- 17 протокол маршрутизации

Содержание
- 2. Наиболее простым способом передачи пакетов по сети является так называемая лавинная маршрутизация, когда каждый маршрутизатор передает
- 3. В протоколах маршрутизации чаще всего маршрут выбирается по критерию кратчайшего расстояния. При этом расстояние измеряется в
- 4. Различают протоколы, выполняющие статическую и адаптивную (динамическую) маршрутизацию. При статической маршрутизации все записи в таблице имеют
- 5. При адаптивной маршрутизации все изменения конфигурации сети автоматически отражаются в таблицах маршрутизации благодаря протоколам маршрутизации. В
- 6. Протоколы адаптивной маршрутизации бывают распределенными и централизованными. Применяемые сегодня в IP-сетях протоколы маршрутизации относятся к адаптивным
- 7. При централизованном подходе в сети существует один выделенный маршрутизатор, который собирает всю информацию о топологии и
- 8. В дистанционно-векторных алгоритмах (DVA) каждый маршрутизатор периодически и широковещательно рассылает по сети вектор, компонентами которого являются
- 9. Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях. В больших сетях они периодически засоряют линии связи
- 10. Алгоритмы состояния связей (LSA) обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Каждый
- 11. Протокол RIP Протокол RIP (Routing Information Protocol — протокол маршрутной информации) является внутренним протоколом маршрутизации дистанционно-векторного
- 12. Построение таблицы маршрутизации Для измерения расстояния до сети стандарты протокола RIP допускают различные виды метрик: хопы,
- 13. Этап 1 — создание минимальной таблицы.
- 15. Этап 2 — рассылка минимальной таблицы соседям. По отношению к любому маршрутизатору соседями являются те маршрутизаторы,
- 16. Этап 3 — получение RIP-сообщений от соседей и обработка полученной информации. Записи с четвертой по девятую
- 17. Этап 4 — рассылка новой таблицы соседям. Каждый маршрутизатор отсылает новое RIP- сообщение всем своим соседям.
- 18. Этап 5 — получение RIP-сообщений от соседей и обработка полученной информации. Этап 5 повторяет этап 3
- 19. Адаптация маршрутизаторов RIP к изменениям состояния сети К новым маршрутам маршрутизаторы RIP приспосабливаются просто — они
- 20. Механизм истечения времени жизни маршрута основан на том, что каждая запись таблицы маршрутизации, полученная по протоколу
- 21. Когда же сообщение послать можно, маршрутизаторы RIP используют прием, заключающийся в указании бесконечного расстояния до сети,
