Проблемы распараллеливания метода частиц в ячейках для задачи взаимодействия электронного пучка с плазмой
- Проблемы распараллеливания метода частиц в ячейках для задачи взаимодействия электронного пучка с плазмой

Содержание
- 2. Содержание Проблемы эффективного распараллеливания для большого числа процессоров Моделирование динамики плазмы методом частиц в ячейках Проведение
- 3. Проблемы эффективного распараллеливания для большого числа процессоров Решение уравнения Пуассона Параллельная прогонка Метод частиц в ячейках
- 5. Многосеточный метод: Ускорение параллельной программы 0-я гармоника вычисляется с помощью многосеточного метода на отдельном процессоре Остальные
- 6. Зависимость логарифма ускорения от логарифма числа узлов Tn – Время работы на N узлах T1 –
- 7. Всероссийская конференция «Актуальные проблемы вычислительной математики и математического моделирования» 13 - 15 июня 2012 года Новосибирск,
- 8. Установка ГОЛ-3 (ИЯФ СО РАН) Установка ГОЛ-3 представляет собой многопробочную термоядерную ловушку открытого типа с плазмой
- 9. Эффект аномальной теплопроводности В экспериментах на установке ГОЛ-3 (ИЯФ СО РАН) вследствие релаксации мощного электронного пучка
- 10. Система уравнений Власова-Максвелла Плазма описывается системой уравнений Власова-Максвелла: где - функция распределения частиц сорта (электроны или
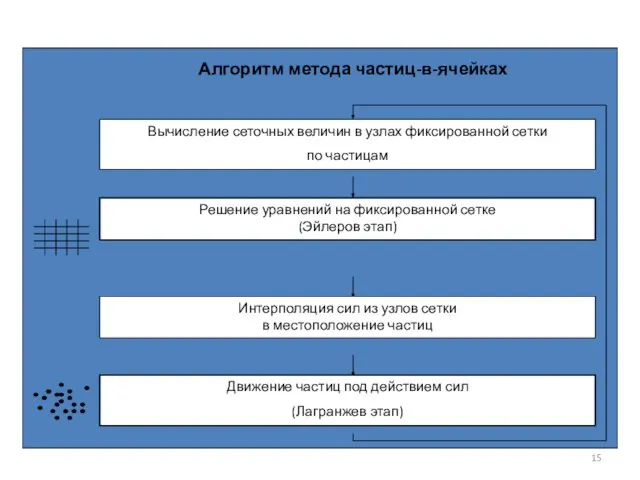
- 11. Лагранжев этап
- 12. Эйлеров этап Эйлеров этап: Схема эйлерова этапа:
- 13. Восстановление плотности заряда по частицам NGP: PIC:
- 14. Схема вычисления токов
- 16. Модуль потока тепловой энергии электронов В соответствии с начальным предположением видно образование изолированных друг от друга
- 18. Проведение больших численных расчетов на суперЭВМ Оценка производительности суперЭВМ Повышение размерности задачи Компьютер — это не
- 19. Оценка производительности суперЭВМ Принятая единица — FlOpS (теоретические, или реально достигнутые, напр. LINPACK ) Однако для
- 20. Значение объема жесткого диска Пример конкретной задачи Релаксация мощного релятивистского пучка в высокотемпературной плазме, метод частиц-в-ячейках,
- 21. Повышение размерности задачи Существуют планы по поводу вычислений Exascale-масштабе. Тем не менее, лишь небольшое количество программ
- 22. Компьютер — это не только процессоры Результат расчета в задачах физики плазмы (не только в рассмотренной
- 23. Требования к системам хранения и передачи данных Объем диска - 200 Петабайт. Скорость диска - 270
- 24. О реализации метода частиц на GPU Необходимость Методика Результаты
- 25. О необходимости использования большого числа частиц На фазовых плоскостях показана скорость частиц пучка в зависимости от
- 26. Оценка размера задачи В настоящее время проведены расчеты взаимодействия релятивистского электронного пучка с плазмой, позволившие в
- 27. Моделирование плазменных неустойчивостей требует кинетического подхода и больших вычислительных ресурсов: Требуется от 1000 частиц в ячейке
- 29. Использование текстур CUDA Что такое текстура: способ доступа к памяти Двух- или трехмерный массив с кэшированием,
- 30. Перспективы достижения экзафлопс-производительности для метода частиц-в-ячейках на GPU Используемая в настоящий момент одномерная декомпозиция области не
- 31. О перспективах достижения экзафлопс-производительности.Если... Взять за основу для рассуждений Tianhe-1A, Выделить для каждой подобласти один ускоритель
- 32. Заключение 1) В настоящее время параллельные методы и алгоритмы недостаточно разработаны, в связи с чем невозможно
- 33. ЦЕНТР КОЛЛЕКТИВНОГО ПОЛЬЗОВАНИЯ ССКЦ ПРИ ИВМиМГ СО РАН Научный руководитель: академик Б.Г. Михайленко Исполнительный директор: д.т.н.
- 34. ОСНОВНЫЕ ЗАДАЧИ ЦКП ССКЦ Обеспечение работ институтов СО РАН и университетов Сибири по математическому моделированию в
- 35. Сервер с общей памятью (hp DL580 G5) GigabitEthernet InfiniBand GE GE Кластер HKC-160 (hp rx1620) В
- 36. Спасибо за внимание!
- 37. Переход к безразмерным переменным скорость света c = 3x1010 см/с плотность плазмы n0 = 1014 см-3
- 38. ГРАНТЫ, ПРИ ВЫПОЛНЕНИИ КОТОРЫХ ИСПОЛЬЗОВАЛИСЬ УСЛУГИ ЦКП ССКЦ В 2010 Г.
- 40. Скачать презентацию
Слайд 2Содержание
Проблемы эффективного распараллеливания для большого числа процессоров
Моделирование динамики плазмы методом частиц в
Содержание
Проблемы эффективного распараллеливания для большого числа процессоров
Моделирование динамики плазмы методом частиц в

