- Файл robots.txt

Содержание
- 2. В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже
- 3. В роботе Яндекса используется сессионный принцип работы, на каждую сессию формируется определенный пул страниц, которые планирует
- 4. Директивы Disallow и Allow Чтобы запретить доступ робота к сайту или некоторым его разделам, используйте директиву
- 6. Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
- 8. Использование спецсимволов * и $ При указании путей директив Allow и Disallow можно использовать спецсимволы *
- 9. Директивы Allow и Disallow без параметров Если директивы не содержат параметры, учитывает данные следующим образом:
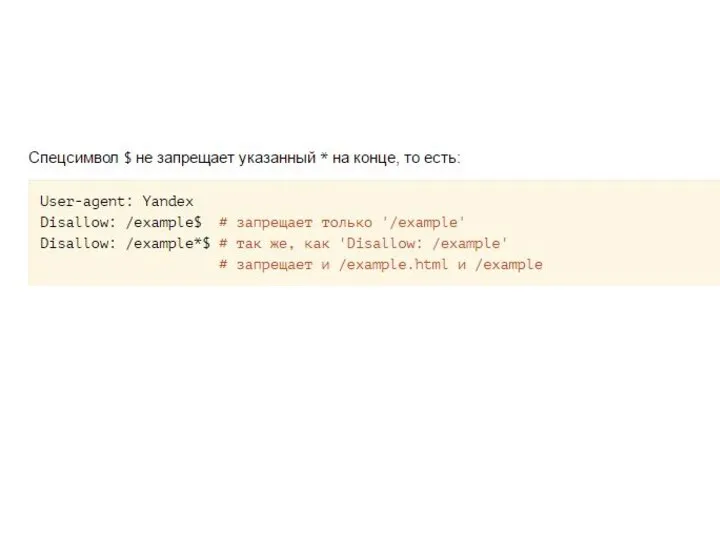
- 10. Использование спецсимволов * и $
- 13. Директива Sitemap
- 14. Директива Host Если у вашего сайта есть зеркала, специальный робот зеркальщик определит их и сформирует группу
- 16. Проверьте ваш файл в вебмастерах google и yandex
- 18. Скачать презентацию

Слайд 3В роботе Яндекса используется сессионный принцип работы, на каждую сессию формируется определенный
В роботе Яндекса используется сессионный принцип работы, на каждую сессию формируется определенный

Слайд 4Директивы Disallow и Allow
Чтобы запретить доступ робота к сайту или некоторым его
Директивы Disallow и Allow
Чтобы запретить доступ робота к сайту или некоторым его


Слайд 6Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow


Слайд 8Использование спецсимволов * и $
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким
Использование спецсимволов * и $
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким

Слайд 9Директивы Allow и Disallow без параметров
Если директивы не содержат параметры, учитывает данные
Директивы Allow и Disallow без параметров Если директивы не содержат параметры, учитывает данные

Слайд 10Использование спецсимволов * и $
Использование спецсимволов * и $


Слайд 13Директива Sitemap
Директива Sitemap

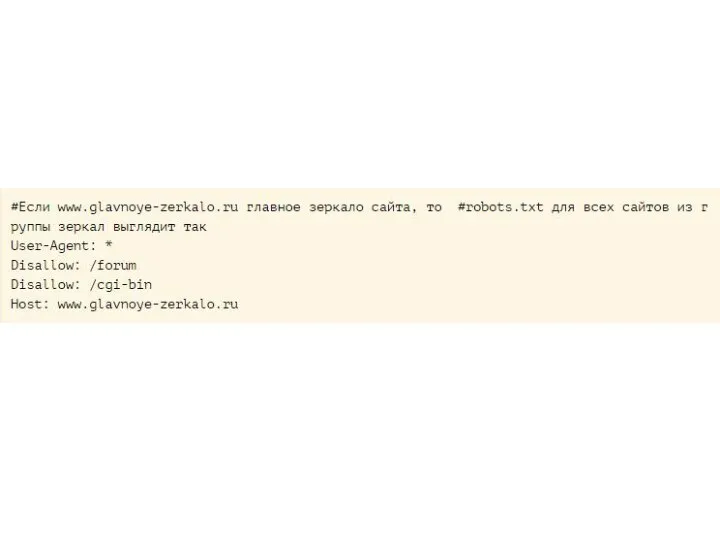
Слайд 14Директива Host
Если у вашего сайта есть зеркала, специальный робот зеркальщик определит их
Директива Host
Если у вашего сайта есть зеркала, специальный робот зеркальщик определит их