- 22. Протокол OSPF Протокол OSPF (Open Shortest Path First — выбор кратчайшего пути первым) является последним протоколом,
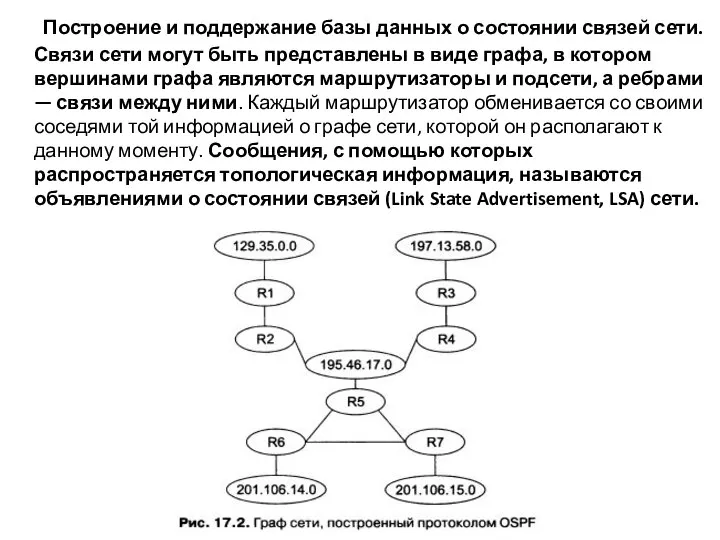
- 23. Построение и поддержание базы данных о состоянии связей сети. Связи сети могут быть представлены в виде
- 24. Нахождение оптимальных маршрутов и генерация таблицы маршрутизации. Задача нахождения оптимального пути на графе является достаточно сложной
- 25. Если состояние связей в сети изменилось и произошла корректировка графа сети, каждый маршрутизатор заново ищет оптимальные
- 26. Метрики При поиске оптимальных маршрутов протокол OSPF по умолчанию использует метрику, учитывающую пропускную способность каналов связи.
- 27. Для преодоления вычислительной сложности с ростом сети в протоколе OSPF вводится понятие области сети. Маршрутизаторы, принадлежащие
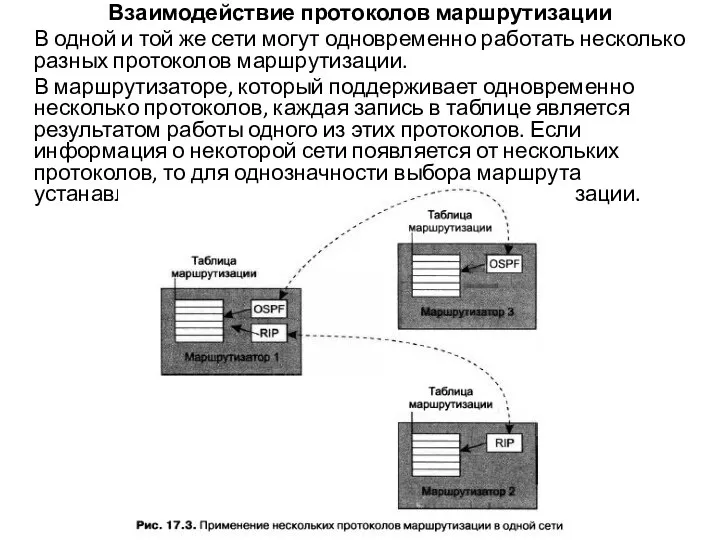
- 28. Взаимодействие протоколов маршрутизации В одной и той же сети могут одновременно работать несколько разных протоколов маршрутизации.
- 29. По умолчанию каждый протокол маршрутизации, работающий на определенном маршрутизаторе, распространяет только «собственную» информацию, то есть ту
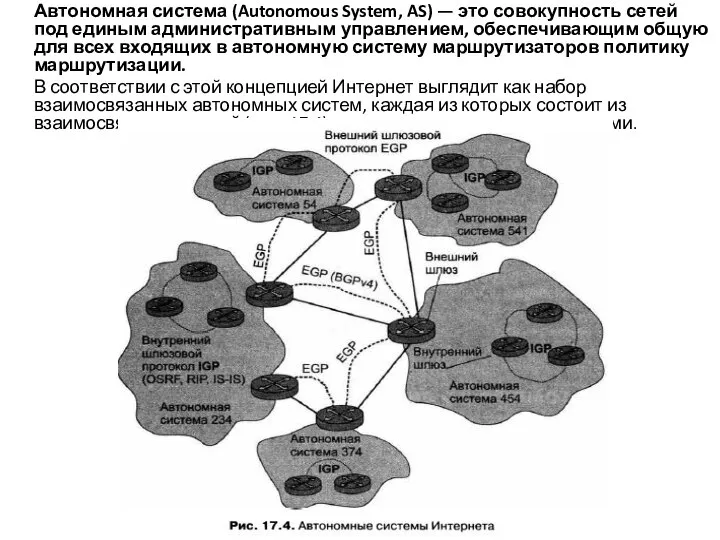
- 30. Автономная система (Autonomous System, AS) — это совокупность сетей под единым административным управлением, обеспечивающим общую для
- 31. Основная цель деления Интернета на автономные системы — обеспечение многоуровневого подхода к маршрутизации. С появлением автономных
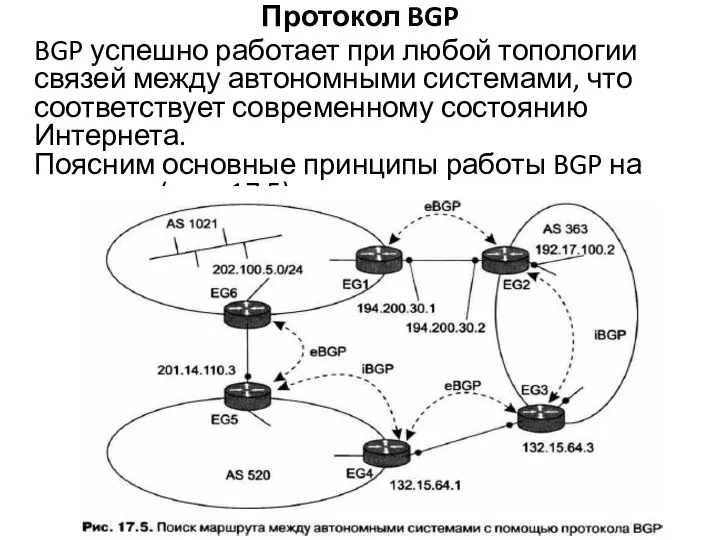
- 32. Протокол BGP BGP успешно работает при любой топологии связей между автономными системами, что соответствует современному состоянию
- 33. Такой способ взаимодействия удобен в ситуации, когда маршрутизаторы, обменивающиеся маршрутной информацией, принадлежат разным поставщикам услуг (ISP).
- 34. Стандартная модель группового вещания IP Основной целью группового вещания является создание эффективного механизма передачи данных от
- 35. При широковещательной рассылке (broadcast) станция направляет пакеты, используя широковещательные адреса.В этой схеме для того, чтобы доставить
- 36. В случае привлечения сервисов прикладного уровня функции по обеспечению групповой доставки перекладываются на самих членов группы.
- 37. Главная идея группового вещания состоит в следующем: источник генерирует только один экземпляр сообщения с групповым адресом,
- 38. Пакет с групповым адресом достигает маршрутизатора, к которому непосредственно подключена сеть с хостами — членами данной
- 39. Есть несколько принципиальных положений, регламентирующих поведение конечных узлов сети, которые являются источниками и получателями группового трафика.
