- Ползать или летать? Компиляторы Intel и их возможности в плане оптимизации ПО.

Содержание
- 2. Ползать или летать? Вы купите машину у которой из передач только первая? И максимальная скорость 20
- 3. Что для этого надо? Знать где он находится. А можно и не знать. Просто попросите того,
- 4. Программа Компиляторы Intel® И их практическое применение
- 5. Компиляторы Intel® C, C++, FORTRAN Имеются для Windows* и Linux* Имеются для 32 и 64-битных платформ
- 6. Факторы повышения производительности SIMD методика для архитектуры NetBurst™ Программная конвейеризация под архитектуру Itanium® Предварительная выборка данных
- 7. Встроенные средства SIMD-расширений встроенные средства SIMD-расширений работают с упакованными данными до 128 бит в длину, что
- 8. Встроенные средства SIMD-расширений Три варианта кодирования: Векторные классы Интринсики (intrinsic) Освобождают от необходимости непосредственного управления регистрами
- 9. Пример использования void quarter(int array[], int len) { int i; for(i=0; i array[i] = array[i]>>2; }
- 10. Автовекторизация Автоматически применяет SIMD команды в наборах команд SSE, SSE2, SSE3 и MMX™ Определяет операции программы,
- 11. Программная конвейеризация Программная конвейеризация предназначена для перекрытия итераций циклов Использует мощную поддержку программной конвейеризации, обеспечиваемую архитектурой
- 12. Распространяет оптимизацию на все файлы -Qipo Межпроцедурная оптимизация
- 13. Оптимизация по профилированию Оптимальна для кода с часто выполняемыми ветвлениями, которые трудно предсказать во время компиляции
- 14. Диспетчеризация ЦП Выбирает соответствующий код в период выполнения в зависимости от фактического типа процессора Позволяет использовать
- 15. Поддержка многопоточной разработки в компиляторах Intel® Поддержка OpenMP* в компиляторах Intel® -Qopenmp Предоставляет стандартный набор библиотечных
- 16. Дополнительные опции оптимизации Optimization report -Qopt_report Vectorizarion report –Qvec_report Parallelization report –Qpar_report Возможность регулирования развертки циклов
- 17. Основные показатели: Компиляторы Intel® 7.0 для Linux* Более подробную информацию о производительности продукции Intel можно получить
- 18. Intel Compilers "The Intel compilers have performed excellently on our ROOT code. On average, the Intel
- 19. Программа Компиляторы Intel® И их практическое применение
- 20. Компиляторная оптимизация Используем опцию -QaxW – агрессивная оптимизация по производительности для Pentium4 Включает HLO (high level
- 21. Проверим, что сделал компилятор? Опции –Qopt_report3 и –Qvec_report3 создают отчёт о проведённой оптимизации Разбираемся, где компилятор
- 22. VortexMovement demo
- 23. Другие опции компилятора Intel® Что ещё можно попробовать? Развёртка циклов #pragma unroll(8) Предварительная подгрузка данных #pragma
- 24. Что обычно даёт эффект? Переход от массива структур к структуре массивов typedef struct Vortex { float
- 25. Что обычно даёт эффект? Последовательный доступ к элементам массивов (data cache misses) Для многомерных циклов важен
- 26. Распараллелим приложение Даёт эффект На многопроцессорных машинах На Pentium4 с HT Возможные опции: Автопараллелизация компилятором –Qparallel
- 27. VortexMovement на P4 с HT Распараллелено с помощью OpenMP. Тест проведён на Pentium4 с HT (3060MHz,
- 28. backup
- 29. Необходимые условия векторизации Короткое тело цикла (один basic block) Векторные или векторизуемые типы данных Избегайте зависимостей
- 31. Скачать презентацию

Слайд 3Что для этого надо?
Знать где он находится.
А можно и не знать.
Просто
Что для этого надо?
Знать где он находится.
А можно и не знать.
Просто

