- Информатика. Сжатие данных

Содержание
- 2. СЖАТИЕ Сжатие данных Кодирование по алгоритму Хаффмана Межсимвольная зависимость Избыточность в английском языке Кодирование Лемпеля –
- 3. Сжатие данных (data compression) – процедура уменьшения их объёма с сохранением (полным или частичным) их целостности.
- 5. Способы решения (устранения избыточности): 1. Замена часто встречающихся данных короткими кодовыми словами, а редких – длинными
- 6. Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или белый шум, зашифрованные сообщения), принципиально невозможно
- 7. Все методы сжатия данных делятся на два основных класса: Сжатие без потерь (полное восстановление исходных данных)
- 8. два способа сжатия текста (сжатие без потерь): Кодирование Хаффмана (энтропийное кодирование) Кодирование Лемпеля-Зива (LZ77)
- 9. Алгоритм Хаффмана – это один из первых методов, в основе которого лежит энтропийное кодирование (кодирование источника).
- 11. АЛГОРИТМ ХАФФМАНА Алгоритм состоит из двух этапов: 1. Сначала символы источника сокращаются путем последовательного образования сложных
- 12. Рассмотрим источник из пяти символов с заданными вероятностями. ПРИМЕР 1
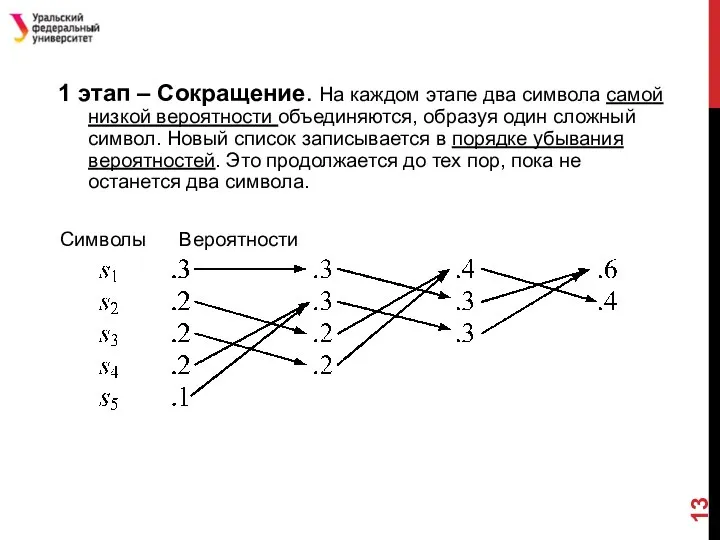
- 13. 1 этап – Сокращение. На каждом этапе два символа самой низкой вероятности объединяются, образуя один сложный
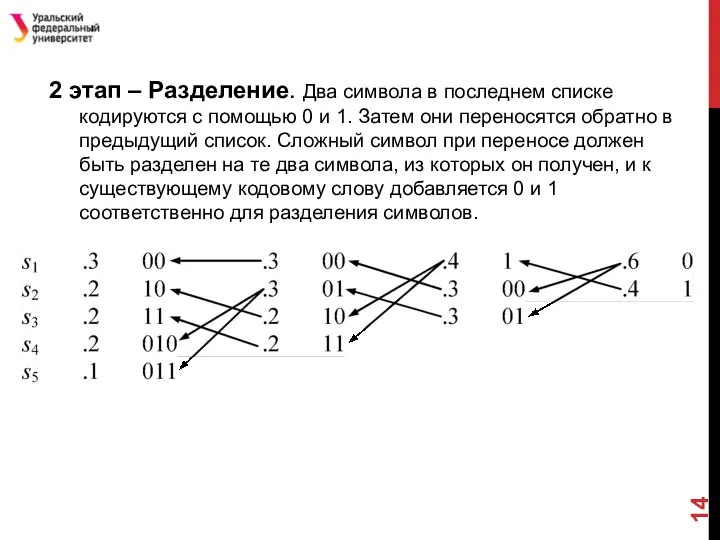
- 14. 2 этап – Разделение. Два символа в последнем списке кодируются с помощью 0 и 1. Затем
- 15. Итак, мы получили код: Символ источника Вероятность Код s1 0.3 00 s2 0.2 10 s3 0.2
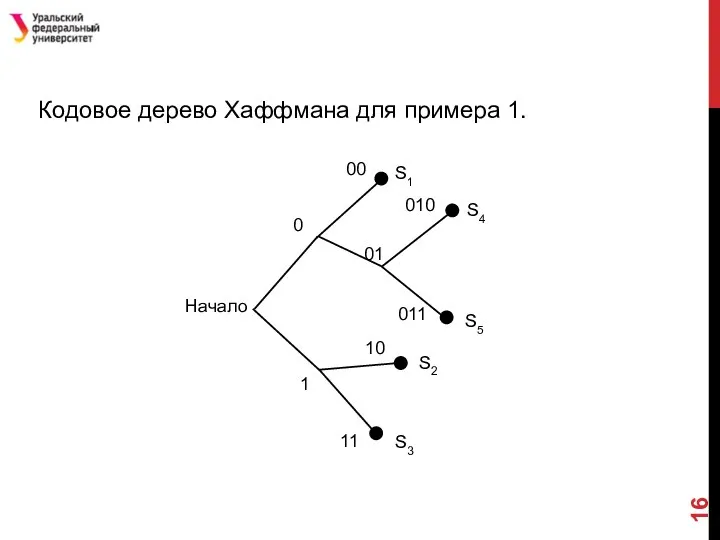