- 40. Адреса группового вещания Ранее в главе 14, изучая типы IP-адресов, мы отмечали, что адреса IPv4 из
- 41. Протокол IGMP К основным функциям протокола IGMP относятся оповещение маршрутизатора о желании хоста быть включенным в
- 42. В IGMPv2 определено три типа сообщений: Запрос о членстве (membership query). С помощью этого сообщения маршрутизатор
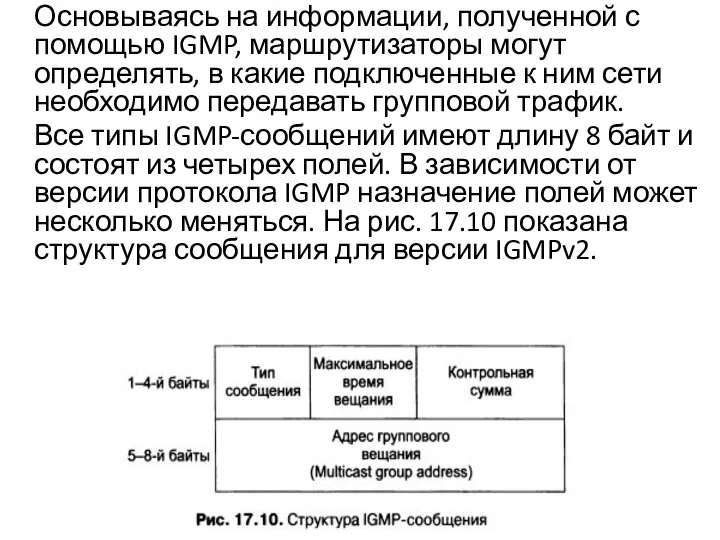
- 43. Основываясь на информации, полученной с помощью IGMP, маршрутизаторы могут определять, в какие подключенные к ним сети
- 44. Принципы маршрутизации трафика группового вещания Среди принципов маршрутизации трафика группового вещания можно отметить: маршрутизацию на основе
- 45. Учет плотности получателей группового трафика. Внутридоменные протоколы маршрутизации разделяются на два принципиально отличных класса: Протоколы плотного
- 46. Два подхода к построению маршрутного дерева. Все протоколы маршрутизации группового вещания используют один из следующих двух
- 47. Концепция продвижения по реверсивному пути. Маршрутизатор проверяет, является ли входной интерфейс, получивший групповой пакет, интерфейсом, через
- 48. Протоколы маршрутизации группового вещания Протоколы маршрутизации осуществляют постоянный мониторинг покрывающего дерева и время от времени отсекают
- 49. Протокол PIM-SM является одной из двух версий протокола PIM (Protocol Independent Multicast): версии плотного режима PIM-DM
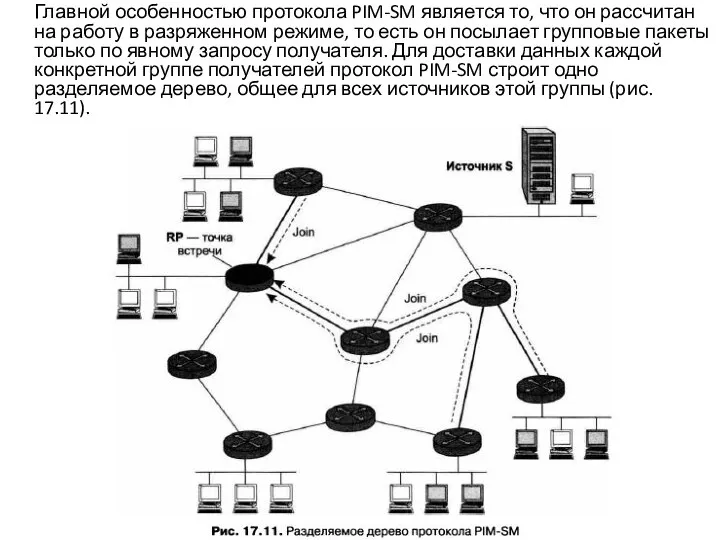
- 50. Главной особенностью протокола PIM-SM является то, что он рассчитан на работу в разряженном режиме, то есть
- 51. Вершина разделяемого дерева не может располагаться в источнике, так как источников может быть несколько. В качестве
- 52. Поддержка QoS в машрутизаторах Были разработаны две системы стандартов QoS для IP-сетей: система интегрированного обслуживания (Integrated
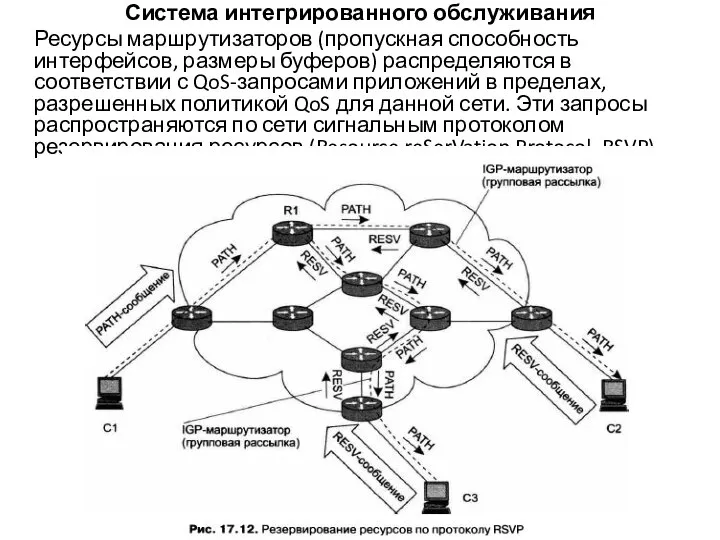
- 53. Система интегрированного обслуживания Ресурсы маршрутизаторов (пропускная способность интерфейсов, размеры буферов) распределяются в соответствии с QoS-запросами приложений
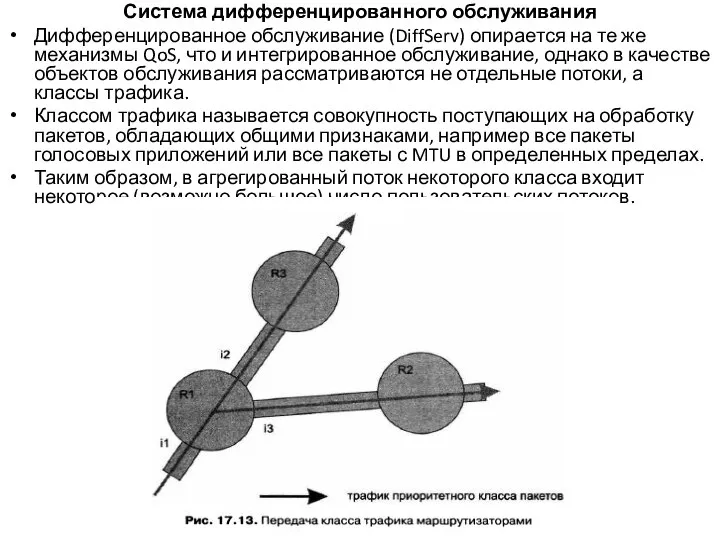
- 54. Система дифференцированного обслуживания Дифференцированное обслуживание (DiffServ) опирается на те же механизмы QoS, что и интегрированное обслуживание,
- 57. Скачать презентацию
Слайд 2 Наиболее простым способом передачи пакетов по сети является так называемая лавинная маршрутизация,
Наиболее простым способом передачи пакетов по сети является так называемая лавинная маршрутизация,