Слайд 4Программа
Компиляторы Intel®
И их практическое применение
Программа
Компиляторы Intel®
И их практическое применение

Слайд 5Компиляторы Intel®
C, C++, FORTRAN
Имеются для Windows* и Linux*
Имеются для 32 и 64-битных
Компиляторы Intel®
C, C++, FORTRAN
Имеются для Windows* и Linux*
Имеются для 32 и 64-битных

Слайд 6Факторы повышения производительности
SIMD методика для архитектуры NetBurst™
Программная конвейеризация под архитектуру Itanium®
Предварительная выборка
Факторы повышения производительности
SIMD методика для архитектуры NetBurst™
Программная конвейеризация под архитектуру Itanium®
Предварительная выборка

Слайд 7Встроенные средства SIMD-расширений
встроенные средства SIMD-расширений работают с упакованными данными до 128 бит
Встроенные средства SIMD-расширений
встроенные средства SIMD-расширений работают с упакованными данными до 128 бит

Слайд 8Встроенные средства SIMD-расширений
Три варианта кодирования:
Векторные классы
Интринсики (intrinsic)
Освобождают от необходимости непосредственного управления регистрами
Встроенные средства SIMD-расширений
Три варианта кодирования:
Векторные классы
Интринсики (intrinsic)
Освобождают от необходимости непосредственного управления регистрами

Слайд 9Пример использования
void quarter(int array[], int len)
{
int i;
for(i=0; i array[i]
Пример использования
void quarter(int array[], int len)
{
int i;
for(i=0; i
![Пример использования void quarter(int array[], int len) { int i; for(i=0; i](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/410401/slide-8.jpg)
Слайд 10Автовекторизация
Автоматически применяет SIMD команды в наборах команд SSE, SSE2, SSE3 и MMX™
Автовекторизация
Автоматически применяет SIMD команды в наборах команд SSE, SSE2, SSE3 и MMX™

Слайд 11Программная конвейеризация
Программная конвейеризация предназначена для перекрытия итераций циклов
Использует мощную поддержку программной конвейеризации,
Программная конвейеризация
Программная конвейеризация предназначена для перекрытия итераций циклов
Использует мощную поддержку программной конвейеризации,

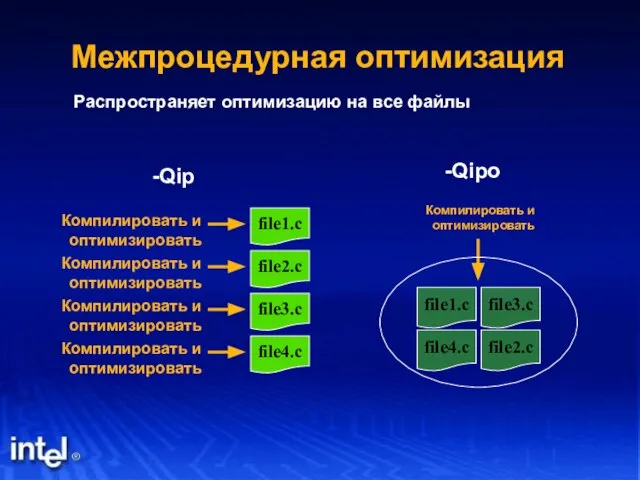
Слайд 12Распространяет оптимизацию на все файлы
-Qipo
Межпроцедурная оптимизация
Распространяет оптимизацию на все файлы
-Qipo
Межпроцедурная оптимизация
Слайд 13Оптимизация по профилированию
Оптимальна для кода с часто выполняемыми ветвлениями, которые трудно предсказать
Оптимизация по профилированию
Оптимальна для кода с часто выполняемыми ветвлениями, которые трудно предсказать

Слайд 14Диспетчеризация ЦП
Выбирает соответствующий код в период выполнения в зависимости от фактического типа
Диспетчеризация ЦП
Выбирает соответствующий код в период выполнения в зависимости от фактического типа

