- Платформы по соревнованиям в анализе данных (DM)

Содержание
- 3. Платформы по соревнованиям в анализе данных (DM)
- 4. Преимущества Kaggle Наиболее раскрученная платформа Возможность запускать in-class соревнования Крутые соревнования от топовых IT компаний Красивый,
- 5. Как выглядят соревнования по DM?
- 6. Цикл решения задач DM
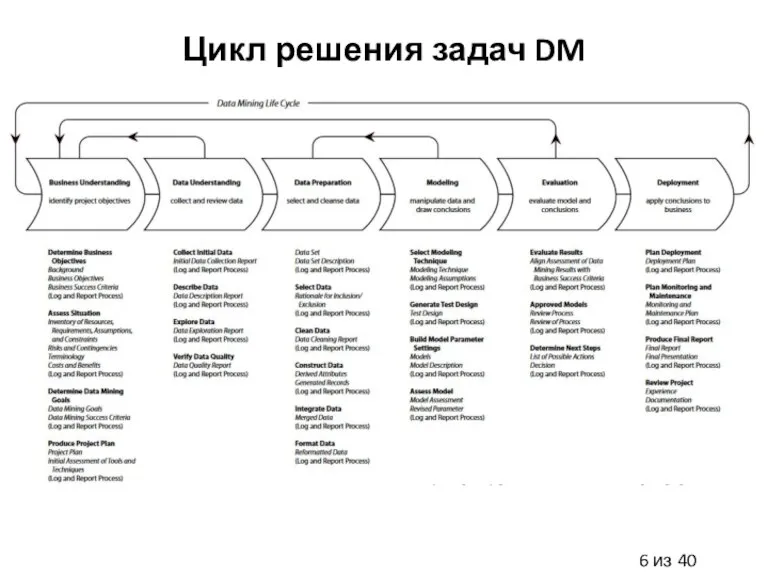
- 7. Понимание задачи Определение и формулировании бизнес задачи Оценка рисков, затрат, общего профита Постановка DM целей Определение
- 8. Понимание данных: Первый шаг Сбор данных Какие данные есть: сколько примеров, сколько признаков, какие признаки по
- 9. Понимание данных: Второй шаг Описательные статистики Корреляции Пирсона, Спирмена Проверка статистических гипотез (нормальность, проверку на распределение)
- 10. Подготовка данных Выбор и интеграция данных Форматирование данных Предобработка данных: заполнение пропусков, определение выбросов, нормализация данных,
- 11. Построение моделей Выбор подходящих моделей, соответствующих проверяемым гипотезам Определение дизайна тестирования Обучение моделей с настройкой гиперпараметров
- 12. Оценка качества моделей Анализ эффективности моделей на тестовом множестве: статистические гипотезы, корреляции Вычисление метрик оценки качества
- 13. Развертывание системы Финальный отчет по проекту Выполнены ли все поставленные DM цели? Удовлетворяют ли результаты критерия
- 15. Исследование распределений: Линеаризация
- 16. Предобработка данных Преобразование категориальных переменных: OneHotEncoder, LabelEncoder Преобразование категориальных переменных: hashing trick Преобразование дат: pandas.TimeStamp, pandas.to_datetime,
- 17. Заполнение пропусков Заполнение нулями Заполнение следующими, предыдущими значениями (pandas.fillna) Заполнение средними, модами, медианами (sklearn.preprocessing.Imputer) Заполнение с
- 18. Определение выбросов Определение через распределения: по квантилям, перцентилям, по другим правилам пальца Определение через визуализацию, использую
- 19. Нормализация данных Стандартная нормализация Нормализация в 0-1 или в -1, 1(для нейроных сетей) Стемминг, лемматизация, TF-IDF
- 20. Выбор признаков Выбор через model-free методы: scikit-feature Статистики (sklearn.feature_selection.SelectKBest) Корреляции Пирсона, Спирмена Выбор через model-based методы:
- 21. Permutation Feature Importance
- 22. Deep Feature Selection Li, Yifeng, Chih-Yu Chen, and Wyeth W. Wasserman. "Deep Feature Selection: Theory and
- 23. Heuristic Variable Selection Yacoub, Meziane, and Y. Bennani. "HVS: A heuristic for variable selection in multilayer
- 24. Экстракция признаков Экстракция через визуальный анализ (handcrafted признаки) Экстракция через model-based методы (NN, RandomForest, т.д.) Экстракция
- 25. Инженерия признаков Простейшие handcrafted признаки: среднее, дисперсия и т.п. по примеру Исследование взаимодействия признаков между собой
- 26. Построение моделей Simple data Complex data
- 27. Обучение нейронных сетей Использовать методы регуляризации для сетей: Dropout, BatchNormalization, weight decay Использовать продвинутые активационные функции
- 28. Обучение нейронных сетей
- 29. Обучение нейронных сетей
- 31. Модели победители на Kaggle соревнованиях Использовать GBM из xgboost, random forest, regularized greedy forest Использовать NN
- 32. Технические Tips & Tricks Делать верную предобработку данных Правильно работать с нормализацией/выбросами/пропусками Проводить визуальный анализ данных,
- 33. Настройка гиперпараметров Найти оптимальное подмножество данных на котором стоит обучаться и настраивать гиперпараметры моделей Использовать следующую
- 34. Оптимальный порог
- 35. Калибровка вероятностей sklearn.calibration.CalibratedClassifierCV
- 36. Несбалансированные данные Использовать методы балансировки данных: imbalanced-learn Undersampling (SVM, kNN, NN) Oversampling (SVM, kNN, NN) Использовать
- 37. Спасибо за внимание! Вопросы? Евгений Путин Университет ИТМО [email protected] 25 мая 2017 Санкт-Петербург
- 39. Скачать презентацию