Слайд 3 В протоколах маршрутизации чаще всего маршрут выбирается по критерию кратчайшего расстояния. При
В протоколах маршрутизации чаще всего маршрут выбирается по критерию кратчайшего расстояния. При

Слайд 4 Различают протоколы, выполняющие статическую и адаптивную (динамическую) маршрутизацию.
При статической маршрутизации все записи
Различают протоколы, выполняющие статическую и адаптивную (динамическую) маршрутизацию.
При статической маршрутизации все записи

Слайд 5 При адаптивной маршрутизации все изменения конфигурации сети автоматически отражаются в таблицах маршрутизации
При адаптивной маршрутизации все изменения конфигурации сети автоматически отражаются в таблицах маршрутизации

Слайд 6 Протоколы адаптивной маршрутизации бывают распределенными и централизованными.
Применяемые сегодня в IP-сетях протоколы маршрутизации
Протоколы адаптивной маршрутизации бывают распределенными и централизованными.
Применяемые сегодня в IP-сетях протоколы маршрутизации

Слайд 7 При централизованном подходе в сети существует один выделенный маршрутизатор, который собирает всю
При централизованном подходе в сети существует один выделенный маршрутизатор, который собирает всю

Слайд 8 В дистанционно-векторных алгоритмах (DVA) каждый маршрутизатор периодически и широковещательно рассылает по сети
В дистанционно-векторных алгоритмах (DVA) каждый маршрутизатор периодически и широковещательно рассылает по сети

Слайд 9 Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях. В больших сетях они
Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях. В больших сетях они

Слайд 10 Алгоритмы состояния связей (LSA) обеспечивают каждый маршрутизатор информацией, достаточной для построения точного
Алгоритмы состояния связей (LSA) обеспечивают каждый маршрутизатор информацией, достаточной для построения точного

Слайд 11Протокол RIP
Протокол RIP (Routing Information Protocol — протокол маршрутной информации) является внутренним
Протокол RIP
Протокол RIP (Routing Information Protocol — протокол маршрутной информации) является внутренним

Слайд 12Построение таблицы маршрутизации
Для измерения расстояния до сети стандарты протокола RIP допускают различные
Построение таблицы маршрутизации
Для измерения расстояния до сети стандарты протокола RIP допускают различные

