- Технология Data Mining

Содержание
- 2. Data Mining Это собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных,
- 3. Классификация задач Data Mining классификация, кластеризация, прогнозирование, ассоциация, визуализация, анализ и обнаружение отклонений, оценивание, анализ связей.
- 4. Основные методы Data mining методы классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных
- 5. Нечеткая логика Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической
- 6. Периоды развития Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде,
- 7. Математический аппарат Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF(x) – степень принадлежности
- 8. Нечеткая и лингвистическая переменные Нечеткая переменная описывается набором (N,X,A), где N – это название переменной, X
- 9. Типовые формы кривых для задания функций принадлежности Существует свыше десятка типовых форм кривых для задания функций
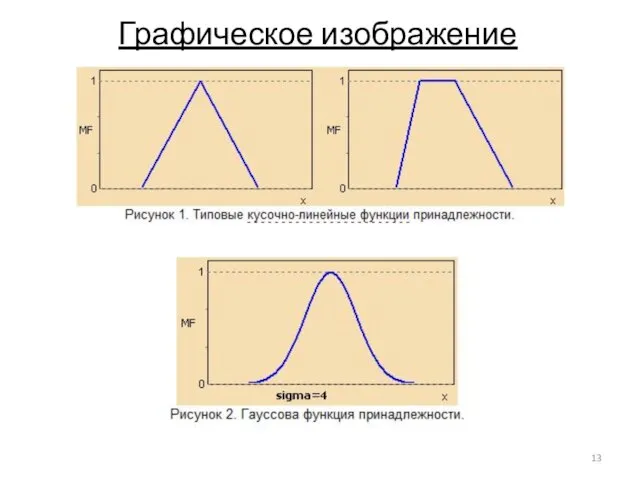
- 10. Треугольная функция принадлежности Определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:
- 11. Трапецеидальная функция принадлежности Для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
- 12. Гауссова функция принадлежности Функция принадлежности гауссова типа описывается формулой: где с – центра нечеткого множества
- 13. Графическое изображение
- 14. Формализация неточного понятия «возраст человека» Так, для человека 48 лет степень принадлежности к множеству "Молодой" равна
- 15. Механизм логического вывода В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий
- 16. Интеграция с интеллектуальными парадигмами Гибридизация методов интеллектуальной обработки информации – девиз, под которым прошли 90-е годы
- 17. Примеры объединения нескольких технологий Нечеткие нейронные сети, Адаптивные нечеткие системы, Нечеткие запросы, Нечеткие ассоциативные правила, Нечеткие
- 18. Применение методов нечеткой логики при оценке информационных ресурсов предприятий Информационные ресурсы организации (ИР) – ресурсы нового
- 19. Оценка информационных ресурсов
- 20. Предположим, что стоимости, полученные тремя основными методами, представляют собой Т – числа и имеют следующие значения
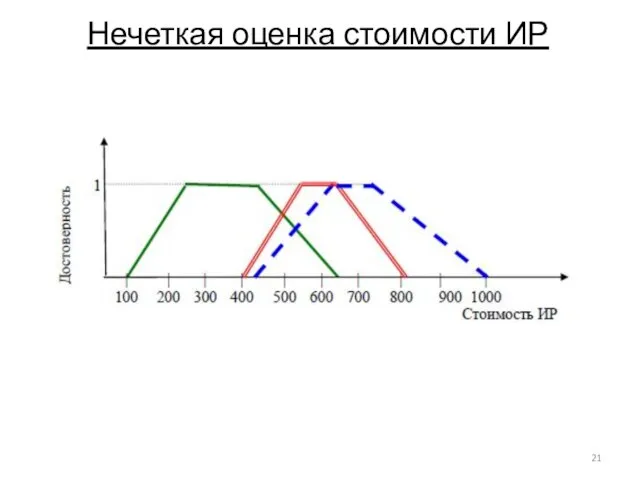
- 21. Нечеткая оценка стоимости ИР
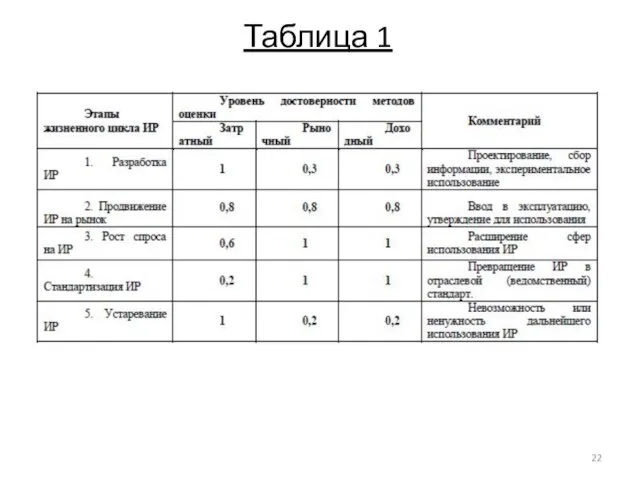
- 22. Таблица 1
- 23. Таблица 2
- 24. Таблица 3
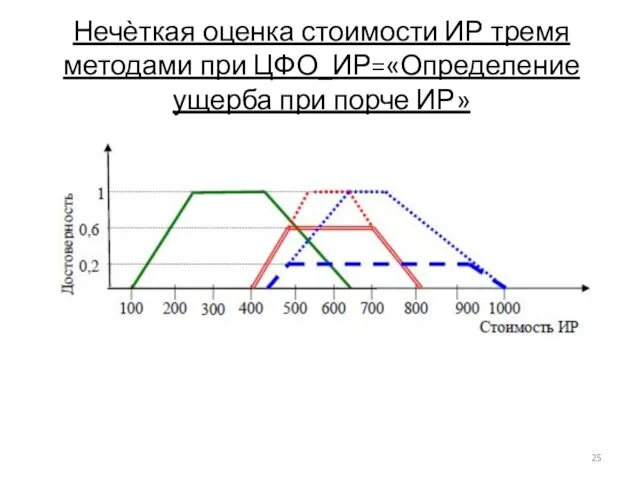
- 25. Нечѐткая оценка стоимости ИР тремя методами при ЦФО_ИР=«Определение ущерба при порче ИР»
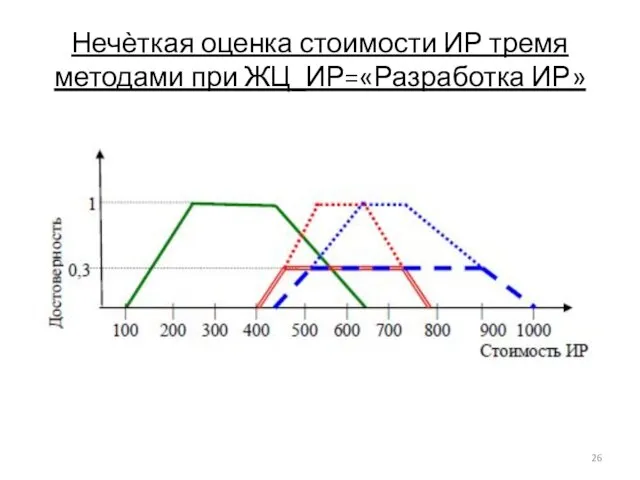
- 26. Нечѐткая оценка стоимости ИР тремя методами при ЖЦ_ИР=«Разработка ИР»
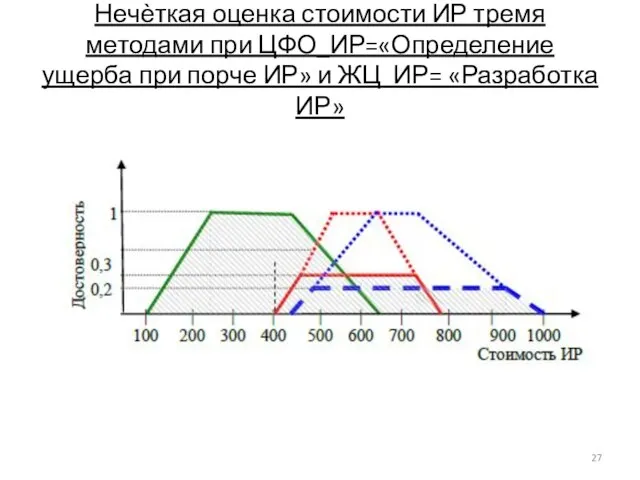
- 27. Нечѐткая оценка стоимости ИР тремя методами при ЦФО_ИР=«Определение ущерба при порче ИР» и ЖЦ_ИР= «Разработка ИР»
- 28. Результат На основе полученной нечѐткой оценки стоимости ИР путѐм дефаззификации определяется чѐткая оценка ИР, равная абсциссе
- 30. Скачать презентацию
Слайд 2Data Mining
Это собирательное название, используемое для обозначения совокупности методов обнаружения в
Data Mining
Это собирательное название, используемое для обозначения совокупности методов обнаружения в