Слайд 3Платформы по соревнованиям в
анализе данных (DM)
Платформы по соревнованиям в
анализе данных (DM)

Слайд 4Преимущества Kaggle
Наиболее раскрученная платформа
Возможность запускать in-class соревнования
Крутые соревнования от топовых IT компаний
Красивый,
Преимущества Kaggle
Наиболее раскрученная платформа
Возможность запускать in-class соревнования
Крутые соревнования от топовых IT компаний
Красивый,

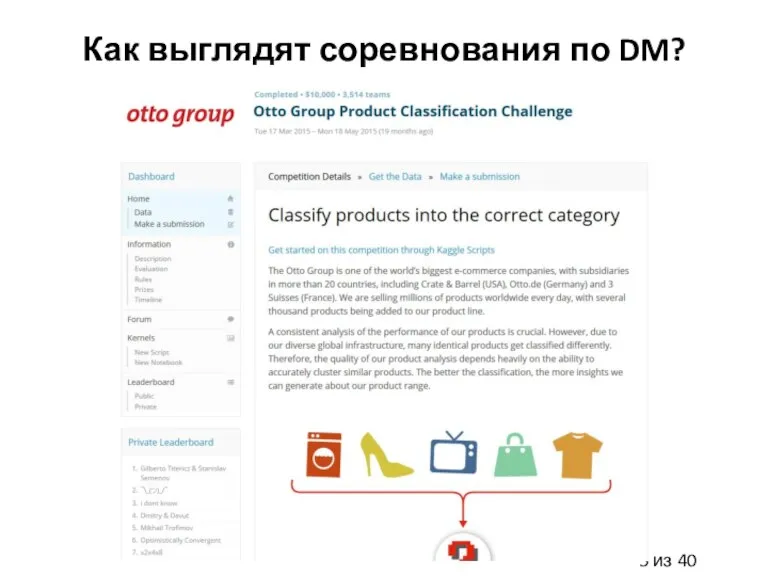
Слайд 5Как выглядят соревнования по DM?
Как выглядят соревнования по DM?
Слайд 6Цикл решения задач DM
Цикл решения задач DM
Слайд 7Понимание задачи
Определение и формулировании бизнес задачи
Оценка рисков, затрат, общего профита
Постановка DM целей
Определение
Понимание задачи
Определение и формулировании бизнес задачи
Оценка рисков, затрат, общего профита
Постановка DM целей
Определение

Слайд 8Понимание данных: Первый шаг
Сбор данных
Какие данные есть: сколько примеров, сколько признаков, какие
Понимание данных: Первый шаг
Сбор данных
Какие данные есть: сколько примеров, сколько признаков, какие

