- Хеш-таблицы

Содержание
- 2. АТД «Словарь» (dictionary) Словарь (ассоциативный массив, associative array, map, dictionary) – структура данных (контейнер) для хранения
- 3. Хеш-таблицы (Hash tables) Хеш-таблица (hash table) – структура данных для хранения пар «ключ – значение» Доступ
- 4. Основная идея Чем хороши статические массивы int v[100]? Быстрый доступ O(1) к элементу массива по его
- 5. Основная идея Чем хороши статические массивы int v[100]? Быстрый доступ O(1) к элементу массива по его
- 6. Хеш-таблицы (Hash tables) Ключ (Key) “Антилопа Гну” Хеш-таблица (Hash table) Хеш-функция (Hash function) hash(key) -> int
- 7. Хеш-таблицы (Hash tables) Хеш-таблица (Hash table) 0 1 2 … h – 1
- 8. Хеш-функции (Hash function) Хеш-функция (Hash function) – это функция преобразующая значения ключа (например: строки, числа, файла)
- 9. Хеш-функции (Hash function) Хеш-функция (Hash function) – это функция преобразующая значения ключа (например: строки, числа, файла)
- 10. Хеш-функции (Hash function) #define HASH_MUL 31 #define HASH_SIZE 128 unsigned int hash(char *s) { unsigned int
- 11. Понятие коллизии (Collision) Коллизия (Collision) – это совпадение значений хеш-функции для двух разных ключей Keys Hashes
- 12. Разрешение коллизий (Collision resolution) Метод цепочек (Chaining) – закрытая адресация Элементы с одинаковым значением хеш-функции объединяются
- 13. Разрешение коллизий (Collision resolution) Открытая адресация (Open addressing) В каждой ячейке хеш-таблицы хранится не указатель на
- 14. Требования к хеш-функциям Быстрое вычисление хэш-кода по значению ключа Сложность вычисления хэш-кода не должна зависеть от
- 15. Требования к хеш-функциям Равномерность (uniform distribution) – хеш-функция должна равномерно заполнять индексы массива возвращаемыми номерами Желательно,
- 16. Требования к хеш-функциям Равномерность (uniform distribution) – хеш-функция должна равномерно заполнять индексы массива возвращаемыми номерами Желательно,
- 17. Эффективность хеш-таблиц Хеш-таблица требует предварительной инициализации ячеек значениями NULL – трудоемкость O(h)
- 18. Пример хэш-функции для строк unsigned int ELFHash(char *key, unsigned int mod) { unsigned int h =
- 19. Jenkins hash functions uint32_t jenkins_hash(char *key, size_t len) { uint32_t hash, i; for (hash = i
- 20. Пример хэш-функции для чисел Ключи – размер файла (int) Значение, хранимое в словаре – название файла
- 21. Пример хэш-функции для строк
- 22. Хеш-таблицы (Hash table) Длину h хеш-таблицы выбирают как простое число Для такой таблицы модульная хеш-функция дает
- 23. Хеш-таблицы vs. Бинарное дерево поиска Эффективность реализации словаря хеш-таблицей (метод цепочек) и бинарным деревом поиска Ключ
- 24. Хеш-таблицы vs. Бинарное дерево поиска Эффективность реализации словаря хеш-таблицей (метод цепочек) и бинарным деревом поиска Ключ
- 25. Реализация хеш-таблицы #include #include #include #define HASHTAB_SIZE 71 #define HASHTAB_MUL 31 struct listnode { char *key;
- 26. Хеш-функция unsigned int hashtab_hash(char *key) { unsigned int h = 0; char *p; for (p =
- 27. Инициализация хеш-таблицы void hashtab_init(struct listnode **hashtab) { int i; for (i = 0; i hashtab[i] =
- 28. Добавление элемента в хеш-таблицу void hashtab_add(struct listnode **hashtab, char *key, int value) { struct listnode *node;
- 29. Поиск элемента struct listnode *hashtab_lookup( struct listnode **hashtab, char *key) { int index; struct listnode *node;
- 30. Поиск элемента int main() { struct listnode *node; hashtab_init(hashtab); hashtab_add(hashtab, "Tigr", 190); hashtab_add(hashtab, "Slon", 2300); hashtab_add(hashtab,
- 31. Удаление элемента void hashtab_delete(struct listnode **hashtab, char *key) { int index; struct listnode *p, *prev =
- 32. Удаление элемента int main() { struct listnode *node; /* ... */ hashtab_delete(hashtab, "Slon"); node = hashtab_lookup(hashtab,
- 34. Скачать презентацию
Слайд 2АТД «Словарь» (dictionary)
Словарь (ассоциативный массив, associative array, map, dictionary) – структура данных
АТД «Словарь» (dictionary)
Словарь (ассоциативный массив, associative array, map, dictionary) – структура данных

