- Фокусы. Оптимизация компилятором

Содержание
- 2. Краткое содержание этой серии Фокусы Оптимизация компилятором
- 3. Фокус №1 Создаю глобальный двухмерный массив Заполняю его случайными числами Вычисляю сумму всех элементов: sum +=
- 4. Фокус №1 А как лежит в памяти двумерный массив? uint8_t array[2][4] = { {1,2,3,4}, {5,6,7,8}}; Точно
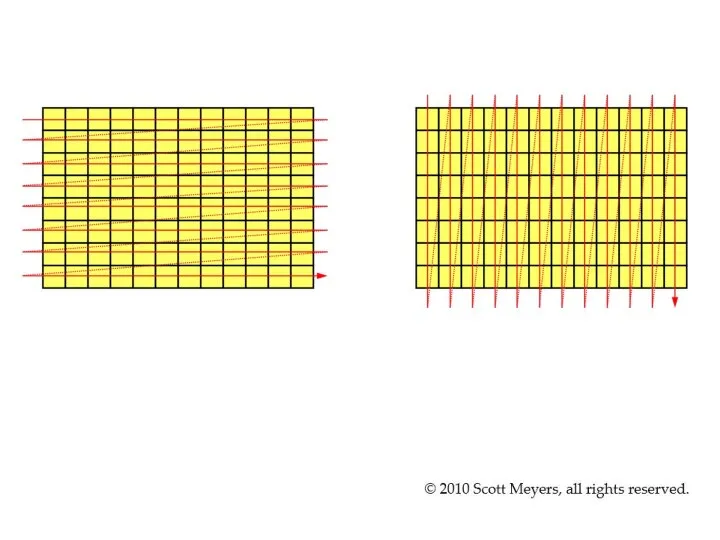
- 6. Все дело в кэш-памяти Зачем нужен кэш? Чтобы ускорить доступ к часто используемым данным, т.к. оперативная
- 7. А как работает кэш? Кэш состоит из «линий» (cache lines) - при каждом обращении в память
- 8. Кэш Вывод? Последовательный доступ к памяти гораздо быстрее, чем случайный. С точки зрения железа самая быстрая
- 9. Кэш В современных процессорах есть: кэш данных (D-cache) кэш инструкций (I-cache) буфер ассоциативной трансляции (TLB) Как
- 10. Кэш в современном процессоре Intel Core i7-9xx: L1 cache: 64 KiB L2 cache: 256 KiB L3
- 11. Кэш в современном процессоре Время чтения из памяти для Core i7-9xx: L1 - 4 такта. L2
- 12. Кэш Допустим, что два ядра процессора обращаются к одной и той же переменной. Тогда соответствующий кусок
- 13. Кэш Допустим, что два ядра процессора обращаются к двум разным переменным, которые расположены в памяти рядом.
- 14. Фокус №1.5 Возьмем неудачный способ сложения элементов массива (по столбцам). Логично предположить, что чем больше массив
- 15. Ассоциативность кэша А как узнать, закэширована переменная или нет? Кэш прямого отображения - каждый адрес памяти
- 16. Частично ассоциативный кэш Например, 16-входовой частично ассоциативный кэш – линии кэша делятся на 16 групп. Каждая
- 17. Кэш для инструкций Линейный код (без переходов) выполняется быстрее Маленькие программы (которые целиком помещаются в кэш)
- 18. Выводы При оценке быстродействия алгоритма нужно помнить про кэш. Писать быстродействующие программы – это сложно. Тестировать
- 19. Фокус №2 Вариант А: Заполним одномерный массив случайными элементами. Много раз найдем сумму всех элементов больше
- 20. Предсказание переходов Ключевой момент: if (data[c] >= 128) sum += data[c]; Если массив отсортирован – то
- 21. Оптимизация Критерии оптимизации: по объему кода (бинарного файла) по скорости исполнения Иногда можно (и хочется) оптимизировать
- 23. Скачать презентацию