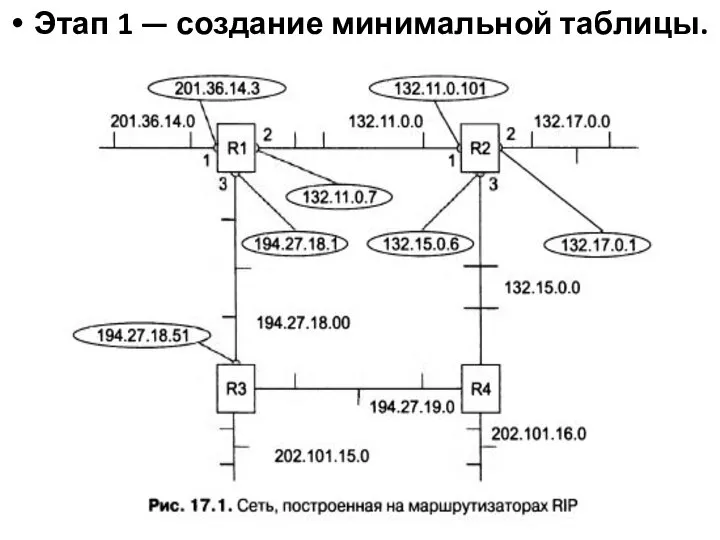
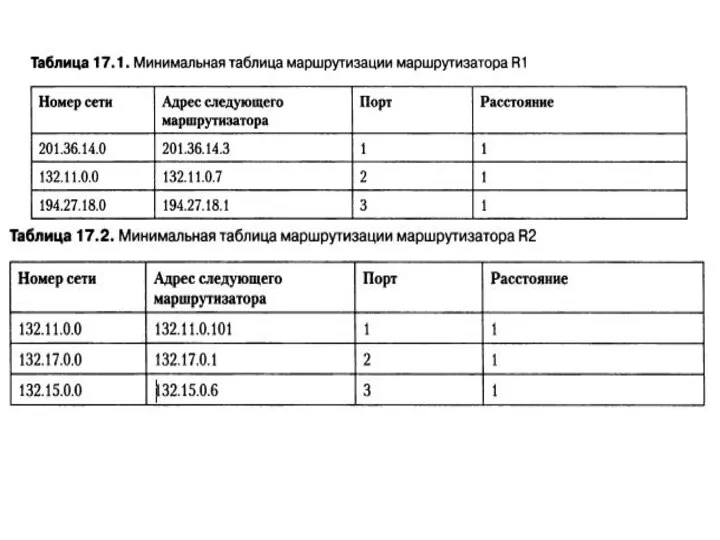
Слайд 13Этап 1 — создание минимальной таблицы.
Этап 1 — создание минимальной таблицы.
Слайд 15Этап 2 — рассылка минимальной таблицы соседям.
По отношению к любому маршрутизатору
Этап 2 — рассылка минимальной таблицы соседям.
По отношению к любому маршрутизатору

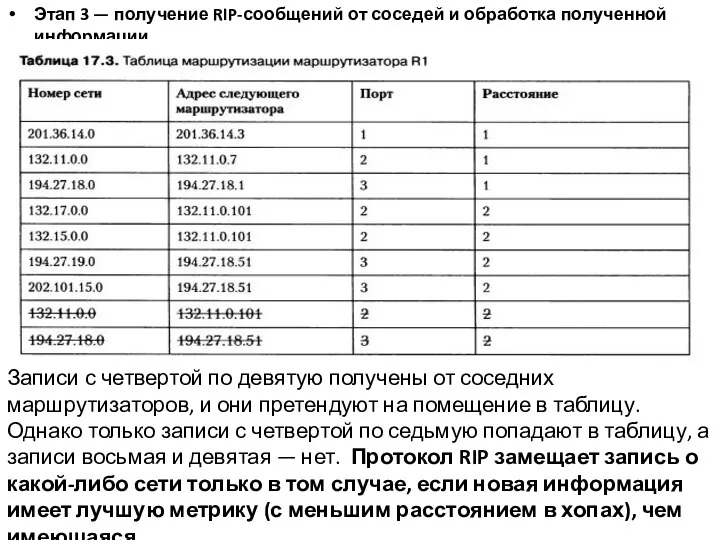
Слайд 16Этап 3 — получение RIP-сообщений от соседей и обработка полученной информации.
Записи
Этап 3 — получение RIP-сообщений от соседей и обработка полученной информации.
Записи
Слайд 17Этап 4 — рассылка новой таблицы соседям.
Каждый маршрутизатор отсылает новое RIP-
Этап 4 — рассылка новой таблицы соседям.
Каждый маршрутизатор отсылает новое RIP-

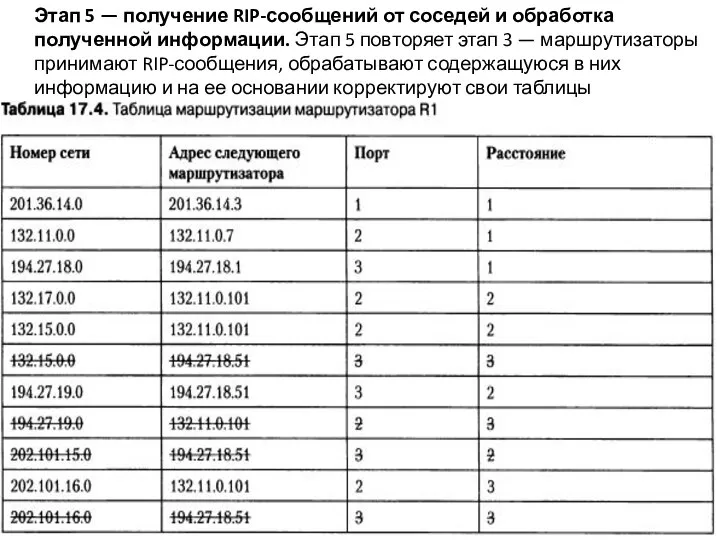
Слайд 18 Этап 5 — получение RIP-сообщений от соседей и обработка полученной информации. Этап
Этап 5 — получение RIP-сообщений от соседей и обработка полученной информации. Этап
Слайд 19Адаптация маршрутизаторов RIP к изменениям состояния сети
К новым маршрутам маршрутизаторы RIP приспосабливаются
Адаптация маршрутизаторов RIP к изменениям состояния сети
К новым маршрутам маршрутизаторы RIP приспосабливаются

