- Статистические методы исследования алгоритмов текстового ранжирования поисковых систем

Содержание
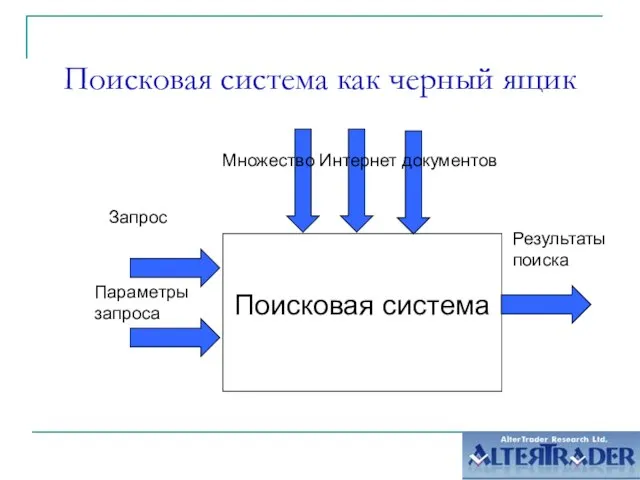
- 2. Поисковая система как черный ящик Результаты поиска
- 3. Простейшие частотные метрики состава html-страниц Абсолютная теговая частота леммы слова – количество канонических форм слова в
- 4. Производные от ICF/IDF метрики IDF(L)*N(L), IDF(L)*N%(L) (5) (6) где li,j-все леммы j-го предложения, содержащего L, Lenj-количество
- 5. Коэффициенты корреляции Пирсона (для количественных величин) (8), где - математическое ожидание величины Х. Кенделла (для ранговых
- 6. Этапы исследования принципов текстового ранжирования Этап 1. Формирования множества данных для анализа. Делается подборка запросов, максимально
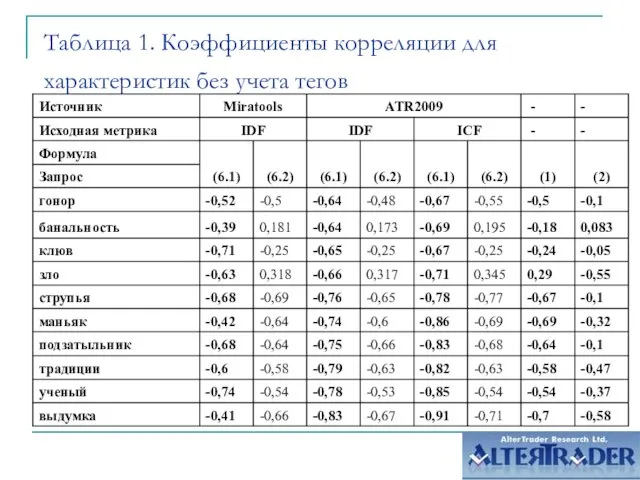
- 7. Таблица 1. Коэффициенты корреляции для характеристик без учета тегов
- 8. Таблица 2. Коэффициенты корреляции для характеристик тега body
- 9. Таблица 3. Коэффициенты корреляции для характеристик тега title
- 10. Двухфакторная линейная регрессионная модель для оценивания позиции оптимизируемой страницы: Y(X1,Х2)=a2X2+a1X1+a0 Система уравнений по МНК Решение системы
- 12. Скачать презентацию
Слайд 3Простейшие частотные метрики состава html-страниц
Абсолютная теговая частота леммы слова – количество канонических
Простейшие частотные метрики состава html-страниц
Абсолютная теговая частота леммы слова – количество канонических

Слайд 4Производные от ICF/IDF метрики
IDF(L)*N(L), IDF(L)*N%(L) (5)
(6)
где li,j-все леммы j-го предложения, содержащего L,
Производные от ICF/IDF метрики
IDF(L)*N(L), IDF(L)*N%(L) (5)
(6)
где li,j-все леммы j-го предложения, содержащего L,

Слайд 5Коэффициенты корреляции
Пирсона (для количественных величин)
(8),
где - математическое ожидание величины Х.
Кенделла
Коэффициенты корреляции
Пирсона (для количественных величин)
(8),
где - математическое ожидание величины Х.
Кенделла

Слайд 6Этапы исследования принципов текстового ранжирования
Этап 1. Формирования множества данных для анализа.
Этапы исследования принципов текстового ранжирования
Этап 1. Формирования множества данных для анализа.