Слайд 3Проблемы эффективного распараллеливания для большого числа процессоров
Решение уравнения Пуассона
Параллельная прогонка
Метод частиц в
Проблемы эффективного распараллеливания для большого числа процессоров
Решение уравнения Пуассона
Параллельная прогонка
Метод частиц в

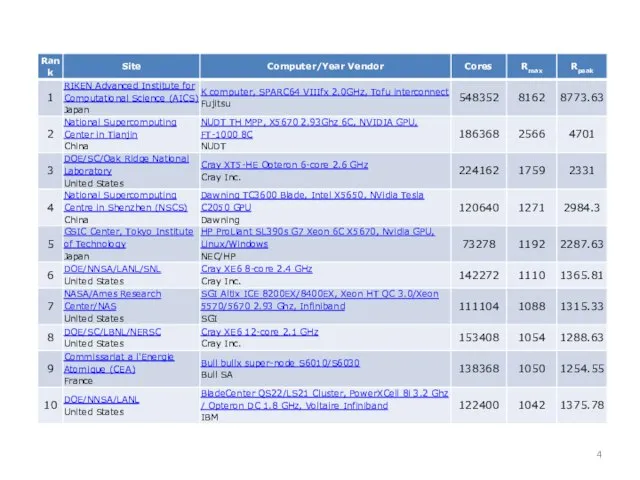
Слайд 5Многосеточный метод:
Ускорение параллельной программы
0-я гармоника вычисляется с помощью
многосеточного метода
Многосеточный метод:
Ускорение параллельной программы
0-я гармоника вычисляется с помощью
многосеточного метода
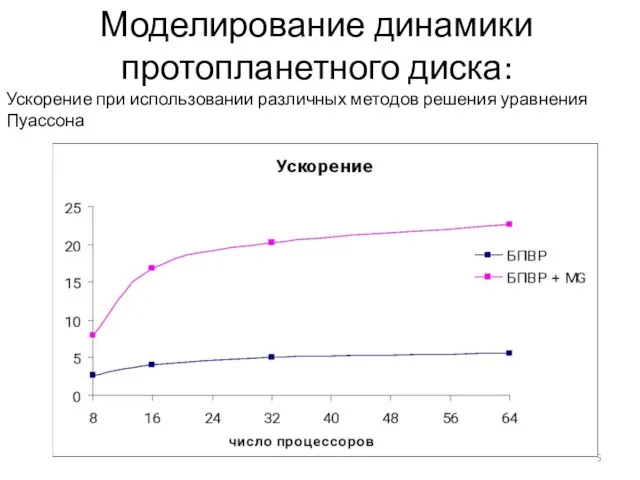
Слайд 6Зависимость логарифма ускорения от логарифма числа узлов
Tn – Время работы на N
Зависимость логарифма ускорения от логарифма числа узлов
Tn – Время работы на N
Слайд 7Всероссийская конференция
«Актуальные проблемы вычислительной математики и математического моделирования»
13 - 15 июня
Всероссийская конференция
«Актуальные проблемы вычислительной математики и математического моделирования»
13 - 15 июня