- 16. Кодовое дерево Хаффмана для примера 1.
- 17. Неоднозначность кодов Хаффмана. Попробуйте построить два различных кода Хаффмана для пятисимвольного источника. ПРИМЕР 2
- 18. Результат: два кода построены по методике Хаффмана и имеют одинаковую среднюю длину.
- 19. ПРИМЕР 3
- 21. Межсимвольная зависимость. Следующие друг за другом символы от источника не всегда являются независимыми. Наоборот, текущие вероятности
- 22. ВЕРОЯТНОСТИ В АНГЛИЙСКОМ ЯЗЫКЕ
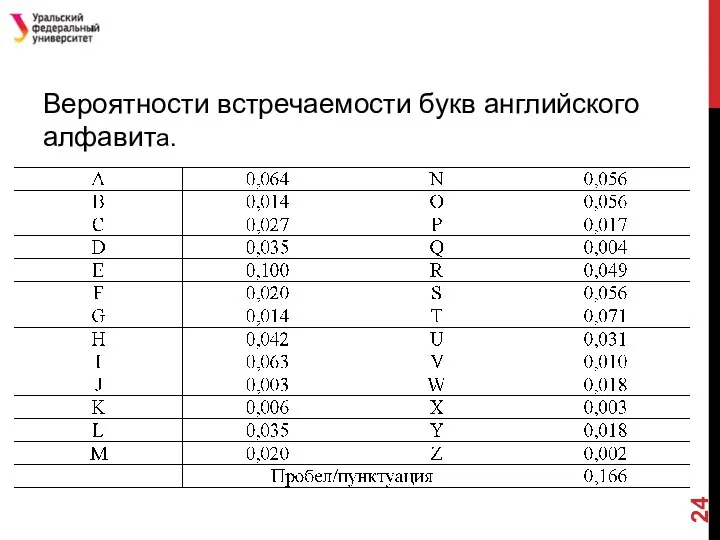
- 24. Вероятности встречаемости букв английского алфавита.
- 26. Таким образом, код Хаффмана для алфавита будет иметь среднюю длину ближе к четырем, чем к пяти.
- 27. ПРИМЕНЕНИЕ ЗАКОНОВ ЦИПФА (ЗИПФА)
- 28. Для расчета Шеннон воспользовался законом Ципфа. (Джордж Ципф в 1949 г. эмпирически вывел соотношение частотностей слов).
- 31. ИЗБЫТОЧНОСТЬ АНГЛИЙСКОГО ЯЗЫКА
- 33. Выводы: Имеется огромная возможность для компрессии английского текста. Текстовый файл может теоретически быть спрессован до размера,
- 34. КОДИРОВАНИЕ ЛЕМПЕЛЯ – ЗИВА Новаторский и талантливый метод компрессии предложили Зив и Лемпель в 1977 г.
- 35. В методе Лемпеля – Зива и отправитель, и получатель ведут запись того, что уже было отправлено.
- 37. ПРИМЕР. LZ77 Исходный текст: THIS-THESIS-IS-THE-THESIS. Передаваемые сообщения (код LZ77): (0, 0, T) T (0, 0, H)
- 38. Задания: 1) Закодируйте сообщение: ROCCOBAROCCO. Код LZ77: (0,0,’R’) (0,0,’O’) (0,0,’C’) (1,1,’O’) (0,0,’B’) (0,0,’A’) (7,5,’.’) 2) Декодируйте
- 39. СОВРЕМЕННЫЕ АРХИВАТОРЫ
- 40. ДРУГИЕ ФОРМЫ СЖАТИЯ ИНФОРМАЦИИ Кроме текста, сжатие также применяется к графике, изображениям, речи, видео…(эти данные не
