- Сжатие информации. Алгоритм Хаффмана

Содержание
- 2. Сжатие информации Сжатие данных – сокращение объема данных при сохранении закодированного в них содержания.
- 3. Сжатие информации Сжатие происходит за счет устранения избыточности кода, например, за счет упрощения кодов, исключения из
- 4. Алгоритмы сжатия 1. Равномерное сжатие с использованием кодов одной длины. Этот метод используется, если в записи
- 5. Сжатие с использованием кодов переменной длины В этом случае возникает проблема отделения кодов символов друг от
- 6. Префиксные коды Чтобы понять, как строятся префиксные коды, рассмотрим, как построить ориентированный граф, определяющий этот код.
- 7. Префиксные коды Построим граф этого кода. Из начальной вершины выходят две дуги, помеченные 0 и 1.
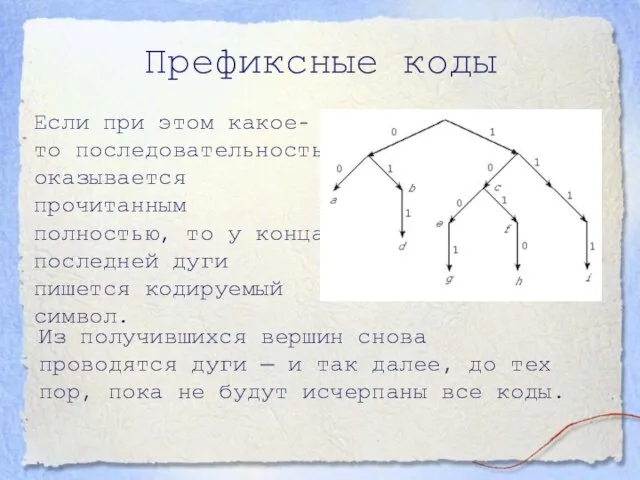
- 8. Префиксные коды Если при этом какое-то последовательность оказывается прочитанным полностью, то у конца последней дуги пишется
- 9. Префиксные коды Если известен граф, созданный по префиксному коду, то по этому графу легко восстанавливается код
- 10. Алгоритм Хаффмана Алгоритм Хаффмана — адаптивный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан
- 11. 1. Символы исходного алфавита образуют вершины. Вес каждой вершины вес равен количеству вхождений данного символа в
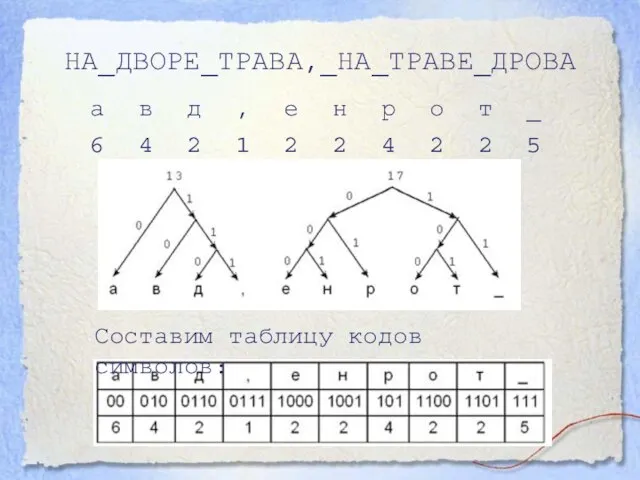
- 12. НА_ДВОРЕ_ТРАВА,_НА_ТРАВЕ_ДРОВА Составим таблицу кодов символов:
- 13. Найдем объем сообщения после кодирования кодом Хаффмана: 2·6 + 3·4 + 4·2 + 4·1 + 4·2
- 14. Математики доказали, что среди алгоритмов, кодирующих каждый символ по отдельности и целым количеством бит, алгоритм Хаффмана
- 15. Для кодирования сообщения, состоящего из букв А, Б, В, Г и Д, используется неравномерный двоичный код,
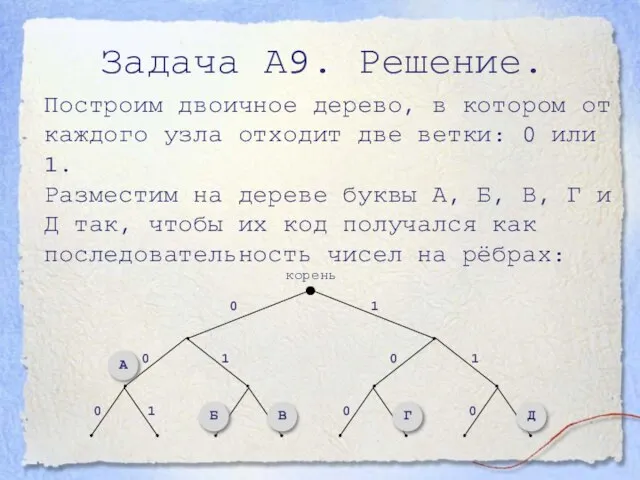
- 16. Задача А9. Решение. Построим двоичное дерево, в котором от каждого узла отходит две ветки: 0 или
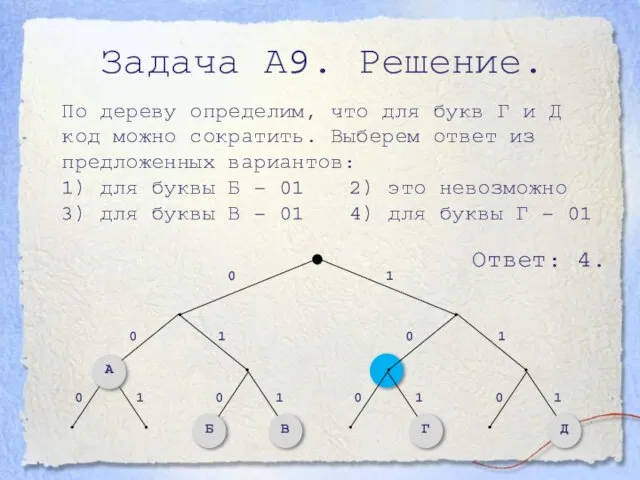
- 17. Задача А9. Решение. По дереву определим, что для букв Г и Д код можно сократить. Выберем
- 18. Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать
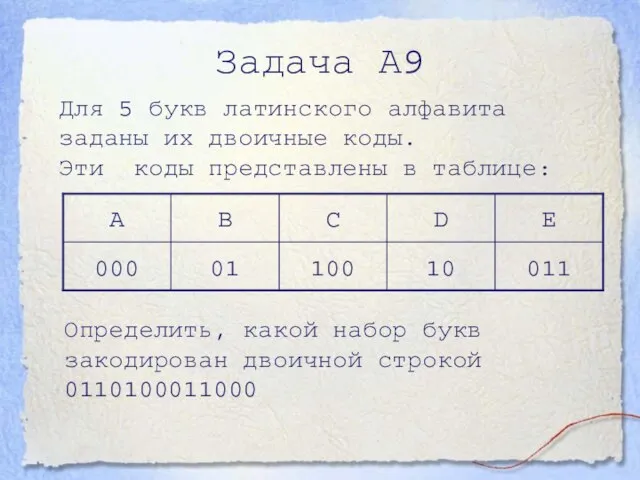
- 19. Для 5 букв латинского алфавита заданы их двоичные коды. Эти коды представлены в таблице: Задача А9
- 21. Скачать презентацию
Слайд 2Сжатие информации
Сжатие данных – сокращение объема данных при сохранении закодированного в них
Сжатие информации
Сжатие данных – сокращение объема данных при сохранении закодированного в них

