- Синхронизация тракта данных

Содержание
- 2. Управление трактом данных Мы знаем что каждый цикл тракта данных можно охарактеризовать микрокомандой. Возникает вопрос: кто
- 3. Выбор следующей микрокоманды Каждая микрокоманда будет дополнена 9 адресными битами (NA) и 3 управляющими битами (JAM).
- 4. Стек Во всех языках программирования есть понятие процедур с локальными переменными. Вопрос: где они должны храниться?
- 5. Организация стека Переменные в стеке не получают абсолютных адресов! Вместо этого есть пара регистров LV и
- 6. Пример: int a(){ int a1, a2, a3; … ; b(); …d(); … } int b(){ int
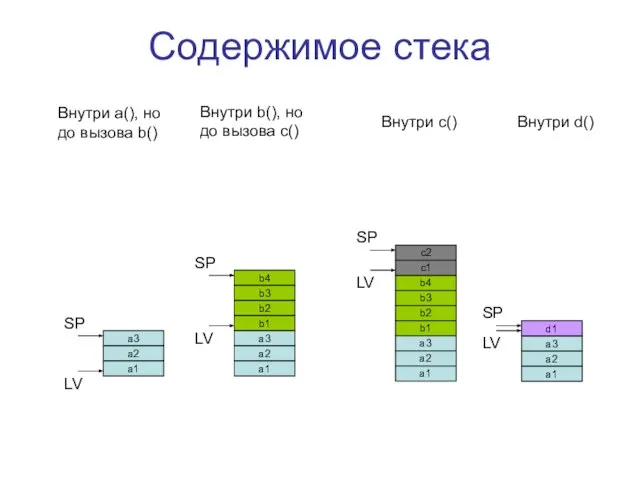
- 7. Содержимое стека a3 a2 a1 b4 b3 b2 b1 a3 a2 a1 b4 b3 b2 b1
- 9. Скачать презентацию
Слайд 2Управление трактом данных
Мы знаем что каждый цикл тракта данных можно охарактеризовать микрокомандой.
Управление трактом данных
Мы знаем что каждый цикл тракта данных можно охарактеризовать микрокомандой.

Слайд 3Выбор следующей микрокоманды
Каждая микрокоманда будет дополнена 9 адресными битами (NA) и 3
Выбор следующей микрокоманды
Каждая микрокоманда будет дополнена 9 адресными битами (NA) и 3

Слайд 4Стек
Во всех языках программирования есть понятие процедур с локальными переменными. Вопрос: где
Стек
Во всех языках программирования есть понятие процедур с локальными переменными. Вопрос: где

Слайд 5Организация стека
Переменные в стеке не получают абсолютных адресов! Вместо этого есть пара
Организация стека
Переменные в стеке не получают абсолютных адресов! Вместо этого есть пара

Слайд 6Пример:
int a(){ int a1, a2, a3; … ; b(); …d(); … }
int
Пример:
int a(){ int a1, a2, a3; … ; b(); …d(); … }
int

Слайд 7Содержимое стека
a3
a2
a1
b4
b3
b2
b1
a3
a2
a1
b4
b3
b2
b1
a3
a2
a1
c2
c1
a3
a2
a1
d1
SP
LV
SP
SP
SP
LV
LV
LV
Внутри a(), но
до вызова b()
Внутри b(), но
до вызова c()
Внутри
Содержимое стека
a3
a2
a1
b4
b3
b2
b1
a3
a2
a1
b4
b3
b2
b1
a3
a2
a1
c2
c1
a3
a2
a1
d1
SP
LV
SP
SP
SP
LV
LV
LV
Внутри a(), но
до вызова b()
Внутри b(), но
до вызова c()
Внутри
 Консультации по написанию заявки РНФ
Консультации по написанию заявки РНФ Художественные поиски свободы в искусстве
Художественные поиски свободы в искусстве Презентация на тему Психолого-педагогическое использование сказкотерапии для воспитания положительных нравственных качеств лич
Презентация на тему Психолого-педагогическое использование сказкотерапии для воспитания положительных нравственных качеств лич Кадровое планирование в организации
Кадровое планирование в организации Педагогическая психология как наука Психология обучения
Педагогическая психология как наука Психология обучения Методические условия эффективности применения современных образовательных технологий
Методические условия эффективности применения современных образовательных технологий 8кл.23.09
8кл.23.09 Рисуем героев любимых сказок
Рисуем героев любимых сказок Подвижная игрушка Слоненок
Подвижная игрушка Слоненок Кабы всё знал, так бы не учился
Кабы всё знал, так бы не учился Душа танца
Душа танца Формирование читательской компетентности младшего школьника
Формирование читательской компетентности младшего школьника Защита прав ребенка в школе. МОУ «СОШ № 8»
Защита прав ребенка в школе. МОУ «СОШ № 8» Лучшие люди России
Лучшие люди России Управление личными знаниями
Управление личными знаниями Rezultate interviu
Rezultate interviu Разработка высоконагруженных проектов(например – сайтов для сообществ)
Разработка высоконагруженных проектов(например – сайтов для сообществ) Техническое задание на фото
Техническое задание на фото Опасные природные явления
Опасные природные явления Понятие об экономическом механизме функционирования фирмы и характеристика его основных элементов
Понятие об экономическом механизме функционирования фирмы и характеристика его основных элементов День Святого Валентина в США
День Святого Валентина в США Былина о Садко и Морском царе. Океан-море синее, Н.А. Римский – Корсаков
Былина о Садко и Морском царе. Океан-море синее, Н.А. Римский – Корсаков рабочая одежда
рабочая одежда Бардымскому району 90 лет
Бардымскому району 90 лет Конструирование фартука
Конструирование фартука Педагогический совет —коллегиальная форма управления
Педагогический совет —коллегиальная форма управления Программа социального исследования
Программа социального исследования Народная танцевальная культура
Народная танцевальная культура