Слайд 20 Механизм истечения времени жизни маршрута основан на том, что каждая запись таблицы
Механизм истечения времени жизни маршрута основан на том, что каждая запись таблицы

Слайд 21 Когда же сообщение послать можно, маршрутизаторы RIP используют прием, заключающийся в указании
Когда же сообщение послать можно, маршрутизаторы RIP используют прием, заключающийся в указании

Слайд 22Протокол OSPF
Протокол OSPF (Open Shortest Path First — выбор кратчайшего пути первым)
Протокол OSPF
Протокол OSPF (Open Shortest Path First — выбор кратчайшего пути первым)

Слайд 23 Построение и поддержание базы данных о состоянии связей сети.
Связи сети могут
Построение и поддержание базы данных о состоянии связей сети.
Связи сети могут
Слайд 24 Нахождение оптимальных маршрутов и генерация таблицы маршрутизации.
Задача нахождения оптимального пути на
Нахождение оптимальных маршрутов и генерация таблицы маршрутизации.
Задача нахождения оптимального пути на

Слайд 25 Если состояние связей в сети изменилось и произошла корректировка графа сети, каждый
Если состояние связей в сети изменилось и произошла корректировка графа сети, каждый

Слайд 26Метрики
При поиске оптимальных маршрутов протокол OSPF по умолчанию использует метрику, учитывающую пропускную
Метрики
При поиске оптимальных маршрутов протокол OSPF по умолчанию использует метрику, учитывающую пропускную

Слайд 27
Для преодоления вычислительной сложности с ростом сети в протоколе OSPF вводится понятие
Для преодоления вычислительной сложности с ростом сети в протоколе OSPF вводится понятие

Слайд 28Взаимодействие протоколов маршрутизации
В одной и той же сети могут одновременно работать несколько
Взаимодействие протоколов маршрутизации
В одной и той же сети могут одновременно работать несколько
Слайд 29 По умолчанию каждый протокол маршрутизации, работающий на определенном маршрутизаторе, распространяет только «собственную»
По умолчанию каждый протокол маршрутизации, работающий на определенном маршрутизаторе, распространяет только «собственную»

Слайд 30 Автономная система (Autonomous System, AS) — это совокупность сетей под единым административным
Автономная система (Autonomous System, AS) — это совокупность сетей под единым административным
Слайд 31 Основная цель деления Интернета на автономные системы — обеспечение многоуровневого подхода к
Основная цель деления Интернета на автономные системы — обеспечение многоуровневого подхода к

Слайд 32Протокол BGP
BGP успешно работает при любой топологии связей между автономными системами, что
Протокол BGP
BGP успешно работает при любой топологии связей между автономными системами, что
Слайд 33 Такой способ взаимодействия удобен в ситуации, когда маршрутизаторы, обменивающиеся маршрутной информацией, принадлежат
Такой способ взаимодействия удобен в ситуации, когда маршрутизаторы, обменивающиеся маршрутной информацией, принадлежат