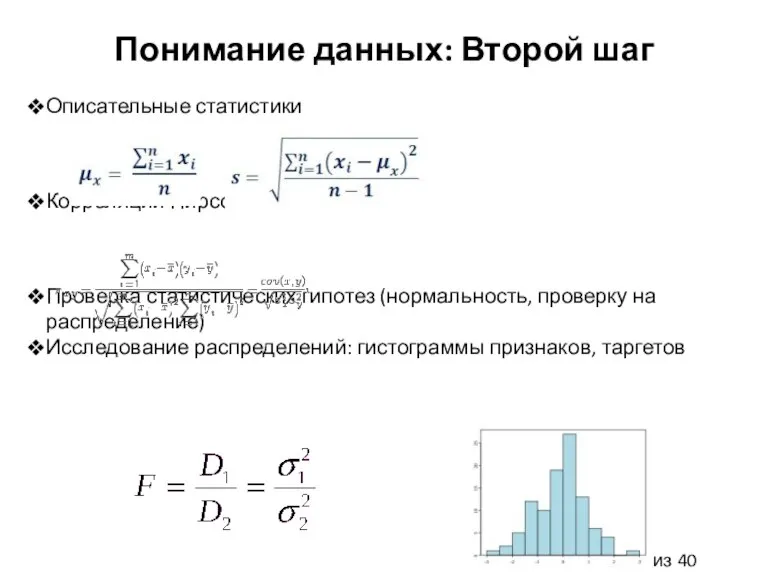
Слайд 9Понимание данных: Второй шаг
Описательные статистики
Корреляции Пирсона, Спирмена
Проверка статистических гипотез (нормальность, проверку на
Понимание данных: Второй шаг
Описательные статистики
Корреляции Пирсона, Спирмена
Проверка статистических гипотез (нормальность, проверку на
Слайд 10Подготовка данных
Выбор и интеграция данных
Форматирование данных
Предобработка данных: заполнение пропусков, определение выбросов, нормализация
Подготовка данных
Выбор и интеграция данных
Форматирование данных
Предобработка данных: заполнение пропусков, определение выбросов, нормализация

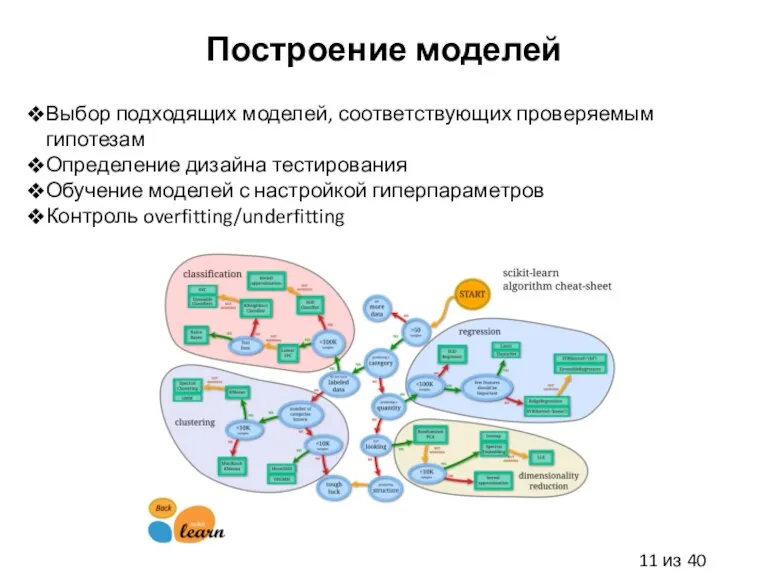
Слайд 11Построение моделей
Выбор подходящих моделей, соответствующих проверяемым гипотезам
Определение дизайна тестирования
Обучение моделей с настройкой
Построение моделей
Выбор подходящих моделей, соответствующих проверяемым гипотезам
Определение дизайна тестирования
Обучение моделей с настройкой
Слайд 12Оценка качества моделей
Анализ эффективности моделей на тестовом множестве: статистические гипотезы, корреляции
Вычисление метрик
Оценка качества моделей
Анализ эффективности моделей на тестовом множестве: статистические гипотезы, корреляции
Вычисление метрик

Слайд 13Развертывание системы
Финальный отчет по проекту
Выполнены ли все поставленные DM цели?
Удовлетворяют ли результаты
Развертывание системы
Финальный отчет по проекту
Выполнены ли все поставленные DM цели?
Удовлетворяют ли результаты


