- Распределенные базы данных

Содержание
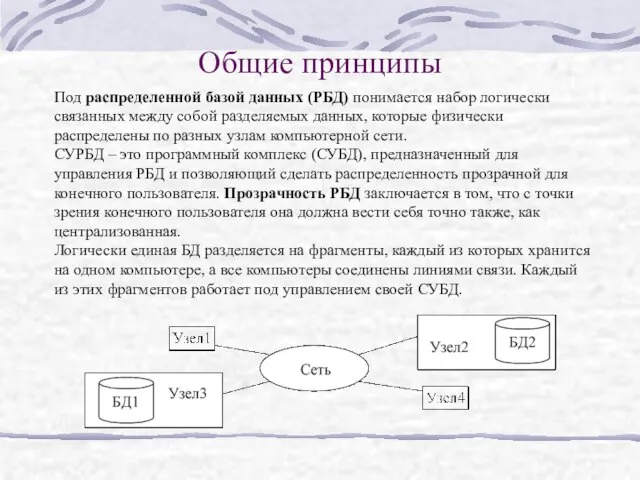
- 2. Общие принципы Под распределенной базой данных (РБД) понимается набор логически связанных между собой разделяемых данных, которые
- 3. Критерии распределенности (по К. Дейту) Локальная автономность. Локальные данные принадлежат локальным узлам и управляется администраторами локальных
- 4. Критерии распределенности (по К. Дейту) Обработка распределенных запросов. Система должна автоматически определять методы выполнения соединения (объединения)
- 5. Методы поддержки распределенных данных Существуют различные методы поддержки распределенности: Фрагментация – разбиение БД или таблицы на
- 6. Фрагментация Фрагментация – основной способ организации РБД. Назначение: хранение данных на том узле, где они чаще
- 7. Фрагментация Типы фрагментации: а) горизонтальная; б) вертикальная; в) смешанная; г) производная. Производная фрагментация строится для подчиненного
- 8. Репликация данных Репликация – это поддержание двух и более идентичных копий (реплик) данных на разных узлах
- 9. Служба тиражирования Служба тиражирования должна выполнять следующие функции: Обеспечение масштабируемости, т.е. эффективной обработки больших и малых
- 10. Репликация с основной копией Существуют следующие варианты: Классический подход заключается в наличии одной основной копии, в
- 11. Репликация без основной копии Симметричная репликация (без основной копии). Все копии реплицируемого набора могут обновляться одновременно
- 12. Репликация без основной копии Конфликтные ситуации: Добавление двух записей с одинаковыми первичными или уникальными ключами. Для
- 13. Репликация без основной копии Методы разрешения конфликтов обновления: Разрешение по приоритету узлов: для каждого узла назначается
- 14. Репликация без основной копии Способы реализации распространения изменений: Использование триггеров. Внутрь триггера помещаются команды, проводящие на
- 15. Распределенные запросы Распределенным называется запрос, который обращается к двум и более узлам РБД, но не обновляет
- 16. Распределенные запросы. Пример База данных "Агентство недвижимости", 2 филиала – в Лондоне и Глазго. Отношения: Property
- 17. Распределенные запросы. Пример Условия: скорость передачи 10000 б/с; задержка передачи – 1 с, все кортежи по
- 18. Распределенные ограничения целостности Распределенные ограничения целостности возникают тогда, когда для проверки соблюдения какого-либо ограничения целостности системе
- 19. Распределенные транзакции Распределенные транзакции обращаются к двум и более узлам и обновляют на них данные. Основная
- 20. Протокол двухфазной фиксации
- 21. Действия координатора транзакции Координатор выполняет протокол 2ФФ по следующему алгоритму: I. Фаза 1 (голосование). Занести запись
- 22. Действия участника транзакции Участник выполняет протокол 2ФФ по следующему алгоритму: При получении команды PREPARE, если он
- 23. Протоколы ликвидации Протокол ликвидации для координатора: Тайм-аут в состоянии WAITING: координатор не может зафиксировать транзакцию, потому
- 24. Протоколы восстановления Действия, которые выполняются на отказавшем узле после его перезагрузки, называются протоколом восстановления. Они зависят
- 25. Протоколы восстановления При отказе участника цель протокола восстановления – гарантировать, что после восстановления узел выполнит в
- 26. Реализация протокола 2ФФ
- 27. Поддержка распределенности в Oracle Прозрачность распределенности. Каждая часть данных, хранимых на одном компьютере в сети, оформлена
- 28. Связь в распределенной БД Oracle Обращение к сервисам базы данных (серверу БД, очереди печати, серверу электронной
- 29. Связи в распределенной БД Oracle Примеры. Локальная база данных – HQ.ACME.COM. Удаленная база данных – SALES.ACME.COM.
- 30. Работа в распределенной БД Oracle Oracle различает следующие виды обработки данных в РБД: удаленный запрос –
- 31. Моментальные снимки в Oracle Oracle поддерживает два типа тиражирования: базовое – копия обеспечивает доступ "только для
- 32. Моментальные снимки в Oracle Примеры: Моментальный снимок, основой которого является запрос select * from employee@hr_link; является
- 33. Моментальные снимки в Oracle Синтаксис создания моментального снимка: create snapshot [имя_схемы.]имя_снимка [ { pctfree целое |
- 34. Моментальные снимки в Oracle Пример создания МС на локальном сервере: create snapshot emp_dept_count pctfree 5 tablespace
- 35. Моментальные снимки в Oracle При создании моментального снимка в локальной базе данных создается: таблица для хранения
- 36. Регенерация моментальных снимков Oracle Возможны два варианта: REFRESH FAST (быстрая регенерация). REFRESH COMPLETE (полная регенерация).
- 37. Регенерация моментальных снимков Oracle Для быстрой регенерации необходим журнал моментальных снимков (snapshot log) – это таблица,
- 39. Скачать презентацию
Слайд 2Общие принципы
Под распределенной базой данных (РБД) понимается набор логически связанных между собой
Общие принципы
Под распределенной базой данных (РБД) понимается набор логически связанных между собой
Слайд 3Критерии распределенности (по К. Дейту)
Локальная автономность. Локальные данные принадлежат локальным узлам и
Критерии распределенности (по К. Дейту)
Локальная автономность. Локальные данные принадлежат локальным узлам и