Слайд 34Стандартная модель группового вещания IP
Основной целью группового вещания является создание эффективного механизма
Стандартная модель группового вещания IP
Основной целью группового вещания является создание эффективного механизма
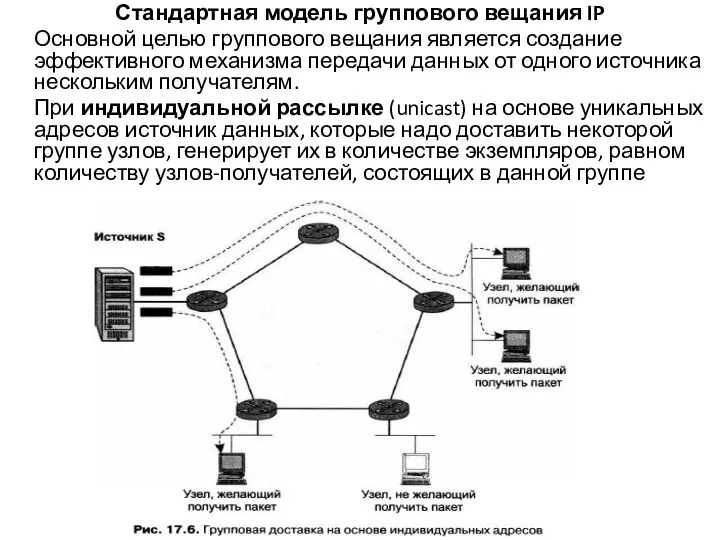
Слайд 35 При широковещательной рассылке (broadcast) станция направляет пакеты, используя широковещательные адреса.В этой схеме
При широковещательной рассылке (broadcast) станция направляет пакеты, используя широковещательные адреса.В этой схеме
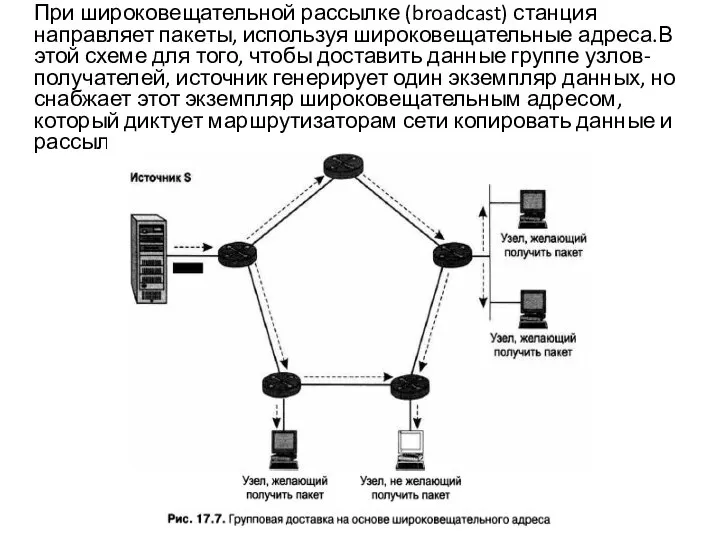
Слайд 36 В случае привлечения сервисов прикладного уровня функции по обеспечению групповой доставки перекладываются
В случае привлечения сервисов прикладного уровня функции по обеспечению групповой доставки перекладываются
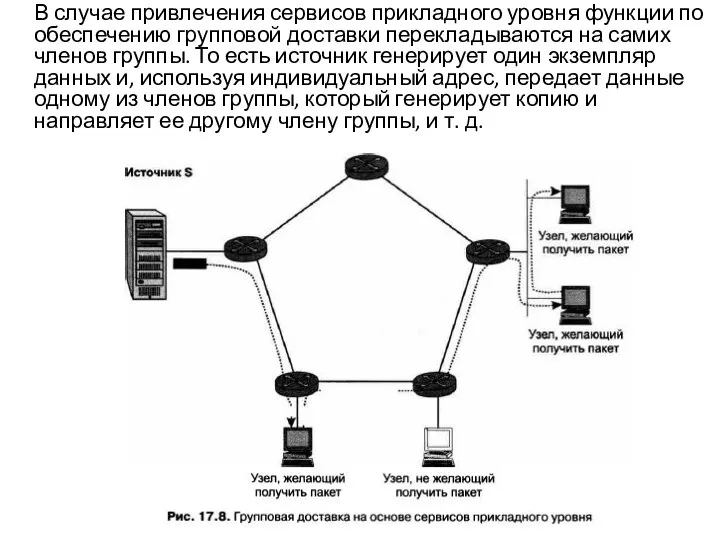
Слайд 37 Главная идея группового вещания состоит в следующем: источник генерирует только один экземпляр
Главная идея группового вещания состоит в следующем: источник генерирует только один экземпляр
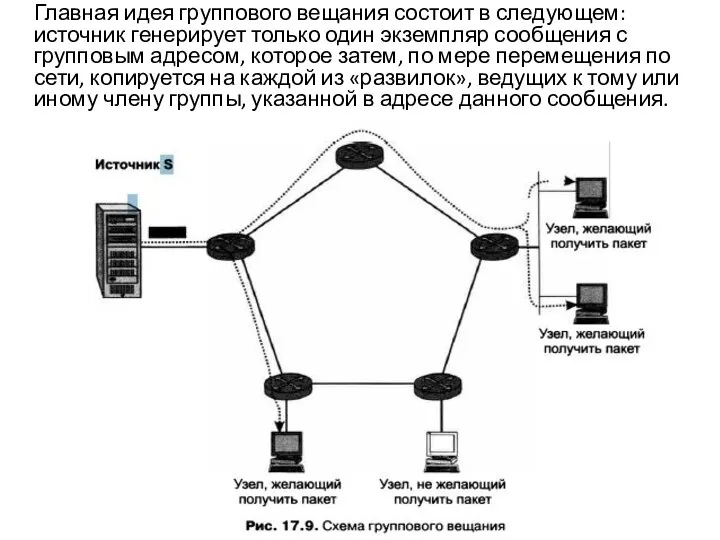
Слайд 38 Пакет с групповым адресом достигает маршрутизатора, к которому непосредственно подключена сеть с
Пакет с групповым адресом достигает маршрутизатора, к которому непосредственно подключена сеть с

Слайд 39 Есть несколько принципиальных положений, регламентирующих поведение конечных узлов сети, которые являются источниками
Есть несколько принципиальных положений, регламентирующих поведение конечных узлов сети, которые являются источниками

Слайд 40Адреса группового вещания
Ранее в главе 14, изучая типы IP-адресов, мы отмечали, что
Адреса группового вещания
Ранее в главе 14, изучая типы IP-адресов, мы отмечали, что

Слайд 41Протокол IGMP
К основным функциям протокола IGMP относятся оповещение маршрутизатора о желании хоста
Протокол IGMP
К основным функциям протокола IGMP относятся оповещение маршрутизатора о желании хоста

Слайд 42В IGMPv2 определено три типа сообщений:
Запрос о членстве (membership query). С помощью
В IGMPv2 определено три типа сообщений:
Запрос о членстве (membership query). С помощью

