- Постановка задачи двуклассового распознавания

Содержание
- 2. I. Зачем нужно обучение? Ошибка на обучающем множестве. Ошибка на тестовом множестве. Цель распознавания – уменьшить
- 3. II. Зачем нужно обучение? ` С заданной вероятностью можно написать, что Errtest 2. Чем больше мы
- 4. Распознаватель «Кора». Пространство признаков – логические утверждения. Симптомы. 3 значения синдрома. Множество решающих правил – конъюнкции
- 5. I. Что можно надежно утверждать об экспрессии генов? Резко выраженная дифференциальная экспрессия. Мы видели, что после
- 6. II. Что можно надежно утверждать об экспрессии генов? Б) Модель, учитывающая неспецифическую гибридизацию. I(G, j, k)
- 7. III. Что можно надежно утверждать об экспрессии генов? В) Как выразить утверждение “высокая экспрессия гена” ?
- 8. Как измерять ошибку распознавания? Ошибка на обучающем множестве всегда занижена. Лучший способ – разбиение на обучающее
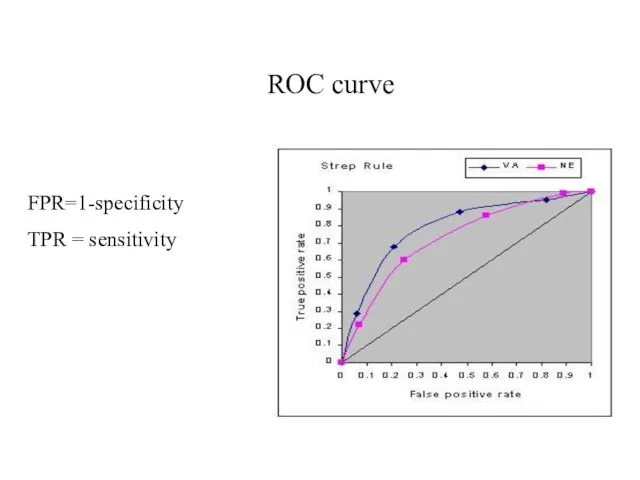
- 9. ROC curve FPR=1-specificity TPR = sensitivity
- 11. Скачать презентацию
Слайд 2I. Зачем нужно обучение?
Ошибка на обучающем множестве. Ошибка на тестовом множестве.
Цель распознавания
I. Зачем нужно обучение?
Ошибка на обучающем множестве. Ошибка на тестовом множестве.
Цель распознавания

Слайд 3II. Зачем нужно обучение?
`
С заданной вероятностью можно написать, что
Errtest < Errtrain
II. Зачем нужно обучение?
`
С заданной вероятностью можно написать, что
Errtest < Errtrain

Слайд 4Распознаватель «Кора».
Пространство признаков – логические утверждения. Симптомы. 3 значения синдрома.
Множество решающих
Распознаватель «Кора».
Пространство признаков – логические утверждения. Симптомы. 3 значения синдрома.
Множество решающих

Слайд 5I. Что можно надежно утверждать об экспрессии генов?
Резко выраженная дифференциальная экспрессия.
Мы видели,
I. Что можно надежно утверждать об экспрессии генов?
Резко выраженная дифференциальная экспрессия.
Мы видели,

Слайд 6II. Что можно надежно утверждать об экспрессии генов?
Б) Модель, учитывающая неспецифическую гибридизацию.
I(G,
II. Что можно надежно утверждать об экспрессии генов?
Б) Модель, учитывающая неспецифическую гибридизацию.
I(G,

Слайд 7III. Что можно надежно утверждать об экспрессии генов?
В) Как выразить утверждение “высокая
III. Что можно надежно утверждать об экспрессии генов?
В) Как выразить утверждение “высокая

Слайд 8Как измерять ошибку распознавания?
Ошибка на обучающем множестве всегда занижена.
Лучший способ – разбиение
Как измерять ошибку распознавания?
Ошибка на обучающем множестве всегда занижена.
Лучший способ – разбиение