Слайд 3Хеш-таблицы (Hash tables)
Хеш-таблица (hash table) – структура данных
для хранения пар «ключ
Хеш-таблицы (Hash tables)
Хеш-таблица (hash table) – структура данных для хранения пар «ключ

Слайд 4Основная идея
Чем хороши статические массивы int v[100]?
Быстрый доступ O(1) к элементу массива
Основная идея
Чем хороши статические массивы int v[100]?
Быстрый доступ O(1) к элементу массива
![Основная идея Чем хороши статические массивы int v[100]? Быстрый доступ O(1) к](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/945724/slide-3.jpg)
Слайд 5Основная идея
Чем хороши статические массивы int v[100]?
Быстрый доступ O(1) к элементу массива
Основная идея
Чем хороши статические массивы int v[100]?
Быстрый доступ O(1) к элементу массива
![Основная идея Чем хороши статические массивы int v[100]? Быстрый доступ O(1) к](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/945724/slide-4.jpg)
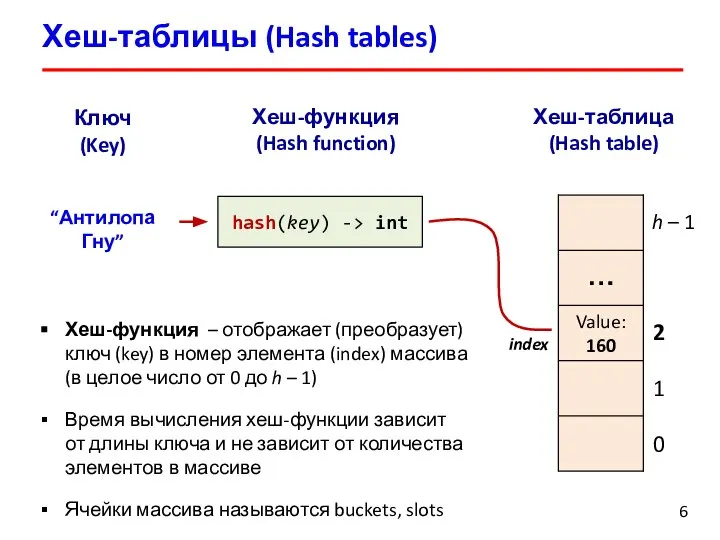
Слайд 6Хеш-таблицы (Hash tables)
Ключ
(Key)
“Антилопа Гну”
Хеш-таблица (Hash table)
Хеш-функция
(Hash function)
hash(key) -> int
0
1
2
…
h – 1
Хеш-функция
Хеш-таблицы (Hash tables)
Ключ
(Key)
“Антилопа Гну”
Хеш-таблица (Hash table)
Хеш-функция
(Hash function)
hash(key) -> int
0
1
2
…
h – 1
Хеш-функция
Слайд 7Хеш-таблицы (Hash tables)
Хеш-таблица (Hash table)
0
1
2
…
h – 1
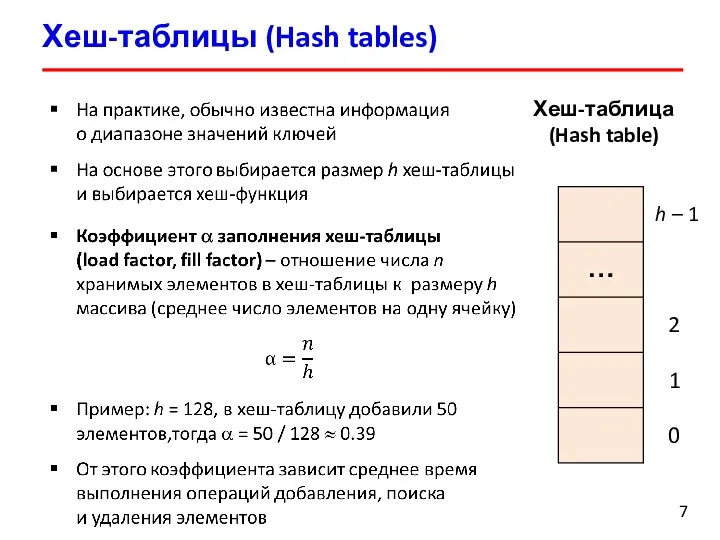
Хеш-таблицы (Hash tables)
Хеш-таблица (Hash table)
0
1
2
…
h – 1
Слайд 8Хеш-функции (Hash function)
Хеш-функция (Hash function) – это функция преобразующая значения ключа (например:
Хеш-функции (Hash function)
Хеш-функция (Hash function) – это функция преобразующая значения ключа (например:

Слайд 9Хеш-функции (Hash function)
Хеш-функция (Hash function) – это функция преобразующая значения ключа (например:
Хеш-функции (Hash function)
Хеш-функция (Hash function) – это функция преобразующая значения ключа (например:

Слайд 10Хеш-функции (Hash function)
#define HASH_MUL 31
#define HASH_SIZE 128
unsigned int hash(char *s) {
unsigned
Хеш-функции (Hash function)
#define HASH_MUL 31
#define HASH_SIZE 128
unsigned int hash(char *s) {
unsigned

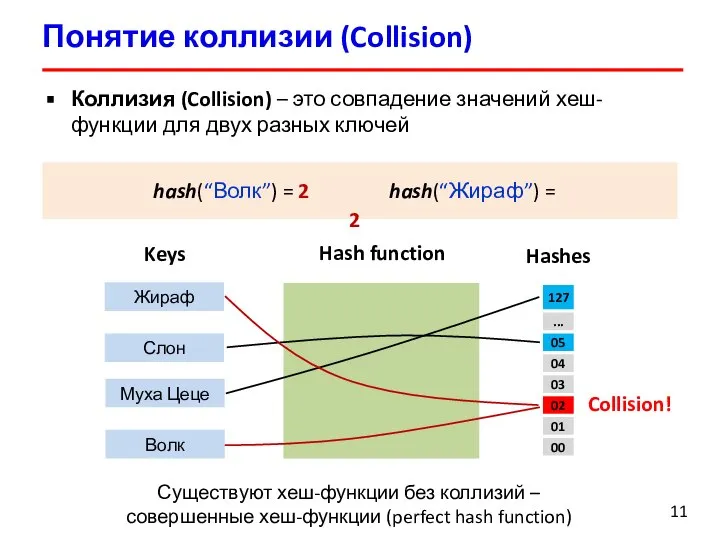
Слайд 11Понятие коллизии (Collision)
Коллизия (Collision) – это совпадение значений хеш-функции для двух разных
Понятие коллизии (Collision)
Коллизия (Collision) – это совпадение значений хеш-функции для двух разных
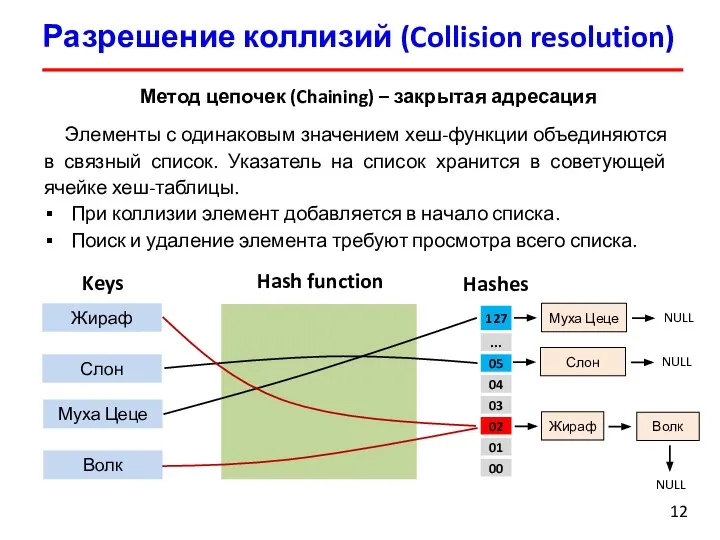
Слайд 12Разрешение коллизий (Collision resolution)
Метод цепочек (Chaining) – закрытая адресация
Элементы с одинаковым значением
Разрешение коллизий (Collision resolution)
Метод цепочек (Chaining) – закрытая адресация
Элементы с одинаковым значением
Слайд 13Разрешение коллизий (Collision resolution)
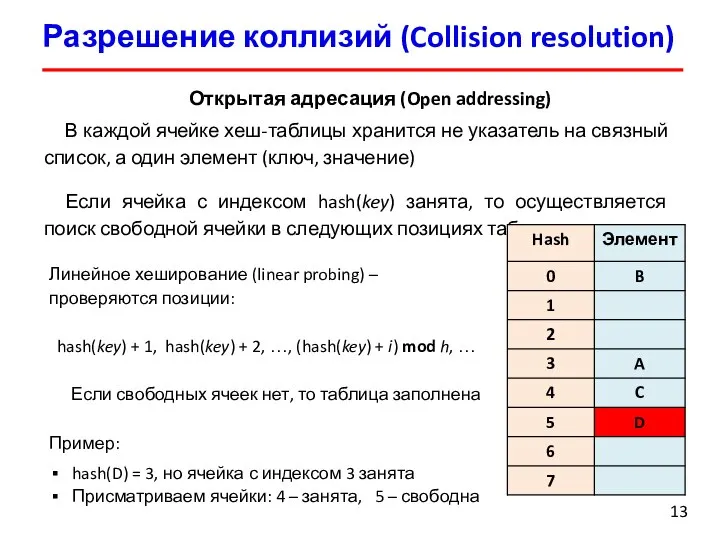
Открытая адресация (Open addressing)
В каждой ячейке хеш-таблицы хранится
Разрешение коллизий (Collision resolution)
Открытая адресация (Open addressing)
В каждой ячейке хеш-таблицы хранится
Слайд 14Требования к хеш-функциям
Быстрое вычисление хэш-кода по значению ключа
Сложность вычисления хэш-кода не должна
Требования к хеш-функциям
Быстрое вычисление хэш-кода по значению ключа
Сложность вычисления хэш-кода не должна

