. Рисунок - музыка - поэзия
Корейская культура. Рисунок - музыка - поэзия Сессия стратегического планирования
Сессия стратегического планирования ФОРМИРОВАНИЕ МОТИВАЦИИ УЧЕБНОЙ ДЕЯТЕЛЬНОСТИ У СТУДЕНТОВ
ФОРМИРОВАНИЕ МОТИВАЦИИ УЧЕБНОЙ ДЕЯТЕЛЬНОСТИ У СТУДЕНТОВ Робот-манипулятор. Разработка конструкции в 3D, с применением CAD системы SolidWorks
Робот-манипулятор. Разработка конструкции в 3D, с применением CAD системы SolidWorks Проведение экспертизы раздела проектной документации «Мероприятия по обеспечению пожарной безопасности». Типовые несоответств
Проведение экспертизы раздела проектной документации «Мероприятия по обеспечению пожарной безопасности». Типовые несоответств Политическое сознание и политическое поведение
Политическое сознание и политическое поведение  Проект «Численность населения села Байдары»
Проект «Численность населения села Байдары» Давайте повторим:
Давайте повторим: Групповой проект
Групповой проект Налог на имущество
Налог на имущество Роль сметы в системе управления строительно-подрядным предприятием
Роль сметы в системе управления строительно-подрядным предприятием Человек, изменивший искусство. К 140-летию со дня рождения Пабло Пикассо
Человек, изменивший искусство. К 140-летию со дня рождения Пабло Пикассо Презентациябизнес-планаОбщие рекомендации
Презентациябизнес-планаОбщие рекомендации МГТУ ГА ФИЗИКА
МГТУ ГА ФИЗИКА