Слайд 4Критерии распределенности (по К. Дейту)
Обработка распределенных запросов.
Система должна автоматически определять методы выполнения
Критерии распределенности (по К. Дейту)
Обработка распределенных запросов.
Система должна автоматически определять методы выполнения

Слайд 5Методы поддержки распределенных данных
Существуют различные методы поддержки распределенности:
Фрагментация – разбиение БД или
Методы поддержки распределенных данных
Существуют различные методы поддержки распределенности:
Фрагментация – разбиение БД или

Слайд 6Фрагментация
Фрагментация – основной способ организации РБД.
Назначение: хранение данных на том узле, где
Фрагментация
Фрагментация – основной способ организации РБД.
Назначение: хранение данных на том узле, где

Слайд 7Фрагментация
Типы фрагментации:
а) горизонтальная;
б) вертикальная;
в) смешанная;
г) производная.
Производная фрагментация строится для подчиненного отношения на
Фрагментация
Типы фрагментации:
а) горизонтальная;
б) вертикальная;
в) смешанная;
г) производная.
Производная фрагментация строится для подчиненного отношения на

Слайд 8Репликация данных
Репликация – это поддержание двух и более идентичных копий (реплик) данных
Репликация данных
Репликация – это поддержание двух и более идентичных копий (реплик) данных

Слайд 9Служба тиражирования
Служба тиражирования должна выполнять следующие функции:
Обеспечение масштабируемости, т.е. эффективной обработки больших
Служба тиражирования
Служба тиражирования должна выполнять следующие функции:
Обеспечение масштабируемости, т.е. эффективной обработки больших