Слайд 9ROC curve
FPR=1-specificity
TPR = sensitivity
ROC curve
FPR=1-specificity
TPR = sensitivity
 Деятельность. Лекция №2
Деятельность. Лекция №2 Танец тени. Такие разные Я
Танец тени. Такие разные Я Иванова Варвара Александровна
Иванова Варвара Александровна Сочи: Вчера. Сегодня. Завтра. (Симметрия в архитектуре)
Сочи: Вчера. Сегодня. Завтра. (Симметрия в архитектуре) Поведенческие теории 2
Поведенческие теории 2 Виды случайных событий
Виды случайных событий ВИРТУАЛЬНОЕ МОДЕЛИРОВАНИЕ ТРЕХМЕРНЫХ СЦЕН
ВИРТУАЛЬНОЕ МОДЕЛИРОВАНИЕ ТРЕХМЕРНЫХ СЦЕН Таможенное право. Лекция 1
Таможенное право. Лекция 1 ВКР: сравнительный анализ рефлексии у студентов различных направлений подготовки
ВКР: сравнительный анализ рефлексии у студентов различных направлений подготовки 1832__
1832__ Урок – ПРЕЗЕНТАЦИЯ по геометрии в 9? классе.
Урок – ПРЕЗЕНТАЦИЯ по геометрии в 9? классе. Самореализующееся пророчество (Эффект Розенталя)
Самореализующееся пророчество (Эффект Розенталя) Психологические особенности ответственности и личностной тревожности молодых людей
Психологические особенности ответственности и личностной тревожности молодых людей Тормозной путь автомобиля
Тормозной путь автомобиля Возможные макрофизические проявления гипотетического нейтринного заряда.
Возможные макрофизические проявления гипотетического нейтринного заряда. Практические инструменты маркетинга в бизнесе
Практические инструменты маркетинга в бизнесе Избирательная система
Избирательная система Использование вихревого эффекта в зерновой промышленности
Использование вихревого эффекта в зерновой промышленности "ВВЕДЕНИЕ В ИНФОРМАТИКУ"
"ВВЕДЕНИЕ В ИНФОРМАТИКУ" РАБОТА С ИЗДАТЕЛЬСТВАМИ. АССОРТИМЕНТ ПЕРИОДИЧЕСКИХ ИЗДАНИЙ. КОНТРОЛЬ ПРОДАЖ. ВОЗВРАТ НЕРЕАЛИЗОВАННЫХ ЭКЗЕМПЛЯРОВ.
РАБОТА С ИЗДАТЕЛЬСТВАМИ. АССОРТИМЕНТ ПЕРИОДИЧЕСКИХ ИЗДАНИЙ. КОНТРОЛЬ ПРОДАЖ. ВОЗВРАТ НЕРЕАЛИЗОВАННЫХ ЭКЗЕМПЛЯРОВ. Зрительные иллюзии в одежде
Зрительные иллюзии в одежде Картины исторические и бытовые
Картины исторические и бытовые Презентация на тему Угол поворота. Радианная мера угла
Презентация на тему Угол поворота. Радианная мера угла Выполнил: Котов О.Ю 5 курс, 4.1 группа Ставрополь 2010. - презентация
Выполнил: Котов О.Ю 5 курс, 4.1 группа Ставрополь 2010. - презентация Основы Технологического Бизнеса.
Основы Технологического Бизнеса. X Международная научно-практическая конференция Молодежь и будущее: профессиональная и личностная самореализация
X Международная научно-практическая конференция Молодежь и будущее: профессиональная и личностная самореализация Пищевые улучшители и добавки
Пищевые улучшители и добавки ДЕЕПРИЧАСТИЕ КАК ЧАСТЬ РЕЧИ
ДЕЕПРИЧАСТИЕ КАК ЧАСТЬ РЕЧИ