Слайд 3Сжатие информации
Сжатие происходит за счет устранения избыточности кода, например, за счет упрощения
Сжатие информации
Сжатие происходит за счет устранения избыточности кода, например, за счет упрощения

Слайд 4Алгоритмы сжатия
1. Равномерное сжатие с использованием кодов одной длины.
Этот метод используется, если
Алгоритмы сжатия
1. Равномерное сжатие с использованием кодов одной длины.
Этот метод используется, если

Слайд 5Сжатие с использованием кодов переменной длины
В этом случае возникает проблема отделения кодов
Сжатие с использованием кодов переменной длины
В этом случае возникает проблема отделения кодов

Слайд 6Префиксные коды
Чтобы понять, как строятся префиксные коды, рассмотрим, как построить ориентированный граф,
Префиксные коды
Чтобы понять, как строятся префиксные коды, рассмотрим, как построить ориентированный граф,

Слайд 7Префиксные коды
Построим граф этого кода.
Из начальной вершины выходят две дуги, помеченные 0
Префиксные коды
Построим граф этого кода.
Из начальной вершины выходят две дуги, помеченные 0

Слайд 8Префиксные коды
Если при этом какое-то последовательность оказывается прочитанным полностью, то у конца
Префиксные коды
Если при этом какое-то последовательность оказывается прочитанным полностью, то у конца
Слайд 9Префиксные коды
Если известен граф, созданный по префиксному коду, то по этому графу
Префиксные коды
Если известен граф, созданный по префиксному коду, то по этому графу

Слайд 10Алгоритм Хаффмана
Алгоритм Хаффмана — адаптивный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью.
Был разработан 1952 году аспирантом Массачусетского технологического института Дэвидом
Алгоритм Хаффмана
Алгоритм Хаффмана — адаптивный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью.
Был разработан 1952 году аспирантом Массачусетского технологического института Дэвидом