Слайд 43 Основываясь на информации, полученной с помощью IGMP, маршрутизаторы могут определять, в какие
Основываясь на информации, полученной с помощью IGMP, маршрутизаторы могут определять, в какие
Слайд 44Принципы маршрутизации трафика группового вещания
Среди принципов маршрутизации трафика группового вещания можно отметить:
маршрутизацию
Принципы маршрутизации трафика группового вещания
Среди принципов маршрутизации трафика группового вещания можно отметить:
маршрутизацию

Слайд 45Учет плотности получателей группового трафика. Внутридоменные протоколы маршрутизации разделяются на два принципиально
Учет плотности получателей группового трафика. Внутридоменные протоколы маршрутизации разделяются на два принципиально

Слайд 46Два подхода к построению маршрутного дерева.
Все протоколы маршрутизации группового вещания используют
Два подхода к построению маршрутного дерева.
Все протоколы маршрутизации группового вещания используют

Слайд 47Концепция продвижения по реверсивному пути.
Маршрутизатор проверяет, является ли входной интерфейс, получивший
Концепция продвижения по реверсивному пути.
Маршрутизатор проверяет, является ли входной интерфейс, получивший

Слайд 48Протоколы маршрутизации группового вещания
Протоколы маршрутизации осуществляют постоянный мониторинг покрывающего дерева и время
Протоколы маршрутизации группового вещания
Протоколы маршрутизации осуществляют постоянный мониторинг покрывающего дерева и время

Слайд 49 Протокол PIM-SM является одной из двух версий протокола PIM (Protocol Independent Multicast):
версии
Протокол PIM-SM является одной из двух версий протокола PIM (Protocol Independent Multicast):
версии

Слайд 50 Главной особенностью протокола PIM-SM является то, что он рассчитан на работу в
Главной особенностью протокола PIM-SM является то, что он рассчитан на работу в
Слайд 51 Вершина разделяемого дерева не может располагаться в источнике, так как источников может
Вершина разделяемого дерева не может располагаться в источнике, так как источников может

Слайд 52Поддержка QoS в машрутизаторах
Были разработаны две системы стандартов QoS для IP-сетей:
система интегрированного
Поддержка QoS в машрутизаторах
Были разработаны две системы стандартов QoS для IP-сетей:
система интегрированного

Слайд 53Система интегрированного обслуживания
Ресурсы маршрутизаторов (пропускная способность интерфейсов, размеры буферов) распределяются в соответствии
Система интегрированного обслуживания
Ресурсы маршрутизаторов (пропускная способность интерфейсов, размеры буферов) распределяются в соответствии
Слайд 54Система дифференцированного обслуживания
Дифференцированное обслуживание (DiffServ) опирается на те же механизмы QoS, что
Система дифференцированного обслуживания
Дифференцированное обслуживание (DiffServ) опирается на те же механизмы QoS, что

 Презентация на тему Программная оболочка Norton Commander
Презентация на тему Программная оболочка Norton Commander  Языки для записи алгоритмов
Языки для записи алгоритмов Условия в алгоритмах. Простые и составные условия. Логические операции в условиях
Условия в алгоритмах. Простые и составные условия. Логические операции в условиях Подача заявления для участия в программе на портале Работа в России
Подача заявления для участия в программе на портале Работа в России Дооп ШкоДа
Дооп ШкоДа Lorem ipsum. Presentation Template
Lorem ipsum. Presentation Template ИК Базы данных. Урок 6. Презентация
ИК Базы данных. Урок 6. Презентация Мемы 2020-го года
Мемы 2020-го года Обзор систем электронный офис
Обзор систем электронный офис Решение логической задачи соки. Рабочая тетрадь №41 стр.36
Решение логической задачи соки. Рабочая тетрадь №41 стр.36 Среда программирования OpenMP. (Лекция 1)
Среда программирования OpenMP. (Лекция 1) Как записаться на онлайн-курсы на платформе Электронная информационно-образовательная среда НИИ КПССЗ
Как записаться на онлайн-курсы на платформе Электронная информационно-образовательная среда НИИ КПССЗ Решение задачи оптимального планирования с применением электронных таблиц
Решение задачи оптимального планирования с применением электронных таблиц Дифференцирующие возможности современных ELT-платформ
Дифференцирующие возможности современных ELT-платформ Компьютерная графика. 8 класс
Компьютерная графика. 8 класс МОФР - практика. Решение всех задач
МОФР - практика. Решение всех задач Parallel от TaxiTime. Аналитика для увеличения прибыли автопарков
Parallel от TaxiTime. Аналитика для увеличения прибыли автопарков Разработка Python-приложения для построения графиков математических функций
Разработка Python-приложения для построения графиков математических функций Устройство компьютера
Устройство компьютера Решение задач на составление разветвляющихся алгоритмов
Решение задач на составление разветвляющихся алгоритмов Средства и методы защиты информации. Лекция 3
Средства и методы защиты информации. Лекция 3 Функции вывода сообщений
Функции вывода сообщений Технология разработки программного обеспечения
Технология разработки программного обеспечения Внешние устройства ПК
Внешние устройства ПК Производственная практика на телеканале Хузур-Спокойствие
Производственная практика на телеканале Хузур-Спокойствие Контрольная работа
Контрольная работа Календарь Победы. Главные битвы Великой Отечественной войны
Календарь Победы. Главные битвы Великой Отечественной войны Программирование на языке Python
Программирование на языке Python