- Функции СУБД. Типовая организация СУБД. Дореляционные СУБД. Лекция №2

Содержание
- 2. Как было показано в первой лекции, традиционных возможностей файловых систем оказывается недостаточно для построения даже простых
- 3. Основные функции СУБД: Непосредственное управление данными во внешней памяти Управление буферами оперативной памяти Управление транзакциями Журнализация
- 4. Непосредственное управление данными во внешней памяти Эта функция включает обеспечение необходимых структур внешней памяти как для
- 5. Управление буферами оперативной памяти СУБД обычно работают с БД значительного размера; по крайней мере этот размер
- 6. Управление транзакциями Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция
- 7. Журнализация Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью
- 8. Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание
- 9. Поддержка языков БД Для работы с базами данных используются специальные языки, в целом называемые языками баз
- 10. Поддержка языков БД В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для
- 11. Типовая организация современной СУБД мы выделили следующие основные функции СУБД: управление данными во внешней памяти; управление
- 12. Логически в современной реляционной СУБД можно выделить наиболее внутреннюю часть - ядро СУБД (часто его называют
- 13. Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и
- 14. Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую выполняемую программу. Основной проблемой
- 15. Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка
- 16. УРА! ПЕРЕМЕНА!
- 17. Дореляционные СУБД Системы, основанные на инвертированных списках, иерархические и сетевые СУБД. Сильные места и недостатки ранних
- 18. Зачем нам знать о таких системах? В этом есть смысл по трем причинам: во-первых, эти системы
- 19. Общие характеристики ранних систем Эти системы активно использовались в течение многих лет, дольше, чем используется какая-либо
- 20. Основные особенности систем, основанных на инвертированных списках Рассмотрим только самое важное: Структуры данных Манипулирование данными Ограничения
- 21. Системы, основанные на инвертированных списках: Структуры данных База данных, организованная с помощью инвертированных списков, похожа на
- 22. Системы, основанные на инвертированных списках: Манипулирование данными Поддерживаются два класса операторов: Операторы, устанавливающие адрес записи, среди
- 23. Системы, основанные на инвертированных списках: Ограничения целостности Общие правила определения целостности БД отсутствуют. В некоторых системах
- 24. Иерархические системы: Структуры данных Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора
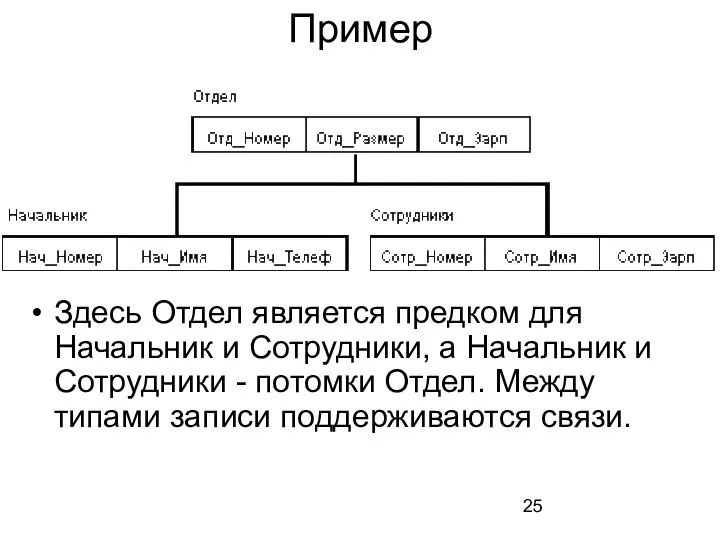
- 25. Пример Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел.
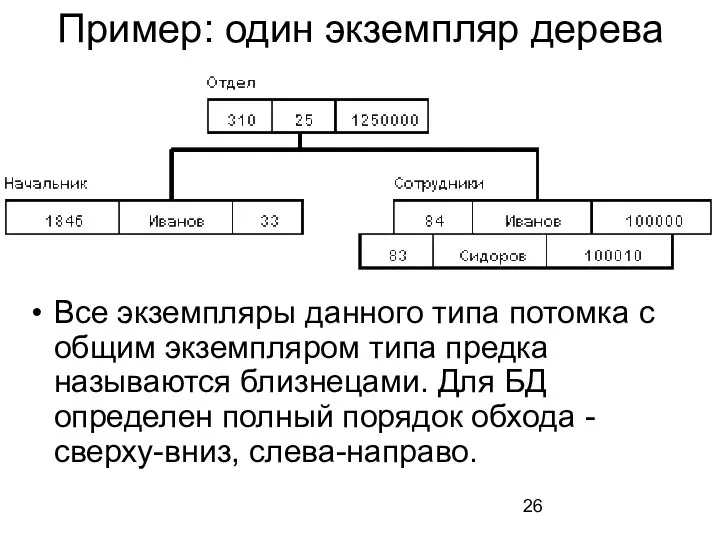
- 26. Пример: один экземпляр дерева Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами.
- 27. Иерархические системы: Манипулирование данными Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие: Найти указанное
- 28. Иерархические системы: Ограничения целостности Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок
- 29. Сетевые системы: Структуры данных Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок
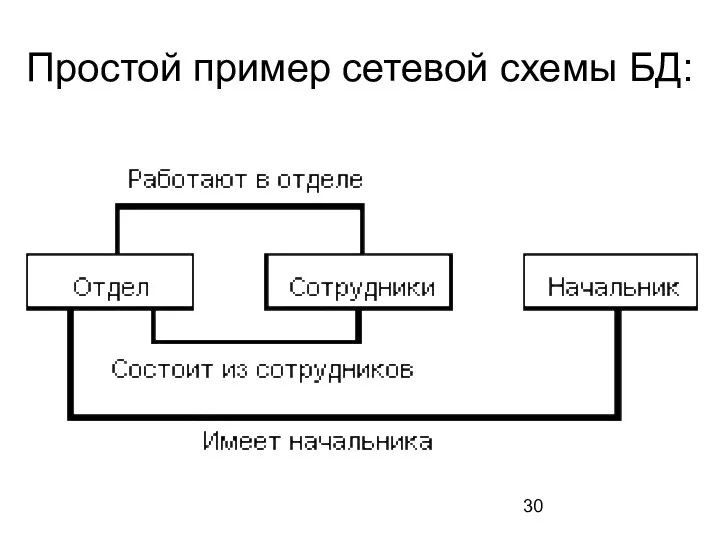
- 30. Простой пример сетевой схемы БД:
- 31. Сетевые системы: Манипулирование данными Примерный набор операций может быть следующим: Найти конкретную запись в наборе однотипных
- 32. Сетевые системы: Ограничения целостности В принципе их поддержание не требуется, но иногда требуют целостности по ссылкам
- 34. Скачать презентацию
Слайд 2Как было показано в первой лекции, традиционных возможностей файловых систем оказывается недостаточно
Как было показано в первой лекции, традиционных возможностей файловых систем оказывается недостаточно