Слайд 15Исследование распределений: Линеаризация
Исследование распределений: Линеаризация
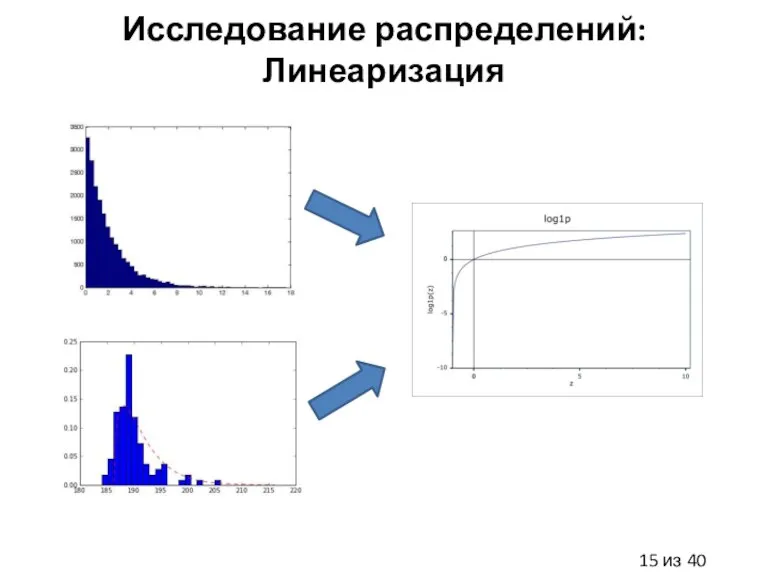
Слайд 16Предобработка данных
Преобразование категориальных переменных: OneHotEncoder, LabelEncoder
Преобразование категориальных переменных: hashing trick
Преобразование дат: pandas.TimeStamp,
Предобработка данных
Преобразование категориальных переменных: OneHotEncoder, LabelEncoder
Преобразование категориальных переменных: hashing trick
Преобразование дат: pandas.TimeStamp,

Слайд 17Заполнение пропусков
Заполнение нулями
Заполнение следующими, предыдущими значениями (pandas.fillna)
Заполнение средними, модами, медианами (sklearn.preprocessing.Imputer)
Заполнение с
Заполнение пропусков
Заполнение нулями
Заполнение следующими, предыдущими значениями (pandas.fillna)
Заполнение средними, модами, медианами (sklearn.preprocessing.Imputer)
Заполнение с
Слайд 18Определение выбросов
Определение через распределения: по квантилям, перцентилям, по другим правилам пальца
Определение через
Определение выбросов
Определение через распределения: по квантилям, перцентилям, по другим правилам пальца
Определение через

Слайд 19Нормализация данных
Стандартная нормализация
Нормализация в 0-1 или в -1, 1(для нейроных сетей)
Стемминг, лемматизация,
Нормализация данных
Стандартная нормализация
Нормализация в 0-1 или в -1, 1(для нейроных сетей)
Стемминг, лемматизация,

Слайд 20Выбор признаков
Выбор через model-free методы: scikit-feature
Статистики (sklearn.feature_selection.SelectKBest)
Корреляции Пирсона, Спирмена
Выбор через model-based методы:
RandomForest
Выбор признаков
Выбор через model-free методы: scikit-feature
Статистики (sklearn.feature_selection.SelectKBest)
Корреляции Пирсона, Спирмена
Выбор через model-based методы:
RandomForest

Слайд 21Permutation Feature Importance
Permutation Feature Importance

Слайд 22Deep Feature Selection
Li, Yifeng, Chih-Yu Chen, and Wyeth W. Wasserman. "Deep Feature
Deep Feature Selection
Li, Yifeng, Chih-Yu Chen, and Wyeth W. Wasserman. "Deep Feature