Слайд 3Классификация задач Data Mining
классификация,
кластеризация,
прогнозирование,
ассоциация,
визуализация,
анализ и обнаружение отклонений,
оценивание,
Классификация задач Data Mining
классификация,
кластеризация,
прогнозирование,
ассоциация,
визуализация,
анализ и обнаружение отклонений,
оценивание,

Слайд 4Основные методы Data mining
методы классификации, моделирования и прогнозирования, основанные на применении деревьев
Основные методы Data mining
методы классификации, моделирования и прогнозирования, основанные на применении деревьев

Слайд 5Нечеткая логика
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy
Нечеткая логика
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy

Слайд 6Периоды развития
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких
Периоды развития
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких

Слайд 7Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF(x)
Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF(x)

Слайд 8Нечеткая и лингвистическая переменные
Нечеткая переменная описывается набором (N,X,A), где N – это
Нечеткая и лингвистическая переменные
Нечеткая переменная описывается набором (N,X,A), где N – это

Слайд 9Типовые формы кривых для задания функций принадлежности
Существует свыше десятка типовых форм
Типовые формы кривых для задания функций принадлежности
Существует свыше десятка типовых форм

Слайд 10Треугольная функция принадлежности
Определяется тройкой чисел (a,b,c), и ее значение в точке
Треугольная функция принадлежности
Определяется тройкой чисел (a,b,c), и ее значение в точке

Слайд 11Трапецеидальная функция принадлежности
Для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
Трапецеидальная функция принадлежности
Для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):

Слайд 12Гауссова функция принадлежности
Функция принадлежности гауссова типа описывается формулой:
где с – центра
Гауссова функция принадлежности
Функция принадлежности гауссова типа описывается формулой:
где с – центра

Слайд 13Графическое изображение
Графическое изображение
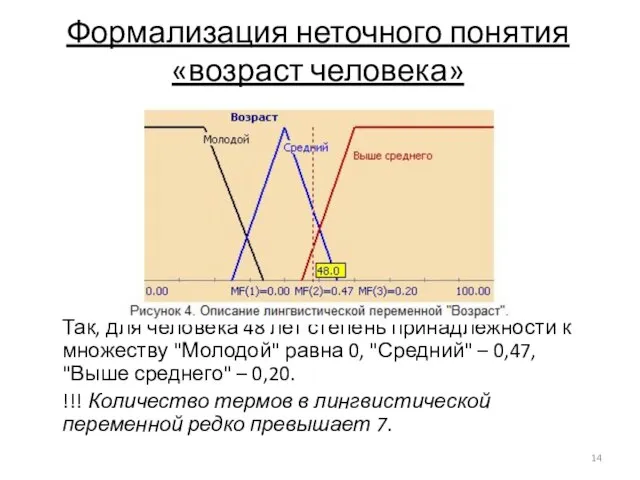
Слайд 14Формализация неточного понятия «возраст человека»
Так, для человека 48 лет степень принадлежности к
Формализация неточного понятия «возраст человека»
Так, для человека 48 лет степень принадлежности к
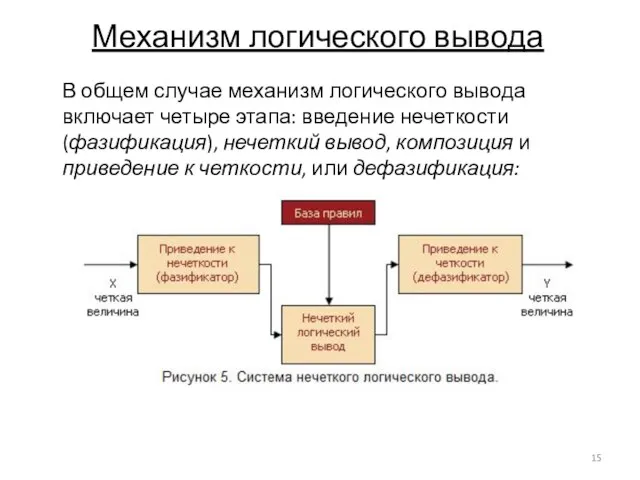
Слайд 15Механизм логического вывода
В общем случае механизм логического вывода включает четыре этапа:
Механизм логического вывода
В общем случае механизм логического вывода включает четыре этапа:
Слайд 16Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под
Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под

Слайд 17Примеры объединения нескольких технологий
Нечеткие нейронные сети,
Адаптивные нечеткие системы,
Нечеткие запросы,
Нечеткие ассоциативные правила,
Нечеткие когнитивные
Примеры объединения нескольких технологий
Нечеткие нейронные сети,
Адаптивные нечеткие системы,
Нечеткие запросы,
Нечеткие ассоциативные правила,
Нечеткие когнитивные

Слайд 18Применение методов нечеткой логики при оценке информационных ресурсов предприятий
Информационные ресурсы организации (ИР)
Применение методов нечеткой логики при оценке информационных ресурсов предприятий
Информационные ресурсы организации (ИР)