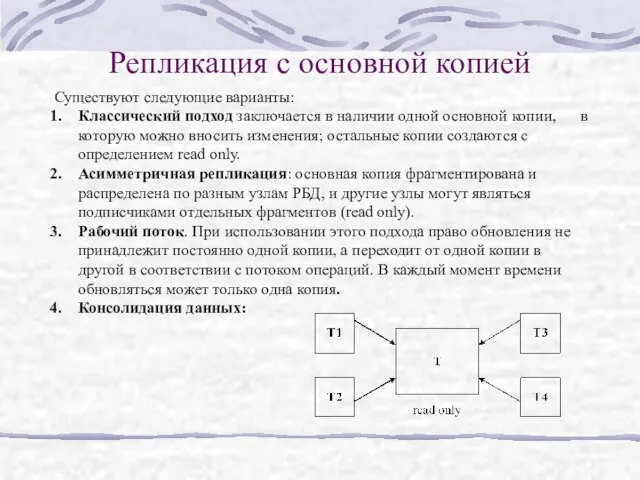
Слайд 10Репликация с основной копией
Существуют следующие варианты:
Классический подход заключается в наличии одной основной
Репликация с основной копией
Существуют следующие варианты:
Классический подход заключается в наличии одной основной
Слайд 11Репликация без основной копии
Симметричная репликация (без основной копии). Все копии реплицируемого набора
Репликация без основной копии
Симметричная репликация (без основной копии). Все копии реплицируемого набора

Слайд 12Репликация без основной копии
Конфликтные ситуации:
Добавление двух записей с одинаковыми первичными или уникальными
Репликация без основной копии
Конфликтные ситуации:
Добавление двух записей с одинаковыми первичными или уникальными

Слайд 13Репликация без основной копии
Методы разрешения конфликтов обновления:
Разрешение по приоритету узлов: для каждого
Репликация без основной копии
Методы разрешения конфликтов обновления:
Разрешение по приоритету узлов: для каждого

Слайд 14Репликация без основной копии
Способы реализации распространения изменений:
Использование триггеров.
Внутрь триггера помещаются
Репликация без основной копии
Способы реализации распространения изменений:
Использование триггеров.
Внутрь триггера помещаются

Слайд 15Распределенные запросы
Распределенным называется запрос, который обращается к двум и более узлам РБД,
Распределенные запросы
Распределенным называется запрос, который обращается к двум и более узлам РБД,

Слайд 16Распределенные запросы. Пример
База данных "Агентство недвижимости", 2 филиала – в Лондоне и
Распределенные запросы. Пример
База данных "Агентство недвижимости", 2 филиала – в Лондоне и

Слайд 17Распределенные запросы. Пример
Условия:
скорость передачи 10000 б/с;
задержка передачи – 1 с,
все кортежи по
Распределенные запросы. Пример
Условия:
скорость передачи 10000 б/с;
задержка передачи – 1 с,
все кортежи по

Слайд 18Распределенные ограничения целостности
Распределенные ограничения целостности возникают тогда, когда для проверки соблюдения какого-либо
Распределенные ограничения целостности
Распределенные ограничения целостности возникают тогда, когда для проверки соблюдения какого-либо

Слайд 19Распределенные транзакции
Распределенные транзакции обращаются к двум и более узлам и обновляют на
Распределенные транзакции
Распределенные транзакции обращаются к двум и более узлам и обновляют на

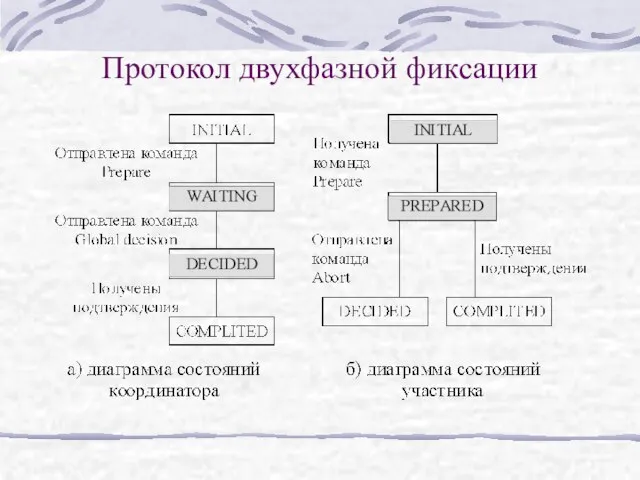
Слайд 20Протокол двухфазной фиксации
Протокол двухфазной фиксации
Слайд 21Действия координатора транзакции
Координатор выполняет протокол 2ФФ по следующему алгоритму:
I. Фаза 1 (голосование).
Занести
Действия координатора транзакции
Координатор выполняет протокол 2ФФ по следующему алгоритму:
I. Фаза 1 (голосование).
Занести

Слайд 22Действия участника транзакции
Участник выполняет протокол 2ФФ по следующему алгоритму:
При получении команды PREPARE,
Действия участника транзакции
Участник выполняет протокол 2ФФ по следующему алгоритму:
При получении команды PREPARE,