Слайд 23Heuristic Variable Selection
Yacoub, Meziane, and Y. Bennani. "HVS: A heuristic for variable
Heuristic Variable Selection
Yacoub, Meziane, and Y. Bennani. "HVS: A heuristic for variable
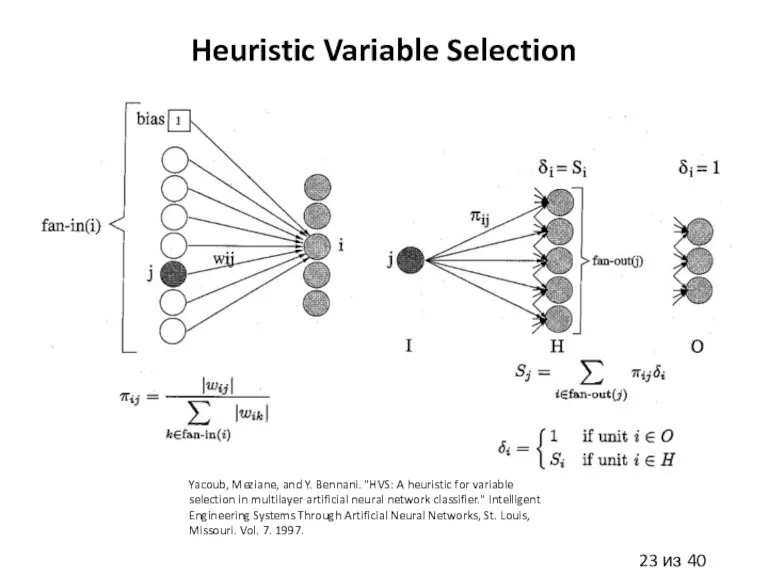
Слайд 24Экстракция признаков
Экстракция через визуальный анализ (handcrafted признаки)
Экстракция через model-based методы (NN, RandomForest,
Экстракция признаков
Экстракция через визуальный анализ (handcrafted признаки)
Экстракция через model-based методы (NN, RandomForest,
Слайд 25Инженерия признаков
Простейшие handcrafted признаки: среднее, дисперсия и т.п. по примеру
Исследование взаимодействия признаков
Инженерия признаков
Простейшие handcrafted признаки: среднее, дисперсия и т.п. по примеру
Исследование взаимодействия признаков

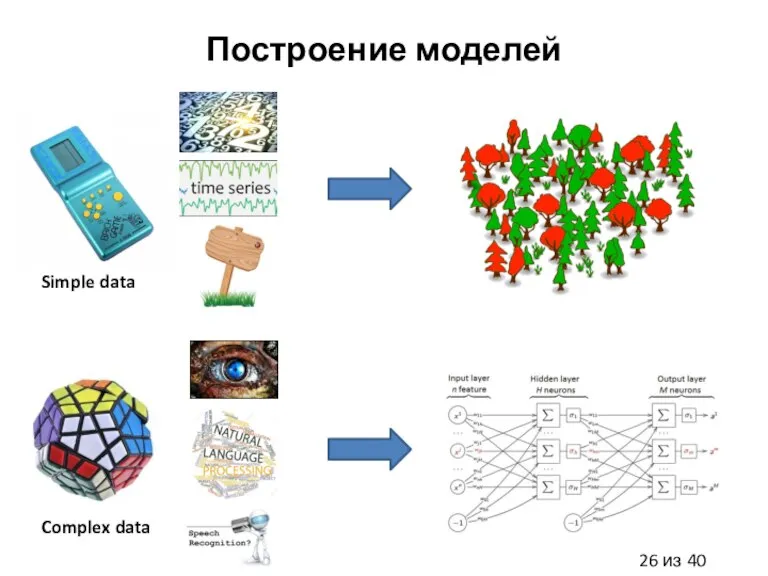
Слайд 26Построение моделей
Simple data
Complex data
Построение моделей
Simple data
Complex data
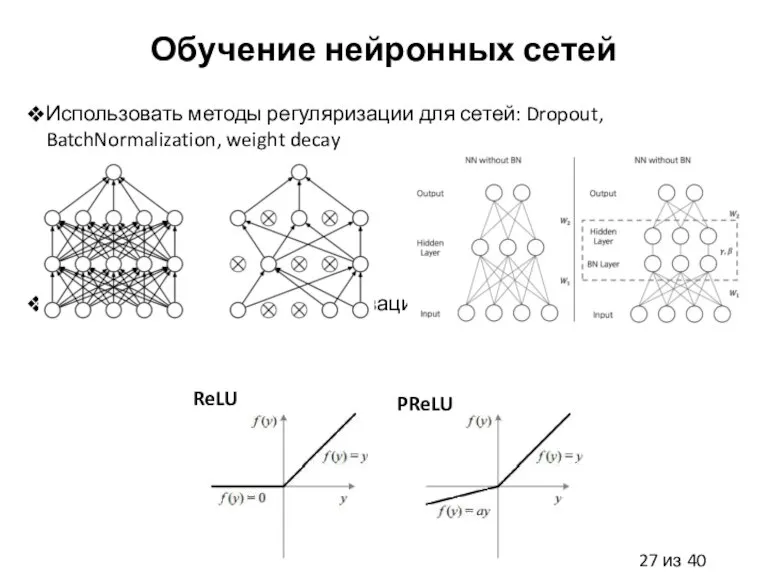
Слайд 27Обучение нейронных сетей
Использовать методы регуляризации для сетей: Dropout, BatchNormalization, weight decay
Использовать продвинутые
Обучение нейронных сетей
Использовать методы регуляризации для сетей: Dropout, BatchNormalization, weight decay
Использовать продвинутые
Слайд 28Обучение нейронных сетей
Обучение нейронных сетей