Слайд 15Требования к хеш-функциям
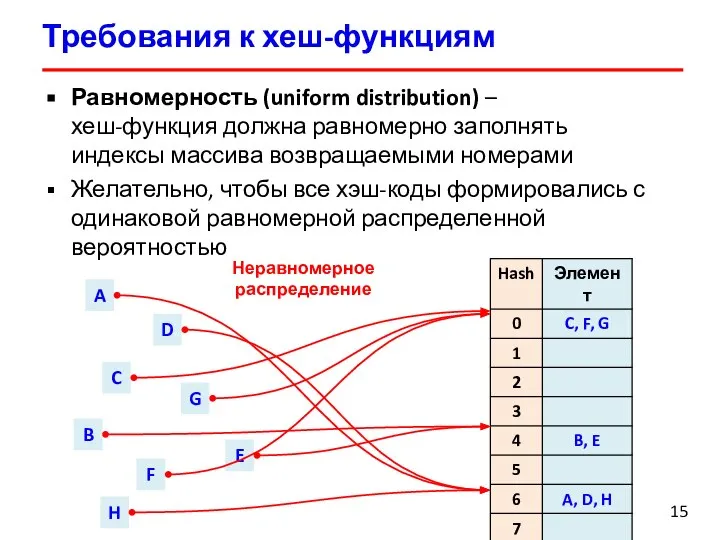
Равномерность (uniform distribution) –
хеш-функция должна равномерно заполнять
индексы массива
Требования к хеш-функциям
Равномерность (uniform distribution) – хеш-функция должна равномерно заполнять индексы массива
Слайд 16Требования к хеш-функциям
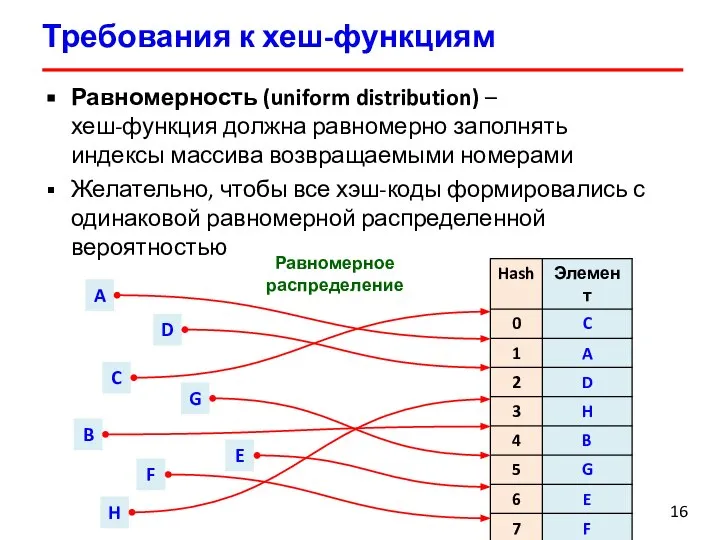
Равномерность (uniform distribution) –
хеш-функция должна равномерно заполнять
индексы массива
Требования к хеш-функциям
Равномерность (uniform distribution) – хеш-функция должна равномерно заполнять индексы массива
Слайд 17Эффективность хеш-таблиц
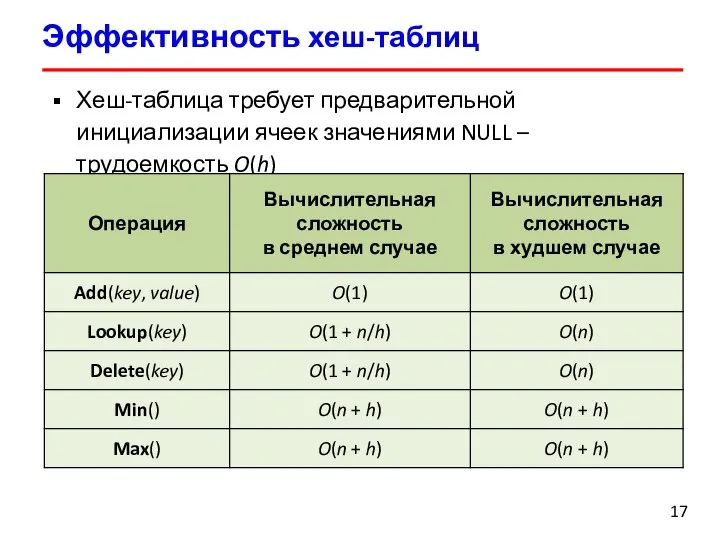
Хеш-таблица требует предварительной инициализации ячеек значениями NULL – трудоемкость O(h)
Эффективность хеш-таблиц
Хеш-таблица требует предварительной инициализации ячеек значениями NULL – трудоемкость O(h)
Слайд 18Пример хэш-функции для строк
unsigned int ELFHash(char *key, unsigned int mod)
{
unsigned
Пример хэш-функции для строк
unsigned int ELFHash(char *key, unsigned int mod)
{
unsigned

Слайд 19Jenkins hash functions
uint32_t jenkins_hash(char *key, size_t len)
{
uint32_t hash, i;
Jenkins hash functions
uint32_t jenkins_hash(char *key, size_t len)
{
uint32_t hash, i;