Слайд 111. Символы исходного алфавита образуют вершины. Вес каждой вершины вес равен количеству
1. Символы исходного алфавита образуют вершины. Вес каждой вершины вес равен количеству

Слайд 12НА_ДВОРЕ_ТРАВА,_НА_ТРАВЕ_ДРОВА
Составим таблицу кодов символов:
НА_ДВОРЕ_ТРАВА,_НА_ТРАВЕ_ДРОВА
Составим таблицу кодов символов:
Слайд 13Найдем объем сообщения после кодирования кодом Хаффмана: 2·6 + 3·4 + 4·2
Найдем объем сообщения после кодирования кодом Хаффмана: 2·6 + 3·4 + 4·2

Слайд 14Математики доказали, что среди алгоритмов, кодирующих каждый символ по отдельности и целым
Математики доказали, что среди алгоритмов, кодирующих каждый символ по отдельности и целым

Слайд 15Для кодирования сообщения, состоящего из букв А, Б, В, Г и Д,
Для кодирования сообщения, состоящего из букв А, Б, В, Г и Д,

Слайд 16Задача А9. Решение.
Построим двоичное дерево, в котором от каждого узла отходит две
Задача А9. Решение.
Построим двоичное дерево, в котором от каждого узла отходит две
Слайд 17Задача А9. Решение.
По дереву определим, что для букв Г и Д код
Задача А9. Решение.
По дереву определим, что для букв Г и Д код
Слайд 18Для передачи по каналу связи сообщения, состоящего только из букв А, Б,
Для передачи по каналу связи сообщения, состоящего только из букв А, Б,

Слайд 19Для 5 букв латинского алфавита заданы их двоичные коды.
Эти коды представлены
Для 5 букв латинского алфавита заданы их двоичные коды.
Эти коды представлены
 Presentation Title
Presentation Title  Увлечение рыбалкой
Увлечение рыбалкой Презентация на тему Понятие и виды государственных служащих
Презентация на тему Понятие и виды государственных служащих  Сад камней
Сад камней Имя прилагательное
Имя прилагательное Presentation Title
Presentation Title  Музыкальный клип Milka-Медленно
Музыкальный клип Milka-Медленно ТЕОРИЯ ФОТОЭФФЕКТА.ПРИМЕНЕНИЕ ФОТОЭФФЕКТА.
ТЕОРИЯ ФОТОЭФФЕКТА.ПРИМЕНЕНИЕ ФОТОЭФФЕКТА. По знаменитым местам мира
По знаменитым местам мира Бизнес-проект Б1Б2Б3 Банк Конечный спрос 111 10 111213,214,2 15,6 Сумма кредитов: 36,2 10% Сырье, материалы, условия производства 16,6.
Бизнес-проект Б1Б2Б3 Банк Конечный спрос 111 10 111213,214,2 15,6 Сумма кредитов: 36,2 10% Сырье, материалы, условия производства 16,6. Что нам стоит сайт построить?
Что нам стоит сайт построить? Задачи в жизненных ситуациях
Задачи в жизненных ситуациях Описание Фундамент: длина 12м ширина12м высота 2,7м Плита низ – ширина 30 см Плита вверх – ширина 30 см Стены по периметру – ширина 50 см
Описание Фундамент: длина 12м ширина12м высота 2,7м Плита низ – ширина 30 см Плита вверх – ширина 30 см Стены по периметру – ширина 50 см  Исследование двухэтапного алгоритма поиска навигационного сигнала
Исследование двухэтапного алгоритма поиска навигационного сигнала Портфолио учителя
Портфолио учителя Русская народная вышивка
Русская народная вышивка Презентация на тему Конфликты в школе
Презентация на тему Конфликты в школе Сегментирование рынка
Сегментирование рынка  Презентация на тему Атмосфера: значение, строение
Презентация на тему Атмосфера: значение, строение Classification of sounds
Classification of sounds Культура Руси в 10 – 13 веках
Культура Руси в 10 – 13 веках Лепка из солёного теста
Лепка из солёного теста Etron - справжня сила енергії
Etron - справжня сила енергії Доброта, красота и гармония
Доброта, красота и гармония Lektsia_3_1_opredelenie_prochnosti_kirpicha_i_metalla_ispytania_Avtosokhranennyi_774
Lektsia_3_1_opredelenie_prochnosti_kirpicha_i_metalla_ispytania_Avtosokhranennyi_774 "Петербургские повести" Н.В. Гоголя
"Петербургские повести" Н.В. Гоголя Устав. Общие положения
Устав. Общие положения Нейронные сети
Нейронные сети