Слайд 29Обучение нейронных сетей
Обучение нейронных сетей

Слайд 31Модели победители на Kaggle соревнованиях
Использовать GBM из xgboost, random forest, regularized greedy
Модели победители на Kaggle соревнованиях
Использовать GBM из xgboost, random forest, regularized greedy

Слайд 32Технические Tips & Tricks
Делать верную предобработку данных
Правильно работать с нормализацией/выбросами/пропусками
Проводить визуальный анализ
Технические Tips & Tricks
Делать верную предобработку данных
Правильно работать с нормализацией/выбросами/пропусками
Проводить визуальный анализ

Слайд 33Настройка гиперпараметров
Найти оптимальное подмножество данных на котором стоит обучаться и настраивать гиперпараметры
Настройка гиперпараметров
Найти оптимальное подмножество данных на котором стоит обучаться и настраивать гиперпараметры

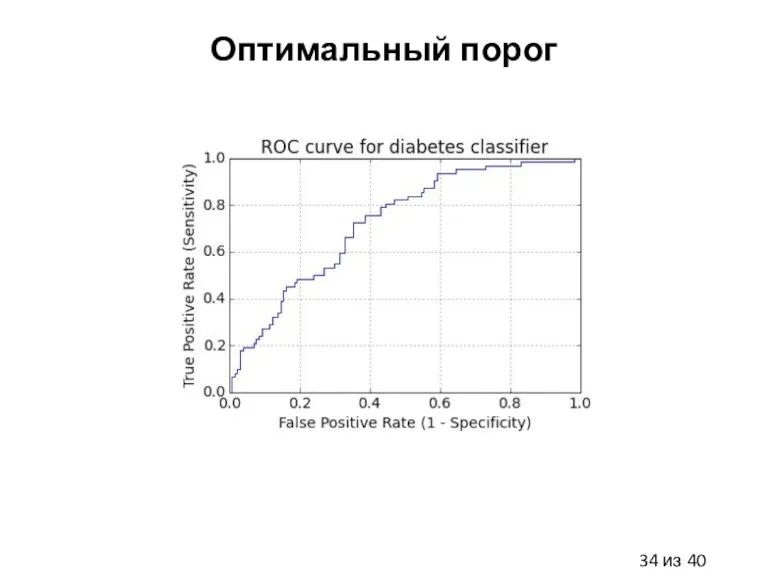
Слайд 34Оптимальный порог
Оптимальный порог
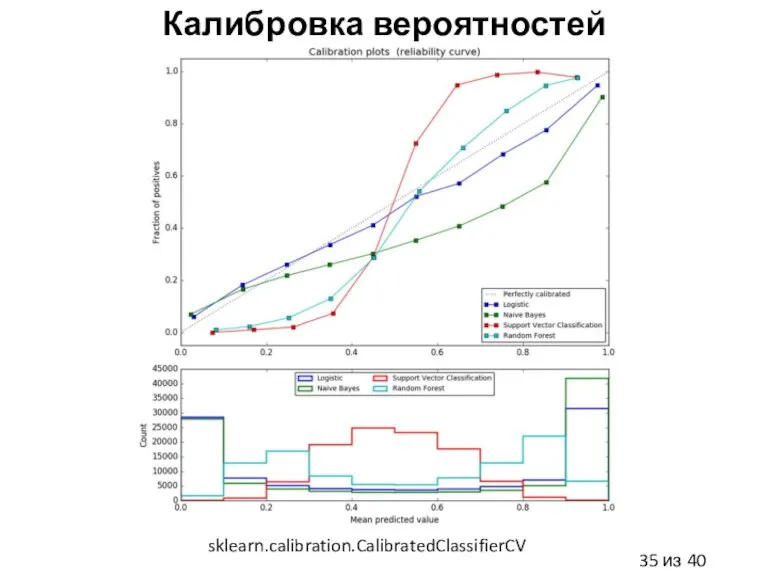
Слайд 35Калибровка вероятностей
sklearn.calibration.CalibratedClassifierCV
Калибровка вероятностей
sklearn.calibration.CalibratedClassifierCV
Слайд 36Несбалансированные данные
Использовать методы балансировки данных: imbalanced-learn
Undersampling (SVM, kNN, NN)
Oversampling (SVM, kNN, NN)
Использовать
Несбалансированные данные
Использовать методы балансировки данных: imbalanced-learn
Undersampling (SVM, kNN, NN)
Oversampling (SVM, kNN, NN)
Использовать