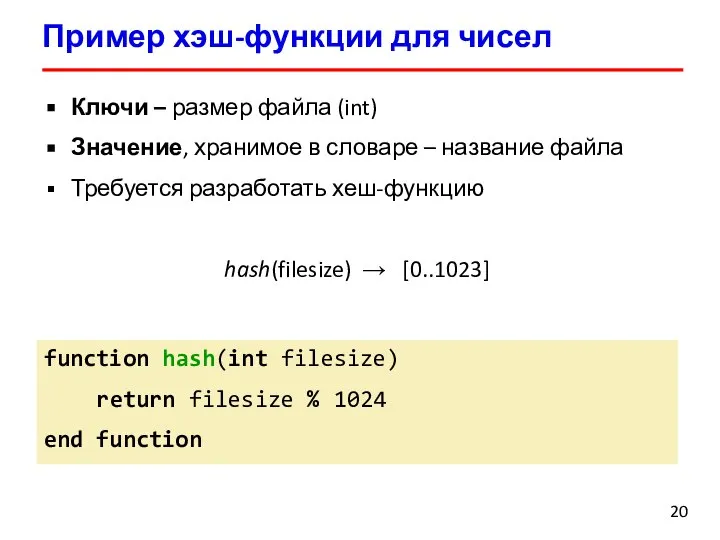
Слайд 20Пример хэш-функции для чисел
Ключи – размер файла (int)
Значение, хранимое в словаре –
Пример хэш-функции для чисел
Ключи – размер файла (int)
Значение, хранимое в словаре –
Слайд 21Пример хэш-функции для строк
Пример хэш-функции для строк

Слайд 22Хеш-таблицы (Hash table)
Длину h хеш-таблицы выбирают как простое число
Для такой таблицы модульная
Хеш-таблицы (Hash table)
Длину h хеш-таблицы выбирают как простое число
Для такой таблицы модульная