Слайд 7Таблица 1. Коэффициенты корреляции для характеристик без учета тегов
Таблица 1. Коэффициенты корреляции для характеристик без учета тегов
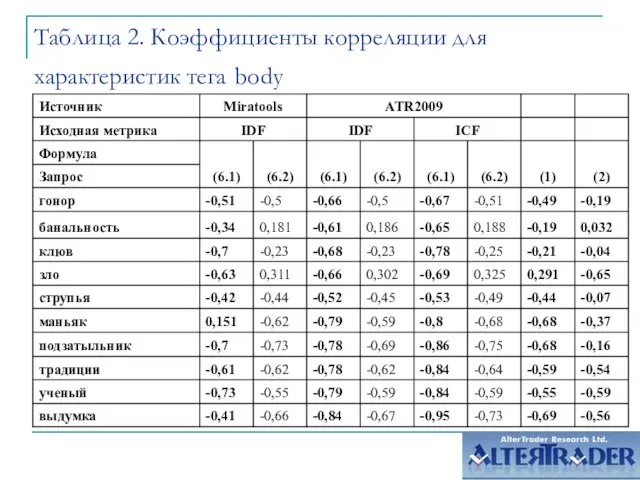
Слайд 8Таблица 2. Коэффициенты корреляции для характеристик тега body
Таблица 2. Коэффициенты корреляции для характеристик тега body
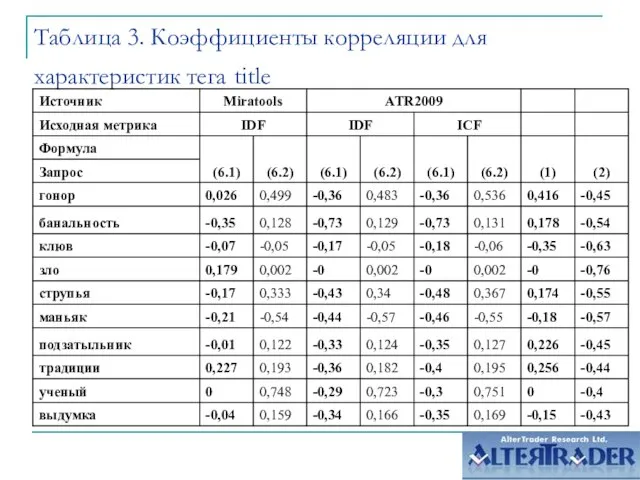
Слайд 9Таблица 3. Коэффициенты корреляции для характеристик тега title
Таблица 3. Коэффициенты корреляции для характеристик тега title
Слайд 10Двухфакторная линейная регрессионная модель для оценивания позиции оптимизируемой страницы: Y(X1,Х2)=a2X2+a1X1+a0
Система
Двухфакторная линейная регрессионная модель для оценивания позиции оптимизируемой страницы: Y(X1,Х2)=a2X2+a1X1+a0
Система

 Моделирование физических явлений
Моделирование физических явлений Вирусы в нашей жизни
Вирусы в нашей жизни Что такое симметрия_ Как получить симметричные детали. (1)
Что такое симметрия_ Как получить симметричные детали. (1) Презентация на тему На фронтах второй мировой войны
Презентация на тему На фронтах второй мировой войны  Забытые и современные виды спорта
Забытые и современные виды спорта Объем прямоугольного параллелепипеда 5 класс
Объем прямоугольного параллелепипеда 5 класс Освоение космоса
Освоение космоса ДЕЙСТВИЯ ПРИ ЖЕЛЕЗНОДОРОЖНОЙ АВАРИИ
ДЕЙСТВИЯ ПРИ ЖЕЛЕЗНОДОРОЖНОЙ АВАРИИ Праздничный пир в теремных палатах
Праздничный пир в теремных палатах Трение не учитывать нельзя
Трение не учитывать нельзя Childe Harold vs Евгений Онегин
Childe Harold vs Евгений Онегин Потребитель – король на рынке
Потребитель – король на рынке Эффективные приемы, используемые на уроках в начальной школе
Эффективные приемы, используемые на уроках в начальной школе 51 Любит лишь Христос
51 Любит лишь Христос Типология людей по А. Е. Личко, Г. Юнгу, Э. Кречмеру
Типология людей по А. Е. Личко, Г. Юнгу, Э. Кречмеру Doc
Doc Презентация на тему Презентация по экономической географии Кабардино-Балкарская республика
Презентация на тему Презентация по экономической географии Кабардино-Балкарская республика  Летние каникулы в Крыму
Летние каникулы в Крыму Практические аспекты мониторинга программ
Практические аспекты мониторинга программ Влагостойкое напольное покрытие. Коллекция AQUAFLOOR STONE
Влагостойкое напольное покрытие. Коллекция AQUAFLOOR STONE Нейрофармакологические и психотропные свойства АЭП при лечении эпилепсии
Нейрофармакологические и психотропные свойства АЭП при лечении эпилепсии Квиллинг – бумажная филигрань
Квиллинг – бумажная филигрань Экономические индексы
Экономические индексы Иисус, Ты Царь царей, Господь наш,Ты царишь над всей землей;Победил врагов Своих на ГолгофеИ воссел не троне Ты.Да, Ты Царь наш, Цар
Иисус, Ты Царь царей, Господь наш,Ты царишь над всей землей;Победил врагов Своих на ГолгофеИ воссел не троне Ты.Да, Ты Царь наш, Цар Character Traits
Character Traits АНАЛИЗ РАБОТЫ ШКОЛЫ
АНАЛИЗ РАБОТЫ ШКОЛЫ Buckingham Palace
Buckingham Palace Presentation Title
Presentation Title