- 41. Общепринятой является обработка этих видов данных первоначально посредством дискретизации временного и пространственного измерения, а также уровней
- 43. МЕТОДЫ ПРЕДСКАЗАНИЯ
- 45. JPEG Стандарты сжатия графической информации были установлены комитетом, который называется Совместной группой экспертов по фотографии (Joint
- 46. АППРОКСИМАЦИЯ
- 47. Популярная версия JPEG аппроксимирует матрицу яркости посредством серии двухмерных функций косинуса и записывает коэффициенты этой серии.
- 48. МРЗ MPEG (филиал комитета JPEG) – группа экспертов по киноизображениям разработала стандарты сжатия для киноизображений и
- 49. Упражнения 1. (Шестисимвольный источник.) Источник имеет шесть символов с нижеуказанными вероятностями. s1 0,3 s4 0,1 s2
- 50. 2. (Пятисимвольный источник.) Найти три различных кода Хаффмана для источника. s1 0,4 s4 0,1 s2 0,2
- 51. 3. (Преимущество алгоритма Хаффмана.) Преимущество компрессии при кодировании по алгоритму Хаффмана S2 вместо S является наиболее
- 52. 4. (Вычитание Хаффмена.) Рассмотрите источник со связанными с ним символами и вероятностями Один код Хаффмена для
- 53. 5. (Пример LZ77.) Декодируйте сообщение (0, 0, ‘a’) (0, 0, ‘b’) (0, 0, ‘r’) (3, 1,
- 55. Скачать презентацию
Слайд 2СЖАТИЕ
Сжатие данных
Кодирование по алгоритму Хаффмана
Межсимвольная зависимость
Избыточность в английском языке
Кодирование Лемпеля – Зива
Другие
СЖАТИЕ
Сжатие данных
Кодирование по алгоритму Хаффмана
Межсимвольная зависимость
Избыточность в английском языке
Кодирование Лемпеля – Зива
Другие