Слайд 3Фокус №1
Создаю глобальный двухмерный массив
Заполняю его случайными числами
Вычисляю сумму всех элементов:
sum +=
Фокус №1
Создаю глобальный двухмерный массив
Заполняю его случайными числами
Вычисляю сумму всех элементов:
sum +=

Слайд 4Фокус №1
А как лежит в памяти двумерный массив?
uint8_t array[2][4] = { {1,2,3,4},
Фокус №1
А как лежит в памяти двумерный массив?
uint8_t array[2][4] = { {1,2,3,4},
![Фокус №1 А как лежит в памяти двумерный массив? uint8_t array[2][4] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/992668/slide-3.jpg)
Слайд 6Все дело в кэш-памяти
Зачем нужен кэш?
Чтобы ускорить доступ к часто используемым данным,
Все дело в кэш-памяти
Зачем нужен кэш?
Чтобы ускорить доступ к часто используемым данным,

Слайд 7А как работает кэш?
Кэш состоит из «линий» (cache lines) -
при каждом
А как работает кэш?
Кэш состоит из «линий» (cache lines) -
при каждом

Слайд 8Кэш
Вывод?
Последовательный доступ к памяти гораздо быстрее, чем случайный.
С точки зрения железа самая
Кэш
Вывод?
Последовательный доступ к памяти гораздо быстрее, чем случайный.
С точки зрения железа самая

Слайд 9Кэш
В современных процессорах есть:
кэш данных (D-cache)
кэш инструкций (I-cache)
буфер ассоциативной трансляции (TLB)
Как правило,
Кэш
В современных процессорах есть:
кэш данных (D-cache)
кэш инструкций (I-cache)
буфер ассоциативной трансляции (TLB)
Как правило,

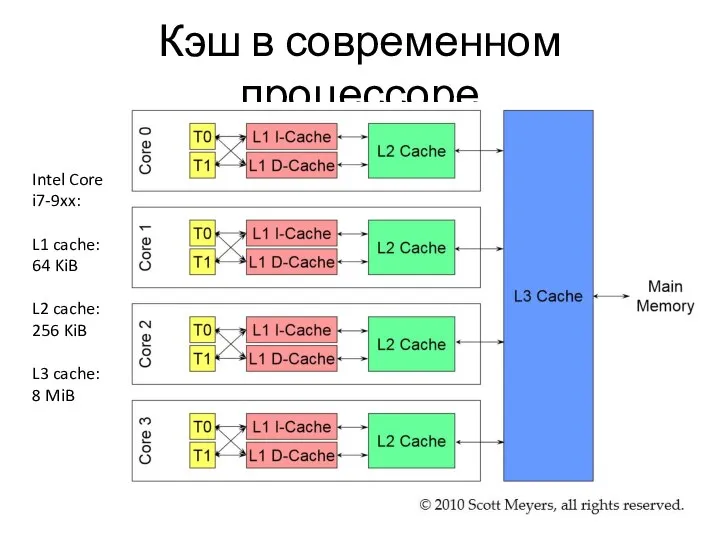
Слайд 10Кэш в современном процессоре
Intel Core i7-9xx:
L1 cache: 64 KiB
L2 cache:
256 KiB
L3 cache:
8
Кэш в современном процессоре
Intel Core i7-9xx:
L1 cache: 64 KiB
L2 cache:
256 KiB
L3 cache:
8
Слайд 11Кэш в современном процессоре
Время чтения из памяти для Core i7-9xx:
L1 - 4
Кэш в современном процессоре
Время чтения из памяти для Core i7-9xx:
L1 - 4

Слайд 12Кэш
Допустим, что два ядра процессора обращаются к одной и той же переменной.
Тогда
Кэш
Допустим, что два ядра процессора обращаются к одной и той же переменной.
Тогда

Слайд 13Кэш
Допустим, что два ядра процессора обращаются к двум разным переменным, которые расположены
Кэш
Допустим, что два ядра процессора обращаются к двум разным переменным, которые расположены

Слайд 14Фокус №1.5
Возьмем неудачный способ сложения элементов массива (по столбцам).
Логично предположить, что чем
Фокус №1.5
Возьмем неудачный способ сложения элементов массива (по столбцам).
Логично предположить, что чем

