- Задача классификации Газпром нефть

Содержание
- 2. Задача классификации Задача классификации Области применения алгоритмов классификации Формальное математическое определение Несбалансированная классификация Критерии качества классификации:
- 3. Области применения алгоритмов классификации
- 4. Области применения алгоритмов классификации Регрессия - множество ответов бесконечно, так как они являются действительными числами или
- 5. Области применения алгоритмов классификации Оценка кредитоспособности заемщиков. Задачи медицинской диагностики Оптическое распознавание символов. Распознавание речи. Обнаружение
- 6. Формальное математическое определение
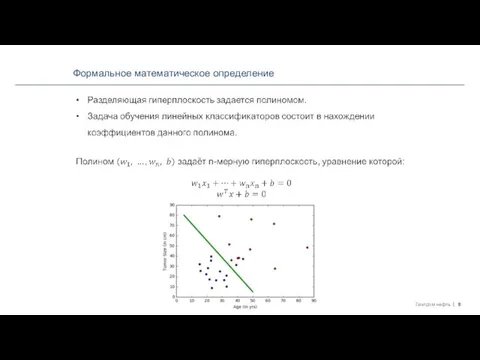
- 7. Формальное математическое определение Разделяющая гиперплоскость – это гиперплоскость, которая отделяет группы объектов, принадлежащим различным классам. Если
- 8. Формальное математическое определение
- 9. Формальное математическое определение
- 10. Несбалансированная классификация Imbalanced Data : один из классов представлен значительно бо́льшим количеством объектов, чем другой –
- 11. Несбалансированная классификация Задачи, в которых несбалансированность данных не просто общая проблема, а ожидаема в силу специфики
- 12. Несбалансированная классификация Обучение на несбалансированных данных осложняется расположением отдельных примеров выборок: Вкрапления Наложения s – чистые
- 13. Несбалансированная классификация Основные подходы к решению проблемы несбалансированных данных в классификации: Сэмплинг (sampling) Уменьшение большего класса
- 14. Несбалансированная классификация Уменьшение большего класса (Undersampling) Случайный или синтетический выбор прецедентов мажоритарного класса в обучающую выборку.
- 15. Несбалансированная классификация Уменьшение большего класса (Undersampling) Поиск связей Томека (Tomek Links) Этот способ хорошо удаляет записи,
- 16. Несбалансированная классификация Уменьшение большего класса (Undersampling) Правило сосредоточенного ближайшего соседа (Condensed Nearest Neighbor Rule) Этот метод
- 17. Несбалансированная классификация Уменьшение большего класса (Undersampling) Односторонний сэмплинг (One-side Sampling, One-sided Selection) Применяется правило сосредоточенного ближайшего
- 18. Несбалансированная классификация Уменьшение большего класса (Undersampling) Правило «очищающего» соседа (Neighborhood Cleaning Rule) Все примеры классифицируются по
- 19. Несбалансированная классификация Увеличение меньшего класса (Oversampling) Добавление прецедентов миноритарного класса позволяет сохранить всю имеющуюся информацию. Недостаток
- 20. Несбалансированная классификация Увеличение меньшего класса (Oversampling) Алгоритм SMOTE (Synthetic Minority Oversampling Technique) - генерация некоторого количества
- 21. Несбалансированная классификация Увеличение меньшего класса (Oversampling) Алгоритм ADASYN (Adaptive Synthetic Minority Oversampling) - использование функции плотности
- 22. Несбалансированная классификация Изменение порога решения (Changing Performance Metric) Многие алгоритмы классификации определяют степень достоверности предсказания. При
- 23. Критерии качества классификации Определим ROC-кривую (receiver operating characteristic, рабочая характеристика приёмника) Ось абсцисс: доля неправильных положительных
- 24. Критерии качества классификации Точность и полнота (Precision and Recall) для случая бинарной классификации TP - правильные
- 25. Критерии качества классификации
- 27. Скачать презентацию
Слайд 2Задача классификации
Задача классификации
Области применения алгоритмов классификации
Формальное математическое определение
Несбалансированная классификация
Критерии качества классификации:
Precision, Recall,
Задача классификации
Задача классификации
Области применения алгоритмов классификации
Формальное математическое определение
Несбалансированная классификация
Критерии качества классификации:
Precision, Recall,

Слайд 3Области применения алгоритмов классификации
Области применения алгоритмов классификации

Слайд 4Области применения алгоритмов классификации
Регрессия - множество ответов бесконечно, так как они являются
Области применения алгоритмов классификации
Регрессия - множество ответов бесконечно, так как они являются