Слайд 3Основные функции СУБД:
Непосредственное управление данными во внешней памяти
Управление буферами оперативной
Основные функции СУБД:
Непосредственное управление данными во внешней памяти
Управление буферами оперативной

Слайд 4Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур
Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур

Слайд 5Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по
Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по

Слайд 6Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как
Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как

Слайд 7Журнализация
Одним из основных требований к СУБД является надежность хранения данных во
Журнализация
Одним из основных требований к СУБД является надежность хранения данных во

Слайд 8Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной
Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной

Слайд 9Поддержка языков БД
Для работы с базами данных используются специальные языки, в
Поддержка языков БД
Для работы с базами данных используются специальные языки, в

Слайд 10Поддержка языков БД
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий
Поддержка языков БД
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий

Слайд 11Типовая организация современной СУБД
мы выделили следующие основные функции СУБД:
управление данными
Типовая организация современной СУБД
мы выделили следующие основные функции СУБД:
управление данными

Слайд 12Логически в современной реляционной СУБД можно выделить
наиболее внутреннюю часть - ядро
Логически в современной реляционной СУБД можно выделить
наиболее внутреннюю часть - ядро

Слайд 13Ядро СУБД отвечает за
управление данными во внешней памяти,
управление буферами оперативной
Ядро СУБД отвечает за
управление данными во внешней памяти,
управление буферами оперативной

Слайд 14Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую
Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую

Слайд 15Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно
Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно

Слайд 16УРА!
ПЕРЕМЕНА!
УРА!
ПЕРЕМЕНА!

