- 1666607538405__u5jj0u

Содержание
- 2. Сжатие информации Сжатие данных – сокращение объема данных при сохранении закодированного в них содержания.
- 3. Сжатие информации Сжатие происходит за счет устранения избыточности кода, например, за счет упрощения кодов, исключения из
- 4. Алгоритмы сжатия 1. Равномерное сжатие с использованием кодов одной длины. Этот метод используется, если в записи
- 5. Сжатие с использованием кодов переменной длины В этом случае возникает проблема отделения кодов символов друг от
- 6. Префиксные коды Чтобы понять, как строятся префиксные коды, рассмотрим, как построить ориентированный граф, определяющий этот код.
- 7. Префиксные коды Построим граф этого кода. Из начальной вершины выходят две дуги, помеченные 0 и 1.
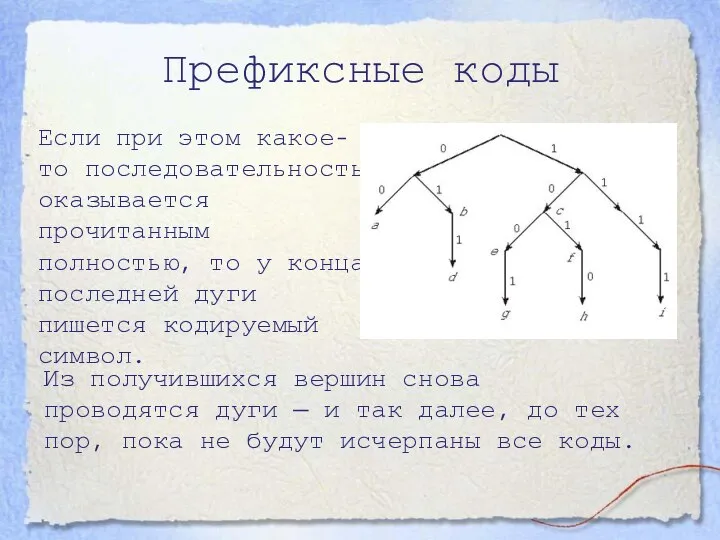
- 8. Префиксные коды Если при этом какое-то последовательность оказывается прочитанным полностью, то у конца последней дуги пишется
- 9. Префиксные коды Если известен граф, созданный по префиксному коду, то по этому графу легко восстанавливается код
- 10. Алгоритм Хаффмана Алгоритм Хаффмана — адаптивный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан
- 11. 1. Символы исходного алфавита образуют вершины. Вес каждой вершины вес равен количеству вхождений данного символа в
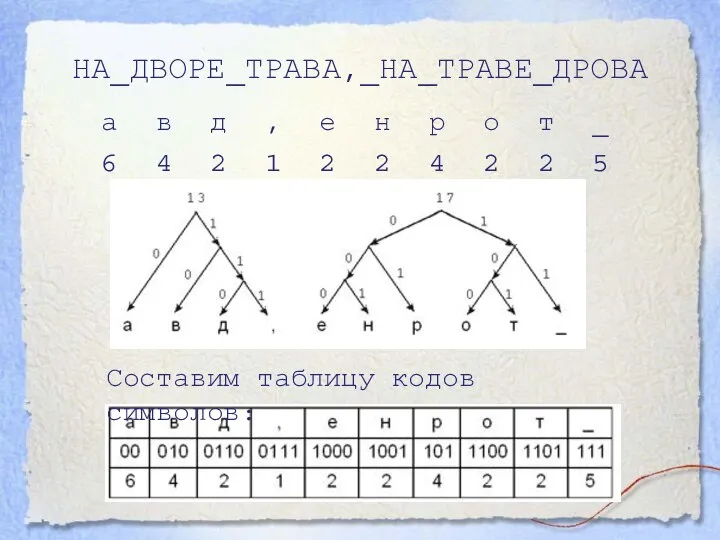
- 12. НА_ДВОРЕ_ТРАВА,_НА_ТРАВЕ_ДРОВА Составим таблицу кодов символов:
- 13. Найдем объем сообщения после кодирования кодом Хаффмана: 2·6 + 3·4 + 4·2 + 4·1 + 4·2
- 14. Математики доказали, что среди алгоритмов, кодирующих каждый символ по отдельности и целым количеством бит, алгоритм Хаффмана
- 17. Практическая работа Алгоритм Хаффмана Цель: закрепить знания о сжатии текстовой информации с помощью алгоритма Хаффмана. Ход
- 19. Скачать презентацию
Слайд 2Сжатие информации
Сжатие данных – сокращение объема данных при сохранении закодированного в них
Сжатие информации
Сжатие данных – сокращение объема данных при сохранении закодированного в них

Слайд 3Сжатие информации
Сжатие происходит за счет устранения избыточности кода, например, за счет упрощения
Сжатие информации
Сжатие происходит за счет устранения избыточности кода, например, за счет упрощения