Слайд 3Сжатие данных (data compression) – процедура уменьшения их объёма с сохранением (полным
Сжатие данных (data compression) – процедура уменьшения их объёма с сохранением (полным


Слайд 5Способы решения (устранения избыточности):
1. Замена часто встречающихся данных короткими кодовыми словами, а
Способы решения (устранения избыточности):
1. Замена часто встречающихся данных короткими кодовыми словами, а

Слайд 6Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или белый шум,
Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или белый шум,

Слайд 7Все методы сжатия данных делятся на два основных класса:
Сжатие без потерь (полное
Все методы сжатия данных делятся на два основных класса:
Сжатие без потерь (полное

Слайд 8два способа сжатия текста (сжатие без потерь):
Кодирование Хаффмана (энтропийное кодирование)
Кодирование Лемпеля-Зива (LZ77)
два способа сжатия текста (сжатие без потерь):
Кодирование Хаффмана (энтропийное кодирование)
Кодирование Лемпеля-Зива (LZ77)

Слайд 9Алгоритм Хаффмана – это один из первых методов, в основе которого лежит
Алгоритм Хаффмана – это один из первых методов, в основе которого лежит


Слайд 11АЛГОРИТМ ХАФФМАНА
Алгоритм состоит из двух этапов:
1. Сначала символы источника сокращаются путем последовательного
АЛГОРИТМ ХАФФМАНА
Алгоритм состоит из двух этапов:
1. Сначала символы источника сокращаются путем последовательного

Слайд 12Рассмотрим источник из пяти символов с заданными вероятностями.
ПРИМЕР 1
Рассмотрим источник из пяти символов с заданными вероятностями.
ПРИМЕР 1

Слайд 131 этап – Сокращение. На каждом этапе два символа самой низкой вероятности
1 этап – Сокращение. На каждом этапе два символа самой низкой вероятности
Слайд 142 этап – Разделение. Два символа в последнем списке кодируются с помощью
2 этап – Разделение. Два символа в последнем списке кодируются с помощью
Слайд 15Итак, мы получили код:
Символ источника Вероятность Код
s1 0.3 00
s2 0.2 10
s3 0.2 11
s4 0.2 010
s5 0.1 011
Средняя длина кода:
Энтропия источника:
(2×0,3) + (2×0,2) + (2×0,2) + (3×0,2) +
Итак, мы получили код:
Символ источника Вероятность Код
s1 0.3 00
s2 0.2 10
s3 0.2 11
s4 0.2 010
s5 0.1 011
Средняя длина кода:
Энтропия источника:
(2×0,3) + (2×0,2) + (2×0,2) + (3×0,2) +

Слайд 16Кодовое дерево Хаффмана для примера 1.
Кодовое дерево Хаффмана для примера 1.
Слайд 17Неоднозначность кодов Хаффмана.
Попробуйте построить два различных кода Хаффмана для пятисимвольного источника.
ПРИМЕР 2
Неоднозначность кодов Хаффмана.
Попробуйте построить два различных кода Хаффмана для пятисимвольного источника.
ПРИМЕР 2

Слайд 18Результат: два кода построены по методике Хаффмана и имеют одинаковую среднюю длину.
Результат: два кода построены по методике Хаффмана и имеют одинаковую среднюю длину.

Слайд 19
ПРИМЕР 3
ПРИМЕР 3


Слайд 21Межсимвольная зависимость. Следующие друг за другом символы от источника не всегда являются
Межсимвольная зависимость. Следующие друг за другом символы от источника не всегда являются

Слайд 22ВЕРОЯТНОСТИ В АНГЛИЙСКОМ ЯЗЫКЕ
ВЕРОЯТНОСТИ В АНГЛИЙСКОМ ЯЗЫКЕ


Слайд 24Вероятности встречаемости букв английского алфавита.
Вероятности встречаемости букв английского алфавита.

Слайд 26Таким образом, код Хаффмана для алфавита будет иметь среднюю длину ближе к
Таким образом, код Хаффмана для алфавита будет иметь среднюю длину ближе к

Слайд 27ПРИМЕНЕНИЕ ЗАКОНОВ ЦИПФА (ЗИПФА)
ПРИМЕНЕНИЕ ЗАКОНОВ ЦИПФА (ЗИПФА)

Слайд 28Для расчета Шеннон воспользовался законом Ципфа. (Джордж Ципф в 1949 г. эмпирически
Для расчета Шеннон воспользовался законом Ципфа. (Джордж Ципф в 1949 г. эмпирически



Слайд 31ИЗБЫТОЧНОСТЬ АНГЛИЙСКОГО ЯЗЫКА
ИЗБЫТОЧНОСТЬ АНГЛИЙСКОГО ЯЗЫКА


Слайд 33Выводы:
Имеется огромная возможность для компрессии английского текста.
Текстовый файл может теоретически быть
Выводы:
Имеется огромная возможность для компрессии английского текста.
Текстовый файл может теоретически быть