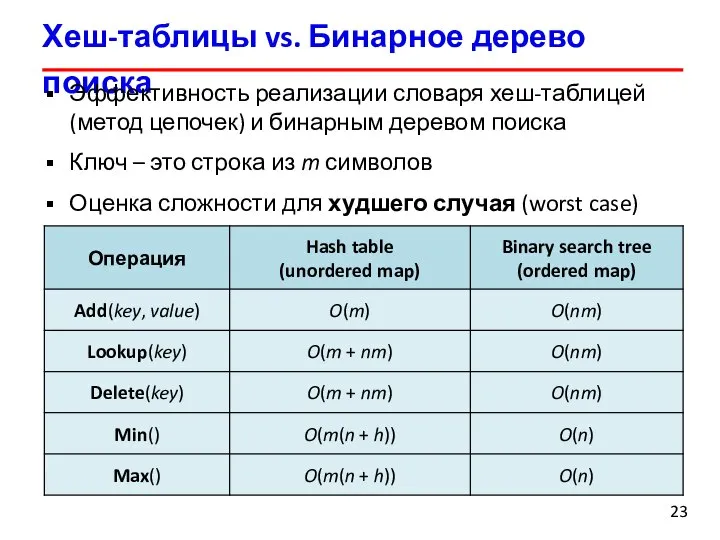
Слайд 23Хеш-таблицы vs. Бинарное дерево поиска
Эффективность реализации словаря хеш-таблицей
(метод цепочек) и бинарным
Хеш-таблицы vs. Бинарное дерево поиска
Эффективность реализации словаря хеш-таблицей (метод цепочек) и бинарным
Слайд 24Хеш-таблицы vs. Бинарное дерево поиска
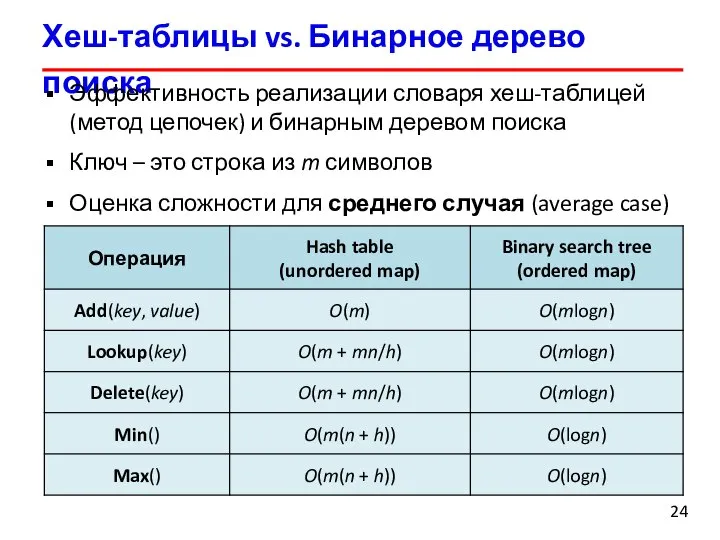
Эффективность реализации словаря хеш-таблицей
(метод цепочек) и бинарным
Хеш-таблицы vs. Бинарное дерево поиска
Эффективность реализации словаря хеш-таблицей (метод цепочек) и бинарным
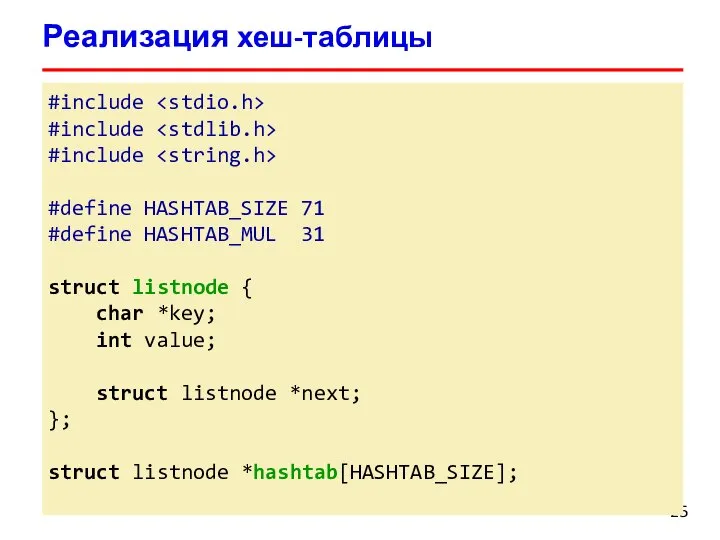
Слайд 25Реализация хеш-таблицы
#include
#include
#include
#define HASHTAB_SIZE 71
#define HASHTAB_MUL 31
struct listnode {
char
Реализация хеш-таблицы
#include