Слайд 15Поддержка многопоточной разработки в компиляторах Intel®
Поддержка OpenMP* в компиляторах Intel® -Qopenmp
Предоставляет стандартный
Поддержка многопоточной разработки в компиляторах Intel®
Поддержка OpenMP* в компиляторах Intel® -Qopenmp
Предоставляет стандартный

Слайд 16Дополнительные опции оптимизации
Optimization report -Qopt_report
Vectorizarion report –Qvec_report
Parallelization report –Qpar_report
Возможность регулирования развертки циклов
Дополнительные опции оптимизации
Optimization report -Qopt_report
Vectorizarion report –Qvec_report
Parallelization report –Qpar_report
Возможность регулирования развертки циклов

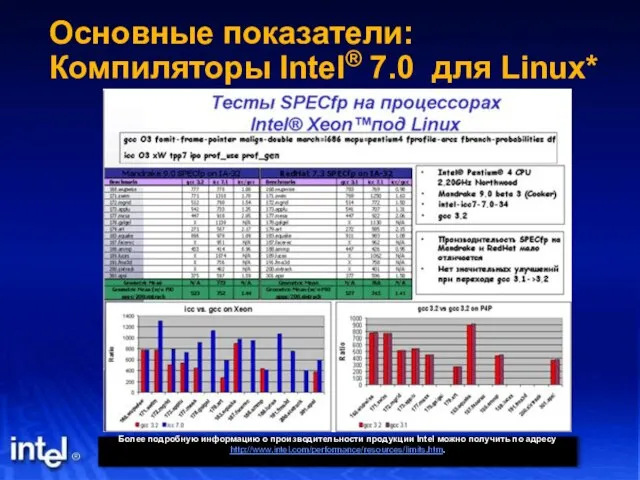
Слайд 17Основные показатели: Компиляторы Intel® 7.0 для Linux*
Более подробную информацию о производительности продукции
Основные показатели: Компиляторы Intel® 7.0 для Linux*
Более подробную информацию о производительности продукции
Слайд 18Intel Compilers
"The Intel compilers have performed excellently on our ROOT code. On
Intel Compilers
"The Intel compilers have performed excellently on our ROOT code. On

Слайд 19Программа
Компиляторы Intel®
И их практическое применение
Программа
Компиляторы Intel®
И их практическое применение

Слайд 20Компиляторная оптимизация
Используем опцию -QaxW – агрессивная оптимизация по производительности для Pentium4
Включает HLO
Компиляторная оптимизация
Используем опцию -QaxW – агрессивная оптимизация по производительности для Pentium4
Включает HLO

Слайд 21Проверим, что сделал компилятор?
Опции –Qopt_report3 и –Qvec_report3 создают отчёт о проведённой оптимизации
Разбираемся,
Проверим, что сделал компилятор?
Опции –Qopt_report3 и –Qvec_report3 создают отчёт о проведённой оптимизации
Разбираемся,

Слайд 22VortexMovement demo
VortexMovement demo

Слайд 23Другие опции компилятора Intel®
Что ещё можно попробовать?
Развёртка циклов #pragma unroll(8)
Предварительная подгрузка данных
Другие опции компилятора Intel®
Что ещё можно попробовать?
Развёртка циклов #pragma unroll(8)
Предварительная подгрузка данных

Слайд 24Что обычно даёт эффект?
Переход от массива структур к структуре массивов
typedef struct Vortex
{
float
Что обычно даёт эффект?
Переход от массива структур к структуре массивов
typedef struct Vortex
{
float

Слайд 25Что обычно даёт эффект?
Последовательный доступ к элементам массивов (data cache misses)
Для многомерных
Что обычно даёт эффект?
Последовательный доступ к элементам массивов (data cache misses)
Для многомерных