Слайд 34КОДИРОВАНИЕ ЛЕМПЕЛЯ – ЗИВА
Новаторский и талантливый метод компрессии предложили Зив и
КОДИРОВАНИЕ ЛЕМПЕЛЯ – ЗИВА
Новаторский и талантливый метод компрессии предложили Зив и

Слайд 35В методе Лемпеля – Зива и отправитель, и получатель ведут запись того,
В методе Лемпеля – Зива и отправитель, и получатель ведут запись того,


Слайд 37ПРИМЕР. LZ77
Исходный текст:
THIS-THESIS-IS-THE-THESIS.
Передаваемые сообщения (код LZ77):
(0, 0, T) T
(0, 0, H) TH
(0, 0,
ПРИМЕР. LZ77
Исходный текст:
THIS-THESIS-IS-THE-THESIS.
Передаваемые сообщения (код LZ77):
(0, 0, T) T
(0, 0, H) TH
(0, 0,

Слайд 38Задания:
1) Закодируйте сообщение:
ROCCOBAROCCO.
Код LZ77:
(0,0,’R’) (0,0,’O’) (0,0,’C’) (1,1,’O’) (0,0,’B’) (0,0,’A’) (7,5,’.’)
2) Декодируйте
Задания:
1) Закодируйте сообщение:
ROCCOBAROCCO.
Код LZ77:
(0,0,’R’) (0,0,’O’) (0,0,’C’) (1,1,’O’) (0,0,’B’) (0,0,’A’) (7,5,’.’)
2) Декодируйте

Слайд 39СОВРЕМЕННЫЕ АРХИВАТОРЫ
СОВРЕМЕННЫЕ АРХИВАТОРЫ

Слайд 40ДРУГИЕ ФОРМЫ СЖАТИЯ ИНФОРМАЦИИ
Кроме текста, сжатие также применяется к графике, изображениям,
ДРУГИЕ ФОРМЫ СЖАТИЯ ИНФОРМАЦИИ
Кроме текста, сжатие также применяется к графике, изображениям,

Слайд 41Общепринятой является обработка этих видов данных первоначально посредством дискретизации временного и пространственного
Общепринятой является обработка этих видов данных первоначально посредством дискретизации временного и пространственного