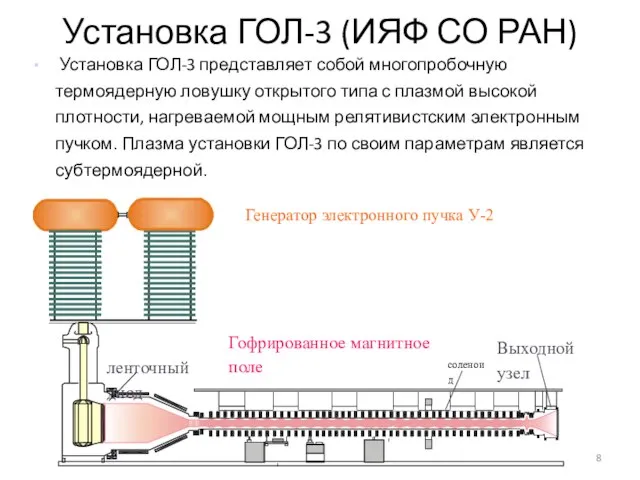
Слайд 8Установка ГОЛ-3 (ИЯФ СО РАН)
Установка ГОЛ-3 представляет собой многопробочную термоядерную ловушку
Установка ГОЛ-3 (ИЯФ СО РАН)
Установка ГОЛ-3 представляет собой многопробочную термоядерную ловушку
Слайд 9Эффект аномальной теплопроводности
В экспериментах на установке ГОЛ-3 (ИЯФ СО РАН) вследствие релаксации
Эффект аномальной теплопроводности
В экспериментах на установке ГОЛ-3 (ИЯФ СО РАН) вследствие релаксации

Слайд 10Система уравнений Власова-Максвелла
Плазма описывается системой уравнений Власова-Максвелла:
где - функция распределения частиц сорта
Система уравнений Власова-Максвелла
Плазма описывается системой уравнений Власова-Максвелла:
где - функция распределения частиц сорта

Слайд 11Лагранжев этап
Лагранжев этап

Слайд 12Эйлеров этап
Эйлеров этап:
Схема эйлерова этапа:
Эйлеров этап
Эйлеров этап:
Схема эйлерова этапа:

Слайд 13Восстановление плотности заряда по частицам
NGP:
PIC:
Восстановление плотности заряда по частицам
NGP:
PIC:

Слайд 14 Схема вычисления токов
Схема вычисления токов

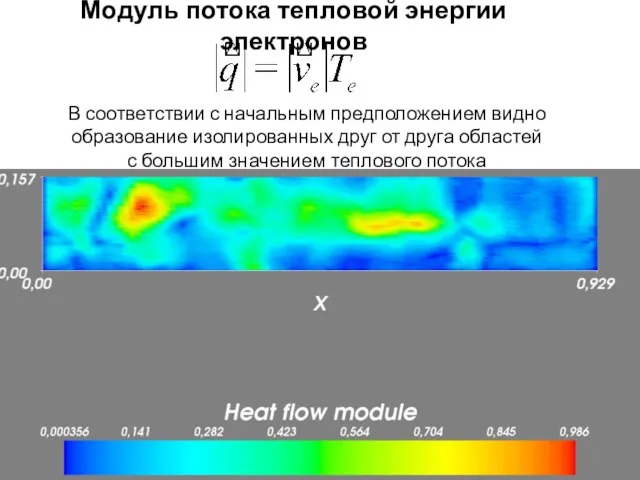
Слайд 16Модуль потока тепловой энергии электронов
В соответствии с начальным предположением видно
образование изолированных
Модуль потока тепловой энергии электронов
В соответствии с начальным предположением видно
образование изолированных
Слайд 18Проведение больших численных расчетов на суперЭВМ
Оценка производительности суперЭВМ
Повышение размерности задачи
Компьютер — это
Проведение больших численных расчетов на суперЭВМ
Оценка производительности суперЭВМ
Повышение размерности задачи
Компьютер — это