Слайд 23Протоколы ликвидации
Протокол ликвидации для координатора:
Тайм-аут в состоянии WAITING: координатор не может зафиксировать
Протоколы ликвидации
Протокол ликвидации для координатора:
Тайм-аут в состоянии WAITING: координатор не может зафиксировать

Слайд 24Протоколы восстановления
Действия, которые выполняются на отказавшем узле после его перезагрузки, называются протоколом
Протоколы восстановления
Действия, которые выполняются на отказавшем узле после его перезагрузки, называются протоколом

Слайд 25Протоколы восстановления
При отказе участника цель протокола восстановления – гарантировать, что после восстановления
Протоколы восстановления
При отказе участника цель протокола восстановления – гарантировать, что после восстановления

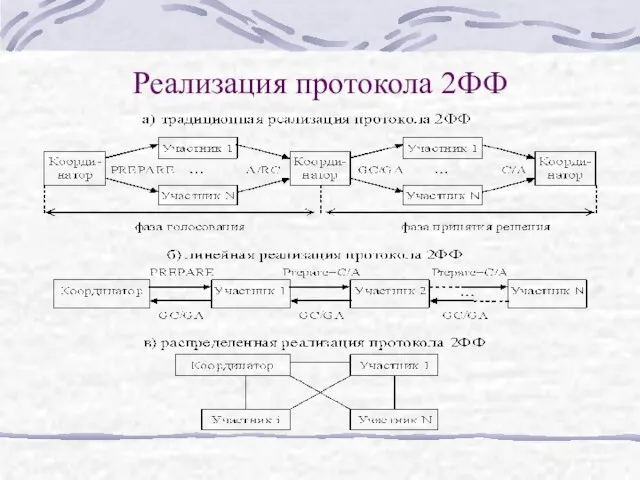
Слайд 26Реализация протокола 2ФФ
Реализация протокола 2ФФ
Слайд 27Поддержка распределенности в Oracle
Прозрачность распределенности.
Каждая часть данных, хранимых на одном компьютере в
Поддержка распределенности в Oracle
Прозрачность распределенности.
Каждая часть данных, хранимых на одном компьютере в

Слайд 28Связь в распределенной БД Oracle
Обращение к сервисам базы данных (серверу БД,
Связь в распределенной БД Oracle
Обращение к сервисам базы данных (серверу БД,

Слайд 29Связи в распределенной БД Oracle
Примеры.
Локальная база данных – HQ.ACME.COM.
Удаленная база данных –
Связи в распределенной БД Oracle
Примеры.
Локальная база данных – HQ.ACME.COM.
Удаленная база данных –

Слайд 30Работа в распределенной БД Oracle
Oracle различает следующие виды обработки данных в РБД:
удаленный запрос
Работа в распределенной БД Oracle
Oracle различает следующие виды обработки данных в РБД:
удаленный запрос

Слайд 31Моментальные снимки в Oracle
Oracle поддерживает два типа тиражирования:
базовое – копия обеспечивает доступ
Моментальные снимки в Oracle
Oracle поддерживает два типа тиражирования:
базовое – копия обеспечивает доступ

Слайд 32Моментальные снимки в Oracle
Примеры:
Моментальный снимок, основой которого является запрос
select * from employee@hr_link;
является
Моментальные снимки в Oracle
Примеры:
Моментальный снимок, основой которого является запрос
select * from employee@hr_link;
является

Слайд 33Моментальные снимки в Oracle
Синтаксис создания моментального снимка:
create snapshot [имя_схемы.]имя_снимка
[ { pctfree целое
Моментальные снимки в Oracle
Синтаксис создания моментального снимка:
create snapshot [имя_схемы.]имя_снимка
[ { pctfree целое
![Моментальные снимки в Oracle Синтаксис создания моментального снимка: create snapshot [имя_схемы.]имя_снимка [](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/395883/slide-32.jpg)
Слайд 34Моментальные снимки в Oracle
Пример создания МС на локальном сервере:
create snapshot emp_dept_count
pctfree 5
tablespace
Моментальные снимки в Oracle
Пример создания МС на локальном сервере:
create snapshot emp_dept_count
pctfree 5
tablespace