Слайд 17Дореляционные СУБД
Системы, основанные на инвертированных списках,
иерархические
и сетевые СУБД.
Сильные места и
Дореляционные СУБД
Системы, основанные на инвертированных списках,
иерархические
и сетевые СУБД.
Сильные места и

Слайд 18Зачем нам знать о таких системах?
В этом есть смысл по трем причинам:
Зачем нам знать о таких системах?
В этом есть смысл по трем причинам:

Слайд 19Общие характеристики ранних систем
Эти системы активно использовались в течение многих лет,
Общие характеристики ранних систем
Эти системы активно использовались в течение многих лет,

Слайд 20Основные особенности систем, основанных на инвертированных списках
Рассмотрим только самое важное:
Структуры данных
Основные особенности систем, основанных на инвертированных списках
Рассмотрим только самое важное:
Структуры данных

Слайд 21Системы, основанные на инвертированных списках: Структуры данных
База данных, организованная с помощью
Системы, основанные на инвертированных списках: Структуры данных
База данных, организованная с помощью

Слайд 22Системы, основанные на инвертированных списках: Манипулирование данными
Поддерживаются два класса операторов:
Операторы,
Системы, основанные на инвертированных списках: Манипулирование данными
Поддерживаются два класса операторов:
Операторы,

Слайд 23Системы, основанные на инвертированных списках: Ограничения целостности
Общие правила определения целостности БД
Системы, основанные на инвертированных списках: Ограничения целостности
Общие правила определения целостности БД

Слайд 24Иерархические системы:
Структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более
Иерархические системы:
Структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более

Слайд 25Пример
Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники
Пример
Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники
Слайд 26Пример: один экземпляр дерева
Все экземпляры данного типа потомка с общим экземпляром
Пример: один экземпляр дерева
Все экземпляры данного типа потомка с общим экземпляром
Слайд 27Иерархические системы:
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут
Иерархические системы:
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут

Слайд 28Иерархические системы:
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками.
Иерархические системы:
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками.

Слайд 29Сетевые системы:
Структуры данных
Сетевой подход к организации данных является расширением иерархического.
Сетевые системы:
Структуры данных
Сетевой подход к организации данных является расширением иерархического.

Слайд 30Простой пример сетевой схемы БД:
Простой пример сетевой схемы БД:
Слайд 31Сетевые системы:
Манипулирование данными
Примерный набор операций может быть следующим:
Найти конкретную
Сетевые системы:
Манипулирование данными
Примерный набор операций может быть следующим:
Найти конкретную

Слайд 32Сетевые системы:
Ограничения целостности
В принципе их поддержание не требуется, но иногда
Сетевые системы:
Ограничения целостности
В принципе их поддержание не требуется, но иногда

 Разработка тестов. Практическая работа № 5
Разработка тестов. Практическая работа № 5 Самая популярная газета в Сан-Фиерро
Самая популярная газета в Сан-Фиерро Сравнительный анализ сайтов. Сайты вузов
Сравнительный анализ сайтов. Сайты вузов FX Net. Практическая работа
FX Net. Практическая работа Текстовый процессор MS Word
Текстовый процессор MS Word Что такое айтишечка?
Что такое айтишечка? Компьютерные технологии и информационные системы. Тема 3.2
Компьютерные технологии и информационные системы. Тема 3.2 Почтовые программы
Почтовые программы Пошук у сетцы Інтэрнэт
Пошук у сетцы Інтэрнэт Інформація. Інформаційні процеси
Інформація. Інформаційні процеси Интерактивные форматы и особенности вёрстки в медиа
Интерактивные форматы и особенности вёрстки в медиа Презентация на тему Основные понятия и правила записи функций в Excel
Презентация на тему Основные понятия и правила записи функций в Excel  Однопроходные алгоритмы
Однопроходные алгоритмы Размещение графики на Web-страницах
Размещение графики на Web-страницах Системы счисления
Системы счисления О себе
О себе Типы данных в VBA
Типы данных в VBA Защита информации. Безопасность информации. Математический аппарат
Защита информации. Безопасность информации. Математический аппарат Электронные таблицы обработка числовой информации в электронных таблицах
Электронные таблицы обработка числовой информации в электронных таблицах Основные понятия теории управления сложными системами. Информационные технологии и их классификация
Основные понятия теории управления сложными системами. Информационные технологии и их классификация Компьютерная графика
Компьютерная графика Ростейшие преобразования изображений
Ростейшие преобразования изображений Логические основы компьютера
Логические основы компьютера Форматирование текста (шрифт)
Форматирование текста (шрифт) Динамические структуры данных
Динамические структуры данных Знакомство с языком программирования. Линейные вычислительные алгоритмы
Знакомство с языком программирования. Линейные вычислительные алгоритмы Паскаль. Ветвление
Паскаль. Ветвление Характеристика производственной системы. Тема №4
Характеристика производственной системы. Тема №4