Слайд 15Ассоциативность кэша
А как узнать, закэширована переменная или нет?
Кэш прямого отображения - каждый
Ассоциативность кэша
А как узнать, закэширована переменная или нет?
Кэш прямого отображения - каждый

Слайд 16Частично ассоциативный кэш
Например, 16-входовой частично ассоциативный кэш – линии кэша делятся на
Частично ассоциативный кэш
Например, 16-входовой частично ассоциативный кэш – линии кэша делятся на

Слайд 17Кэш для инструкций
Линейный код (без переходов) выполняется быстрее
Маленькие программы (которые целиком помещаются
Кэш для инструкций
Линейный код (без переходов) выполняется быстрее
Маленькие программы (которые целиком помещаются

Слайд 18Выводы
При оценке быстродействия алгоритма нужно помнить про кэш.
Писать быстродействующие программы – это
Выводы
При оценке быстродействия алгоритма нужно помнить про кэш.
Писать быстродействующие программы – это

Слайд 19Фокус №2
Вариант А:
Заполним одномерный массив случайными элементами.
Много раз найдем сумму всех элементов
Фокус №2
Вариант А:
Заполним одномерный массив случайными элементами.
Много раз найдем сумму всех элементов

Слайд 20Предсказание переходов
Ключевой момент:
if (data[c] >= 128)
sum += data[c];
Если массив отсортирован
Предсказание переходов
Ключевой момент:
if (data[c] >= 128)
sum += data[c];
Если массив отсортирован
![Предсказание переходов Ключевой момент: if (data[c] >= 128) sum += data[c]; Если](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/992668/slide-19.jpg)
Слайд 21Оптимизация
Критерии оптимизации:
по объему кода (бинарного файла)
по скорости исполнения
Иногда можно (и хочется) оптимизировать
Оптимизация
Критерии оптимизации:
по объему кода (бинарного файла)
по скорости исполнения
Иногда можно (и хочется) оптимизировать

 6_1Массивы
6_1Массивы Теги по фону и картинкам
Теги по фону и картинкам Презентация на тему Основы моделирования
Презентация на тему Основы моделирования  Пример презентации. Р/Д
Пример презентации. Р/Д Структура курса и введение в информатику. Лекция №1
Структура курса и введение в информатику. Лекция №1 1.Вводная лекция
1.Вводная лекция Проектная работа на тему: Мобильное приложение События УрФУ
Проектная работа на тему: Мобильное приложение События УрФУ Создание онлайн-викторин, игр и квестов
Создание онлайн-викторин, игр и квестов Мышление, УМК по информатике для 5-7 классов
Мышление, УМК по информатике для 5-7 классов Spinia. Betamo
Spinia. Betamo Логические основы ЭЦВМ
Логические основы ЭЦВМ Информационное пространство в моем окружении
Информационное пространство в моем окружении Участие в разработке ИС. Создание WEB-сайта Магазин канцелярских товаров
Участие в разработке ИС. Создание WEB-сайта Магазин канцелярских товаров История интеренета
История интеренета Всемирная паутина
Всемирная паутина Программирование на языке Python. Уровень 2
Программирование на языке Python. Уровень 2 Компьютерная графика
Компьютерная графика Комп’ютерний вiруси та їх классифiкацiя
Комп’ютерний вiруси та їх классифiкацiя Информационные системы. Качества и характеристика информационных систем
Информационные системы. Качества и характеристика информационных систем Операционные системы
Операционные системы Презентация на тему Электронные деньги и их свойства
Презентация на тему Электронные деньги и их свойства  10u-2a_Кодирование-I
10u-2a_Кодирование-I Лекция 3_Основы технологии совместной работы_Облачные технологии
Лекция 3_Основы технологии совместной работы_Облачные технологии Блокированный жилой дом
Блокированный жилой дом Презентация на тему Программная оболочка Norton Commander
Презентация на тему Программная оболочка Norton Commander  Архитектура персонального компьютера
Архитектура персонального компьютера Функции и модули 1
Функции и модули 1 Текстовая информация
Текстовая информация