Слайд 26Распараллелим приложение
Даёт эффект
На многопроцессорных машинах
На Pentium4 с HT
Возможные опции:
Автопараллелизация компилятором –Qparallel
С
Распараллелим приложение
Даёт эффект
На многопроцессорных машинах
На Pentium4 с HT
Возможные опции:
Автопараллелизация компилятором –Qparallel
С

Слайд 27VortexMovement на P4 с HT
Распараллелено с помощью OpenMP.
Тест проведён на Pentium4
VortexMovement на P4 с HT
Распараллелено с помощью OpenMP.
Тест проведён на Pentium4

Слайд 28 backup
backup

Слайд 29Необходимые условия векторизации
Короткое тело цикла (один basic block)
Векторные или векторизуемые типы данных
Избегайте
Необходимые условия векторизации
Короткое тело цикла (один basic block)
Векторные или векторизуемые типы данных
Избегайте

 Прыжок в высоту способом «перешагивание»
Прыжок в высоту способом «перешагивание» Избирательная система и система подсчета результатов голосования
Избирательная система и система подсчета результатов голосования Акробатические элементы. Упражнения на гибкость, растяжка, координация
Акробатические элементы. Упражнения на гибкость, растяжка, координация Английская революция
Английская революция Барлық жеңіс өзіңді-өзің жеңуден басталмақ
Барлық жеңіс өзіңді-өзің жеңуден басталмақ підготовка до ділових переговорів
підготовка до ділових переговорів Приклад заповнення ПКО
Приклад заповнення ПКО Презентация
Презентация Подготовила учитель истории Подготовила учитель истории МОУ Талаканской СОШ №6 Черткова Ольга Александровна
Подготовила учитель истории Подготовила учитель истории МОУ Талаканской СОШ №6 Черткова Ольга Александровна Основное энергетическое уравнение турбины. Кавитация в гидромашинах. Режимы работы гидромашин и их регулирование
Основное энергетическое уравнение турбины. Кавитация в гидромашинах. Режимы работы гидромашин и их регулирование Птица года-варакушка
Птица года-варакушка Северо-западный экономический район (9 класс)
Северо-западный экономический район (9 класс) Презентация на тему Основные закономерности возникновения государства
Презентация на тему Основные закономерности возникновения государства  Дробные числительные. 6 класс
Дробные числительные. 6 класс ПРОЕКТ «Волшебный мир семейного музея» Толубаева Е.Б., методист МОУ ДПО «Ме
ПРОЕКТ «Волшебный мир семейного музея» Толубаева Е.Б., методист МОУ ДПО «Ме Носов "Затейники" 2 класс
Носов "Затейники" 2 класс Kahrs Life. Новый тип деревянных полов
Kahrs Life. Новый тип деревянных полов Коламбия пикчерз не представляет…
Коламбия пикчерз не представляет… Трудные случаи пунктуации Запятая перед союзом И (Подготовка к ЕГЭ)
Трудные случаи пунктуации Запятая перед союзом И (Подготовка к ЕГЭ) Гимнастика в 5-11 классах
Гимнастика в 5-11 классах Мультик с шаром
Мультик с шаром Итоги государственной (итоговой) аттестации -2012
Итоги государственной (итоговой) аттестации -2012 Презентация на тему Решение задач 1 класс
Презентация на тему Решение задач 1 класс  МЛУ-ТБ:Приверженность лечению
МЛУ-ТБ:Приверженность лечению L_r_1_Kriminalisticheskaya_fotografia
L_r_1_Kriminalisticheskaya_fotografia Ослепительная улыбка на всю жизнь
Ослепительная улыбка на всю жизнь ПОРТФОЛИО
ПОРТФОЛИО Российский союз выставок и ярмарок как эффективная площадка коммуникаций Выездное заседание ЭКСПОКЛУБА «Актуальные вопросы выст
Российский союз выставок и ярмарок как эффективная площадка коммуникаций Выездное заседание ЭКСПОКЛУБА «Актуальные вопросы выст