Слайд 19Оценка производительности суперЭВМ
Принятая единица — FlOpS (теоретические, или реально достигнутые, напр. LINPACK
Оценка производительности суперЭВМ
Принятая единица — FlOpS (теоретические, или реально достигнутые, напр. LINPACK

Слайд 20Значение объема жесткого диска
Пример конкретной задачи
Релаксация мощного релятивистского пучка в высокотемпературной плазме,
Значение объема жесткого диска
Пример конкретной задачи
Релаксация мощного релятивистского пучка в высокотемпературной плазме,

Слайд 21Повышение размерности задачи
Существуют планы по поводу вычислений Exascale-масштабе.
Тем не менее, лишь небольшое
Повышение размерности задачи
Существуют планы по поводу вычислений Exascale-масштабе.
Тем не менее, лишь небольшое

Слайд 22Компьютер — это не только процессоры
Результат расчета в задачах физики плазмы (не
Компьютер — это не только процессоры
Результат расчета в задачах физики плазмы (не

Слайд 23Требования к системам хранения и передачи данных
Объем диска - 200 Петабайт.
Скорость диска
Требования к системам хранения и передачи данных
Объем диска - 200 Петабайт.
Скорость диска

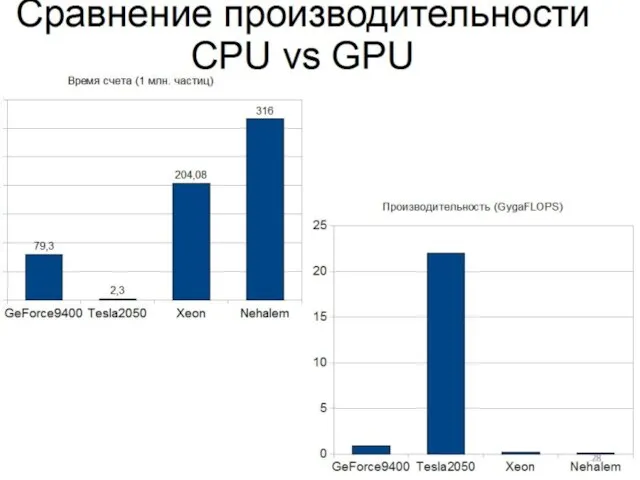
Слайд 24О реализации метода частиц на GPU
Необходимость
Методика
Результаты
О реализации метода частиц на GPU
Необходимость
Методика
Результаты

Слайд 25О необходимости использования большого числа частиц
На фазовых плоскостях показана скорость частиц пучка
О необходимости использования большого числа частиц
На фазовых плоскостях показана скорость частиц пучка
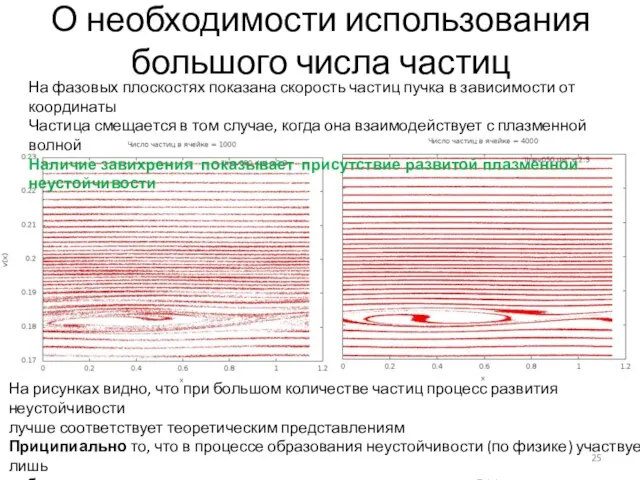
Слайд 26Оценка размера задачи
В настоящее время проведены расчеты взаимодействия релятивистского электронного пучка с
Оценка размера задачи
В настоящее время проведены расчеты взаимодействия релятивистского электронного пучка с