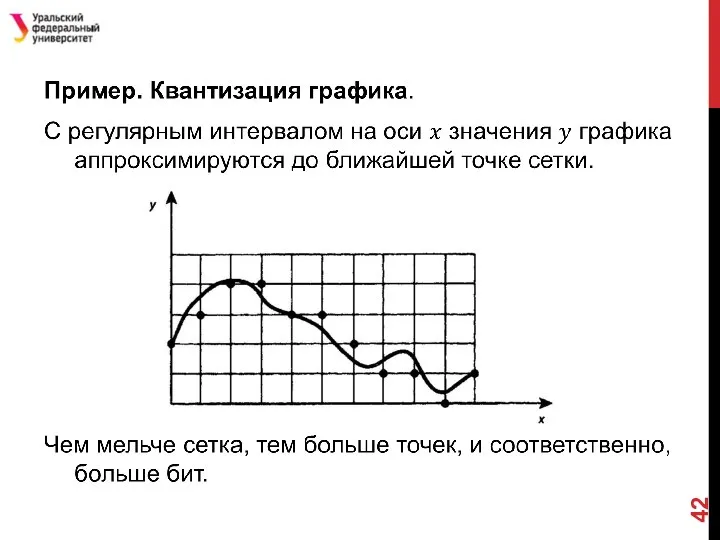
Слайд 43МЕТОДЫ ПРЕДСКАЗАНИЯ
МЕТОДЫ ПРЕДСКАЗАНИЯ
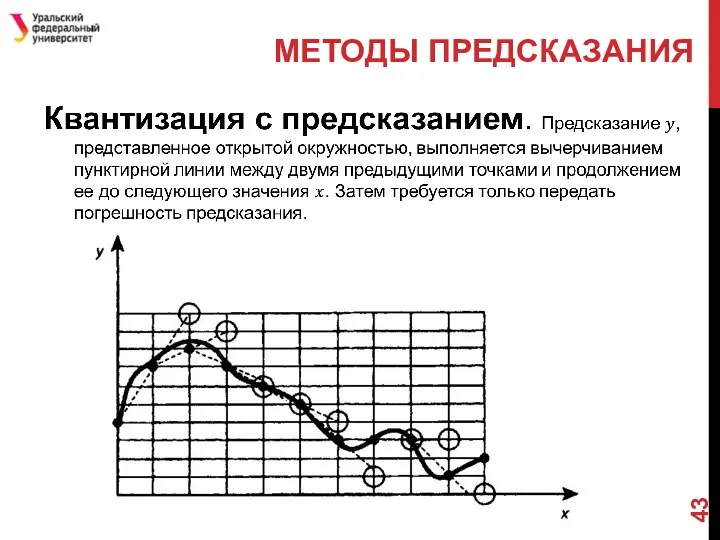
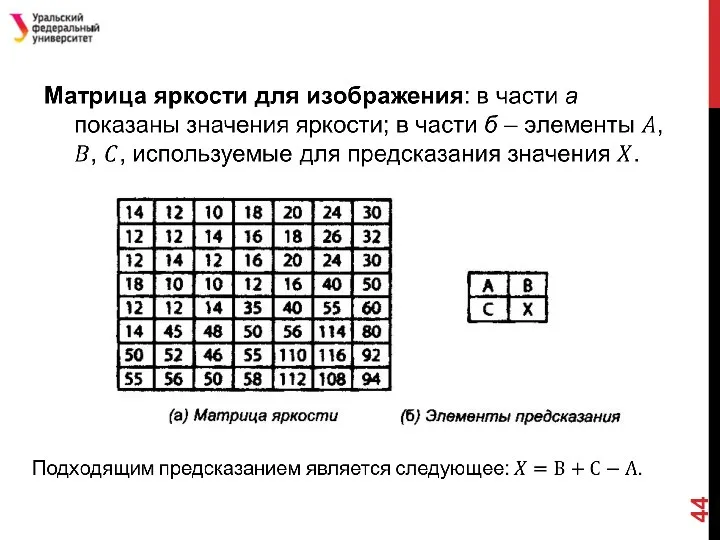
Слайд 45JPEG
Стандарты сжатия графической информации были установлены комитетом, который называется Совместной группой экспертов
JPEG
Стандарты сжатия графической информации были установлены комитетом, который называется Совместной группой экспертов

Слайд 46АППРОКСИМАЦИЯ
АППРОКСИМАЦИЯ
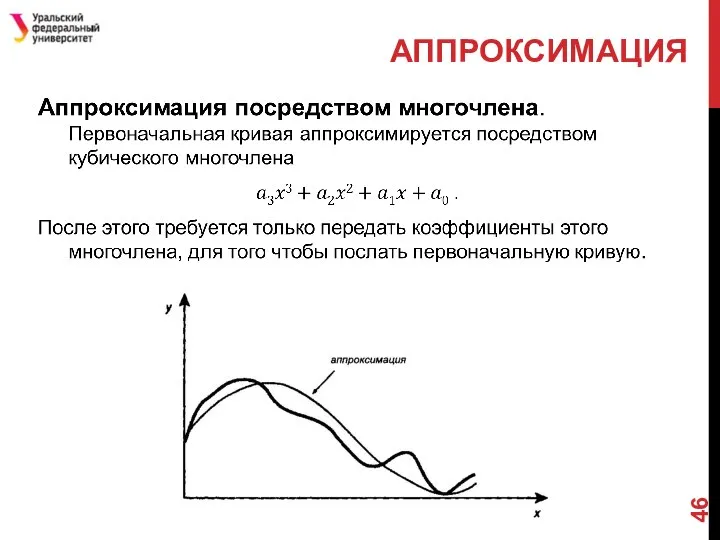
Слайд 47Популярная версия JPEG аппроксимирует матрицу яркости посредством серии двухмерных функций косинуса и
Популярная версия JPEG аппроксимирует матрицу яркости посредством серии двухмерных функций косинуса и