Слайд 5Области применения алгоритмов классификации
Оценка кредитоспособности заемщиков.
Задачи медицинской диагностики
Оптическое распознавание символов.
Распознавание речи.
Обнаружение спама.
Классификация
Области применения алгоритмов классификации
Оценка кредитоспособности заемщиков.
Задачи медицинской диагностики
Оптическое распознавание символов.
Распознавание речи.
Обнаружение спама.
Классификация

Слайд 6Формальное математическое определение
Формальное математическое определение

Слайд 7Формальное математическое определение
Разделяющая гиперплоскость – это гиперплоскость, которая отделяет группы объектов, принадлежащим
Формальное математическое определение
Разделяющая гиперплоскость – это гиперплоскость, которая отделяет группы объектов, принадлежащим

Слайд 8Формальное математическое определение
Формальное математическое определение
Слайд 9Формальное математическое определение
Формальное математическое определение

Слайд 10Несбалансированная классификация
Imbalanced Data : один из классов представлен значительно бо́льшим количеством объектов,
Несбалансированная классификация
Imbalanced Data : один из классов представлен значительно бо́льшим количеством объектов,

Слайд 11Несбалансированная классификация
Задачи, в которых несбалансированность данных не просто общая проблема, а ожидаема
Несбалансированная классификация
Задачи, в которых несбалансированность данных не просто общая проблема, а ожидаема

Слайд 12Несбалансированная классификация
Обучение на несбалансированных данных осложняется расположением отдельных примеров выборок:
Вкрапления
Наложения
s – чистые
Несбалансированная классификация
Обучение на несбалансированных данных осложняется расположением отдельных примеров выборок:
Вкрапления
Наложения
s – чистые

Слайд 13Несбалансированная классификация
Основные подходы к решению проблемы несбалансированных данных в классификации:
Сэмплинг (sampling)
Уменьшение большего
Несбалансированная классификация
Основные подходы к решению проблемы несбалансированных данных в классификации:
Сэмплинг (sampling)
Уменьшение большего

Слайд 14Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Случайный или синтетический выбор прецедентов мажоритарного класса в
Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Случайный или синтетический выбор прецедентов мажоритарного класса в

Слайд 15Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Поиск связей Томека (Tomek Links)
Этот способ хорошо удаляет
Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Поиск связей Томека (Tomek Links)
Этот способ хорошо удаляет

Слайд 16Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Правило сосредоточенного ближайшего соседа
(Condensed Nearest Neighbor Rule)
Этот
Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Правило сосредоточенного ближайшего соседа
(Condensed Nearest Neighbor Rule)
Этот

Слайд 17Несбалансированная классификация
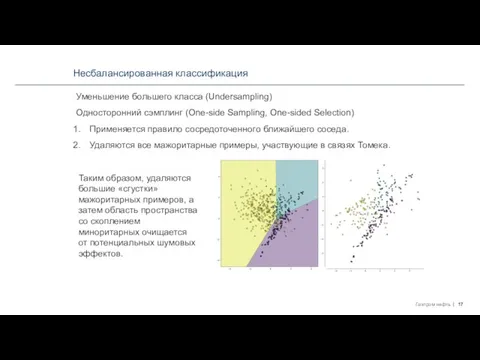
Уменьшение большего класса (Undersampling)
Односторонний сэмплинг (One-side Sampling, One-sided Selection)
Применяется правило сосредоточенного
Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Односторонний сэмплинг (One-side Sampling, One-sided Selection)
Применяется правило сосредоточенного
Слайд 18Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Правило «очищающего» соседа (Neighborhood Cleaning Rule)
Все примеры классифицируются
Несбалансированная классификация
Уменьшение большего класса (Undersampling)
Правило «очищающего» соседа (Neighborhood Cleaning Rule)
Все примеры классифицируются

Слайд 19Несбалансированная классификация
Увеличение меньшего класса (Oversampling)
Добавление прецедентов миноритарного класса позволяет сохранить всю имеющуюся
Несбалансированная классификация
Увеличение меньшего класса (Oversampling)
Добавление прецедентов миноритарного класса позволяет сохранить всю имеющуюся

Слайд 20Несбалансированная классификация
Увеличение меньшего класса (Oversampling)
Алгоритм SMOTE (Synthetic Minority Oversampling Technique) - генерация
Несбалансированная классификация
Увеличение меньшего класса (Oversampling)
Алгоритм SMOTE (Synthetic Minority Oversampling Technique) - генерация

Слайд 21Несбалансированная классификация
Увеличение меньшего класса (Oversampling)
Алгоритм ADASYN (Adaptive Synthetic Minority Oversampling) - использование
Несбалансированная классификация
Увеличение меньшего класса (Oversampling)
Алгоритм ADASYN (Adaptive Synthetic Minority Oversampling) - использование