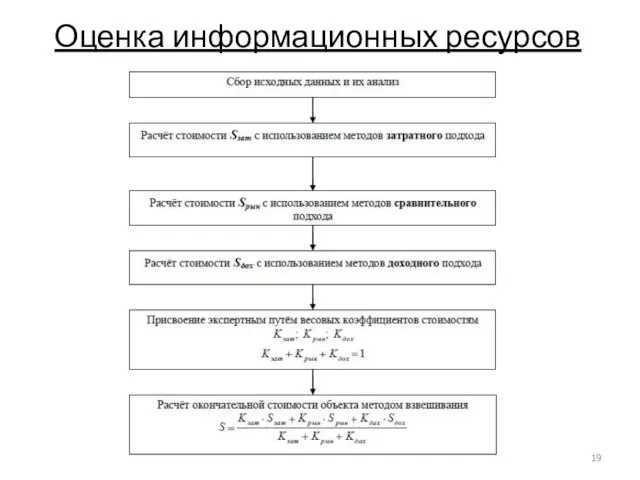
Слайд 19Оценка информационных ресурсов
Оценка информационных ресурсов
Слайд 20 Предположим, что стоимости, полученные тремя основными методами, представляют собой Т –
Предположим, что стоимости, полученные тремя основными методами, представляют собой Т –

Слайд 21Нечеткая оценка стоимости ИР
Нечеткая оценка стоимости ИР
Слайд 22Таблица 1
Таблица 1
Слайд 23Таблица 2
Таблица 2

Слайд 24Таблица 3
Таблица 3

Слайд 25Нечѐткая оценка стоимости ИР тремя методами при ЦФО_ИР=«Определение ущерба при порче ИР»
Нечѐткая оценка стоимости ИР тремя методами при ЦФО_ИР=«Определение ущерба при порче ИР»
Слайд 26Нечѐткая оценка стоимости ИР тремя методами при ЖЦ_ИР=«Разработка ИР»
Нечѐткая оценка стоимости ИР тремя методами при ЖЦ_ИР=«Разработка ИР»
Слайд 27Нечѐткая оценка стоимости ИР тремя методами при ЦФО_ИР=«Определение ущерба при порче ИР»
Нечѐткая оценка стоимости ИР тремя методами при ЦФО_ИР=«Определение ущерба при порче ИР»
Слайд 28Результат
На основе полученной нечѐткой оценки стоимости ИР путѐм дефаззификации определяется чѐткая
Результат
На основе полученной нечѐткой оценки стоимости ИР путѐм дефаззификации определяется чѐткая

 ИТС ПРОФ - профессиональная информационная система для бухгалтераи руководителя
ИТС ПРОФ - профессиональная информационная система для бухгалтераи руководителя EasyMani
EasyMani Pepsi - участник фестиваля Пикник Афиша
Pepsi - участник фестиваля Пикник Афиша Именины Загоскина М.Н
Именины Загоскина М.Н Исаак Бабель
Исаак Бабель В некотором царстве,В некотором государстве,вернее в ТюрлемеЖивет своей жизнью
В некотором царстве,В некотором государстве,вернее в ТюрлемеЖивет своей жизнью Памятники Гоголю
Памятники Гоголю Правила безопасного обращения с бытовыми электроприборами
Правила безопасного обращения с бытовыми электроприборами Черная металлургия
Черная металлургия Психолого-педагогическая диагностика
Психолого-педагогическая диагностика Рукописные книги
Рукописные книги Использование приёмов технологии развития критического мышления при написании части «С».
Использование приёмов технологии развития критического мышления при написании части «С». МЕДИЦИНСКАЯ И БИОЛОГИЧЕСКАЯ ФИЗИКА
МЕДИЦИНСКАЯ И БИОЛОГИЧЕСКАЯ ФИЗИКА Передача жилых домов в управление
Передача жилых домов в управление Aleksander Sergeevich PUSHKIN 1799-1837
Aleksander Sergeevich PUSHKIN 1799-1837 Сергей Александрович Есенин.(1895-1925)
Сергей Александрович Есенин.(1895-1925) Презентация на тему "Будни и праздники 5 класса" - скачать презентации по Педагогике
Презентация на тему "Будни и праздники 5 класса" - скачать презентации по Педагогике Эпоха возрождения
Эпоха возрождения Интуитивные решения. Интуитивное мышление
Интуитивные решения. Интуитивное мышление Ведение реестра организаций отдыха детей и их оздоровления , расположенных на территории Свердловской области
Ведение реестра организаций отдыха детей и их оздоровления , расположенных на территории Свердловской области экстр пси ДПО
экстр пси ДПО Профессии в области хореографии
Профессии в области хореографии Изменение величин
Изменение величин Поведение во время грозы
Поведение во время грозы Тайна бумажного листа
Тайна бумажного листа Воспитательная программа «Любознайки»
Воспитательная программа «Любознайки» Век Просвещения
Век Просвещения Проблемный метод обученияв преподавании истории
Проблемный метод обученияв преподавании истории