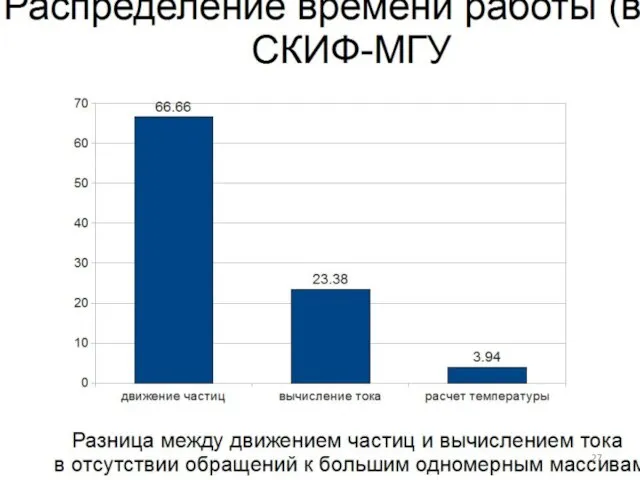
Слайд 27Моделирование плазменных неустойчивостей требует кинетического подхода и больших вычислительных ресурсов:
Требуется от 1000
Моделирование плазменных неустойчивостей требует кинетического подхода и больших вычислительных ресурсов:
Требуется от 1000
Слайд 29Использование текстур CUDA
Что такое текстура: способ доступа к памяти
Двух- или трехмерный массив
Использование текстур CUDA
Что такое текстура: способ доступа к памяти
Двух- или трехмерный массив

Слайд 30Перспективы достижения экзафлопс-производительности для метода частиц-в-ячейках на GPU
Используемая в настоящий момент одномерная
Перспективы достижения экзафлопс-производительности для метода частиц-в-ячейках на GPU
Используемая в настоящий момент одномерная

Слайд 31О перспективах достижения экзафлопс-производительности.Если...
Взять за основу для рассуждений Tianhe-1A,
Выделить для каждой подобласти
О перспективах достижения экзафлопс-производительности.Если...
Взять за основу для рассуждений Tianhe-1A,
Выделить для каждой подобласти

Слайд 32Заключение
1) В настоящее время параллельные методы и алгоритмы недостаточно разработаны, в связи
Заключение
1) В настоящее время параллельные методы и алгоритмы недостаточно разработаны, в связи

Слайд 33ЦЕНТР КОЛЛЕКТИВНОГО
ПОЛЬЗОВАНИЯ ССКЦ ПРИ ИВМиМГ СО РАН
Научный руководитель: академик Б.Г. Михайленко
Исполнительный
ЦЕНТР КОЛЛЕКТИВНОГО
ПОЛЬЗОВАНИЯ ССКЦ ПРИ ИВМиМГ СО РАН
Научный руководитель: академик Б.Г. Михайленко
Исполнительный

Слайд 34ОСНОВНЫЕ ЗАДАЧИ ЦКП ССКЦ
Обеспечение работ институтов СО РАН и университетов Сибири по
ОСНОВНЫЕ ЗАДАЧИ ЦКП ССКЦ
Обеспечение работ институтов СО РАН и университетов Сибири по

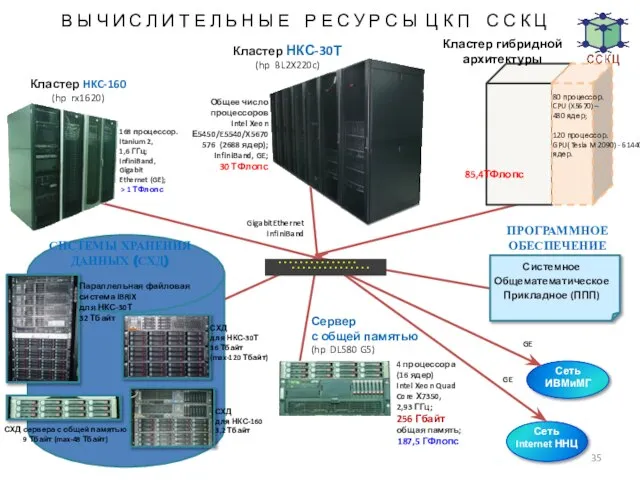
Слайд 35Сервер
с общей памятью
(hp DL580 G5)
GigabitEthernet
InfiniBand
GE
GE
Кластер HKC-160
(hp rx1620)
В Ы Ч И С
Сервер
с общей памятью
(hp DL580 G5)
GigabitEthernet
InfiniBand
GE
GE
Кластер HKC-160
(hp rx1620)
В Ы Ч И С
Слайд 36Спасибо за внимание!
Спасибо за внимание!