#include
#include
#define HASHTAB_SIZE 71
#define HASHTAB_MUL 31
struct listnode {
char
Слайд 26Хеш-функция
unsigned int hashtab_hash(char *key)
{
unsigned int h = 0;
char *p;
for (p
Хеш-функция
unsigned int hashtab_hash(char *key)
{
unsigned int h = 0;
char *p;
for (p

Слайд 27Инициализация хеш-таблицы
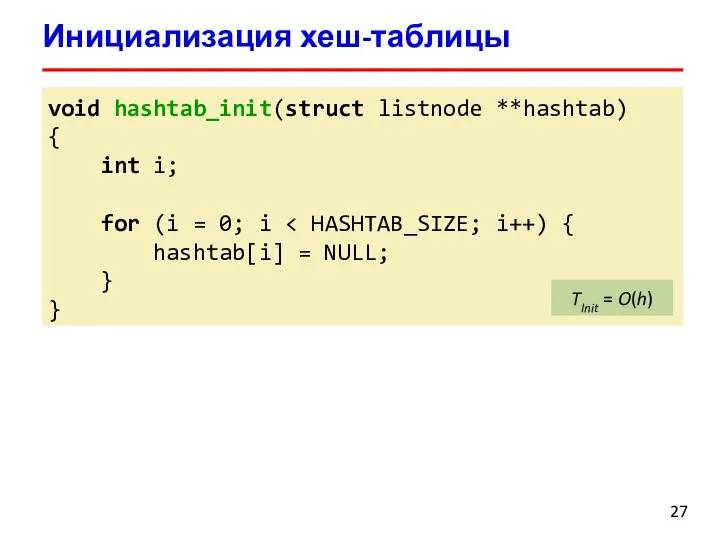
void hashtab_init(struct listnode **hashtab)
{
int i;
for (i = 0; i <
Инициализация хеш-таблицы
void hashtab_init(struct listnode **hashtab)
{
int i;
for (i = 0; i <
Слайд 28Добавление элемента в хеш-таблицу
void hashtab_add(struct listnode **hashtab,
char *key, int value)
{
struct
Добавление элемента в хеш-таблицу
void hashtab_add(struct listnode **hashtab,
char *key, int value)
{
struct