Слайд 35Моментальные снимки в Oracle
При создании моментального снимка в локальной базе данных создается:
таблица
Моментальные снимки в Oracle
При создании моментального снимка в локальной базе данных создается:
таблица

Слайд 36Регенерация моментальных снимков Oracle
Возможны два варианта:
REFRESH FAST (быстрая регенерация).
REFRESH COMPLETE (полная
Регенерация моментальных снимков Oracle
Возможны два варианта:
REFRESH FAST (быстрая регенерация).
REFRESH COMPLETE (полная

Слайд 37Регенерация моментальных снимков Oracle
Для быстрой регенерации необходим журнал моментальных снимков (snapshot log)
Регенерация моментальных снимков Oracle
Для быстрой регенерации необходим журнал моментальных снимков (snapshot log)

 Технологическое оборудование подготовки сырья
Технологическое оборудование подготовки сырья  Русский лес
Русский лес ГОТЫ И ЭМО – ДОРОГА В НИКУДА.
ГОТЫ И ЭМО – ДОРОГА В НИКУДА. СПИСОК ИСТОЧНИКОВ
СПИСОК ИСТОЧНИКОВ Май 2012
Май 2012 Основные компоненты содержания школьного образования по инфор-матике. Примерная программа курса информатики для 5-11классов.
Основные компоненты содержания школьного образования по инфор-матике. Примерная программа курса информатики для 5-11классов. Ответственность за преступления
Ответственность за преступления Групповой проект
Групповой проект Політична система суспільства та соціально-політичні механізми здійснення влади
Політична система суспільства та соціально-політичні механізми здійснення влади Гражданский бюджет города Сатпаев на 2012-2014 годы
Гражданский бюджет города Сатпаев на 2012-2014 годы Обеспечение доверия электронных государственных услуг на основе сервисов доверенной третьей стороны
Обеспечение доверия электронных государственных услуг на основе сервисов доверенной третьей стороны Математическая игра "Путешествие по станциям"
Математическая игра "Путешествие по станциям" Аттестация педагогических работников государственных и муниципальных образовательных учреждений с 1 января 2011г.
Аттестация педагогических работников государственных и муниципальных образовательных учреждений с 1 января 2011г. Ибн-Сина. Пути познания
Ибн-Сина. Пути познания Вышивание
Вышивание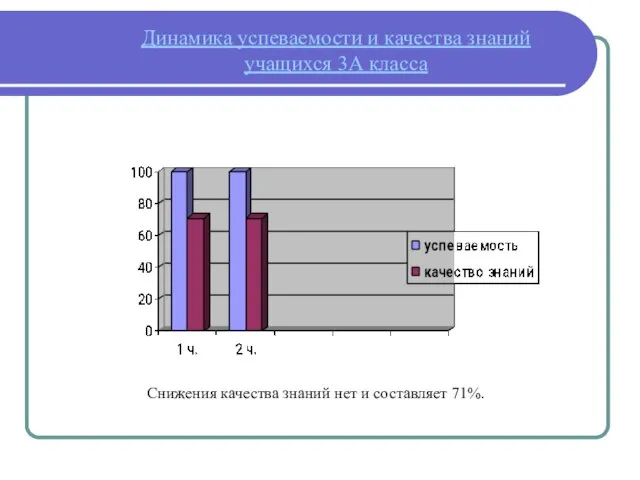 Динамика успеваемости и качества знаний учащихся
Динамика успеваемости и качества знаний учащихся Древний Киев (4 класс)
Древний Киев (4 класс) Программа обучения оператора участка измельчения руды. Теория процесса дробления руды
Программа обучения оператора участка измельчения руды. Теория процесса дробления руды Техническое оснащение кондитерского цеха
Техническое оснащение кондитерского цеха Спасибо за мир!
Спасибо за мир! Презентация на тему Награды Великой Отечественной войны
Презентация на тему Награды Великой Отечественной войны Стандартизация, основные понятия и определения
Стандартизация, основные понятия и определения Mariana Trench
Mariana Trench Николай Федорович Ватутин
Николай Федорович Ватутин заповедники россии
заповедники россии Презентация на тему Русская архитектура в XVII веке
Презентация на тему Русская архитектура в XVII веке  Рисование в нетрадиционной технике
Рисование в нетрадиционной технике A real professional. What does it mean?
A real professional. What does it mean?