Слайд 37Спасибо за внимание!
Вопросы?
Евгений Путин
Университет ИТМО
[email protected]
25 мая 2017
Санкт-Петербург
Спасибо за внимание!
Вопросы?
Евгений Путин
Университет ИТМО
[email protected]
25 мая 2017
Санкт-Петербург

 Теория поведения потребителя. Кардиналистский и ординалистский подходы
Теория поведения потребителя. Кардиналистский и ординалистский подходы Рынок и конкуренция
Рынок и конкуренция عوامل موثر در تعیین سود خرده فروش در بازار برق
عوامل موثر در تعیین سود خرده فروش در بازار برق Аудит эффективности и перспективы его развития
Аудит эффективности и перспективы его развития Спрос на ресурсы. Правила использования ресурсов
Спрос на ресурсы. Правила использования ресурсов Причины безработицы на рынке труда в России
Причины безработицы на рынке труда в России Государственный социализм Отто фон Бисмарка
Государственный социализм Отто фон Бисмарка Россия. Швеция. Италия
Россия. Швеция. Италия Предмет макроэкономики и макроэкономический анализ. Макроэкономическое равновесие
Предмет макроэкономики и макроэкономический анализ. Макроэкономическое равновесие Проблема утечки умов и её последствия для белорусской экономики
Проблема утечки умов и её последствия для белорусской экономики Организация международной торговли
Организация международной торговли Турбулентность экономических процессов и финансы
Турбулентность экономических процессов и финансы Казахстан в рейтинге Doing Business 2016
Казахстан в рейтинге Doing Business 2016 Анализ ликвидности баланса спортивной организации
Анализ ликвидности баланса спортивной организации Мастер- класс: Планируем на перспективу
Мастер- класс: Планируем на перспективу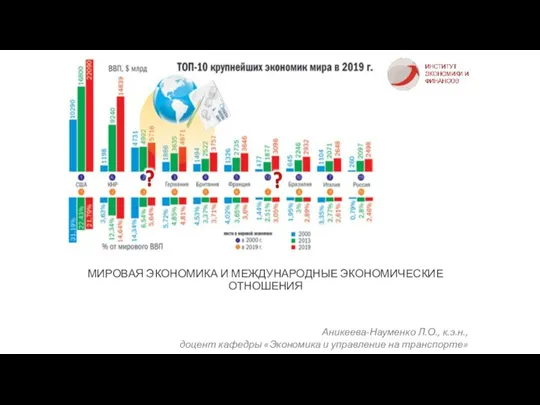 Мировая экономика и международные экономические отношения
Мировая экономика и международные экономические отношения Система экономических отношений (Тема 2)
Система экономических отношений (Тема 2) Фирмы в экономике
Фирмы в экономике Полезность и поведение потребителя. Кардиналистский подход в теории потребительского выбора
Полезность и поведение потребителя. Кардиналистский подход в теории потребительского выбора Экономика как наука
Экономика как наука Модель инновационного потенциала личности и группы
Модель инновационного потенциала личности и группы Тема 1.2 Конкурентоспособность государств на мировом рынке ПОНЯТИЕ КОНКУРЕНТОСПОСОБНОСТИ ГОСУДАРСТВА Способность экономики с
Тема 1.2 Конкурентоспособность государств на мировом рынке ПОНЯТИЕ КОНКУРЕНТОСПОСОБНОСТИ ГОСУДАРСТВА Способность экономики с Банковская система
Банковская система Теория производства фирмы. Лекция 3
Теория производства фирмы. Лекция 3 Основные фонды предприятия
Основные фонды предприятия Семейная экономика
Семейная экономика Экономное здоровое питание (10 класс)
Экономное здоровое питание (10 класс) Вторичный рынок дорожно-строительной техники в РФ: проблемы и перспективы
Вторичный рынок дорожно-строительной техники в РФ: проблемы и перспективы