- Файлы и файловые структуры

Содержание
- 2. Физические модели баз данных определяют способы размещения данных в среде хранения и способы доступа к этим
- 3. В каждой СУБД по-разному организованы хранение и доступ к данным. Существуют файловые структуры, которые имеют общепринятые
- 5. С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях. В файле
- 6. В соответствии с методами управления доступом различают: устройства внешней памяти с произвольной адресацией (магнитные и оптические
- 7. Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа. В
- 8. Каждая файловая система СУФ — система управления файлами поддерживает некоторую иерархическую файловую структуру, включающую чаще всего
- 9. Для каждого файла в системе хранится следующая информация: имя файла; тип файла (например, расширение или другие
- 10. Для файлов с постоянной длиной записи адрес размещения записи с номером K может быть вычислен по
- 11. На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа. Файлы с переменной длиной записи
- 12. Файлы с прямым доступом обеспечивают наиболее быстрый способ доступа. Доступ по номеру записи в базах данных
- 13. При организации файлов прямого доступа в некоторых очень редких случаях возможно построение функции, которая по значению
- 14. Не всегда удается построить взаимно-однозначное соответствие между значениями ключа и номерами записей. Часто бывает, что значения
- 15. Суть методов хэширования состоит в том, что мы берем значения ключа (или некоторые его характеристики) и
- 16. Стратегия разрешения коллизий с областью переполнения Область хранения разбивается на 2 части. Для каждой новой записи
- 17. Если вновь заносимая запись имеет значение функции хэширования такое же, которое использовала другая запись, уже имеющаяся
- 18. При поиске записи сначала вычисляется значение ее хэш-функции и считывается первая запись в цепочке синонимов, которая
- 19. Организация стратегии свободного замещения При этой стратегии файловое пространство не разделяется на области, но для каждой
- 20. Если да, то новая запись располагается на первом свободном месте и для нее устанавливаются соответствующие ссылки:
- 22. Скачать презентацию

Слайд 3В каждой СУБД по-разному организованы хранение и доступ к данным.
Существуют файловые структуры,
В каждой СУБД по-разному организованы хранение и доступ к данным.
Существуют файловые структуры,

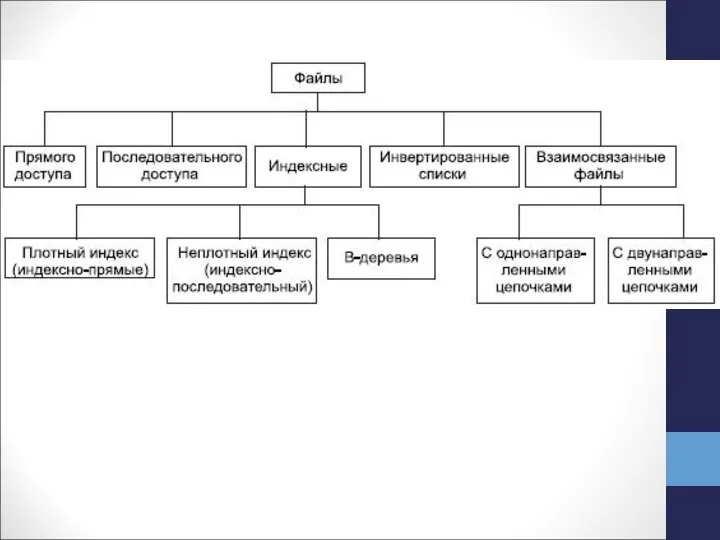
Слайд 5С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на

Слайд 6В соответствии с методами управления доступом различают:
устройства внешней памяти с произвольной адресацией
В соответствии с методами управления доступом различают:
устройства внешней памяти с произвольной адресацией