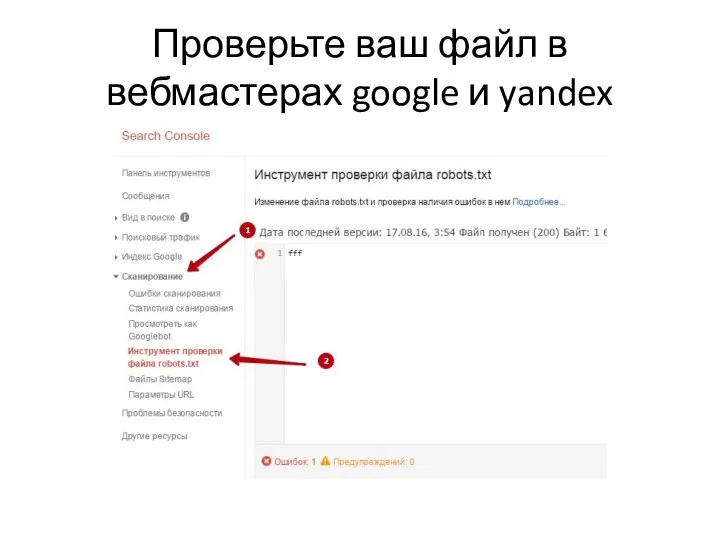
Слайд 16Проверьте ваш файл в вебмастерах google и yandex
Проверьте ваш файл в вебмастерах google и yandex
 Динамічні бібліотеки (DLL)
Динамічні бібліотеки (DLL) Автоматизированное тестирование
Автоматизированное тестирование Элементы алгебры логики. Высказывание. Математические основы информатики
Элементы алгебры логики. Высказывание. Математические основы информатики Метапредметный урок Система – это хаос или порядок? 5 класс
Метапредметный урок Система – это хаос или порядок? 5 класс Тест по устройству ПК
Тест по устройству ПК Реализация кодировщика\декодировщика на основе структуры Машины Тьюринга
Реализация кодировщика\декодировщика на основе структуры Машины Тьюринга Job Hunter
Job Hunter Линейная структура программы
Линейная структура программы PowerPoint. 87 анимированных иконок
PowerPoint. 87 анимированных иконок Латынь в социальных сетях
Латынь в социальных сетях Опыт взаимодействия с Партнерами в области BIM. Лекция 2
Опыт взаимодействия с Партнерами в области BIM. Лекция 2 Python. Пишем свои функции
Python. Пишем свои функции Api сервис ocs или невозможные матрешки
Api сервис ocs или невозможные матрешки Редактирование и форматирование web-текста
Редактирование и форматирование web-текста Вставка и редактирование текста WortArt
Вставка и редактирование текста WortArt Правовые организационные основы защиты информации ограниченного доступа
Правовые организационные основы защиты информации ограниченного доступа OBRABOTKA_INFORMATsII
OBRABOTKA_INFORMATsII How to begin a programmer
How to begin a programmer Введение в SAS Enterprise Guide
Введение в SAS Enterprise Guide TDL – Tests Definition Language
TDL – Tests Definition Language Lektsia_GOST_R_ISO_MEK_12207_Osnovnye_protsessy_i_vzaimosvyaz_mezhdu_dokumentami_v_informatsionnoy_sisteme_soglasno_standartam
Lektsia_GOST_R_ISO_MEK_12207_Osnovnye_protsessy_i_vzaimosvyaz_mezhdu_dokumentami_v_informatsionnoy_sisteme_soglasno_standartam Цикл с переменной
Цикл с переменной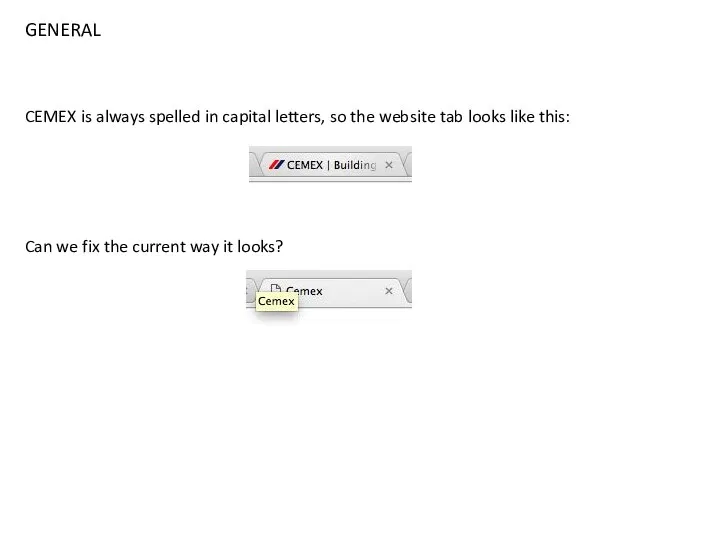 Element list page
Element list page Информация для регистрации на mos.ru
Информация для регистрации на mos.ru 1С:Биллинг. Решение для автоматизации абонентского отдела на предприятиях в сфере услуг
1С:Биллинг. Решение для автоматизации абонентского отдела на предприятиях в сфере услуг Таблицы и картинки в документе Microsoft Word. Урок 9
Таблицы и картинки в документе Microsoft Word. Урок 9 Компьютерные сети
Компьютерные сети Технологическая экосистема ArcGIS. Ресурсы для геокриологов-исследователей
Технологическая экосистема ArcGIS. Ресурсы для геокриологов-исследователей