Слайд 29Поиск элемента
struct listnode *hashtab_lookup(
struct listnode **hashtab,
char *key)
{
int index;
Поиск элемента
struct listnode *hashtab_lookup(
struct listnode **hashtab,
char *key)
{
int index;

Слайд 30Поиск элемента
int main()
{
struct listnode *node;
hashtab_init(hashtab);
hashtab_add(hashtab, "Tigr", 190);
hashtab_add(hashtab, "Slon", 2300);
Поиск элемента
int main()
{
struct listnode *node;
hashtab_init(hashtab);
hashtab_add(hashtab, "Tigr", 190);
hashtab_add(hashtab, "Slon", 2300);

Слайд 31Удаление элемента
void hashtab_delete(struct listnode **hashtab, char *key)
{
int index;
struct listnode *p,
Удаление элемента
void hashtab_delete(struct listnode **hashtab, char *key)
{
int index;
struct listnode *p,

Слайд 32Удаление элемента
int main()
{
struct listnode *node;
/* ... */
hashtab_delete(hashtab, "Slon");
node = hashtab_lookup(hashtab,
Удаление элемента
int main()
{
struct listnode *node;
/* ... */
hashtab_delete(hashtab, "Slon");
node = hashtab_lookup(hashtab,

 Среда моделирования Rational Rose
Среда моделирования Rational Rose 1С: Прогресс. Официальный партнер фирмы 1С
1С: Прогресс. Официальный партнер фирмы 1С Команды языка Паскаль
Команды языка Паскаль Интегрируем 1С и 1С-bitrix
Интегрируем 1С и 1С-bitrix Устройства ввода графической информации. Практическая работа № 8. Работаем с графическими фрагментами
Устройства ввода графической информации. Практическая работа № 8. Работаем с графическими фрагментами Программы-архиваторы
Программы-архиваторы Стрижка собак
Стрижка собак Изучение и применение графов, а так же их визуализация. Практическая работа
Изучение и применение графов, а так же их визуализация. Практическая работа Презентация на тему Кодирование информации
Презентация на тему Кодирование информации  Популярные компьютерные игры
Популярные компьютерные игры Принципы динамического программирования на примере задачи поиска кратчайшего пути на клеточном поле
Принципы динамического программирования на примере задачи поиска кратчайшего пути на клеточном поле Порядок работы с электронным каталогом НБ УГГУ
Порядок работы с электронным каталогом НБ УГГУ Технология установки, настройки и обновления прикладного программного обеспечения
Технология установки, настройки и обновления прикладного программного обеспечения Работа с интернет магазином, интернет - СМИ, интернет - библиотекой
Работа с интернет магазином, интернет - СМИ, интернет - библиотекой Особенности текстов разных типов
Особенности текстов разных типов Работа в среде TRIK Studio
Работа в среде TRIK Studio Euronews. История создания. Учредители
Euronews. История создания. Учредители Цвет в компьютерной графики
Цвет в компьютерной графики Разработка методов и алгоритмов поисковой системы
Разработка методов и алгоритмов поисковой системы IP в IT. Индивидуальные и пакетные решения
IP в IT. Индивидуальные и пакетные решения По сайту
По сайту Особенности CoralDraw
Особенности CoralDraw Книжная графика, как активный медиасигнал. Раскрытие специфики детской книжной иллюстрации
Книжная графика, как активный медиасигнал. Раскрытие специфики детской книжной иллюстрации Проект. Рецепты для всех
Проект. Рецепты для всех Презентация "Надстройка для PowerPoint" - скачать презентации по Информатике
Презентация "Надстройка для PowerPoint" - скачать презентации по Информатике Композиция. Правила и приемы
Композиция. Правила и приемы Программирование на языке Python
Программирование на языке Python Скриншот история подключений
Скриншот история подключений