Слайд 4Алгоритмы сжатия
1. Равномерное сжатие с использованием кодов одной длины.
Этот метод используется, если
Алгоритмы сжатия
1. Равномерное сжатие с использованием кодов одной длины.
Этот метод используется, если

Слайд 5Сжатие с использованием кодов переменной длины
В этом случае возникает проблема отделения кодов
Сжатие с использованием кодов переменной длины
В этом случае возникает проблема отделения кодов

Слайд 6Префиксные коды
Чтобы понять, как строятся префиксные коды, рассмотрим, как построить ориентированный граф,
Префиксные коды
Чтобы понять, как строятся префиксные коды, рассмотрим, как построить ориентированный граф,

Слайд 7Префиксные коды
Построим граф этого кода.
Из начальной вершины выходят две дуги, помеченные 0
Префиксные коды
Построим граф этого кода.
Из начальной вершины выходят две дуги, помеченные 0

Слайд 8Префиксные коды
Если при этом какое-то последовательность оказывается прочитанным полностью, то у конца
Префиксные коды
Если при этом какое-то последовательность оказывается прочитанным полностью, то у конца
Слайд 9Префиксные коды
Если известен граф, созданный по префиксному коду, то по этому графу
Префиксные коды
Если известен граф, созданный по префиксному коду, то по этому графу

Слайд 10Алгоритм Хаффмана
Алгоритм Хаффмана — адаптивный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью.
Был разработан 1952 году аспирантом Массачусетского технологического института Дэвидом
Алгоритм Хаффмана
Алгоритм Хаффмана — адаптивный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью.
Был разработан 1952 году аспирантом Массачусетского технологического института Дэвидом

Слайд 111. Символы исходного алфавита образуют вершины. Вес каждой вершины вес равен количеству
1. Символы исходного алфавита образуют вершины. Вес каждой вершины вес равен количеству

Слайд 12НА_ДВОРЕ_ТРАВА,_НА_ТРАВЕ_ДРОВА
Составим таблицу кодов символов:
НА_ДВОРЕ_ТРАВА,_НА_ТРАВЕ_ДРОВА
Составим таблицу кодов символов:
Слайд 13Найдем объем сообщения после кодирования кодом Хаффмана: 2·6 + 3·4 + 4·2
Найдем объем сообщения после кодирования кодом Хаффмана: 2·6 + 3·4 + 4·2

Слайд 14Математики доказали, что среди алгоритмов, кодирующих каждый символ по отдельности и целым
Математики доказали, что среди алгоритмов, кодирующих каждый символ по отдельности и целым



Слайд 17Практическая работа
Алгоритм Хаффмана
Цель: закрепить знания о сжатии текстовой информации с помощью алгоритма
Практическая работа
Алгоритм Хаффмана
Цель: закрепить знания о сжатии текстовой информации с помощью алгоритма

 Программное обеспечение компьютера
Программное обеспечение компьютера Кодирование информации
Кодирование информации ProPowerPoint.Ru
ProPowerPoint.Ru Маски выделения. Photoshop
Маски выделения. Photoshop Виртуальная реальность
Виртуальная реальность Виды тестирования. Лекция 5
Виды тестирования. Лекция 5 Составление и выполнение алгоритмов чертёжника
Составление и выполнение алгоритмов чертёжника Устройства внешней памяти
Устройства внешней памяти Линии связи с использованием искусственных спутников Земли
Линии связи с использованием искусственных спутников Земли DNS
DNS 02_ООП_практика
02_ООП_практика Модульное тестирование ( unit testing)
Модульное тестирование ( unit testing) Основы языка гипертекстовой разметки документа HTML
Основы языка гипертекстовой разметки документа HTML Материалы к выпускной письменной экзаменационной работе по теме Сравнение способов создания таблиц в MS Word MS Excel
Материалы к выпускной письменной экзаменационной работе по теме Сравнение способов создания таблиц в MS Word MS Excel Киберспорт
Киберспорт Что такое массив?
Что такое массив? Удмуртская клавиатура для компьютера и смартфона
Удмуртская клавиатура для компьютера и смартфона Комплексное тестирование и анкетирование
Комплексное тестирование и анкетирование Создание видеоролика
Создание видеоролика Цели информатизации образования
Цели информатизации образования лекция 5
лекция 5 Новсти мира
Новсти мира Презентация смайликов
Презентация смайликов Прогнозирование развития фондов муниципальных библиотек
Прогнозирование развития фондов муниципальных библиотек Техніка безпеки при роботі з комп'ютером і правила поведінки у комп'ютерному класі
Техніка безпеки при роботі з комп'ютером і правила поведінки у комп'ютерному класі Поисковое продвижение сайтов
Поисковое продвижение сайтов Рисуем снежинку. Занятие по программе Paint
Рисуем снежинку. Занятие по программе Paint Информация. Информационные процессы
Информация. Информационные процессы