Слайд 7Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются

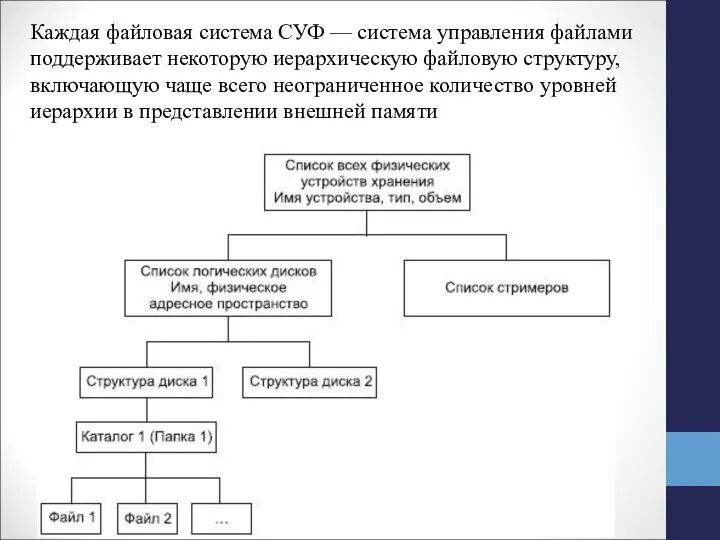
Слайд 8Каждая файловая система СУФ — система управления файлами поддерживает некоторую иерархическую файловую
Каждая файловая система СУФ — система управления файлами поддерживает некоторую иерархическую файловую
Слайд 9Для каждого файла в системе хранится следующая информация:
имя файла;
тип файла (например,
Для каждого файла в системе хранится следующая информация:
имя файла;
тип файла (например,

Слайд 10Для файлов с постоянной длиной записи адрес размещения записи с номером K
Для файлов с постоянной длиной записи адрес размещения записи с номером K

Слайд 11На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Файлы с
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Файлы с

Слайд 12Файлы с прямым доступом обеспечивают наиболее быстрый способ доступа.
Доступ по номеру
Доступ по номеру

Слайд 13При организации файлов прямого доступа в некоторых очень редких случаях возможно построение
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение

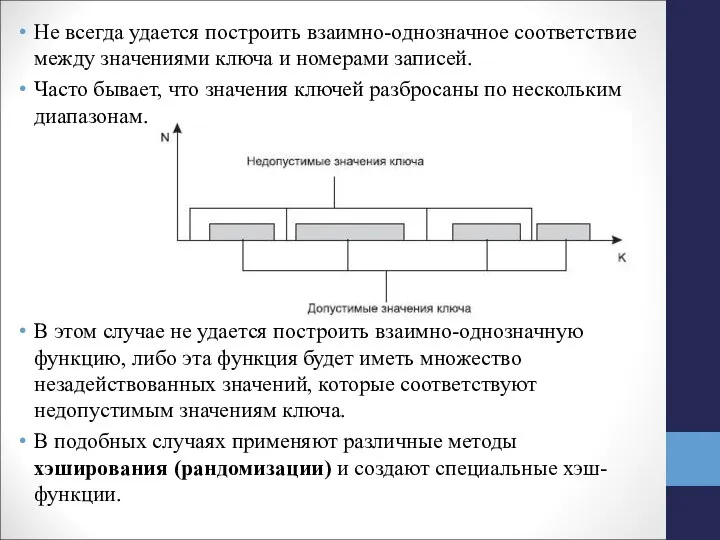
Слайд 14Не всегда удается построить взаимно-однозначное соответствие между значениями ключа и номерами записей.
Часто
Не всегда удается построить взаимно-однозначное соответствие между значениями ключа и номерами записей.
Часто
Слайд 15Суть методов хэширования состоит в том, что мы берем значения ключа (или
Суть методов хэширования состоит в том, что мы берем значения ключа (или