Слайд 22Несбалансированная классификация
Изменение порога решения (Changing Performance Metric)
Многие алгоритмы классификации определяют степень достоверности
Несбалансированная классификация
Изменение порога решения (Changing Performance Metric)
Многие алгоритмы классификации определяют степень достоверности

Слайд 23Критерии качества классификации
Определим ROC-кривую (receiver operating characteristic, рабочая характеристика приёмника)
Ось абсцисс: доля
Критерии качества классификации
Определим ROC-кривую (receiver operating characteristic, рабочая характеристика приёмника)
Ось абсцисс: доля

Слайд 24Критерии качества классификации
Точность и полнота (Precision and Recall) для случая бинарной классификации
TP
Критерии качества классификации
Точность и полнота (Precision and Recall) для случая бинарной классификации
TP

Слайд 25Критерии качества классификации
Критерии качества классификации

 Инфляция. Причины и формы проявления
Инфляция. Причины и формы проявления Экономика и экономическая наука
Экономика и экономическая наука Бизнес-план
Бизнес-план Виды инфляции Подготовила Волчкова Алиса Группа МЭ092
Виды инфляции Подготовила Волчкова Алиса Группа МЭ092 Экстенсивный и интенсивный варианты экономического развития. Влияние природных факторов
Экстенсивный и интенсивный варианты экономического развития. Влияние природных факторов Тренажёр для отработки задания по теме Статистика
Тренажёр для отработки задания по теме Статистика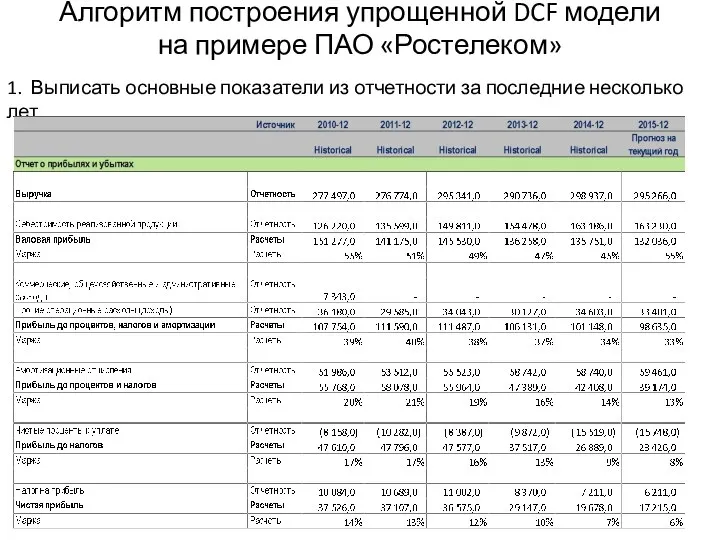 Алгоритм построения упрощенной DCF модели на примере ПАО Ростелеком
Алгоритм построения упрощенной DCF модели на примере ПАО Ростелеком Модель взаимодействия экономических и социальных переменных Г. Мюрдаля
Модель взаимодействия экономических и социальных переменных Г. Мюрдаля Преимущества и трудности управления персоналом в холдинговых компаниях
Преимущества и трудности управления персоналом в холдинговых компаниях Глобальное экономическое регулирование. Практическое занятие
Глобальное экономическое регулирование. Практическое занятие Виды анализа и его информационное обеспечение. (Тема 3)
Виды анализа и его информационное обеспечение. (Тема 3) Экономика. Роль экономики в жизни общества. Участники экономических отношений
Экономика. Роль экономики в жизни общества. Участники экономических отношений Меценаты России
Меценаты России Китай
Китай Основные этапы формирования современной экономической теории
Основные этапы формирования современной экономической теории Издержки производства
Издержки производства Товарная биржа
Товарная биржа Какие бывают потребности. 6 класс
Какие бывают потребности. 6 класс Экономическое планирование предприятия
Экономическое планирование предприятия Теоретическая база
Теоретическая база Инфляция
Инфляция Экономия и рациональное использование воды
Экономия и рациональное использование воды Предмет и методы экономической науки. Основные принципы экономики
Предмет и методы экономической науки. Основные принципы экономики Биржевая торговля зерновыми фьючерсами
Биржевая торговля зерновыми фьючерсами Цифровая экономика
Цифровая экономика Рынок труда
Рынок труда Комп'ютери. Види комп'ютерів
Комп'ютери. Види комп'ютерів Что изучает курс Обществознание в 11 классе. Роль экономики в жизни общества
Что изучает курс Обществознание в 11 классе. Роль экономики в жизни общества