Слайд 48МРЗ
MPEG (филиал комитета JPEG) – группа экспертов по киноизображениям разработала стандарты сжатия
МРЗ
MPEG (филиал комитета JPEG) – группа экспертов по киноизображениям разработала стандарты сжатия

Слайд 49Упражнения
1. (Шестисимвольный источник.) Источник имеет шесть символов с нижеуказанными вероятностями.
s1 0,3 s4 0,1
s2 0,2 s5 0,1
s3 0,2 s6 0,1
(а) Найти код
Упражнения
1. (Шестисимвольный источник.) Источник имеет шесть символов с нижеуказанными вероятностями.
s1 0,3 s4 0,1
s2 0,2 s5 0,1
s3 0,2 s6 0,1
(а) Найти код

Слайд 502. (Пятисимвольный источник.) Найти три различных кода Хаффмана для источника.
s1 0,4 s4 0,1
s2 0,2 s5 0,1
s3 0,2
2. (Пятисимвольный источник.) Найти три различных кода Хаффмана для источника.
s1 0,4 s4 0,1
s2 0,2 s5 0,1
s3 0,2

Слайд 513. (Преимущество алгоритма Хаффмана.) Преимущество компрессии при кодировании по алгоритму Хаффмана S2
3. (Преимущество алгоритма Хаффмана.) Преимущество компрессии при кодировании по алгоритму Хаффмана S2

Слайд 524. (Вычитание Хаффмена.) Рассмотрите источник со связанными с ним символами и вероятностями
Один
4. (Вычитание Хаффмена.) Рассмотрите источник со связанными с ним символами и вероятностями
Один

Слайд 535. (Пример LZ77.)
Декодируйте сообщение
(0, 0, ‘a’) (0, 0, ‘b’) (0, 0,
5. (Пример LZ77.)
Декодируйте сообщение
(0, 0, ‘a’) (0, 0, ‘b’) (0, 0,

 Полгода стажерства
Полгода стажерства Логические основы информатики
Логические основы информатики Райффайзенбанк. Веб-приложение
Райффайзенбанк. Веб-приложение Sport programming assist. Simply submitting code
Sport programming assist. Simply submitting code Автоматический перевод текстов
Автоматический перевод текстов ERP-системы. Доклад
ERP-системы. Доклад Подготовка материалов на конкурс в облачной среде МойОфис
Подготовка материалов на конкурс в облачной среде МойОфис 8-3py_Массивы (Python)_2
8-3py_Массивы (Python)_2 История развития компьютерной техники
История развития компьютерной техники Базовые принципы проектирования
Базовые принципы проектирования Количество путей в графе
Количество путей в графе Медиабезопасность для детей
Медиабезопасность для детей Диаграмма компонентов
Диаграмма компонентов Исследовательская работа по информатике Миры Kodu
Исследовательская работа по информатике Миры Kodu Введение в контроль версий
Введение в контроль версий Информационные процессы
Информационные процессы Шаблон презентации проекта
Шаблон презентации проекта Занятие №4
Занятие №4 Симулятор Православного Храма
Симулятор Православного Храма Памяти поколений. Дни воинской славы России! Создание документации с помощью электронных таблиц
Памяти поколений. Дни воинской славы России! Создание документации с помощью электронных таблиц Стили. Оглавление. MS WORD 5
Стили. Оглавление. MS WORD 5 Компьютерная безопасность. Лекция 8
Компьютерная безопасность. Лекция 8 Проектные технологии
Проектные технологии Безопасность школьников в сети Интернета
Безопасность школьников в сети Интернета Nokia 5650. Разработка финской промышленности
Nokia 5650. Разработка финской промышленности Криптовалюта
Криптовалюта Нелинейные структуры данных. Тема 5
Нелинейные структуры данных. Тема 5 Путешествие по острову числовой информации
Путешествие по острову числовой информации