Слайд 37Переход к безразмерным переменным
скорость света c = 3x1010 см/с
плотность плазмы n0 =
Переход к безразмерным переменным
скорость света c = 3x1010 см/с
плотность плазмы n0 =

Слайд 38ГРАНТЫ, ПРИ ВЫПОЛНЕНИИ КОТОРЫХ
ИСПОЛЬЗОВАЛИСЬ УСЛУГИ ЦКП ССКЦ В 2010 Г.
ГРАНТЫ, ПРИ ВЫПОЛНЕНИИ КОТОРЫХ
ИСПОЛЬЗОВАЛИСЬ УСЛУГИ ЦКП ССКЦ В 2010 Г.

 Презентация на тему Спасители Отечества. Конец Смуты
Презентация на тему Спасители Отечества. Конец Смуты  Восстание Уота Тайлера в Англии
Восстание Уота Тайлера в Англии Курсовая работа слушателя курсов повышения квалификации «Информационные технологии в деятельности учителя- предметника» Гав
Курсовая работа слушателя курсов повышения квалификации «Информационные технологии в деятельности учителя- предметника» Гав Организация учебно – исследовательской деятельности в школе
Организация учебно – исследовательской деятельности в школе Развитие агропромышленного и рыбохозяйственного комплексов Вологодской области. Объем государственной поддержки
Развитие агропромышленного и рыбохозяйственного комплексов Вологодской области. Объем государственной поддержки Царскосельский пушкинский лицей (викторина)
Царскосельский пушкинский лицей (викторина) Устный счёт «Деление на двузначное число»
Устный счёт «Деление на двузначное число» Международный трибунал по морскому праву
Международный трибунал по морскому праву Осевая и центральная симметрия
Осевая и центральная симметрия РАЗВИТИЕ КСО ЧЕРЕЗ ПРЕПОДАВАНИЕ В УНИВЕРСИТЕТАХ КИШИНЕВ, 30 ОКТЯБРЯ МАРИНА САПРЫКИНА, ЦЕНТР РАЗВИТИЯ КСО
РАЗВИТИЕ КСО ЧЕРЕЗ ПРЕПОДАВАНИЕ В УНИВЕРСИТЕТАХ КИШИНЕВ, 30 ОКТЯБРЯ МАРИНА САПРЫКИНА, ЦЕНТР РАЗВИТИЯ КСО Белоруссия
Белоруссия ВКР: Бухгалтерский учет и анализ оплаты труда на предприятии
ВКР: Бухгалтерский учет и анализ оплаты труда на предприятии Имущество
Имущество Презентация для дипломной работы
Презентация для дипломной работы Презентация на тему Законы Кеплера законы движения небесных тел
Презентация на тему Законы Кеплера законы движения небесных тел  Интеграция информационных систем:состояние, тенденции, перспективы
Интеграция информационных систем:состояние, тенденции, перспективы Всемирный банк Программа Интернет-услуг
Всемирный банк Программа Интернет-услуг Салейкинская сельская библиотека
Салейкинская сельская библиотека Современные средства поражения
Современные средства поражения Ya_kontseptsia_Ya_ustal
Ya_kontseptsia_Ya_ustal Дикие животные тропиков
Дикие животные тропиков Урок презентация на тему Борис Заходер «История гусеницы»
Урок презентация на тему Борис Заходер «История гусеницы»  Дом приведение. Школьник. Детская газета. Выпуск 2
Дом приведение. Школьник. Детская газета. Выпуск 2 ИТОГИ ПЕРВОГО ТРИМЕСТРА
ИТОГИ ПЕРВОГО ТРИМЕСТРА ВГПУ, встреча с абитуриентами - 18
ВГПУ, встреча с абитуриентами - 18 Предоставление заявки на сертификацию СМК
Предоставление заявки на сертификацию СМК Тефлон
Тефлон Проблемыметодического обеспечения учебных дисциплин в контексте ФГОС нового поколения
Проблемыметодического обеспечения учебных дисциплин в контексте ФГОС нового поколения