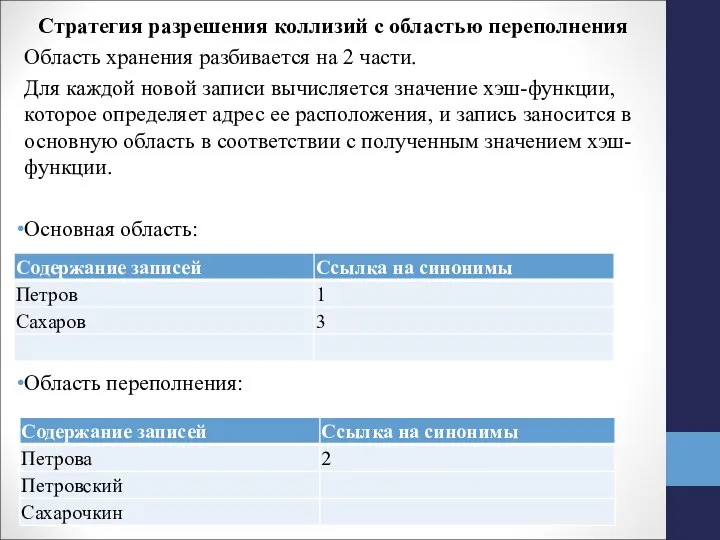
Слайд 16Стратегия разрешения коллизий с областью переполнения
Область хранения разбивается на 2 части.
Для каждой
Стратегия разрешения коллизий с областью переполнения
Область хранения разбивается на 2 части.
Для каждой
Слайд 17Если вновь заносимая запись имеет значение функции хэширования такое же, которое использовала
Если вновь заносимая запись имеет значение функции хэширования такое же, которое использовала

Слайд 18При поиске записи сначала вычисляется значение ее хэш-функции и считывается первая запись
При поиске записи сначала вычисляется значение ее хэш-функции и считывается первая запись

Слайд 19Организация стратегии свободного замещения
При этой стратегии файловое пространство не разделяется на области,
Организация стратегии свободного замещения
При этой стратегии файловое пространство не разделяется на области,

Слайд 20Если да, то новая запись располагается на первом свободном месте и для
Если да, то новая запись располагается на первом свободном месте и для

 IoC Inversion of Control инверсия управления. Dependency Injection (внедрение зависимостей)
IoC Inversion of Control инверсия управления. Dependency Injection (внедрение зависимостей) логика
логика Особенности материалов для соцсетей: пост, лонгрид подкаст
Особенности материалов для соцсетей: пост, лонгрид подкаст 1_количество_инф
1_количество_инф Использование свободного программного обеспечения для обучения графике
Использование свободного программного обеспечения для обучения графике Информация
Информация Разработка автоматизированной информационной системы учета материальных и иных активов в ЦЦОД IT-Куб г. Княгинино
Разработка автоматизированной информационной системы учета материальных и иных активов в ЦЦОД IT-Куб г. Княгинино Создание кроссворда в текстовом процессоре Word. 8 класс
Создание кроссворда в текстовом процессоре Word. 8 класс Анализ неструктурированных данных и оптимизация их хранения
Анализ неструктурированных данных и оптимизация их хранения ВКР: Разработка агрегатора сервисных центров по ремонту электроники
ВКР: Разработка агрегатора сервисных центров по ремонту электроники Настройка Vlan
Настройка Vlan Составление комбинированных алгоритмов для графических исполнителей
Составление комбинированных алгоритмов для графических исполнителей Макросы MoveHim и MoveTo
Макросы MoveHim и MoveTo Дистанционная подготовка
Дистанционная подготовка Отношения между объектами
Отношения между объектами Библиотечный урок В гостях у книжки о структуре книги
Библиотечный урок В гостях у книжки о структуре книги Интересные факты
Интересные факты Створюємо блог
Створюємо блог Школа “Успех в Internet PRO100”
Школа “Успех в Internet PRO100” Мемы
Мемы Самоаудит отделений boxberry через мобильное приложение Checkpoint
Самоаудит отделений boxberry через мобильное приложение Checkpoint Работа редактора с композицией медиатекста
Работа редактора с композицией медиатекста Jobs Guessing Game
Jobs Guessing Game App that change adventures
App that change adventures Основные логические операции
Основные логические операции Улучшаем монетизацию c РСЯ
Улучшаем монетизацию c РСЯ Представление данных в текстовом формате. Информационные технологии
Представление данных в текстовом формате. Информационные технологии Триггеры в презентации. Применение
Триггеры в презентации. Применение